当前位置:网站首页>Adaptive Bezier curve network for real-time end-to-end text recognition
Adaptive Bezier curve network for real-time end-to-end text recognition
2022-07-06 10:26:00 【How about a song without trace】
ABCNet V2: Adaptive for real-time end-to-end text recognition Bezier Curve networks
Abstract :
Abstract end-to-end text location, which aims to integrate detection and recognition into a unified framework, has attracted more and more attention due to the simplicity of its two complementary tasks . It's still an open question , Especially when dealing with text instances with arbitrary shapes . The previous methods can be roughly divided into two groups : Character based and segmentation based , Due to unstructured output , They usually require character level comments and / Or complex post-processing . ad locum , We present an adaptive Bessel curve network v2 (ABCNet v2) To solve the problem of end-to-end text recognition . Our main contribution has four aspects : 1) For the first time, we adopt parameterized Bezier The curve adaptively fits arbitrary shaped text , Compared with the segmentation based method , This curve can not only provide structured output , And it can provide controllable representation .2) We designed a novel BezierAlign layer , It is used to extract accurate convolution features of text instances with arbitrary shapes , Compared with the previous method, the recognition accuracy is significantly improved .3) Different from previous methods , Previous methods often suffer from complex post-processing and sensitive hyperparameters , our ABCNet v2 Maintain a simple assembly line , Among them, only post-processing non maximum inhibition (NMS).4) Because the performance of text recognition is closely dependent on feature alignment ,ABCNet v2 Further, a simple and effective coordinate convolution is used to encode the position of the convolution filter , This has led to considerable improvement , The computational overhead is negligible . In all kinds of bilingual ( English and Chinese ) Comprehensive experiments on benchmark data sets show ,ABCNet v2 Can achieve the most advanced performance , While maintaining very high efficiency . what's more , There is little work to quantify the text speckle model , Therefore, we quantify the model to improve the proposed ABCNet v2 Reasoning time of . This may be valuable for real-time applications . The code and model can be found at : https:// git.io/AdelaiDet.
One 、 introduction
Previous scene text recognition methods often involve two independent modules : Text detection and recognition , These two modules are implemented in sequence . Many of them deal with only one task , And directly borrow the best performance module from another task . This simplified approach is unlikely to take full advantage of the potential of deep convolution Networks , Because the two tasks are isolated , There is no shared function .

Picture translation : In the figure (a) in , We follow the previous method , Use TPS[1] and STN[2] Twist the curved text area into a rectangle . In the figure (b) in , We use generated Bezier Curve and proposed Bezieralign To distort the result , So as to improve the accuracy .
lately , End to end scenario text Click method [3],[4]、[5]、[6]、[7]、[8]、[9]、[10]、[11] And other methods that directly establish a unified mapping relationship between the input image and the text record set have attracted more and more attention . Compared with the model in which detection and recognition are two independent modules , The advantages of designing an end-to-end frame are as follows . First , Word recognition can significantly improve the accuracy of detection . One of the most prominent features of text is sequence attribute . However , False positives show that the appearance of the sequence exists in an unconditional environment , Such as block 、 Buildings and railings . In order to make the network have the ability to distinguish different modes , Some methods [3],[4],[5] Propose to share the characteristics between two tasks , Train the network end to end . and , Due to the shared characteristics of end-to-end framework , It often shows an advantage in reasoning speed , More suitable for real-time applications . Last , At present, independent recognition models usually use fully cropped text images or heuristic synthetic images for training . The end-to-end module can force the identification module to adapt to the detection output , Therefore, the results can be more robust [10].
The existing methods of end-to-end text recognition can be roughly divided into two categories : Character based and segmentation based . The character based method first detects and recognizes a single character , Then output words by applying additional grouping modules . Although effective , But it requires laborious character level annotation . Besides , Grouping algorithms usually require some predefined super parameters , Thus, it shows limited robustness and generalization ability . Another line of research is based on segmentation , Where text instances are represented by unstructured outlines , This makes the subsequent identification steps difficult . for example ,[1 2] The work in depends on TPS [1] or STN [2] Step twist the original ground truth into a rectangular shape . Please note that , Characters may be significantly distorted , Pictured 1 Shown . Besides , Compared with detection , Text recognition requires a lot of training data , This leads to optimization difficulties in the unified framework .
To address these limitations , We propose an adaptive Bessel curve network v2 (ABCNet v2), This is an end-to-end trainable framework , For real-time arbitrary shape scene text positioning .ABCNet v2 It can be achieved through simple and effective Bezier Curve adaptation to achieve arbitrary shape scene text detection , Compared with standard rectangular bounding box detection , This brings negligible computational overhead . Besides , We designed a novel feature alignment layer , be called BezierAlign, To accurately calculate the convolution characteristics of curved text instances , Thus, higher recognition accuracy can be achieved . We have successfully used parameter space for the first time (Bezier curve ) Multi directional or curved text positioning , Thus, a very simple and efficient pipeline is realized .
suffer [13] 、 [14] 、 [15] Inspired by recent work , We are in our conference version [16] It has been improved in four aspects ABCNet: Feature extractor 、 Detection branch 、 Identify branches and end-to-end training . Due to inevitable proportional changes , Suggested ABCNet v2 Combined with iterative bidirectional function , To achieve better accuracy and efficiency tradeoffs . Besides , According to our observations , Detecting feature alignment in branches is very important for subsequent text recognition . So , We use a coordinate coding method with negligible computational overhead to explicitly encode the positions in the convolution filter , Thus, the accuracy is greatly improved . For identifying branches , We have integrated a character attention module , This module can recursively predict the characters of each word , Without using character level comments . In order to achieve effective end-to-end training , We further propose an adaptive end-to-end training (AET) Strategy , To match the detection of end-to-end training . This can force the identification branch to be more robust to the detection behavior . therefore , The proposed ABCNet v2 There are several advantages over the previous most advanced methods , Summarized below :
- • We use it for the first time Bezier Curve introduces a new , Concise parametric representation of surface scene text . Compared with the standard bounding box representation , It introduces negligible computational overhead .
- • We propose a new feature alignment method , That is to say BezierAlign, Thus, the identified branches can be seamlessly connected to the overall structure . By sharing trunk features , Identifying branches can design light-weight structures for effective reasoning .
- • ABCNet v2 It is more general to deal with multi-scale text instances by considering the global text features of bi-directional multi-scale pyramid .
- • As far as we know , Our method is the first one that can simultaneously detect and recognize the level in a single shot way 、 Multi directional and arbitrarily shaped text , While maintaining the speed of real-time reasoning framework .
- • In order to further speed up the reasoning , We also use model quantification technology , indicate ABCNet v2 It can achieve faster reasoning speed when only marginal accuracy is reduced .
- • Comprehensive experiments on various benchmarks have proved the proposed ABCNet v2 The latest text location performance in terms of accuracy and speed .
Two 、 Related work
Scene text recognition needs to detect and recognize text at the same time , Instead of just one task . Early scene text recognition methods are usually simply connected through independent detection and recognition models . The two models are optimized with different architectures . In recent years , End to end approach (§2.2) By integrating detection and identification into a unified network , Significantly improve the performance of text recognition .
2.1 Separate scene text positioning
In this section , We briefly review the literature , The key is to detect or identify .
2.1.1 Scene text detection
Through the flexibility of detection, we can observe the development trend of text detection . Detect the text detection of the focused horizontal scene represented by the bounding box from the horizontal rectangle , To rotate the rectangular or quadrilateral bounding box to represent the multi-faceted scene text detection , Then to instance segmentation mask or arbitrary shape scene text detection represented by polygons . Early methods based on horizontal rectangles can be traced back to Lucas wait forsomeone . [17], It builds a groundbreaking level ICDAR'03 The benchmark . ICDAR'03 And subsequent data sets (ICDAR'11[18] and ICDAR'13[19]) It has attracted a large number of researchers in horizontal scene text detection [20]、[21]、[22]、[23]、[24]、[25].
stay 2010 Years ago , Most methods only focus on the regular horizontal scene text , This is limited to generalization to practical applications , Multidirectional scene text is everywhere . So , Yao et al . [26] A practical detection system and a multi-directional benchmark for multi-directional scene text detection are proposed (MSRA-TD500). Both the method and the dataset use rotating rectangular bounding boxes to detect and annotate multi-directional text instances . except MSRA-TD500, Include NEOCR [27] and USTBSV1K [28] The emergence of other multidirectional data sets, including, has further promoted many methods based on rotating rectangles [3]、[26]、[28]、[29]、[30] ,[31]. since 2015 Since then ,ICDAR'15 [32] Start using quadrilateral annotations based on four points for each text instance , This promotes many methods , These methods have successfully proved more compact 、 Advantages of more flexible quadrilateral detection method . SegLink Method [33] Predict the text area through the directional segment , And learn to connect links to recombine results .
DMPNet [34] It is observed that the rotating rectangle may still contain unnecessary background noise 、 An imperfect match or unnecessary overlap , Therefore, it is recommended to use quadrilateral bounding boxes to detect text with auxiliary predefined quadrilateral sliding windows . EAST [35] The dense prediction structure is used to predict the quadrilateral boundary box directly . WordSup [36] An iterative strategy for automatically generating character regions is proposed , Show robustness in complex scenes . ICDAR 2015 The successful attempt of has inspired many quadrilateral based datasets , for example RCTW'17 [37]、MLT [38] and ReCTS [39]. lately , The research focus has shifted from multi-directional scene text detection to arbitrary shape text detection . Arbitrary shapes are mainly represented by curvilinear characters in the wild , It can also be very common in our real world , For example, cylindrical objects ( Bottles and stones )、 A spherical object 、 Copy plane ( clothes 、 Streamer and receipt )、 COINS 、 sign 、 The seal 、 Signs, etc . The first curved text data set CUTE80 [40] Is in 2014 Built in . But this data set is mainly used for scene text recognition , Because it only contains 80 A clean image , There are relatively few text instances . In order to detect the scene text with arbitrary shape , Two benchmarks have recently been proposed ——Total-Text [41] and SCUT-CTW1500 [42]—— To promote many influential work [43]、[44]、[45]、[46]、 [47]、[48]、[49]、[50]、[51]. TextSnake [47] Designed a FCN To predict the geometric properties of text instances , Then group them into the final output . CRAFT [44] Predict the affinity between the character region of the text and adjacent characters . SegLink++ [48] Provides an instance aware component grouping framework , For dense and arbitrary shape text detection . PSENet [46] It is recommended to learn the text kernel , Then expand them to cover the entire text instance . PAN [45] be based on PSENet [46], Adopt learnable post-processing methods , By predicting the similarity vector of pixels . Wang et al . [52] This paper proposes learning adaptive text region representation to detect arbitrarily shaped text . DRRN [53] It is recommended to detect the text component first , Then combine them through graph network . ContourNet [50] Use adaptive RPN And additional contour prediction branches to improve accuracy .
2.1.2 Scene text recognition
Scene text recognition aims to recognize text through cropped text images . Many previous methods [54],[55], Follow the bottom-up approach , First, the character area is divided by sliding window and each character is classified , Then group them into one word , To consider their dependence on their neighbors . They have achieved good performance in scene text recognition , But it is limited to expensive character level annotations for character detection . If there is no large training data set , Models in this category usually do not generalize well .Su and Lu [56],[57] Put forward a kind of utilization HOG Features and recurrent neural networks (RNN) Scene text recognition system , This is the successful introduction RNN One of the pioneer works for scene text recognition .
And then , Based on CNN The recursive neural network method of performs in a top-down manner , This method can predict text sequence end-to-end , Without any character detection .Shi wait forsomeone .[58] Categorize connectionist time (CTC) [59] Apply to have rnn Network integration cnn, be called CRNN. stay CTC Lost guidance , be based on CRNN Our model can effectively transcribe image content . except CTC Outside , Attention mechanism [60] Also used for text recognition . The above methods are mainly applied to conventional text recognition , For irregular text recognition, it is not robust . In recent years , The methods used for arbitrary shape text recognition are dominant , It can be divided into correction based methods and uncorrected methods .
For the former ,STN [2] And sheet spline (TPS) [61] Are two widely used text correction methods .Shi etc. [62] Take the lead in introducing STN And an attention based decoder to predict text sequences .[63] The work in uses iterative text correction to achieve better performance . Besides , Luo et al .[64] Put forward MORAN, It corrects the text by returning the offset of the position offset .Liu wait forsomeone [65] A character perception neural network is proposed (CharNet), The network first detects characters , Then convert them into horizontal characters .ESIR [66] An iterative rectification pipeline is proposed , You can convert the position of text from perspective distortion to regular format , Thus, an effective end-to-end scene text recognition system can be constructed .
Litman wait forsomeone [67] First, apply on the input image TPS, Then stack several selective attention decoders for visual and contextual features . In the category of no rectification method ,Cheng wait forsomeone [68] An arbitrary directional network is proposed (AON) To extract features in four directions and character position clues .Li wait forsomeone [69] application 2d Note that the mechanism captures irregular text features , Achieved impressive results . In order to solve the problem of attention drift ,Yue etc. .[70] A novel location enhanced branch is designed in the recognition model . Besides , Some uncorrected methods are based on semantic segmentation . Liao et al [71] And WAN et al [72] Both propose to segment and classify people through visual features .
2.2 End to end scene text positioning
2.2.1 Conventional end-to-end scene text positioning
Li et al . [3] It may be the first to propose an end-to-end trainable scene text Click method . This method is successfully used ROI pool [73] Add detection and recognition features through a two-stage framework . It is designed to handle horizontal and centralized text . An improved version of it [11] Significantly improved performance . Busta et al . [74] An end-to-end depth text detector is also proposed . He waited for someone . [4] and Liu wait forsomeone . [5] Adopt anchor free mechanism , At the same time, improve the speed of training and reasoning . They use similar sampling strategies , That is, text alignment sampling and ROI rotate , They are respectively used to extract features from quadrilateral detection results . Please note that , Neither of these two methods can find any shape of scene text .
2.2.2 Arbitrary shape end-to-end scene text positioning
In order to detect the scene text with arbitrary shape ,Liao wait forsomeone . [6] Put forward a kind of Mask TextSpotter, It cleverly improves Mask RCNN, And use character level supervision to detect and recognize characters and instance masks at the same time . This method significantly improves the positioning performance of arbitrary shape scene text . Its improved version [10] Significantly reduce the dependence on character level annotations . Sun et al . [75] A method of pre generating quadrilateral detection bounding box is proposed TextNet, Then use the regional proposal network to input the detection features for recognition .
lately , Qin et al . [7] It is recommended to use RoI Masking To focus on arbitrarily shaped text areas . Please note that , Additional calculations are required to fit polygons . [8] In this paper, we propose an arbitrary shape scene text location method , be called CharNet, Character level training data and TextField [76] Group the recognition results . [9] The author proposed a new sampling method RoISlide, It uses the fusion features of predicted fragments from text instances , Therefore, it is robust to long text with arbitrary shape .
Wang et al . [12] First, detect the boundary points of arbitrarily shaped text , adopt TPS Correct the detected text , Then input it into the identification Branch . Liao et al . [77] A segmentation suggestion network is proposed (SPN) To accurately extract the text area , And follow [10] Get the final result .
3 Our approach
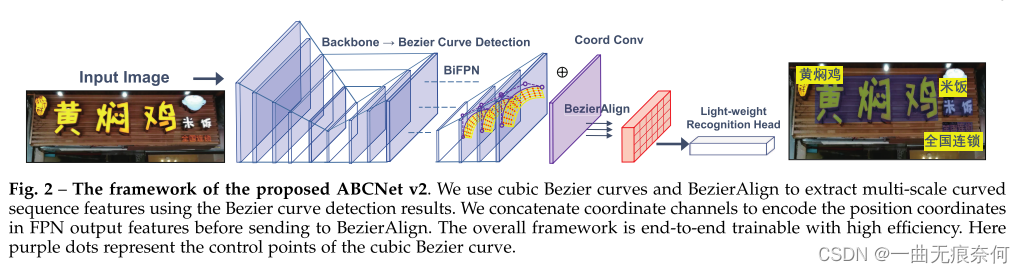
The visual pipeline of our method is shown in the figure 2 Shown . suffer [78]、[79]、[80] Inspired by the , We use single 、 An anchor free convolutional neural network is used as the detection framework . The removal of the anchor box greatly simplifies the detection of our task . Dense prediction detection on the output characteristic map of the detection head , The detection head is made of 4 Steps are 1, Fill in with 1 and 3×3 The stacking and convolution layer of the core . Next , We introduced ABCNet V2 Six key parts of :1)Bezier Curve detection ; 2) Coordinate convolution module ; 3) alignment ; 4) Lightweight attention recognition module ; 5) Adaptive end-to-end training strategy ; 6) Text location quantification .
3.1 Bezier curve detection
And segmentation based methods [44],[46],[47],[49],[76],[81] comparison , The method based on regression is more suitable for arbitrary shape text detection , Such as [42],[52] Shown . One disadvantage of these methods is the complexity of the pipeline , Complex post-processing steps are often required to obtain the final result . In order to simplify the detection of arbitrary shape scene text instances , We propose to perform regression fitting on several key points Bezier The method of curve . Bezier The curve is represented by Bernstein Polynomial based parametric curve C(t). Define as equation (1) Shown :
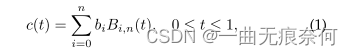
among ,n Indicates times ,bi It means the first one i Control points ,bi,n(t) Express Bernstein Fundamental polynomials , Such as the type (2) Shown :
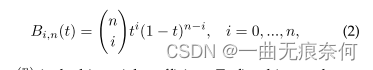
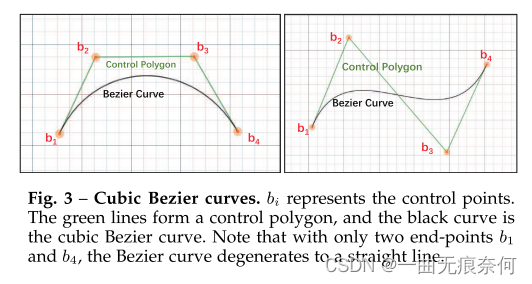
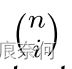 It's binomial coefficient . For use Bezier Curve fitting arbitrary shaped text , We examine the scene text with arbitrary shape from the existing data set , And it has been proved by experience for three times Bezier curve ( namely n=3) It is enough to fit the surface scene text in different formats , Especially in datasets with word level annotations . Higher order data may work better on text line level datasets , In a data set at the text line level, multiple waves may appear in one instance . In the experimental part , We have provided information about Bezier Comparison of the order of the curve . Three times Bezier The diagram of the curve is shown in Figure 3 Shown .
It's binomial coefficient . For use Bezier Curve fitting arbitrary shaped text , We examine the scene text with arbitrary shape from the existing data set , And it has been proved by experience for three times Bezier curve ( namely n=3) It is enough to fit the surface scene text in different formats , Especially in datasets with word level annotations . Higher order data may work better on text line level datasets , In a data set at the text line level, multiple waves may appear in one instance . In the experimental part , We have provided information about Bezier Comparison of the order of the curve . Three times Bezier The diagram of the curve is shown in Figure 3 Shown .
Based on three times Bezier curve , We can reduce the problem of text detection in arbitrary shaped scenes to a regression problem similar to bounding box regression , But there are a total of eight control points . Please note that , With four control points ( Four peaks ) The straight text of is a typical case of arbitrary shape scene text . For consistency , We interpolate two additional control points on the triangular points of each long side . In order to learn the coordinates of the control point , We first generate §3.1.1 Described in the Bezier Curve notes , And follow [34] The similar regression method in . For each text instance , We use
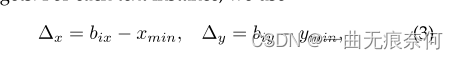
among Xmin and Ymin respectively 4 The smallest of vertices x and y value . The advantage of predicting relative distance is that it is related to Bezier Whether the curve control point exceeds the image boundary is irrelevant . Inside the detection head , We only use one convolution layer and 4 individual (n+1)(n by Bezier Degree of curve ) Output channel to learn Δx and Δy, This is almost free , And the result is still accurate . We are §4 Details are discussed in .
3.1.1 Bessel ground truth generation
In this section , We briefly introduced how to generate Bezier Curve ground truth . Data sets of arbitrary shape , for example total-text[41] and scutctw1500[42], Use polygon annotation for text areas . Annotation points on the boundary of a given curve {pi}n i=1, among pi It means the first one i Notes , The main purpose is to find the equation (1) Three times Bezier curve c(t) The optimal parameters of the system . To achieve this , We can simply apply standard least square fitting , As shown below :
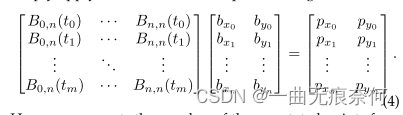
here m The number of annotation points representing the curve boundary . about Total-Text and SCUT-CTW1500,m Respectively 5 and 7. t It is calculated by using the ratio of cumulative length to broken line perimeter . According to the type (1) Sum formula (4), We convert the original polyline annotation into a parameterized Bezier curve . Please note that , We directly use the first and last comment points as the first (b0) And the last (bn) The control points . The visual comparison is shown in the figure 1 Shown , This shows that the generated results can be even better visually than the original annotations . Besides , Due to structured output , We can apply our BezierAlign( See §3.3) Easily formulate text recognition tasks , It distorts the curved text into a horizontal representation . More results generated by Bezier curve are shown in Figure 4 Shown . The simplicity of our method enables it to deal with various shapes in a unified representation format .
3.2 COORDCONV
Such as [14] As pointed out in , I'm learning (x,y) Mapping between coordinates in Cartesian space and coordinates in hot pixel space , Conventional convolution shows local limitations . This problem can be effectively solved by connecting the coordinates to the feature map . Recent practice of coding relative coordinates [15] Also shows , Relative coordinates can provide information tips for instance segmentation .Let fouts Express FPN The characteristics of different proportions ,Oi,x and Oi,y respectively FPN Of the i All positions of level ( That is, the position of the generated filter ) Absolute x and y coordinate . all Oi,x and Oi,y By two characteristic graphs fox and foy form . We're just gonna fox and foy Connect to the last one along the channel dimension fouts passageway . therefore , A new feature with two additional channels is formed , Then input it into three convolution layers , Its kernel size , The stride and fill size are set to 3、1 and 1. We found that , Using this simple coordinate convolution can greatly improve the performance of scene text location .
3.3bezieralign
In order to achieve end-to-end training , Most of the previous methods used various sampling ( Feature alignment ) Method to connect and identify branches . Usually , The sampling method represents the region clipping process in the network . in other words , Given a feature graph and region of interest (RoI), Use the sampling method to extract RoI Characteristics of , And efficiently output a fixed size feature graph . However , Previous sampling methods based on non segmented methods , for example RoI pool [3]、ROIROATE[5]、 Text alignment sampling [4] or RoI Transformation [75], Unable to correctly align the features of arbitrarily shaped text . By utilizing structured Bezier Parametric properties of curve bounding box , We have put forward BezierAlign For feature sampling / alignment , This can be seen as RoAlign Flexible expansion of [82]. And RoIAlign Different ,BezierAlign The shape of the sampling grid of is not rectangular . contrary , Each column of an arbitrary shape grid is orthogonal to the Bezier curve boundary of the text . The sampling points are equidistant in width and height , This is bilinear interpolation relative to coordinates .
Formally , Given input feature mapping and Bezier Curve control points , The size of Hout×Wout All output pixels of the rectangular output feature map are processed . With position (GIW,GIH) The pixels of the output feature map Gi For example , We calculated T as follows :

And then according to the formula (1) Calculate the upper Bezier Curve boundary tp And Bezier Curve boundary bp The point of . utilize TP and BP, We can use the formula (6) For sampling points OP Linear indexing :
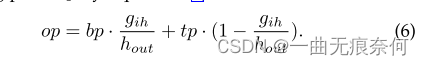
utilize OP The location of , We can easily apply bilinear interpolation to calculate the result . Due to the accurate sampling of features , The performance of text recognition has been substantially improved . We will bezieralign Compared with other sampling strategies , Pictured 5 Shown .


3.4 Attention based recognition Branch
From shared trunk features and Bezieralign Benefit from , We designed a lightweight recognition Branch , As shown in the table 1 Shown , In order to execute . It consists of 6 Convolution layers 、1 Two way LSTM Layer and an attention based recognition module . In the conference version [16] in , We will CTC Loss [59] Applied to text string alignment between prediction and basic truth , But we found that the attention based recognition module [10]、[60]、[83]、[84] More powerful , Can lead to better results . At the inference stage , Use the detected Bezier Curve instead of ROI Area , Such as §3.1 Shown . Be careful , stay [16] in , We only use generated Bezier Curve to extract ROI features . In this paper , We also used the test results ( see §3.5).
Note that the mechanism adopts zero RNN The embedded features of initial state and initial symbol are used for sequence prediction . At each step , Use recursively C- Category Softmax forecast ( Indicates the characteristics of the prediction )、 Previous hidden state and cropped Bezier Calculate the result by the weighted sum of curve features . The forecast continues , Until the prediction reaches the end of the sequence (EOS) Symbol . The class size of English courses is set to 96 people ( barring EOS Symbol ), The class size of bilingual courses is set to 5462 people . Formally , In the time step t in , The attention weight is calculated by the following method :

among ,HT-1 Is the last hidden state ,K、W、U and B Is a learnable weight matrix and parameters . The weighted sum of sequence eigenvectors is expressed as :
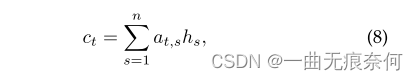
among at,s Defined as :
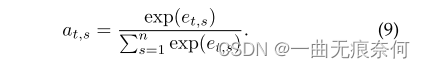
then , Hidden status can be updated , As shown below :
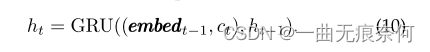
here ,Embedt-1 Is the previous decoding result generated by the classifier yt Embedding vector of :

surface 1- Identify the structure of the branch , This is a CRNN Simplified version of [58]. For all convolutions , The fill size is limited to 1. n Indicates the batch size . C Indicates the channel size . h and w Represents the height and width of the output feature map ,nclass Indicates the number of prediction classes .

therefore , We use it Softmax Function to estimate the probability distribution P(ut).
![]()
among v Represents the parameter to learn . In order to stabilize the training , We also use teacher coercion [85], In our implementation , The predefined probability is set to 0.5 Under the circumstances , This strategy passes a basic fact character instead of the next predicted GRU forecast .
3.5 Adaptive end-to-end training
In our conference version [16] in , We only use the basic truth in the training stage Bezieralign For text recognition Branch . In the test phase , Use the detection results to cut features . According to the observations , When the test result is not as good as the ground truth Bezier When the curve bounding box is accurate , There may be some errors . To alleviate these problems , We propose a simple and effective strategy , It is called adaptive end-to-end training (AET). In form , First, the confidence threshold is used to suppress the detection results , And then use NMS Eliminate redundant test results . then , The minimum sum of distances based on the coordinates of control points , Assign the corresponding recognition ground truth value to each test result :
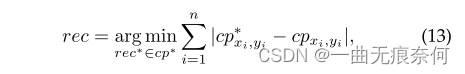
among cp* Is the ground truth value of the control point . n Is the number of control points . After identifying and marking the test results , We simply connect the new target to the original ground truth set for further recognition training .
3.6 Text location quantification
Scene text reading applications usually require real-time ; However , Few studies have tried to apply quantization technology to scene text recognition . The purpose of model quantification is to do without affecting the network performance , The full precision tensor is discretized into a low bit tensor . A limited number of representation levels ( Quantization level ) You can use . The quantized bit width is B The bit , The number of quantization levels is 2B. It's easy to see , As the quantization bit width decreases , Deep learning models may suffer significant performance degradation . To maintain accuracy , Discretization error should be minimized :
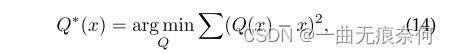
among q(x) Is a quantized function . stay LSQ[86] Inspired by , This paper adopts the following equation as the activation quantifier . To be specific , For the tensor from activation xa Any data for xa, Its quantitative value q(xa) It is calculated through a series of transformations .
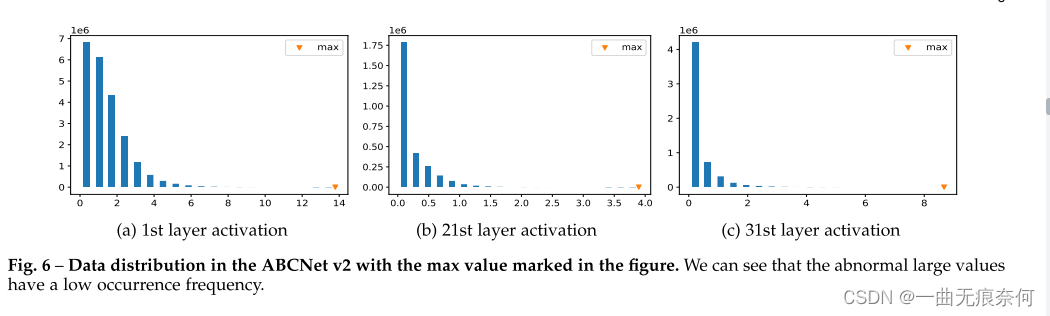
First , Just like the work contract [87] Pointed out , Not all full precision data should be mapped linearly to quantized values . It is common to find some abnormal large values , It rarely appears in the full precision tensor . We are in the picture 6 Further visualization in ABCNet v2 Data distribution in some layers , A similar phenomenon was observed . therefore , Assign a learnable parameter αa To dynamically describe the discretization range , And trim the excess data to the boundary :
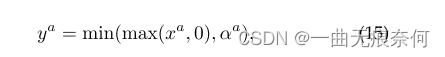
secondly , Clipping range ( The so-called quantitative interval ) The data in is linearly mapped to nearby integers , Like the equation (16) Shown :
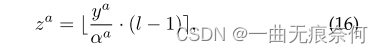
among l=2b Is the number of quantization levels mentioned above ,· Is the nearest rounding function . Third , In order to keep the data amplitude similar before and after quantification , We are ZA Apply the corresponding scale factor , Get Q(xa):
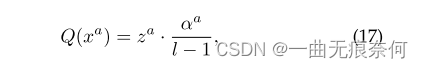
All in all , The quantification of activation can be written as :
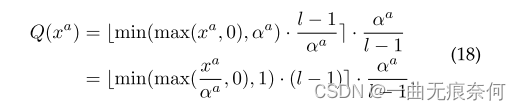
Unlike activation , Weight parameters usually contain positive and negative values , Therefore, an additional linear transformation is introduced before discretization , As shown below :
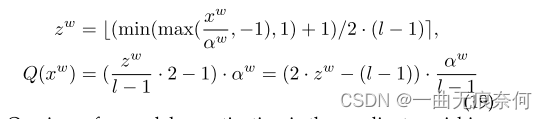
One problem in model quantification is the disappearance of gradients caused by circular functions (·). This is because circular functions have zero gradients almost everywhere . Use a pass through estimator (STE) To solve this problem . say concretely , We constantly rewrite the derivative of the rounding function as 1(∂· = 1). We use a small batch gradient descent optimizer to train quantization related parameters in each layer αa and αw And the original parameters from the network . Attention should be paid to , For each convolution layer , Its quantitative introduction parameters αa and αw Input activation tensor Xa And weight tensor Xw All elements in share . therefore , The computing order can be exchanged during network forward propagation , Like the equation 20 Shown , For better efficiency . By exchange , The time-consuming convolution calculation operates only in integer format ( All the elements za∈ Za and zw∈ Zw yes b An integer ). therefore , Compared with the corresponding floating-point type , You can delay 、 Realize advantages in memory occupation and energy consumption .
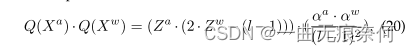
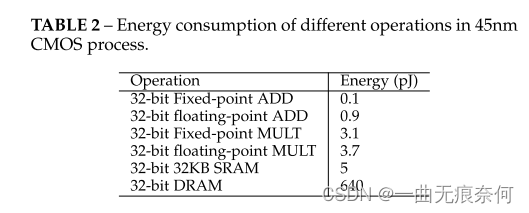
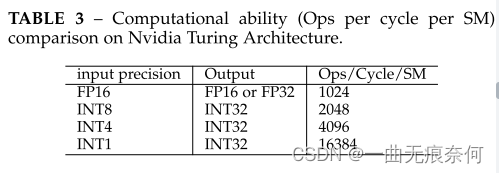
Theoretically , about b Bit quantization network , Input activation and weight can save 32 b × Memory . For energy consumption , We are on the table 2 The estimated energy costs for different types of on-chip operations are listed in . We can see , floating-point ADD and MULT The energy consumption cost of is far greater than that of fixed-point operation . Besides , And ALU Operation comparison ,DRAM Access consumes an order of magnitude more energy . therefore , Obviously , Compared with the full accuracy model , Quantitative models may save a lot of energy . In terms of reasoning delay , The actual acceleration of quantitative model to full precision model depends on the computing power of fixed-point arithmetic and floating-point arithmetic on the platform . surface 3 Shows Nvidia Turing Architecturally, each SM Operation of each cycle . We can get it from the table 3 I learned that , Compared with the full precision counterpart on the platform ,8 Bit networks are possible 2 Double acceleration . What's more impressive is ,4 Bit networks and binary neural networks (1 position ) The running speed of the model is faster than that of the full precision model 4 Times and 16 times .
4、 experiment
To evaluate ABCNet V2 The effectiveness of the , We have carried out experiments on a variety of scene text benchmarks , Including multi aspect scene text benchmark ICDAR'15[32]、MSRA-TD500[26]、RECTS[39] And two arbitrary shape benchmarks Total-Text[41] and SCUT-CTW1500[42]. stay Total-Text and SCUT-CTW1500 Ablation studies were carried out on , To verify each component of our proposed method .
4.1 Details of the experiment
Unless otherwise stated , Otherwise, the backbone working here follows the same general settings as most previous work , namely ResNet-50 [88] And feature pyramid network (FPN) [89]. For detecting branches , We are 5 Application on characteristic graph RoIAlign, The resolution is... Of the input image respectively 1/8、1/16、1/32、1/64 and 1/128, For identifying branches ,BezierAlign On the three feature maps, the sizes are 1/4、1/8 and 1/16, The width and height of the sampling grid are set to 8 and 32. For pure English datasets , Pre training data are collected from publicly available data sets based on English word levels , Including the... Described in the next section 150K Synthetic data 、7K ICDARMLT data [38] And the corresponding training data of each data set . Then fine tune the pre training model on the training set of the target data set . Please note that , Our previous manuscript [16] Medium 15k COCO-Text [90] The image is not used in this improved version . about ReCTS Data sets , We use LSVT [91]、ArT [92]、ReCTS [39] And synthetic pre training data to train the model . Besides , We also adopted a data enhancement strategy , For example, random scale training , Short size from 640 To 896( The interval is 32) The only choice , The length size is less than 1600; And random clipping , We ensure that cropped images do not cut text instances ( For some special cases that are difficult to meet the conditions , We don't apply random clipping ). We use 4 individual Tesla V100 GPU Train our models , The image batch size is 8. The maximum number of iterations is 260K; The initial learning rate is 0.01, In the 160K In the next iteration, it is reduced to 0.001, In the 220K In the next iteration, it is reduced to 0.0001.

4.2 The benchmark
Bezier Curve synthesis dataset 150k. For end-to-end scenario text discovery methods , Always need a lot of free synthetic data . however , The existing 800k SynText Data sets [93] Only a quadrilateral bounding box is provided for most straight text . In order to diversify and enrich the scene text of any shape , We made some efforts , use VGG The synthesis method synthesized 150K A data set of images (94,723 The image contains most of the straight text ,54,327 The image contains most of the curved text ) [93]. Specially , We from COCO-text [90] And we've screened out 40k No text background image , Then prepare the segmentation mask and scene depth of each background image for the following text rendering . In order to expand the shape diversity of synthetic text , We use various artistic fonts and corpus to synthesize scene text to modify VGG Synthesis method , And generate polygon annotations for all text instances . then , adopt § 3.1.1 The generation method described in , Use comments to generate Bezier Basic truth of curve . Our comprehensive data example is shown in the figure 8 Shown . For Chinese pre training , We synthesized 100K Images , Some examples are shown in the figure 9 Shown .
Total-Text Data sets [41] yes 2017 One of the most important arbitrary shape scene text benchmarks proposed in , It is collected from various scenes , Including text like scene complexity and low contrast background . It contains 1,555 Zhang image , among 1,255 Zhang is used for training ,300 Zhang for testing . In order to simulate the real world scene , Most of the images in this dataset contain a large amount of regular text , At the same time, ensure that each image has at least one curved text . Text instances are annotated with polygons based on word levels . An extended version of it [41] Improve the annotation of the training set by annotating each text instance with a fixed ten points after the text recognition sequence . The dataset contains only English text . To evaluate end-to-end results , We follow the same metrics as the previous methods , Use F-measure To measure the accuracy of words . SCUT-CTW1500 Data sets [42] yes 2017 Another important arbitrary shape scene text benchmark proposed in . And Total-Text comparison , The dataset contains English and Chinese texts . Besides , Comments are based on the text line level , It also includes some text similar to documents , That is, many small texts may be stacked together . SCUT-CTW1500 contain 1k A training image and 500 A test image .
ICDAR2015 Data sets [32] Provides images accidentally captured in the real world . Compared with the previous ICDAR Data sets are different , In the past ICDAR Data set , The text is clean , Capture good , And horizontally centered in the image . The dataset includes 1000 Two training images and 500 A test image with complex background . Some text can also appear in any direction and in any position , Small size or low resolution . Annotation is based on word level , It only includes English samples .


MSRA-TD500 Data sets [26] contain 500 Zhang Duoxiang Chinese and English images , among 300 Images for training ,200 Images for testing . Most of the images were taken indoors . In order to overcome the shortage of training data , We use the synthetic Chinese data mentioned above for model pre training . ICDAR'19-ReCTs Data sets [39] contain 25k An annotated signboard image , among 20k Images for training set , The rest is for the test set . Compared with the English text , The number of categories of Chinese texts is usually much more , Common characters 6k many , The typesetting is complicated , There are so many Fonts . This data set mainly contains the text of the store logo , And provide comments for each character . ICDAR'19-ArT Data sets [92] It is currently the largest arbitrary shape scene text data set . It is Total-text and SCUT-CTW1500 The combination and extension of . The new image also contains at least one arbitrarily shaped text for each image . There are great differences in text direction . Art The data set is split into a training set , It includes 5,603 Two images and 4,563 For test set . All English and Chinese text instances are annotated with tight polygons . ICDAR'19-LSVT Data sets [91] It provides an unprecedented number of street view texts . It provides a total of 450k Images , Rich real scene information , among 50k Fully annotated (30k Used for training , rest 20k Used for testing ). And Art [92] similar , The dataset also contains some curved text annotated with polygons .

4.3 Melting research
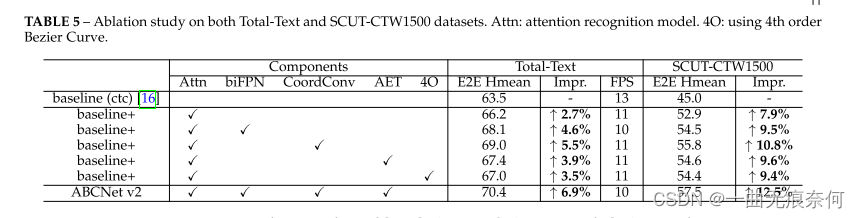
To evaluate the effectiveness of the proposed components , We conducted ablation studies on two datasets ,Total-Text and SCUT-CTW1500. We found that , Due to different initialization , There are some training errors . in addition , The task of text recognition requires that all characters can be correctly recognized . To avoid these problems , We train each method three times , And report the average results . Results such as table 5 Shown , It shows that all modules can significantly improve the baseline model on two data sets . We can see , Use an attention based recognition module , stay Total-Text and SCUT-CTW1500 The recognition results are improved respectively 2.7% and 7.9%. then , We use the attention based recognition branch to evaluate all other modules . Some conclusions are as follows :
Use biFPN framework , The result can be improved additionally 1.9% and 1.6%, The reasoning speed is only reduced 1 FPS. therefore , We have achieved a better balance between speed and accuracy .
• Use §3.2 Coordinate convolution mentioned in , The results on the two data sets can be significantly improved 2.8% and 2.9%. Please note that , This improvement will not introduce significant computational overhead .
• We also tested it §3.5 Mentioned in AET Strategy , The results improved 1.2% and 1.7%.
• Last , We conducted experiments to show how the order of Bessel curve affects the results . say concretely , We use 4 The order Bessel curve regenerates all basic facts for the same composite image and real image . then , We go back to the control point and use 4 rank BezierAlign To train ABCNet v2. Other parts remain the same as 3 The order settings are the same . surface 5 The results shown show that , Increasing the order is conducive to the text positioning results , Especially when using text line annotation SCUT-CTW1500 On . Under the same experimental setup , We are Totaltext Use... On datasets 5 rank Bezier The curve is further tested ; However , Compared to the baseline , We found out E2E Hmean for , Performance from 66.2% Down to 65.5%. According to observation , We assume that the decline may be because the extremely high order may lead to drastic changes in the control point , This may make it more difficult to return . Some results of using fourth-order Bessel curve are shown in Figure 10 Shown . We can see that the detection bounding box can be more compact , Thus, the text features can be trimmed more accurately for subsequent recognition .
We pass the will Bezieralign Compare with previous sampling methods to further evaluate it , Pictured 5 Shown . For a fair and quick comparison , We used a small training and testing scale . surface 4 The results shown in show that ,Bezieralign Can significantly improve end-to-end results . Qualitative examples are shown in the figure 11 Shown . Another ablation study is to evaluate Bezier Time consumption of curve detection , We observed that Bezier Compared with standard bounding box detection, curve detection only introduces negligible computational overhead .
4.4 Comparison with the most advanced level
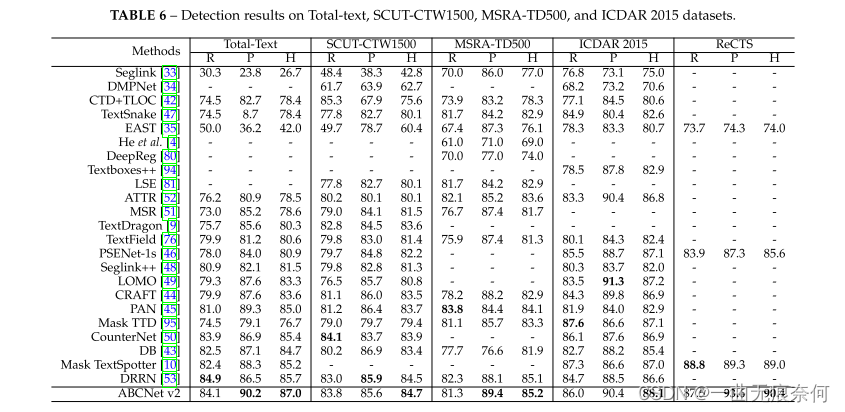
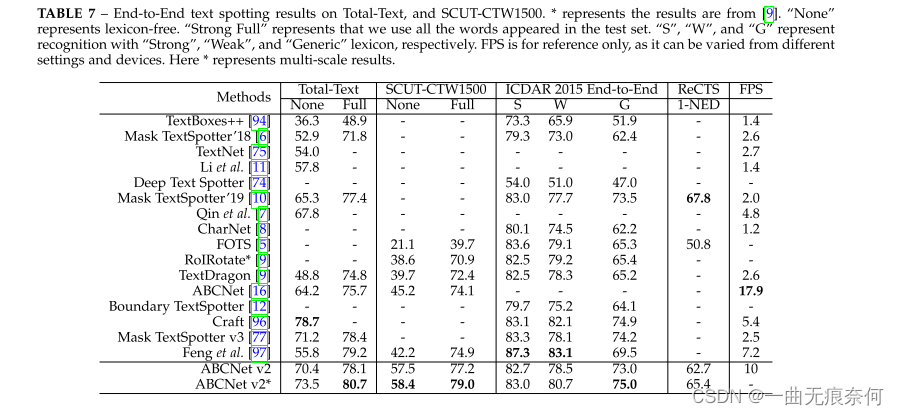
In detection and end-to-end text location tasks , We compared our method with the previous method . The optimal settings including reasoning threshold and test scale are determined by grid search . For test tasks , We did experiments on four datasets , Including two data sets of arbitrary shape (Total-Text and SCUT-CTW1500)、 Two multi oriented datasets (MSRA-TD500 and ICDAR2015) And a bilingual dataset RECTS. surface 6 The results in show that , Our method can achieve the most advanced performance on all four data sets , Better than the most advanced methods before .
For the end-to-end scene text positioning task ,ABCNet v2 stay SCUT-CTW1500 and ICDAR 2015 Best performance on datasets , Significantly better than previous methods . Results such as table 7 Shown . Although our method is RECTS On dataset 1-NED Aspect ratio Mask TextSpotter[10] Bad , But we don't think we are using the provided CharacterLevel Bounding box , Our method shows obvious advantages in reasoning speed . On the other hand , According to the table 6, And mask TextSpotter[10] comparison ,ABCNet v2 Better detection performance can still be achieved . The qualitative results of the test set are shown in Figure 7 Shown . We can see from the picture ,ABCNet v2 It realizes the powerful recall ability of various texts , Including levels 、 Multi faceted and curved text , Or long and dense text rendering style .
4.5 And Mask TextSpotter V3 A comprehensive comparison of
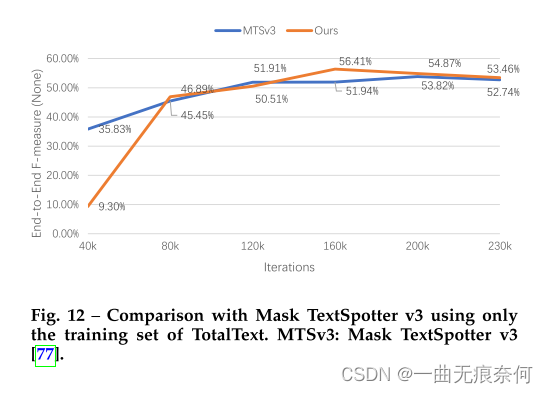
Use a small amount of data for comparison . We find that the proposed method can achieve promising localization results with only a small amount of training data . To verify effectiveness , We use Mask TextSpotter v3 [77] The official code of , And experiment according to the same settings , Use only TotalText Official training data training model . say concretely , Optimizer and learning rate of our method (0.002) Set to and Mask TextSpotter v3 identical . The batch size is set to 4, Both methods go through 23 Ten thousand iterations of training . To ensure the best setting of these two methods ,Mask TextSpotter v3 The minimum size of is 800、1000、1200 and 1400, The maximum size is 2333. Test with minimum size 1000 And maximum size 4000 Conduct . The minimum size of the method is 640 To 896, The interval is 32, The maximum size is set to 1600. In order to stabilize the training , Less sample training is not used AET Strategy . The minimum size of the test is 1000, The maximum size is 1824. We also do a grid search to find Mask TextSpotter v3 The optimal threshold of . The results of different iterations are shown in Figure 12 Shown . We can see , although Mask TextSpotter v3 At first, it converges faster , But the final result of our method is better (56.41% vs. 53.82%).



Use large-scale data for comparison . We also used enough training data to communicate with Mask TextSpotter V3 Make a more thorough comparison . In form , We use Bezier Curve synthesis dataset (150K)、MLT(7K) and TotalText Train carefully Mask TextSpotter V3, They are exactly the same as our method . Training scale 、 Batch size 、 The number of iterations and others are set to 4.1 The same as mentioned in section . Grid search is also used to mask TextSpotter V3 Find the best threshold . Results such as table 8 Shown , From which we can see Mask TextSpotter V3 stay F- Better than ABCNet V1 0.9,ABCNet V2 Can be better than Mask TextSpotter V3(65.1% Yes 70.4%). At the same test scale ( The maximum size is set to 1824) And equipment (RTX A40) The reasoning time is measured , The effectiveness of this method is further proved .
4.6 Finiteness
Further error analysis of the samples with wrong prediction . We observe two common mistakes , They may limit ABCNet v2 Scene text positioning performance .
The first one is shown in Figure 13 In the example . The text instance contains two characters . For each character , The reading order is from left to right . But for the whole example , The reading order is from top to bottom . because Bezier The curve is interpolated on the longer side of the text instance , therefore BezierAlign Compared with its original feature, the feature will be a rotating feature , This may lead to a completely different meaning . On the other hand , This situation only accounts for a small part of the whole training set , It is easy to be incorrectly identified or predicted as an invisible category , As in the second character “” Express . The second error appears in different fonts , Pictured 13 Shown in the middle . The first two characters are written in an unusual calligraphy font , Therefore, it is difficult to identify . Generally speaking , This challenge can only be alleviated by more training images . We also found that CTW1500 There is an extreme bending condition in the test set of , There are more than three peaks in the same text instance , Pictured 13 The third line of shows . under these circumstances , Low order such as cubic Bessel curve may be limited , Because the shape representation is not accurate , character “i” Incorrectly recognized as uppercase “I”. however , This is a rare case , Especially for data sets that use word level bounding boxes .

4.7 Speed of reasoning
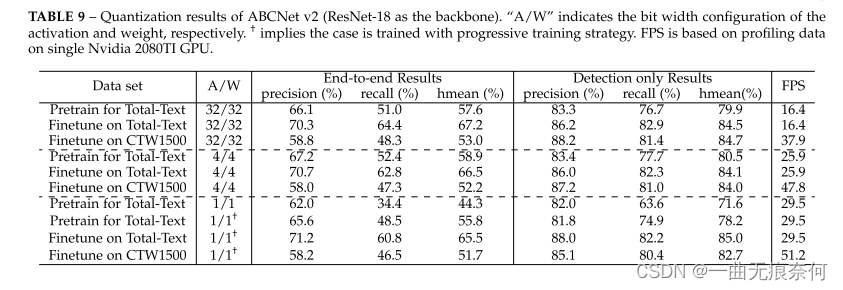
To further test the potential real-time performance of the proposed method , We use quantitative techniques to significantly improve the speed of reasoning . The baseline model uses the same settings as the baseline , With table 5 Attention based recognition branch shown in . The trunk is ResNet-18 replace , This significantly increases the speed , But it only reduces the marginal accuracy . surface 9 Various quantization bit configurations are reported in (4/1 position ) Quantify the performance of the network . Full accuracy performance is also listed for comparison . To train quantitative networks , We first pre train the low order model on the synthetic data set . then , We are in a dedicated dataset TotalText and CTW1500 Fine tune the network for better performance . The accuracy results of pre training model and fine tuning model are reported . During pre training , Trained 260K iteration , Batch size is 8. The initial learning rate is set to 0.01, stay 160K and 220K When iterating, divide by 10. about TotalText Fine tuning of data sets , Batch size remains 8, The initial learning rate is set to 0.001. Only fine tune 5K Sub iteration . stay CTW1500 When fine tuning on a dataset , The batch size and initial learning rate are the same . however , The total number of iterations is set to 120k, And in iteration 80k Learning rate divided by 10. Similar to previous quantitative work , We quantify all the convolution layers in the network , In addition to the input and output layers . If not specified , The network will be initialized with full precision counterparts .
From the table 9 in , We can see , Using our quantitative method 4 The bit model can achieve the same performance as the full precision model . for example , Pre trained on synthetic datasets 4 End to end of bit model hmean Even better than the full accuracy model (57.6% Yes 58.9%). After fine tuning ,TotalText and CTW1500 On 4 End to end of bit model hmean It is lower than the full precision model 0.7%(67.2% Yes 66.5%) and 0.8%(53.0% Yes 52.2%). in fact ,4 The performance of the bit model has hardly decreased ( The same observation was made in image classification and target detection tasks [98]), This shows that there is considerable redundancy in the full accuracy scene text location model . However , The performance of binary network has greatly decreased , End to end hmean Only for 44.3%. To compensate , We recommend using progressive training to train BNN( Binary neural network ) Model , The quantization bit width gradually decreases ( for example ,4bit→ 2 The bit → 1 position ). Use new training strategies ( The table contains † The strategy of ), The performance of binary networks has been significantly improved . for example , Use BNN The model is trained end-to-end on synthetic data sets hmean It is only higher than that of full precision hmean low 1.8%(57.6% Yes 55.8%). In addition to performance evaluation , We also compare the overall speed of the quantitative model and the full precision model . In practice , Only the quantitative convolution layer accelerates with other layers , For example, maintain complete accuracy LSTM. From the table 9 It can be seen that , With limited performance degradation ,ABCNet v2 The binary network of can run in real time TotalText and CTW1500 Data sets .
5 Conclusion
We proposed ABCNet V2-- A real-time end-to-end approach , It USES Bezier Curve to click the scene text of any shape . ABCNet V2 By parameterizing Bezier Curve reconstruction arbitrary shape scene text , Realized the use of Bezier Curve detection arbitrary shape scene text . Compared with standard bounding box detection , Our method introduces a negligible computational cost . Use this Bezier Curve bounding box , We can pass a new Bezieralign Layer naturally connects a lightweight recognition Branch , This is very important for accurately extracting features , Especially for curved text instances . The effectiveness of the proposed component is proved by comprehensive experiments on different data sets , Including the use of attention recognition module 、BIFPN structure 、 Coordinate convolution and a new adaptive end-to-end training strategy . Last , We propose to apply quantization technology to model deployment of real-time tasks , It shows a wide range of application potential .
边栏推荐
- The 32 year old programmer left and was admitted by pinduoduo and foreign enterprises. After drying out his annual salary, he sighed: it's hard to choose
- How to build an interface automation testing framework?
- What is the difference between TCP and UDP?
- 基于Pytorch肺部感染识别案例(采用ResNet网络结构)
- MySQL34-其他数据库日志
- PyTorch RNN 实战案例_MNIST手写字体识别
- 高并发系统的限流方案研究,其实限流实现也不复杂
- MNIST implementation using pytoch in jupyter notebook
- Security design verification of API interface: ticket, signature, timestamp
- The appearance is popular. Two JSON visualization tools are recommended for use with swagger. It's really fragrant
猜你喜欢
Not registered via @enableconfigurationproperties, marked (@configurationproperties use)
C miscellaneous lecture continued
MySQL35-主从复制
如何搭建接口自动化测试框架?
Mysql36 database backup and recovery
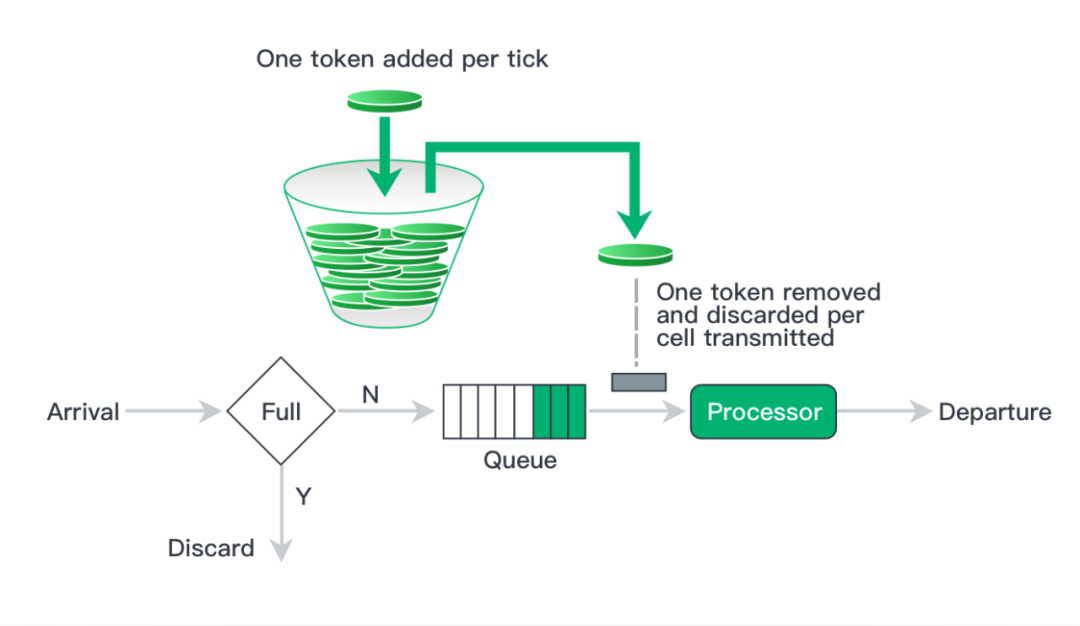
高并发系统的限流方案研究,其实限流实现也不复杂
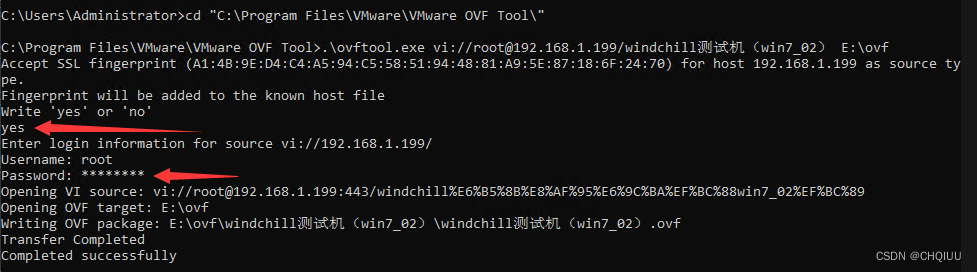
Export virtual machines from esxi 6.7 using OVF tool
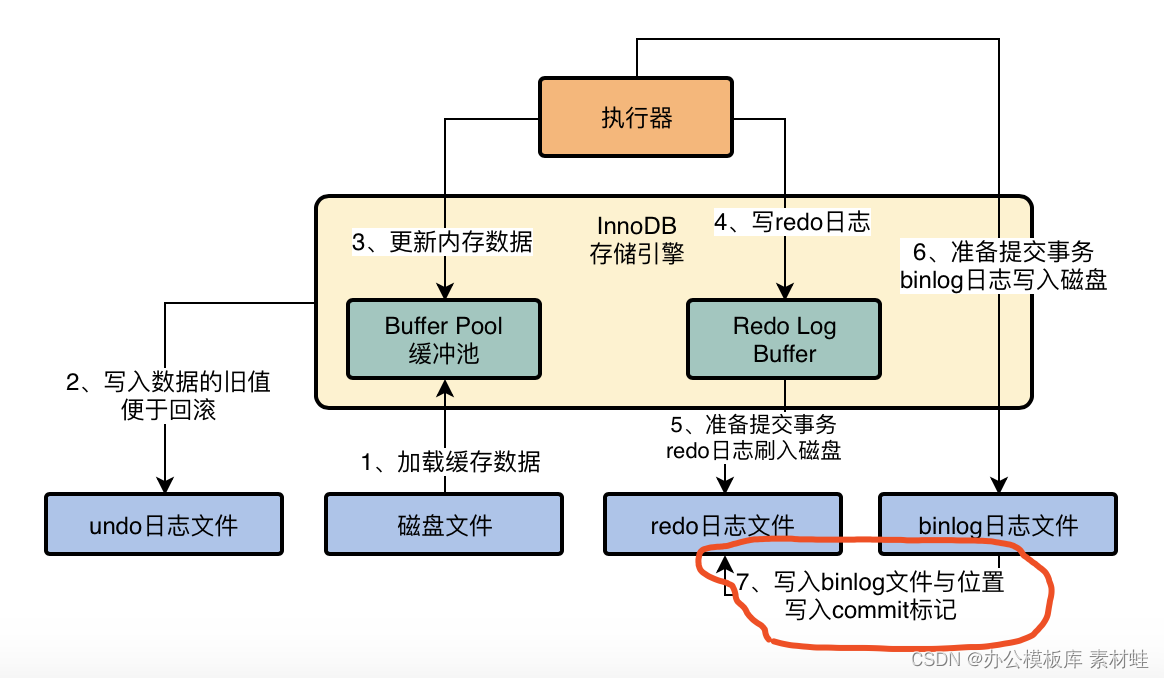
MySQL實戰優化高手04 借著更新語句在InnoDB存儲引擎中的執行流程,聊聊binlog是什麼?
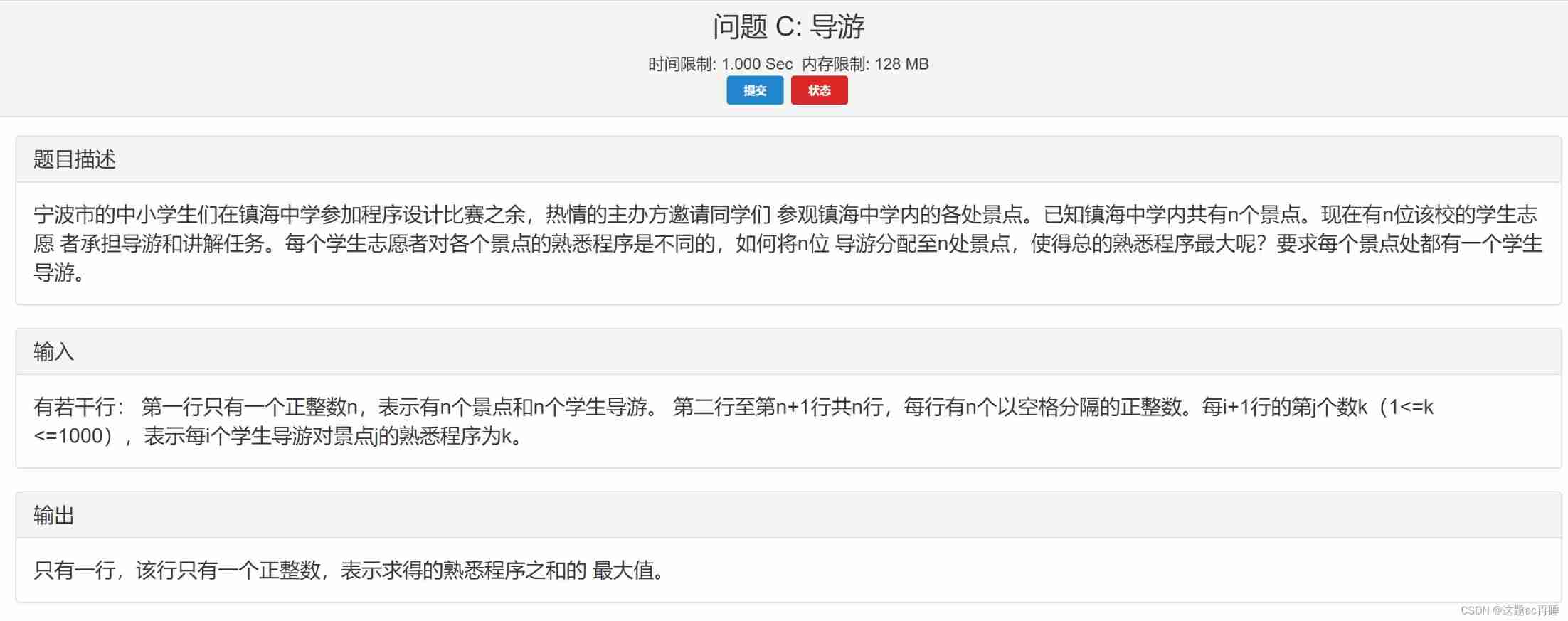
Contest3145 - the 37th game of 2021 freshman individual training match_ C: Tour guide
MySQL实战优化高手03 用一次数据更新流程,初步了解InnoDB存储引擎的架构设计
随机推荐
Nanny hand-in-hand teaches you to write Gobang in C language
MySQL實戰優化高手08 生產經驗:在數據庫的壓測過程中,如何360度無死角觀察機器性能?
15 医疗挂号系统_【预约挂号】
Write your own CPU Chapter 10 - learning notes
What is the difference between TCP and UDP?
text 文本数据增强方法 data argumentation
C miscellaneous dynamic linked list operation
Docker MySQL solves time zone problems
安装OpenCV时遇到的几种错误
Anaconda3 installation CV2
百度百科数据爬取及内容分类识别
四川云教和双师模式
MySQL storage engine
14 medical registration system_ [Alibaba cloud OSS, user authentication and patient]
What is the current situation of the game industry in the Internet world?
[after reading the series] how to realize app automation without programming (automatically start Kwai APP)
MySQL实战优化高手07 生产经验:如何对生产环境中的数据库进行360度无死角压测?
MySQL35-主从复制
Jar runs with error no main manifest attribute
Preliminary introduction to C miscellaneous lecture document