当前位置:网站首页>CSDN blog summary (I) -- a simple first edition implementation
CSDN blog summary (I) -- a simple first edition implementation
2022-07-06 10:42:00 【Alexxinlu】
Catalog
Series articles
Team blog : CSDN AI team
1. background
2. Blog summary
2.1 Blog structured
The blog contains too many elements , Abstracting directly as text will seriously affect the quality of abstracts . So first, we need to structure the blog , After structuring, the content in the body will be effectively distinguished , for example :head( title )、code( Code )、table( form )、text( The paragraph )、img( picture )、link( link ) etc. , It's more convenient 、 Get the content of each part accurately , Provide more convenient and clear structured information for the preprocessing logic and rule logic in the subsequent blog abstracts , And provide better input for the model . The following figure is an example of blog structure :
2.2 The rules section
- The rules 1 : Judge whether there is “ Preface ”、“ Let me write it out front ” And other modules that introduce the article , If any , Directly extract the content in the preface , And cut it to the specified length ( Default length :256)

- The rules 2 : Judge whether there is content before the first level Title , If any , Extract this part directly , And cut it to the specified length ( Default length :256)

2.3 The model part
If the rule cannot extract the summary , Then use TextRank The model abstracts blog posts . The input of the model is except head( title )、code( Code )、table( form )、text( The paragraph )、img( picture )、link( link ) And other text information . The specific implementation process is as follows :
- a) For samples that do not meet the rules , Directly extract and divide pictures 、 Code 、 title 、 All text except the contents and other information ;
- b) Divide the text into sentences , Input to TextRank In the model , Make a text summary ;
- c) TextRank The model will be based on the importance of the sentence , Rate each sentence ( The total score of all sentences is 1);
- d) Rank all sentences from high to low , And splicing in turn , Until the length is close to the specified length , But no longer than the specified length .( Default length :256)
2.4 Score setting
- The score range is : [0, 1]
- The default rule score is :0.5
- Model score : Sum of scores of all spliced sentences
3. Next step
The current version is a preliminary version , Further optimization is needed . Next steps include :
- Build test set , Conduct quantitative effect evaluation . The evaluation index :BLEU、ROUGE;
- Optimization of sentence splicing : Rank all sentences from high to low , Combined with The order of sentences in the original Splicing , Until the length is close to the specified length ;
- TextRank When the algorithm constructs the sentence graph , Consider the weight of words . for example : Based on all blogs in the same tag , Use similar to TF-IDF The algorithm calculates the weight of each word .
P.S.
This series of articles will be continuously updated . hope NLP Colleagues in other fields 、 Teachers and experts can provide valuable advice , thank you !
边栏推荐
- 该不会还有人不懂用C语言写扫雷游戏吧
- MySQL23-存儲引擎
- 解决扫描不到xml、yml、properties文件配置
- MySQL 29 other database tuning strategies
- February 13, 2022 - Maximum subarray and
- [paper reading notes] - cryptographic analysis of short RSA secret exponents
- Solution to the problem of cross domain inaccessibility of Chrome browser
- windows无法启动MYSQL服务(位于本地计算机)错误1067进程意外终止
- API learning of OpenGL (2002) smooth flat of glsl
- Security design verification of API interface: ticket, signature, timestamp
猜你喜欢
PyTorch RNN 实战案例_MNIST手写字体识别
Mysql32 lock
Export virtual machines from esxi 6.7 using OVF tool
Mysql26 use of performance analysis tools
MySQL25-索引的创建与设计原则

Bytetrack: multi object tracking by associating every detection box paper reading notes ()
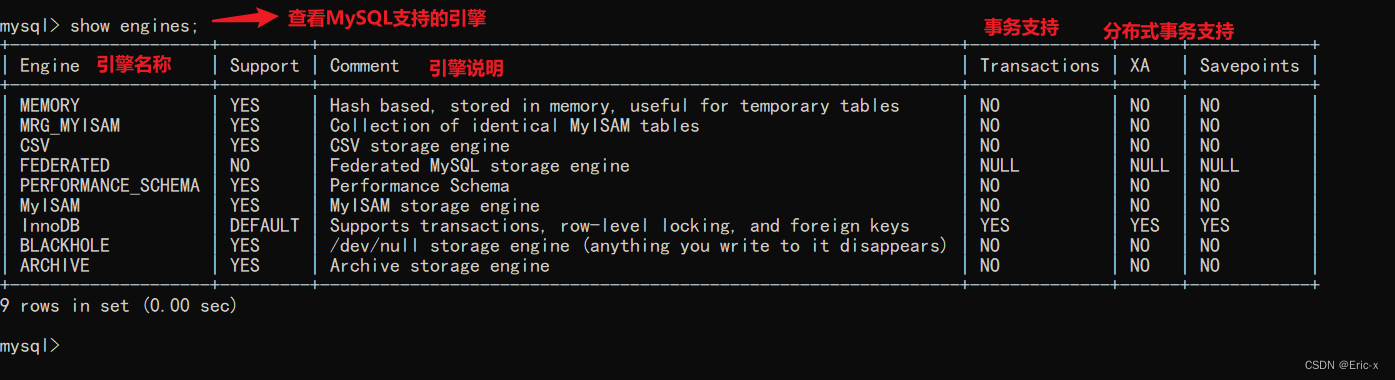
MySQL底层的逻辑架构
Ueeditor internationalization configuration, supporting Chinese and English switching
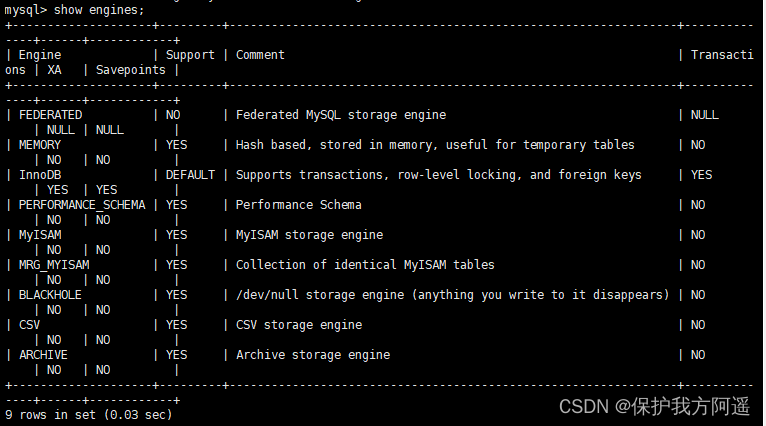
Moteur de stockage mysql23
Not registered via @enableconfigurationproperties, marked (@configurationproperties use)
随机推荐
MySQL 20 MySQL data directory
高并发系统的限流方案研究,其实限流实现也不复杂
[reading notes] rewards efficient and privacy preserving federated deep learning
MySQL27-索引优化与查询优化
基于Pytorch的LSTM实战160万条评论情感分类
Implement context manager through with
MySQL23-存储引擎
MySQL33-多版本并发控制
API learning of OpenGL (2005) gl_ MAX_ TEXTURE_ UNITS GL_ MAX_ TEXTURE_ IMAGE_ UNITS_ ARB
Texttext data enhancement method data argument
基于Pytorch肺部感染识别案例(采用ResNet网络结构)
[programmers' English growth path] English learning serial one (verb general tense)
MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?
MySQL19-Linux下MySQL的安装与使用
在jupyter NoteBook使用Pytorch进行MNIST实现
Mysql34 other database logs
CSDN问答模块标题推荐任务(二) —— 效果优化
【C语言】深度剖析数据存储的底层原理
How to find the number of daffodils with simple and rough methods in C language
[untitled]