当前位置:网站首页>一键提取pdf中的表格
一键提取pdf中的表格
2022-07-06 09:13:00 【zkkkkkkkkkkkkk】
前言:
因工作需要,现在需要将pdf中的表格原封不对的输出csv或者数据库表,然后开启了苦逼的调研之路。经过调研,目前支持从可编辑pdf中读取出表格的Python库有:pdfminer3k、tabula、pdfplumber 等。三个库都有瑕疵。但是比好用的话我还是更偏向 pdfplumber 。自我感觉pdfplumber 简单易于实现功能。下面文章是关于 pdfplumber 的介绍。如对另外两个Python库感兴趣的话可以自行查看相关资料。对于pdf中非可编辑(图片中表格识别)问题,可能这个库就帮不上你什么忙了。
目录
一、pdfplumber介绍
1.1、介绍
先看一段官方介绍:pdfplumber支持垂直查看PDF,查看每个文本字符、矩形和行的详细信息。 附加功能:表提取和可视化调试。最适合机器生成的,而不是扫描的pdf文件。总体来说pdfplumber是一个集多种功能为一身的pdf处理工具。
1.2、代码开源git地址
1.3、官方文档
1.4、安装方式
pip install pdfplumber二、简单使用
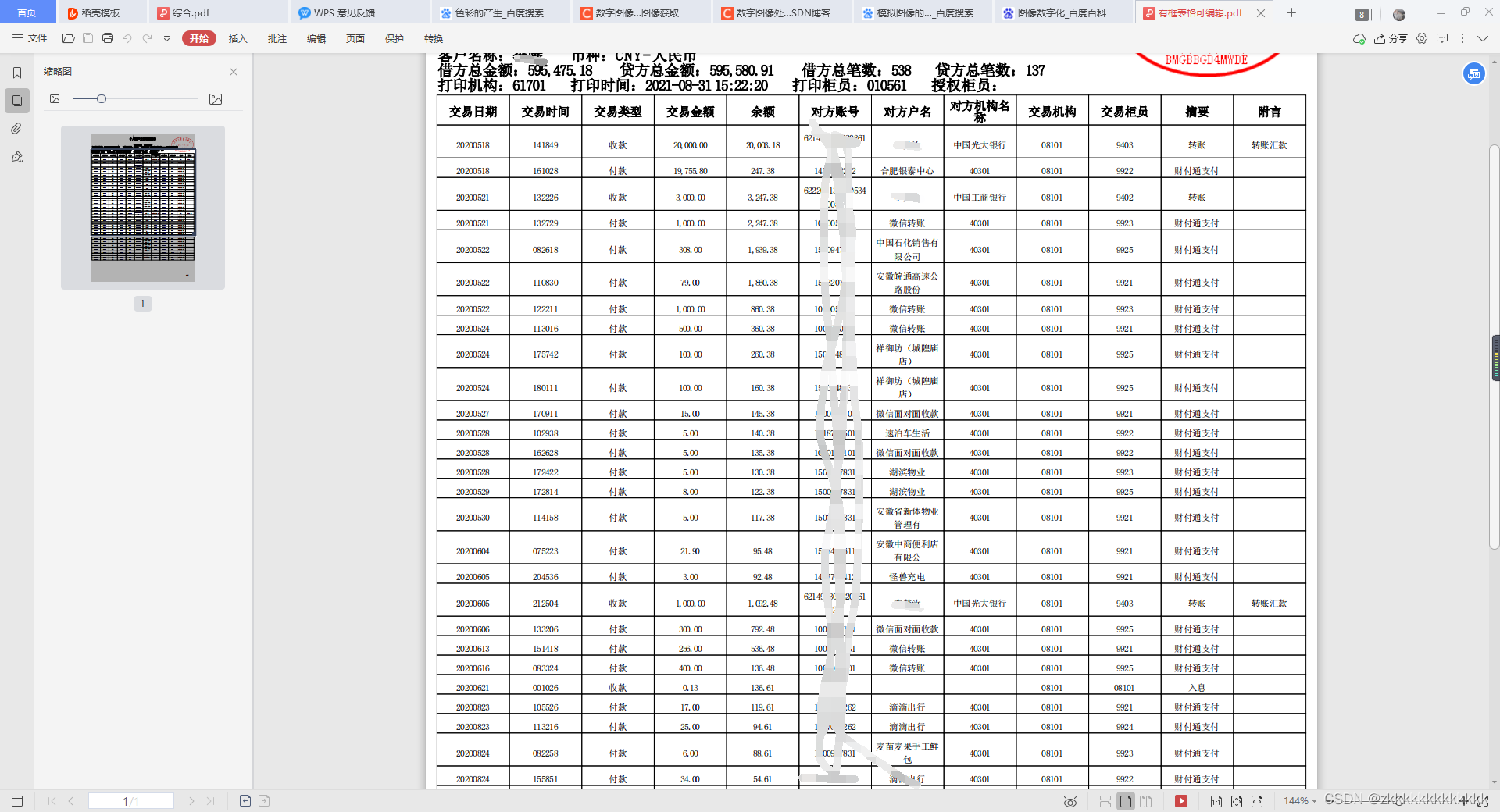
2.1、数据集介绍
数据为交易流水,pdf表格为可编辑。目的是将表格里的数据提取出来。
2.2、代码实现
import pdfplumber
# path = 'D:\\202104147187110045_1.pdf'
path = '../recognize_img/demo_img/有框表格可编辑.pdf'
pdf = pdfplumber.open(path)
# 获取pdf页数对象
print(pdf.pages) # [<Page:1>]
count = 0
for page in pdf.pages:
count += 1
# page.extract_text()可以抓取当前页的全部信息,因为内容较多就先注释。
# print(page.extract_text())
for table in page.extract_tables():
for row in table:
print(row)
print(f'============ 第{count}页解析结束 ============')
# 转为dataframe输出
# pass
pdf.close()3.3、结果输出
结果是以每行列表的形式输出的。如果有需要csv或者数据库需求的话,可以先将下面的数据转为dataframe,然后再输出到目标源。

边栏推荐
- February 13, 2022-3-middle order traversal of binary tree
- [recommended by bloggers] background management system of SSM framework (with source code)
- CSDN question and answer tag skill tree (II) -- effect optimization
- CSDN blog summary (I) -- a simple first edition implementation
- Data dictionary in C #
- MySQL 29 other database tuning strategies
- Ansible practical Series III_ Task common commands
- Ansible实战系列三 _ task常用命令
- frp内网穿透那些事
- Global and Chinese markets of static transfer switches (STS) 2022-2028: Research Report on technology, participants, trends, market size and share
猜你喜欢
Moteur de stockage mysql23

How to change php INI file supports PDO abstraction layer
Swagger、Yapi接口管理服务_SE
![[Li Kou 387] the first unique character in the string](/img/2d/f2c99549cac86c08efbfbd8ba76427.jpg)
[Li Kou 387] the first unique character in the string
![[free setup] asp Net online course selection system design and Implementation (source code +lunwen)](/img/ac/b518796a92d00615cd374c0c835f38.jpg)
[free setup] asp Net online course selection system design and Implementation (source code +lunwen)

Mysql27 index optimization and query optimization
CSDN问答标签技能树(一) —— 基本框架的构建

MySQL master-slave replication, read-write separation
![[ahoi2009]chess Chinese chess - combination number optimization shape pressure DP](/img/7d/8cbbd2f328a10808319458a96fa5ec.jpg)
[ahoi2009]chess Chinese chess - combination number optimization shape pressure DP
Postman Interface Association
随机推荐
Global and Chinese markets for aprotic solvents 2022-2028: Research Report on technology, participants, trends, market size and share
Have you mastered the correct posture of golden three silver four job hopping?
There are three iPhone se 2022 models in the Eurasian Economic Commission database
The virtual machine Ping is connected to the host, and the host Ping is not connected to the virtual machine
[recommended by bloggers] C WinForm regularly sends email (with source code)
MySQL completely uninstalled (windows, MAC, Linux)
Ansible实战系列一 _ 入门
Other new features of mysql18-mysql8
Water and rain condition monitoring reservoir water and rain condition online monitoring
A trip to Macao - > see the world from a non line city to Macao
Ansible practical Series II_ Getting started with Playbook
February 13, 2022-2-climbing stairs
Mysql25 index creation and design principles
February 13, 2022 - Maximum subarray and
La table d'exportation Navicat génère un fichier PDM
Why is MySQL still slow to query when indexing is used?
Mysql27 index optimization and query optimization
CSDN question and answer tag skill tree (I) -- Construction of basic framework
++Implementation of I and i++
Redis的基础使用