当前位置:网站首页>Case identification based on pytoch pulmonary infection (using RESNET network structure)
Case identification based on pytoch pulmonary infection (using RESNET network structure)
2022-07-06 10:25:00 【How about a song without trace】
One 、 Overall process
1. Dataset download address :https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia/download
2. Data set presentation

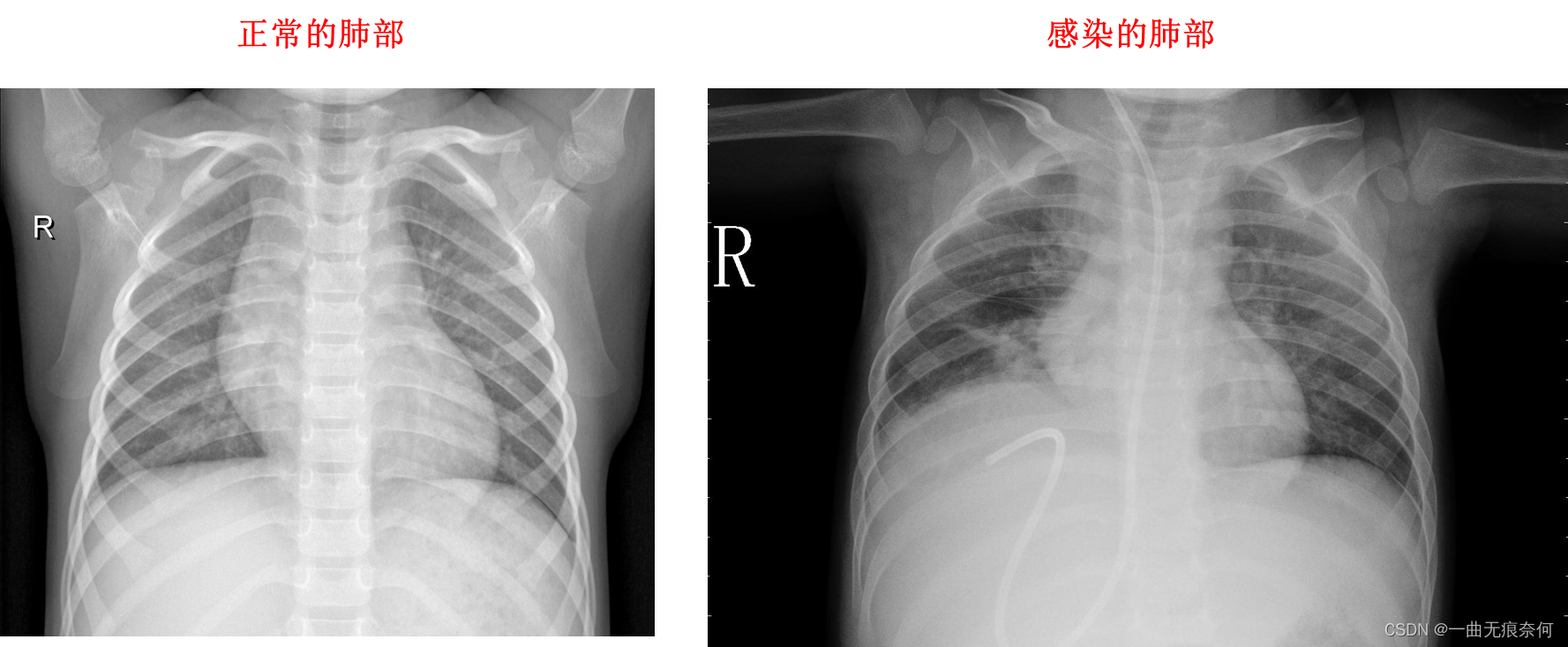
The main process of the case :
First step : Load pre training model ResNet, The model has been used in ImageNet Trained in .
The second step : Freeze the parameters of the lower convolution layer in the pre training model ( The weight ).
The third step : Replace the classification layer with a multi-layer of trainable parameters .
Step four : Train the classification layer on the training set .
Step five : Fine tune the super parameters , Thaw more layers as needed .
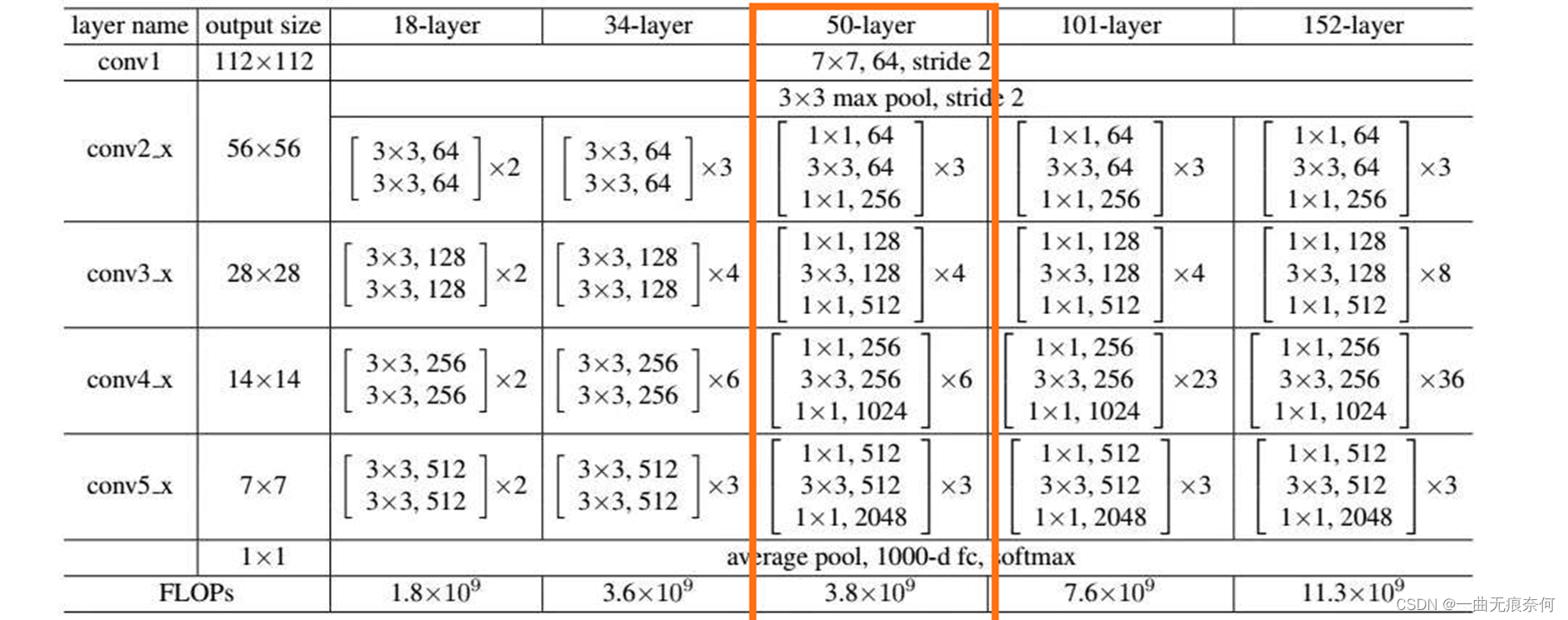
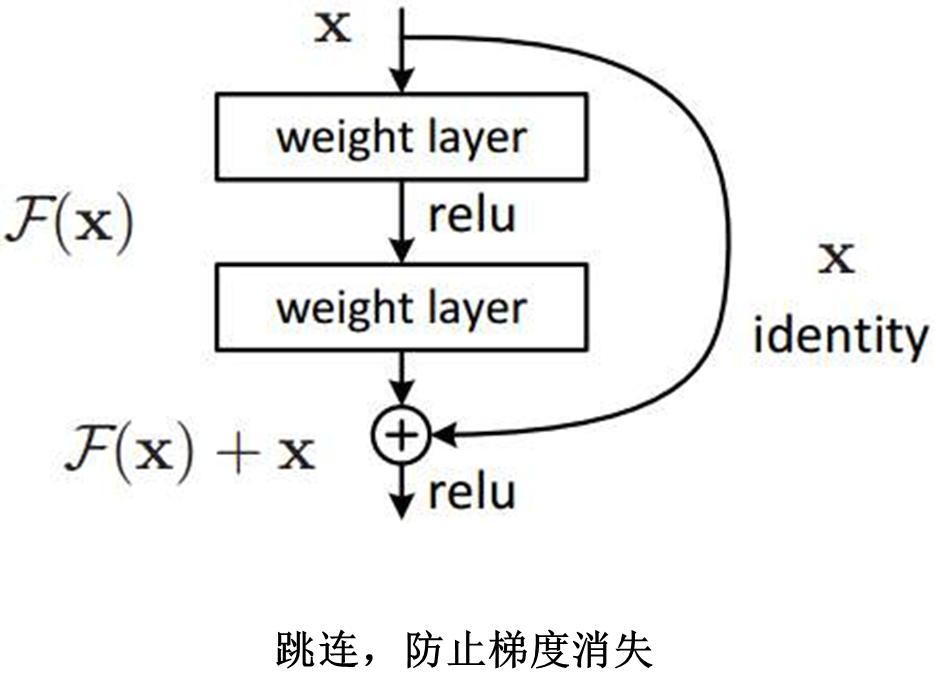
ResNet Network structure chart
Two 、 Display picture function
#1 Load the library
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
import os
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
#2、 Define a method : display picture
def img_show(inp, title=None):
plt.figure(figsize=(14,3))
inp = inp.numpy().transpose((1,2,0)) # Turn into numpy, And then transpose
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224,0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
plt.show()
def main():
pass
#3、 Define super parameters
BATCH_SIZE = 8
DEVICE = torch.device("gpu" if torch.cuda.is_available() else "cpu")
#4、 Picture conversion Use a dictionary for conversion
data_transforms = {
'train': transforms.Compose([
transforms.Resize(300),
transforms.RandomResizedCrop(300) ,# Random cutting
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(256),
transforms.ToTensor(), # Into a tensor
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) # Regularization
]),
'val': transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(), # Into a tensor
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) # Regularization
])
}
#5、 Operating data sets
# 5.1、 Dataset path
data_path = "D:/chest_xray/"
#5.2、 Loading data sets train val
img_datasets = { x : datasets.ImageFolder(os.path.join(data_path,x),
data_transforms[x]) for x in ["train","val"]}
#5.3、 Create an iterator for the dataset , Reading data
dataloaders = {x : DataLoader(img_datasets[x], shuffle=True,
batch_size= BATCH_SIZE) for x in ["train","val"]
}
# 5.4、 Size of training set and verification set ( Number of pictures )
data_sizes = {x : len(img_datasets[x]) for x in ["train","val"]}
# 5.5、 Get label category name NORMAL normal -- PNEUMONIA infection
target_names = img_datasets['train'].classes
#6 Display a batch_size Pictures of the (8 A picture )
#6.1 Read 8 A picture
datas ,targets = next(iter(dataloaders['train'])) #iter Turn the object into an iteratable object ,next Go iterate
#6.2、 Flatten several positive pictures into an image
out = make_grid(datas, norm = 4, padding = 10)
#6.3 display picture
img_show(out, title=[target_names[x] for x in targets]) #title Get category , That is, labels
if __name__ == '__main__':
main()The function of the above code is to show image samples ( To be continued )
Show sample pictures in the dataset :
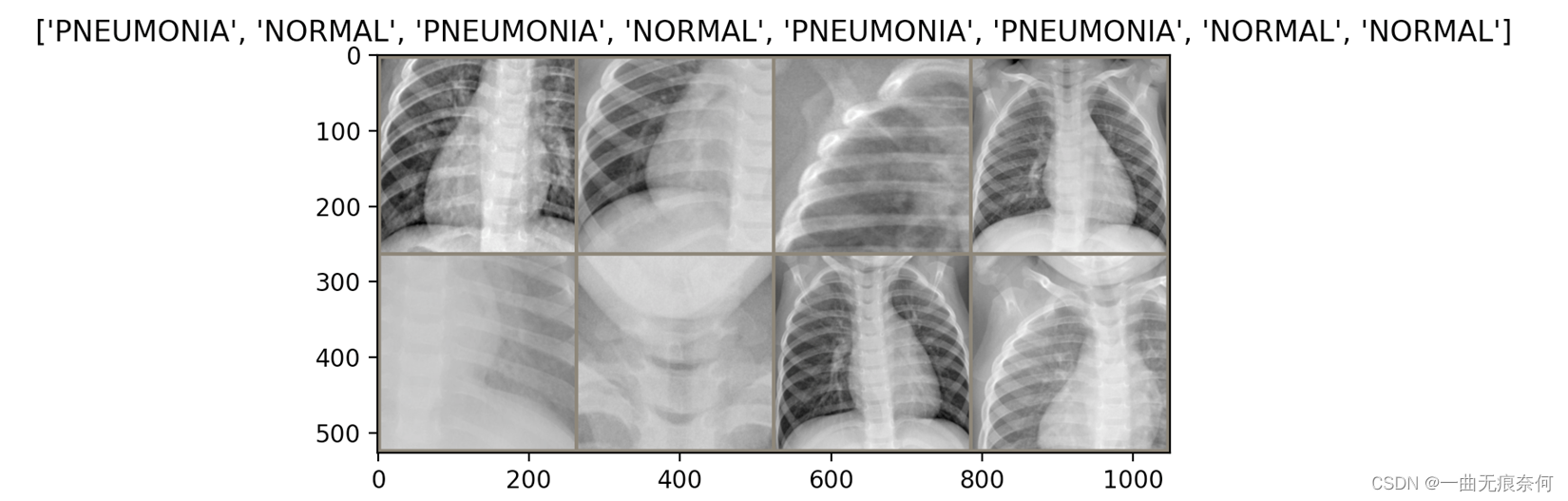
3、 ... and 、 The migration study , Fine tune the model
The migration study (Transfer learning) It is to transfer the trained model parameters to the new model to help the new model training .
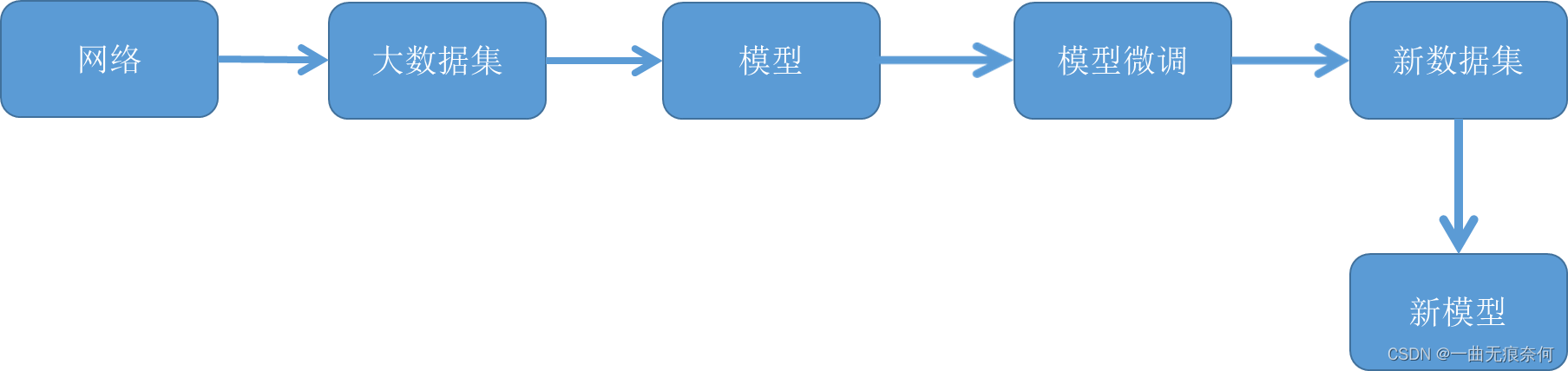
The following code uses Jupyter NoteBook
Case study : Lung tests
# 1 Add the necessary Libraries
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, transforms, utils, models
import time
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torch.utils.tensorboard.writer import SummaryWriter
import os
import torchvision
import copy
# 2 Load data set
# 2.1 Image change settings
data_transforms = {
"train":
transforms.Compose([
transforms.RandomResizedCrop(300),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
"val":
transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test':
transforms.Compose([
transforms.Resize(size=300),
transforms.CenterCrop(size=256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224,
0.225])
]),
}
# 3 Visualizations
def imshow(inp, title=None):
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# 6 Visual model prediction
def visualize_model(model, num_images=6):
""" Display the predicted picture results
Args:
model: The model after training
num_images: Number of pictures to display
Returns:
nothing
"""
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (datas, targets) in enumerate(dataloaders['val']):
datas, targets = datas.to(device), targets.to(device)
outputs = model(datas) # Forecast data
_, preds = torch.max(outputs, 1) # Get the maximum value of each row of data
for j in range(datas.size()[0]):
images_so_far += 1 # Cumulative number of pictures
ax = plt.subplot(num_images // 2, 2, images_so_far) # display picture
ax.axis('off') # Turn off the axis
ax.set_title('predicted:{}'.format(class_names[preds[j]]))
imshow(datas.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
# 7 Define training function
def train(model, device, train_loader, criterion, optimizer, epoch, writer):
# effect : Declare in model training , use Batch Normalization and Dropout
# Batch Normalization : Normalize each layer in the middle of the network , Ensure that the extracted feature distribution of each layer will not be destroyed
# Dropout : Reduce overfitting
model.train()
total_loss = 0.0 # The total loss is initialized to 0.0
# Read training data circularly , Update model parameters
for batch_id, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # The gradient is initialized to zero
output = model(data) # Output after training
loss = criterion(output, target) # Calculate the loss
loss.backward() # Back propagation
optimizer.step() # Parameters are updated
total_loss += loss.item() # Accumulated loss
# Write to the log
writer.add_scalar('Train Loss', total_loss / len(train_loader), epoch)
writer.flush() # Refresh
return total_loss / len(train_loader) # Returns the average loss value
# 8 Define test functions
def test(model, device, test_loader, criterion, epoch, writer):
# effect : Declare in model training , Do not use Batch Normalization and Dropout
model.eval()
# Loss and correctness
total_loss = 0.0
correct = 0.0
# Loop read data
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# Forecast output
output = model(data)
# Calculate the loss
total_loss += criterion(output, target).item()
# Obtain the subscript with the largest probability of each row of data in the prediction result
_,preds = torch.max(output, dim=1)
# pred = output.data.max(1)[1]
# Accumulate the number of correct predictions
correct += torch.sum(preds == target.data)
# correct += pred.eq(target.data).cpu().sum()
######## increase #######
misclassified_images(preds, writer, target, data, output, epoch) # Record pictures of misclassification
# Total loss
total_loss /= len(test_loader)
# Accuracy rate
accuracy = correct / len(test_loader)
# Write to the log
writer.add_scalar('Test Loss', total_loss, epoch)
writer.add_scalar('Accuracy', accuracy, epoch)
writer.flush()
# Output information
print("Test Loss : {:.4f}, Accuracy : {:.4f}".format(total_loss, accuracy))
return total_loss, accuracy
# Defined function , obtain Tensorboard Of writer
def tb_writer():
timestr = time.strftime("%Y%m%d_%H%M%S")
writer = SummaryWriter('logdir/' + timestr)
return writer
# 8 Fine tuning the model
# Define a pooled layer processing function
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, size=None):
super().__init__()
size = size or (1,1) # The convolution kernel size of the pool layer , The default value is (1,1)
self.pool_one = nn.AdaptiveAvgPool2d(size) # Pooling layer 1
self.pool_two = nn.AdaptiveMaxPool2d(size) # Pooling layer 2
def forward(self, x):
return torch.cat([self.pool_one(x), self.pool_two(x)], 1) # Connect two pooling layers
def get_model():
model_pre = models.resnet50(pretrained=True) # Get pre training model
# Freeze all parameters in the pre training model
for param in model_pre.parameters():
param.requires_grad = False
# Replace ResNet The last two layers of network , Return a new model ( The migration study )
model_pre.avgpool = AdaptiveConcatPool2d() # Pool layer replacement
model_pre.fc = nn.Sequential(
nn.Flatten(), # All dimensions are leveled
nn.BatchNorm1d(4096), # Regularization processing
nn.Dropout(0.5), # Lose neurons
nn.Linear(4096, 512), # Linear layer processing
nn.ReLU(), # Activation function
nn.BatchNorm1d(512), # Regularization processing
nn.Dropout(p=0.5), # Lose neurons
nn.Linear(512, 2), # Linear layer
nn.LogSoftmax(dim=1) # Loss function
)
return model_pre
def train_epochs(model, device, dataloaders, criterion, optimizer, num_epochs, writer):
"""
Returns:
Return to the best model after training
"""
print("{0:>20} | {1:>20} | {2:>20} | {3:>20} |".format('Epoch', 'Training Loss', 'Test Loss', 'Accuracy'))
best_score = np.inf # Assume the best prediction
start = time.time() # Starting time
# Start reading data circularly for training and verification
for epoch in num_epochs:
train_loss = train(model, device, dataloaders['train'], criterion, optimizer, epoch, writer)
test_loss, accuracy = test(model, device, dataloaders['val'], criterion, epoch, writer)
if test_loss < best_score:
best_score = test_loss
torch.save(model.state_dict(), model_path) # Save the model # state_dict Variables store the weights and bias coefficients that need to be learned in the training process
print("{0:>20} | {1:>20} | {2:>20} | {3:>20.2f} |".format(epoch, train_loss, test_loss, accuracy))
writer.flush()
# The total time spent after training
time_all = time.time() - start
# Output time information
print("Training complete in {:.2f}m {:.2f}s".format(time_all // 60, time_all % 60))
def train_epochs(model, device, dataloaders, criterion, optimizer, num_epochs, writer):
"""
Returns:
Return to the best model after training
"""
print("{0:>20} | {1:>20} | {2:>20} | {3:>20} |".format('Epoch', 'Training Loss', 'Test Loss', 'Accuracy'))
best_score = np.inf # Assume the best prediction
start = time.time() # Starting time
# Start reading data circularly for training and verification
for epoch in num_epochs:
train_loss = train(model, device, dataloaders['train'], criterion, optimizer, epoch, writer)
test_loss, accuracy = test(model, device, dataloaders['val'], criterion, epoch, writer)
if test_loss < best_score:
best_score = test_loss
torch.save(model.state_dict(), model_path) # Save the model # state_dict Variables store the weights and bias coefficients that need to be learned in the training process
print("{0:>20} | {1:>20} | {2:>20} | {3:>20.2f} |".format(epoch, train_loss, test_loss, accuracy))
writer.flush()
# The total time spent after training
time_all = time.time() - start
# Output time information
print("Training complete in {:.2f}m {:.2f}s".format(time_all // 60, time_all % 60))
def misclassified_images(pred, writer, target, data, output, epoch, count=10):
misclassified = (pred != target.data) # Record the difference between the predicted value and the real value True and False
for index, image_tensor in enumerate(data[misclassified][:count]):
# Show different predictions before 10 A picture
img_name = '{}->Predict-{}x{}-Actual'.format(
epoch,
LABEL[pred[misclassified].tolist()[index]],
LABEL[target.data[misclassified].tolist()[index]],
)
writer.add_image(img_name, inv_normalize(image_tensor), epoch)
# 9 Training and validation
# Define super parameters
model_path = 'model.pth'
batch_size = 16
device = torch.device('gpu' if torch.cuda.is_available() else 'cpu') # gpu and cpu choice
# 2.2 Load data
data_path = "D:/chest_xray/" # The folder path where the dataset is located
# 2.2.1 Load data set
image_datasets = {x : datasets.ImageFolder(os.path.join(data_path, x), data_transforms[x]) for x in ['train', 'val', 'test']}
# 2.2.2 Create... For the dataset iterator
dataloaders = {x : DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'val', 'test']}
# 2.2.3 Size of training set and verification set
data_sizes = {x : len(image_datasets[x]) for x in ['train', 'val', 'test']}
# 2.2.4 The tag corresponding to the training set
class_names = image_datasets['train'].classes # Altogether 2 individual :NORMAL normal vs PNEUMONIA Pneumonia
LABEL = dict((v, k ) for k, v in image_datasets['train'].class_to_idx.items())
print("-" * 50)
# 4 obtain trian A batch of data in
datas, targets = next(iter(dataloaders['train']))
# 5 Display this batch of data
out = torchvision.utils.make_grid(datas)
imshow(out, title=[class_names[x] for x in targets])
# take tensor Convert to image
inv_normalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.255]
)
writer = tb_writer()
images, labels = next(iter(dataloaders['train'])) # Get a batch of data
grid = torchvision.utils.make_grid([inv_normalize(image) for image in images[:32]]) # Read 32 A picture
writer.add_image('X-Ray grid', grid, 0) # Add to TensorBoard
writer.flush() # Read data into memory
model = get_model().to(device) # Get the model
criterion = nn.NLLLoss() # Loss function
optimizer = optim.Adam(model.parameters())
train_epochs(model, device, dataloaders, criterion, optimizer, range(0,10), writer)
writer.close()
# 9 Training and validation
# Define super parameters
model_path = 'model.pth'
batch_size = 16
device = torch.device('gpu' if torch.cuda.is_available() else 'cpu') # gpu and cpu choice
# 2.2 Load data
data_path = "D:/chest_xray/" # The folder path where the dataset is located
# 2.2.1 Load data set
image_datasets = {x : datasets.ImageFolder(os.path.join(data_path, x), data_transforms[x]) for x in ['train', 'val', 'test']}
# 2.2.2 Create... For the dataset iterator
dataloaders = {x : DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'val', 'test']}
# 2.2.3 Size of training set and verification set
data_sizes = {x : len(image_datasets[x]) for x in ['train', 'val', 'test']}
# 2.2.4 The tag corresponding to the training set
class_names = image_datasets['train'].classes # Altogether 2 individual :NORMAL normal vs PNEUMONIA Pneumonia
LABEL = dict((v, k ) for k, v in image_datasets['train'].class_to_idx.items())
print("-" * 50)
# 4 obtain trian A batch of data in
datas, targets = next(iter(dataloaders['train']))
# 5 Display this batch of data
out = torchvision.utils.make_grid(datas)
imshow(out, title=[class_names[x] for x in targets])
# take tensor Convert to image
inv_normalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.255]
)
writer = tb_writer()
images, labels = next(iter(dataloaders['train'])) # Get a batch of data
grid = torchvision.utils.make_grid([inv_normalize(image) for image in images[:32]]) # Read 32 A picture
writer.add_image('X-Ray grid', grid, 0) # Add to TensorBoard
writer.flush() # Read data into memory
model = get_model().to(device) # Get the model
criterion = nn.NLLLoss() # Loss function
optimizer = optim.Adam(model.parameters())
train_epochs(model, device, dat 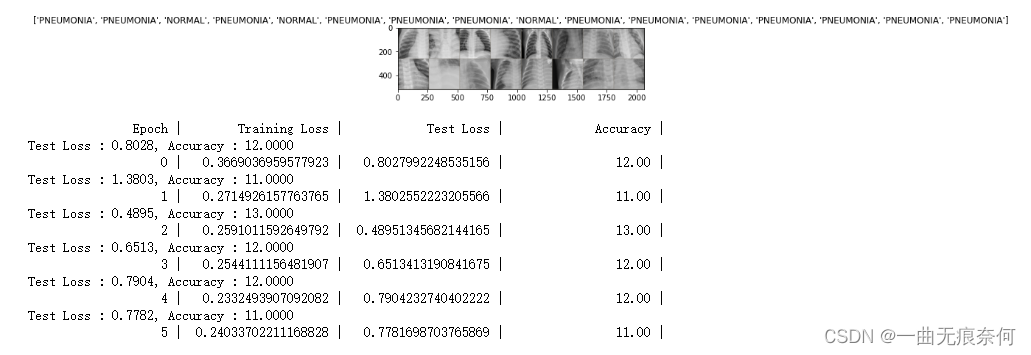
边栏推荐
- NLP routes and resources
- Mexican SQL manual injection vulnerability test (mongodb database) problem solution
- Pytorch LSTM实现流程(可视化版本)
- Not registered via @EnableConfigurationProperties, marked(@ConfigurationProperties的使用)
- [programmers' English growth path] English learning serial one (verb general tense)
- Super detailed steps to implement Wechat public number H5 Message push
- 百度百科数据爬取及内容分类识别
- AI的路线和资源
- The underlying logical architecture of MySQL
- Mysql32 lock
猜你喜欢
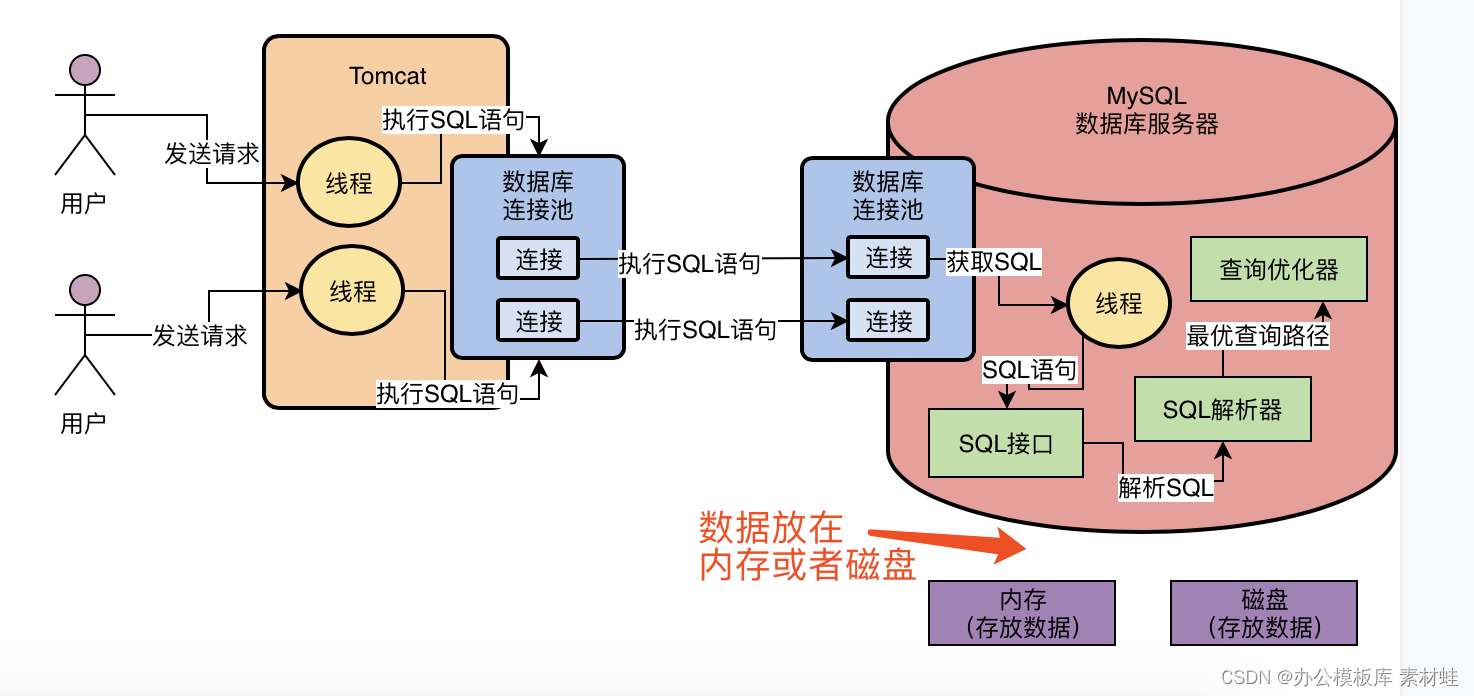
MySQL实战优化高手02 为了执行SQL语句,你知道MySQL用了什么样的架构设计吗?
![13 medical registration system_ [wechat login]](/img/c9/05ad1fc86e02cf51a37c9331938b0a.jpg)
13 medical registration system_ [wechat login]
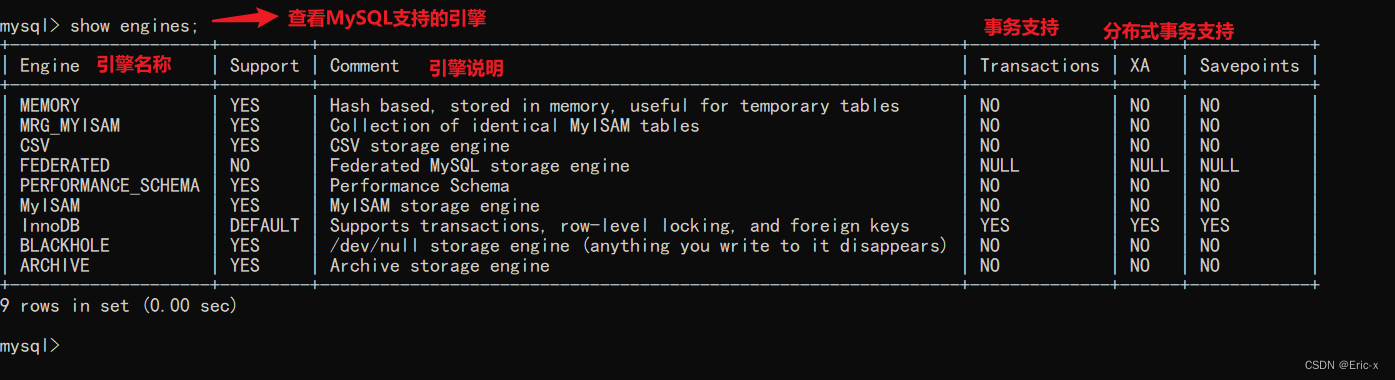
MySQL底层的逻辑架构
What is the current situation of the game industry in the Internet world?

Jar runs with error no main manifest attribute
Record the first JDBC
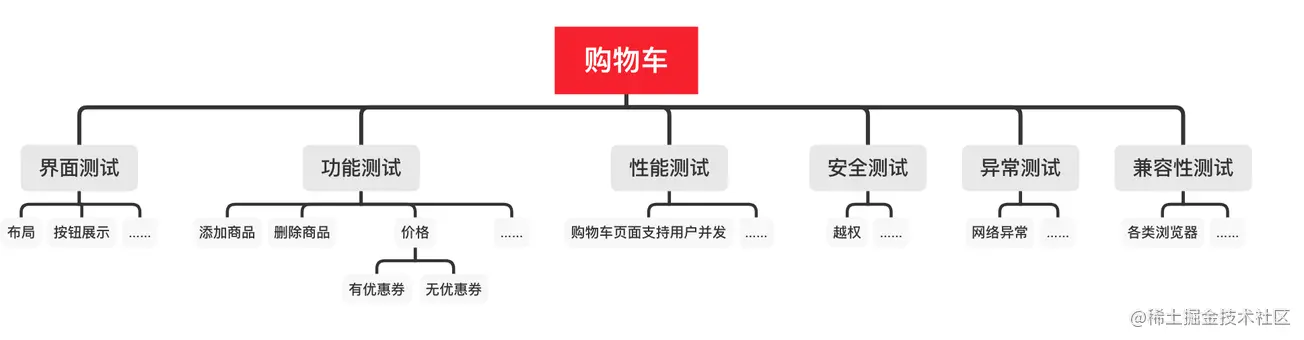
软件测试工程师必备之软技能:结构化思维
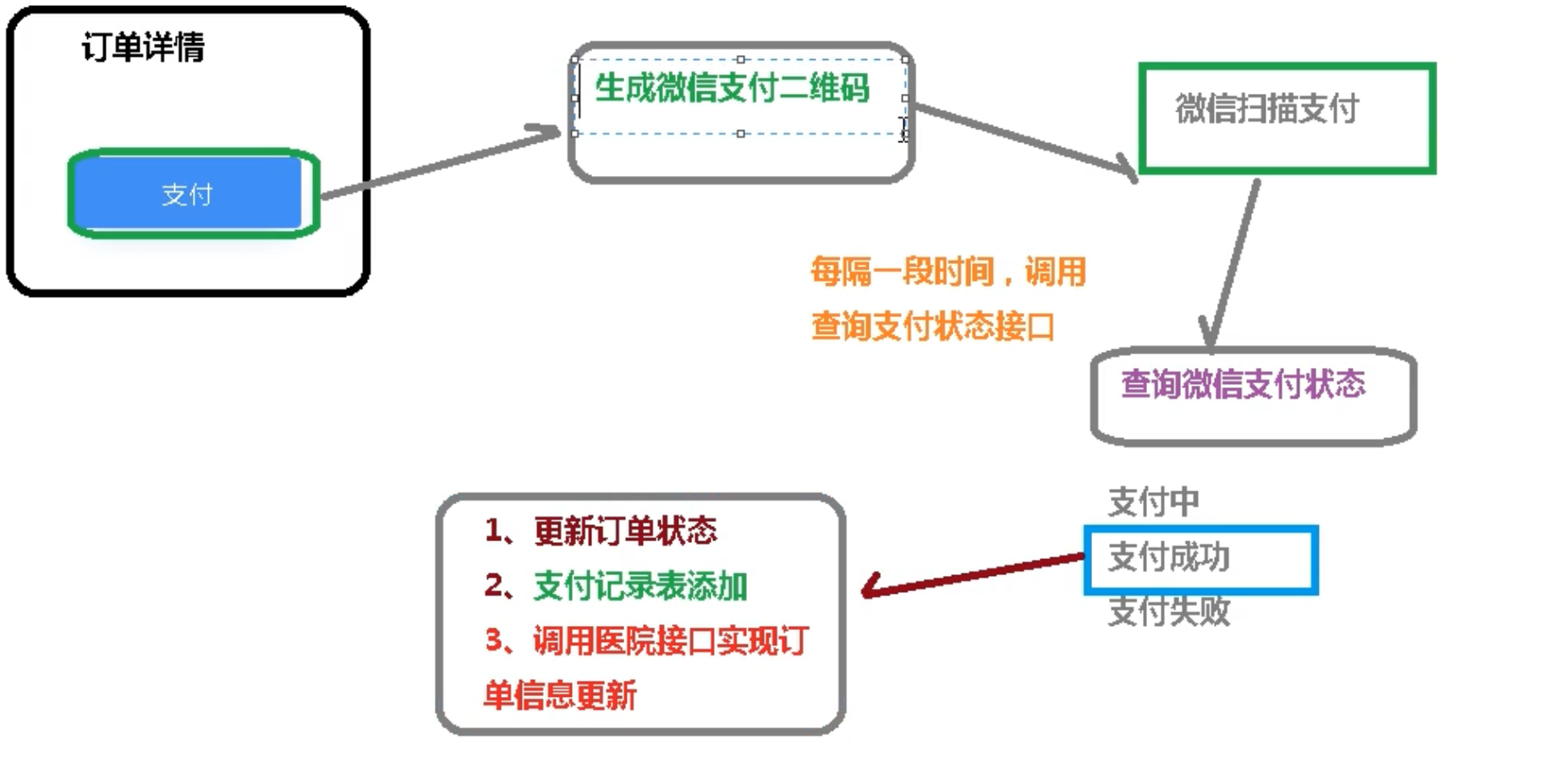
17 医疗挂号系统_【微信支付】
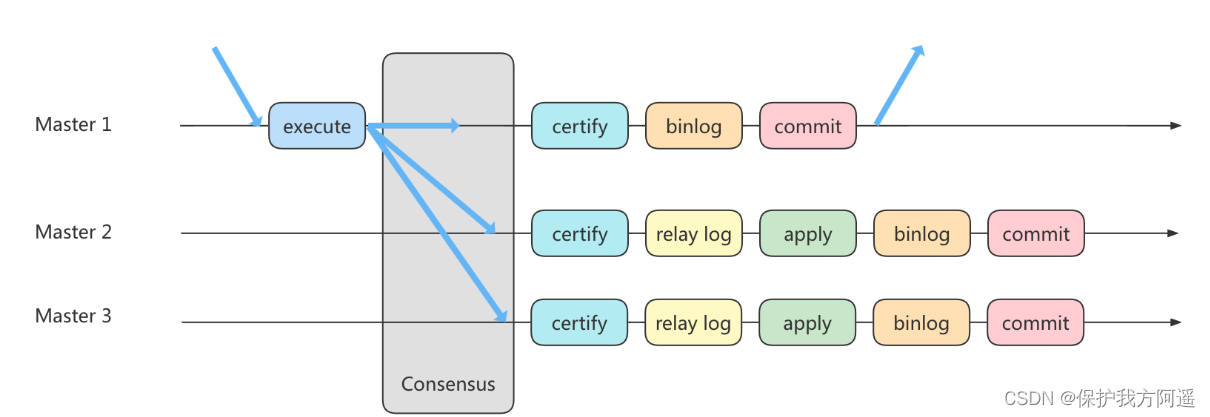
MySQL35-主从复制
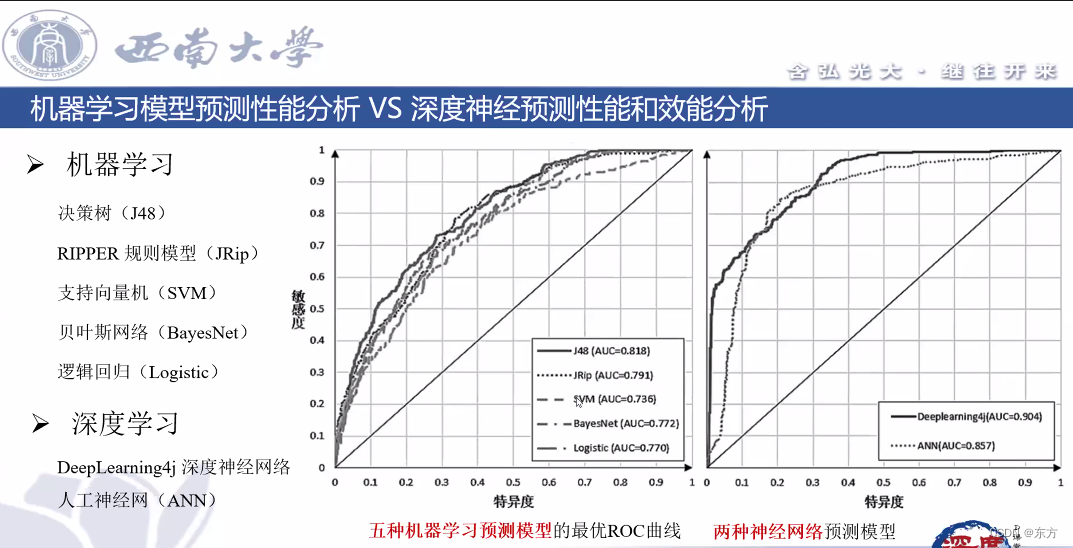
Southwest University: Hu hang - Analysis on learning behavior and learning effect
随机推荐
MySQL36-数据库备份与恢复
使用OVF Tool工具从Esxi 6.7中导出虚拟机
宝塔的安装和flask项目部署
Write your own CPU Chapter 10 - learning notes
ByteTrack: Multi-Object Tracking by Associating Every Detection Box 论文阅读笔记()
第一篇博客
A necessary soft skill for Software Test Engineers: structured thinking
软件测试工程师必备之软技能:结构化思维
Introduction tutorial of typescript (dark horse programmer of station B)
[unity] simulate jelly effect (with collision) -- tutorial on using jellysprites plug-in
15 medical registration system_ [appointment registration]
MySQL实战优化高手10 生产经验:如何为数据库的监控系统部署可视化报表系统?
基于Pytorch的LSTM实战160万条评论情感分类
评估方法的优缺点
Use JUnit unit test & transaction usage
A necessary soft skill for Software Test Engineers: structured thinking
The governor of New Jersey signed seven bills to improve gun safety
text 文本数据增强方法 data argumentation
Target detection -- yolov2 paper intensive reading
美疾控中心:美国李斯特菌疫情暴发与冰激凌产品有关