当前位置:网站首页>用于实时端到端文本识别的自适应Bezier曲线网络
用于实时端到端文本识别的自适应Bezier曲线网络
2022-07-06 09:11:00 【一曲无痕奈何】
ABCNet V2:用于实时端到端文本识别的自适应Bezier曲线网络
摘要:
旨在将检测和识别集成到统一框架中的抽象端到端文本定位由于其两个互补任务的简单性而引起了越来越多的关注。这仍然是一个悬而未决的问题,尤其是在处理任意形状的文本实例时。以前的方法可以大致分为两组: 基于字符的和基于分割的,由于非结构化的输出,它们通常需要字符级别的注释和/或复杂的后处理。在这里,我们通过呈现自适应贝塞尔曲线网络v2 (ABCNet v2) 来解决端到端文本识别问题。我们的主要贡献有四个方面: 1) 我们首次通过参数化的Bezier曲线自适应地拟合任意形状的文本,与基于分割的方法相比,该曲线不仅可以提供结构化的输出,而且可以提供可控的表示。2) 我们设计了一种新颖的BezierAlign层,用于提取任意形状的文本实例的准确卷积特征,比以前的方法显着提高了识别精度。3) 与以前的方法不同,以前的方法经常遭受复杂的后处理和敏感的超参数的困扰,我们的ABCNet v2维护了一个简单的流水线,其中只有后处理非最大抑制 (NMS)。4) 由于文本识别的性能密切依赖于特征对齐,ABCNet v2进一步采用简单而有效的坐标卷积来编码卷积滤波器的位置,这导致了相当大的改进,计算开销可以忽略不计。在各种双语 (英文和中文) 基准数据集上进行的综合实验表明,ABCNet v2可以实现最先进的性能,同时保持非常高的效率。更重要的是,由于对文本斑点模型进行量化的工作很少,因此我们对模型进行量化以改善所提出的ABCNet v2的推理时间。这对于实时应用程序可能是有价值的。代码和模型可在以下网址获得: https:// git.io/AdelaiDet。
一、引言
以往的场景文本识别方法往往涉及到两个独立的模块:文本检测和识别,这两个模块是按顺序实现的。 它们中的许多只处理一个任务,并直接从另一个任务中借用性能最好的模块。 这种简化的方法不太可能充分利用深度卷积网络的潜力,因为两个任务是孤立的,没有可共享的功能。

图片翻译:在图(a)中,我们遵循前面的方法,使用TPS[1]和STN[2]将弯曲的文本区域扭曲成矩形。 在图(b)中,我们使用生成的Bezier曲线和提出的Bezieralign来扭曲结果,从而提高精度。
最近,端到端场景文本点击方法[3],[4]、[5]、[6]、[7]、[8]、[9]、[10]、[11]等直接在输入图像和文字记录集之间建立统一的映射关系的方法越来越受到人们的重视。 与检测和识别是两个独立模块的模型相比,设计端到端框架的优点如下。 首先,单词识别可以显著提高检测的正确率。 文本最显著的特征之一是序列属性。 然而,假阳性表现出序列的外观存在于无条件的环境中,如街区、建筑物和栏杆。 为了使网络具有区分不同模式的能力,一些方法[3],[4],[5]提出共享两个任务之间的特征,以端到端的方式训练网络。 而且,端到端框架由于共享的特性,往往在推理速度上表现出优势,更适合于实时应用。 最后,目前的独立识别模型通常采用完全裁剪的文本图像或启发式合成图像进行训练。 端到端模块可以迫使识别模块适应检测输出,因此结果可以更加稳健[10]。
端到端文本识别的现有方法可以大致分为两类: 基于字符的和基于分割的。基于字符的方法首先检测和识别单个字符,然后通过应用额外的分组模块输出单词。虽然有效,但需要费力的字符级注释。此外,分组算法通常需要一些预定义的超参数,从而显示出有限的鲁棒性和泛化能力。研究的另一行是基于细分的,其中文本实例由非结构化轮廓表示,这使得后续识别步骤变得困难。例如,[1 2] 中的工作依赖于TPS [1] 或STN [2] 步骤将原始地面真相扭曲成矩形形状。请注意,字符可能会明显失真,如图1所示。此外,与检测相比,文本识别需要大量的训练数据,从而导致统一框架中的优化困难。
为了解决这些限制,我们提出了自适应贝塞尔曲线网络v2 (ABCNet v2),这是一种端到端可训练的框架,用于实时任意形状的场景文本定位。ABCNet v2可以通过简单而有效的Bezier曲线自适应来实现任意形状的场景文本检测,与标准矩形边界框检测相比,这会带来可忽略不计的计算开销。此外,我们设计了一种新颖的特征对齐层,称为BezierAlign,以精确计算弯曲形状文本实例的卷积特征,从而可以实现较高的识别精度。我们首次成功地采用了参数空间 (Bezier曲线) 进行多方向或弯曲的文本定位,从而实现了非常简洁高效的管道。
受 [13] 、 [14] 、 [15] 最近工作的启发,我们在我们的会议版本 [16] 中从四个方面改进了ABCNet: 特征提取器、检测分支、识别分支和端到端训练。由于不可避免的比例变化,建议的ABCNet v2结合了迭代双向功能,以实现更好的准确性和效率权衡。此外,根据我们的观察,检测分支中的特征对齐对于后续的文本识别至关重要。为此,我们采用了一种可以忽略不计的计算开销的坐标编码方法来显式编码卷积滤波器中的位置,从而大大提高了精度。对于识别分支,我们集成了一个字符注意模块,该模块可以递归地预测每个单词的字符,而无需使用字符级别的注释。为了实现有效的端到端培训,我们进一步提出了一种自适应端到端培训 (AET) 策略,以匹配端到端培训的检测。这可以迫使识别分支对检测行为更具鲁棒性。因此,所提出的ABCNet v2比以前的最先进的方法有几个优点,总结如下:
- •我们首次使用Bezier曲线介绍了一种新的,简洁的曲面场景文本的参数化表示。与标准边界框表示相比,它引入了可忽略的计算开销。
- • 我们提出了一种新的特征对齐方法,也就是BezierAlign,从而识别分支可以无缝连接到整体结构。通过共享主干特征,识别分支可以设计出重量轻的结构来进行有效的推理。
- • ABCNet v2的检测模型通过考虑双向多尺度金字塔全局文本特征来处理多尺度文本实例更为通用。
- • 据我们所知,我们的方法是第一个能够以单发方式同时检测和识别水平、多方向和任意形状的文本,同时保持实时推理速度的框架。
- • 为了进一步加快推理速度,我们还利用了模型量化技术,表明ABCNet v2可以在只有边际精度降低的情况下达到更快的推理速度。
- • 在各种基准上进行的综合实验证明了所提出的ABCNet v2在准确性和速度方面的最新文本定位性能。
二、相关工作
场景文本识别需要同时检测和识别文本,而不是只涉及一个任务。 早期的场景文本识别方法通常是通过独立的检测和识别模型简单地连接起来的。 用不同的体系结构分别对两个模型进行了优化。 近年来,端到端方法(§2.2)通过将检测和识别集成到一个统一的网络中,显著提高了文本识别的性能。
2.1分离场景文本定位
在这一节中,我们简要回顾文献,重点是检测或识别。
2.1.1场景文本检测
通过检测灵活性可以观察到文本检测的发展趋势。 从水平矩形检测包围盒表示的聚焦水平场景文本检测,到旋转矩形或四边形包围盒表示的多面向场景文本检测,再到实例分割掩码或多边形表示的任意形状场景文本检测。 早期基于水平矩形的方法可以追溯到Lucas等人。 [17],其中构建了开创性的水平ICDAR'03基准。 ICDAR'03及其后续数据集(ICDAR'11[18]和ICDAR'13[19])在水平场景文本检测方面吸引了大量研究人员[20]、[21]、[22]、[23]、[24]、[25]。
在 2010 年之前,大多数方法只关注常规的水平场景文本,这仅限于泛化到实际应用中,其中多向场景文本无处不在。 为此,姚等人。 [26] 提出了一个实用的检测系统以及用于多方向场景文本检测的多方向基准(MSRA-TD500)。 该方法和数据集都使用旋转的矩形边界框来检测和注释多向文本实例。 除了 MSRA-TD500,包括 NEOCR [27] 和 USTBSV1K [28] 在内的其他多向数据集的出现进一步促进了许多基于旋转矩形的方法 [3]、[26]、[28]、[29]、[30] ,[31]。 自 2015 年以来,ICDAR'15 [32] 开始为每个文本实例使用基于四个点的四边形注释,这促进了许多方法,这些方法成功地证明了更紧凑、更灵活的四边形检测方法的优越性。 SegLink 方法 [33] 通过定向段预测文本区域,并学习连接链接以重新组合结果。
DMPNet [34] 观察到旋转的矩形可能仍然包含不必要的背景噪声、不完美的匹配或不必要的重叠,因此它建议使用四边形边界框来检测带有辅助预定义四边形滑动窗口的文本。 EAST [35] 采用密集预测结构直接预测四边形边界框。 WordSup [36] 提出了一种自动生成字符区域的迭代策略,在复杂场景中表现出鲁棒性。 ICDAR 2015 的成功尝试激发了许多基于四边形的数据集,例如 RCTW'17 [37]、MLT [38] 和 ReCTS [39]。 最近,研究重点已从多向场景文本检测转向任意形状的文本检测。 任意形状在野外主要以曲线文字呈现,在我们的现实世界中也可以很常见,例如柱状物体(瓶子和石堆)、球形物体、复制平面(衣服、流光和收据)、硬币 、标志、印章、招牌等。 第一个弯曲文本数据集 CUTE80 [40] 是在 2014 年构建的。但该数据集主要用于场景文本识别,因为它仅包含 80 个干净的图像,文本实例相对较少。 为了检测任意形状的场景文本,最近提出了两个基准——Total-Text [41] 和 SCUT-CTW1500 [42]——来推进许多有影响力的工作 [43]、[44]、[45]、[46]、 [47]、[48]、[49]、[50]、[51]。 TextSnake [47] 设计了一个 FCN 来预测文本实例的几何属性,然后将它们分组到最终输出中。 CRAFT [44] 预测文本的字符区域和相邻字符之间的亲和力。 SegLink++ [48] 提供了一个实例感知组件分组框架,用于密集和任意形状的文本检测。 PSENet [46] 建议学习文本内核,然后扩展它们以覆盖整个文本实例。 PAN [45] 基于 PSENet [46],采用可学习的后处理方法,通过预测像素的相似度向量。 王等人。 [52] 提出学习自适应文本区域表示以检测任意形状的文本。 DRRN [53] 建议首先检测文本组件,然后通过图网络将它们组合在一起。 ContourNet [50] 采用自适应 RPN 和额外的轮廓预测分支来提高精度。
2.1.2场景文本识别
场景文本识别旨在通过裁剪的文本图像识别文本。许多以前的方法 [54],[55],遵循自下而上的方法,首先通过滑动窗口分割字符区域并对每个字符进行分类,然后将它们分组为一个单词,以考虑与其邻居的依赖性。它们在场景文本识别中获得了良好的性能,但仅限于用于字符检测的昂贵的字符级注释。如果没有大型训练数据集,此类别的模型通常无法很好地概括。Su和Lu [56],[57] 提出了一种利用HOG特征和递归神经网络 (RNN) 的场景文本识别系统,这是成功引入RNN进行场景文本识别的先驱作品之一。
随后,提出了基于CNN的递归神经网络方法以自上而下的方式执行,该方法可以端到端地预测文本序列,而无需任何字符检测。Shi等人。[58] 将连接主义时间分类 (CTC) [59] 应用于具有rnn的网络集成的cnn,称为CRNN。在CTC丢失的指导下,基于CRNN的模型可以有效地转录图像内容。除CTC外,注意机制 [60] 也用于文本识别。上述方法主要应用于常规文本识别,而对于不规则文本识别则不够健壮。近年来,用于任意形状文本识别的方法占主导地位,可以分为基于校正的方法和无校正的方法。
对于前者,STN [2] 和薄板样条 (TPS) [61] 是两种广泛使用的文本校正方法。Shi等 [62] 率先引入STN和基于注意力的解码器来预测文本序列。[63] 中的工作使用迭代文本校正实现了更好的性能。此外,罗等人。[64] 提出了MORAN,它通过对位置偏移的偏移进行回归来纠正文本。Liu等人 [65] 提出了一种字符感知神经网络 (CharNet),该网络首先检测字符,然后将其分别转换为水平字符。ESIR [66] 提出了一种迭代整流流水线,可以将文本的位置从透视失真转换为规则格式,从而可以构建有效的端到端场景文本识别系统。
Litman等人 [67] 首先在输入图像上应用TPS,然后为视觉和上下文特征堆叠几个选择性注意解码器。在无整流方法的范畴中,Cheng等人 [68] 提出了一种任意定向网络 (AON) 来提取四个方向的特征和字符位置线索。Li等人 [69] 应用2d注意机制捕捉不规则的文本特征,取得了令人印象深刻的效果。为了解决注意力漂移问题,Yue等。[70] 在识别模型中设计了一个新颖的位置增强分支。此外,一些无矫正方法是基于语义分割的。廖等 [71] 和万等 [72] 都提出通过视觉特征对人物进行分割和分类。
2.2端到端场景文本定位
2.2.1常规的端到端场景文本定位
李等人。 [3]可能是第一个提出端到端可训练的场景文本点击方法。 该方法成功地使用ROI池[73]通过两阶段框架加入检测和识别特征。 它被设计成处理水平的和集中的文本。 它的改进版本[11]显著提高了性能。 布斯塔等人。 [74]还提出了一个端到端的深度文本检测仪。 他等人。 [4]和Liu等人。 [5]采用无锚机制,同时提高训练和推理速度。 它们使用相似的采样策略,即文本对齐采样和ROI旋转,分别用于从四边形检测结果中提取特征。 请注意,这两种方法都不能发现任意形状的场景文本。
2.2.2任意形状的端到端场景文本定位
为了检测任意形状的场景文本,Liao 等人。 [6] 提出了一种 Mask TextSpotter,它巧妙地改进了 Mask RCNN,并使用字符级监督来同时检测和识别字符和实例掩码。该方法显着提高了任意形状场景文本的定位性能。其改进版本 [10] 显着减轻了对字符级注释的依赖。孙等人。 [75] 提出了预先生成四边形检测边界框的 TextNet,然后使用区域提议网络输入检测特征进行识别。
最近,秦等人。 [7] 建议使用 RoI Masking 来关注任意形状的文本区域。请注意,需要额外的计算来拟合多边形。 [8] 中的工作提出了一种任意形状的场景文本定位方法,称为 CharNet,需要字符级训练数据和 TextField [76] 对识别结果进行分组。 [9] 的作者提出了一种新的采样方法 RoISlide,它使用来自文本实例的预测片段的融合特征,因此它对任意形状的长文本具有鲁棒性。
王等人。 [12]首先检测任意形状文本的边界点,通过TPS对检测到的文本进行矫正,然后将其输入识别分支。廖等人。 [77]提出了一种分割建议网络(SPN)来准确提取文本区域,并遵循[10]获得最终结果。
3我们的方法
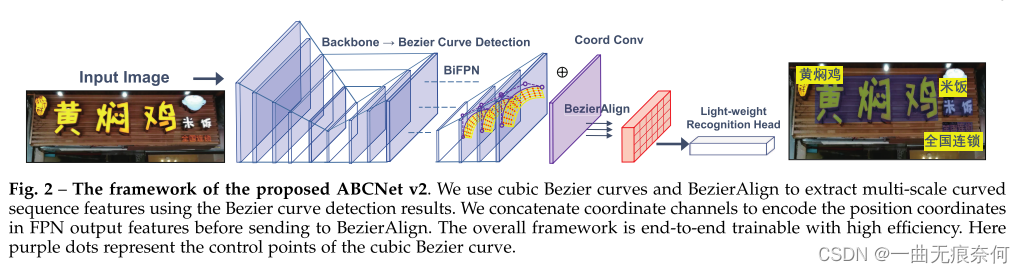
我们的方法的直观管道如图2所示。 受[78]、[79]、[80]的启发,我们采用单次、无锚的卷积神经网络作为检测框架。 锚箱的移除大大简化了我们任务的检测。 在检测头的输出特征图上密集预测检测,该检测头由4个步长为1,填充为1和3×3核的堆叠卷积层构成。 接下来,我们介绍了ABCNet V2的六个关键部分:1)Bezier曲线检测; 2)坐标卷积模块; 3)对齐; 4)轻量级注意力识别模块; 5)自适应端到端培训策略; 6)文本定位量化。
3.1贝塞尔曲线检测
与基于分割的方法[44],[46],[47],[49],[76],[81]相比,基于回归的方法更适合于任意形状的文本检测,如[42],[52]所示。 这些方法的一个缺点是流水线复杂,往往需要复杂的后处理步骤才能获得最终结果。 为了简化对任意形状场景文本实例的检测,我们提出了通过对几个关键点进行回归来拟合Bezier曲线的方法。 Bezier曲线表示以Bernstein多项式为基的参数曲线C(t)。 定义如等式(1)所示:
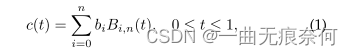
其中,n表示次,bi表示第i个控制点,bi,n(t)表示Bernstein基多项式,如式(2)所示:
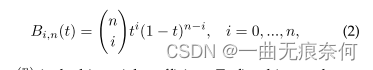
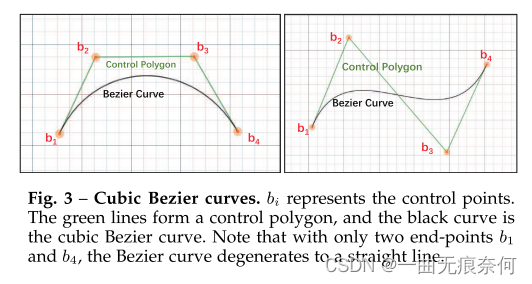
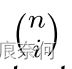 是二项式系数。 为了用Bezier曲线拟合任意形状的文本,我们从已有的数据集中考察任意形状的场景文本,并通过经验证明三次Bezier曲线(即n=3)足以拟合不同格式的曲面场景文本,特别是在带有词级注释的数据集中。 高阶数据在文本行级别的数据集上可能工作得更好,在文本行级别的数据集中可能会在一个实例中呈现多个波。 在实验部分,我们提供了关于Bezier曲线的阶数的比较。 三次Bezier曲线的图示如图3所示。
是二项式系数。 为了用Bezier曲线拟合任意形状的文本,我们从已有的数据集中考察任意形状的场景文本,并通过经验证明三次Bezier曲线(即n=3)足以拟合不同格式的曲面场景文本,特别是在带有词级注释的数据集中。 高阶数据在文本行级别的数据集上可能工作得更好,在文本行级别的数据集中可能会在一个实例中呈现多个波。 在实验部分,我们提供了关于Bezier曲线的阶数的比较。 三次Bezier曲线的图示如图3所示。
基于三次Bezier曲线,我们可以将任意形状的场景文本检测问题归结为一个类似于包围盒回归的回归问题,但总共有八个控制点。 请注意,具有四个控制点(四个顶点)的直文本是任意形状场景文本的典型情况。 为了一致性,我们在每个长边的三方点上插值额外的两个控制点。 为了学习控制点的坐标,我们首先生成§3.1.1中描述的Bezier曲线注释,并遵循[34]中类似的回归方法对目标进行回归。 对于每个文本实例,我们使用
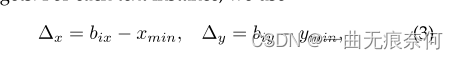
其中Xmin和Ymin分别表示4个顶点的最小x和y值。 预测相对距离的好处是它与Bezier曲线控制点是否超出图像边界无关。 在检测头内部,我们只使用一个卷积层和4个(n+1)(n为Bezier曲线阶数)输出通道来学习Δx和Δy,这几乎是免费的,而结果仍然是准确的。 我们在§4中讨论细节。
3.1.1贝塞尔地面真值生成
在这一节中,我们简要介绍了如何在原始注释的基础上生成Bezier曲线地面真值。 任意形状的数据集,例如total-text[41]和scutctw1500[42],对文本区域使用多边形注释。 给定曲线边界上的注记点{pi}n i=1,其中pi表示第i注记点,主要目的是求出方程(1)中三次Bezier曲线c(t)的最优参数。 为了实现这一点,我们可以简单地应用标准的最小二乘拟合,如下所示:
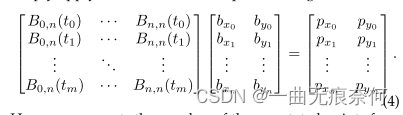
这里 m 表示曲线边界的注释点的数量。 对于 Total-Text 和 SCUT-CTW1500,m 分别为 5 和 7。 t 是通过使用累积长度与折线周长的比率来计算的。 根据式(1)和式(4),我们将原来的折线标注转换为参数化的贝塞尔曲线。 请注意,我们直接使用第一个和最后一个注释点分别作为第一个 (b0) 和最后一个 (bn) 控制点。 可视化对比如图 1 所示,这表明生成的结果在视觉上甚至可以比原始注释更好。 此外,由于结构化输出,可以通过应用我们提出的 BezierAlign(参见 §3.3)轻松地制定文本识别任务,它将弯曲的文本扭曲为水平表示。 贝塞尔曲线生成的更多结果如图 4 所示。我们方法的简单性使其能够以统一的表示格式处理各种形状。
3.2 COORDCONV
如 [14] 中指出的那样,在学习 (x,y) 笛卡尔空间中的坐标与热像素空间中的坐标之间的映射时,常规卷积显示出局限性。通过将坐标连接到特征图可以有效地解决该问题。最近对相对坐标进行编码的实践 [15] 也表明,相对坐标可以为实例分割提供信息提示。Let fouts表示FPN的不同比例的特征,Oi,x和Oi,y分别表示FPN的第i级的所有位置 (即生成滤波器的位置) 的绝对x和y坐标。所有Oi,x和Oi,y由两个特征图fox和foy组成。我们只是将fox和foy连接到沿通道维度的最后一个fouts通道。因此,形成了具有附加两个通道的新特征,随后将其输入到三个卷积层,其内核大小,步幅和填充大小分别设置为3、1和1。我们发现,使用这种简单的坐标卷积可以大大提高场景文本定位的性能。
3.3bezieralign
为了实现端到端的训练,以前的大多数方法都采用各种采样(特征对齐)方法来连接识别分支。通常,采样方法表示网络内区域裁剪过程。也就是说,给定一个特征图和感兴趣区域(RoI),使用采样方法提取RoI的特征,并高效地输出一个固定大小的特征图。然而,以前基于非分段的方法的采样方法,例如RoI池[3]、ROIROATE[5]、文本对齐采样[4]或RoI变换[75],无法正确对齐任意形状文本的特征。通过利用结构化Bezier曲线边界框的参数化性质,我们提出BezierAlign用于特征采样/对齐,这可以看作是RoAlign的灵活扩展[82]。与RoIAlign不同,BezierAlign的采样栅格的形状不是矩形。相反,任意形状网格的每一列都与文本的贝塞尔曲线边界正交。采样点在宽度和高度上分别具有等距间隔,这是相对于坐标的双线性插值。
形式上,给定输入特征映射和Bezier曲线控制点,对大小为Hout×Wout的矩形输出特征映射的所有输出像素进行处理。 以具有位置(GIW,GIH)的输出特征图的像素Gi为例,我们计算T如下:

然后根据式(1)计算出上Bezier曲线边界tp和下Bezier曲线边界bp的点。 利用TP和BP,我们可以通过式(6)对采样点OP进行线性索引:
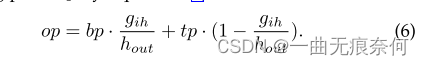
利用OP的位置,我们可以很容易地应用双线性插值来计算结果。 由于对特征的精确采样,文本识别的性能得到了实质性的提高。 我们将bezieralign与其他采样策略进行了比较,如图5所示。


3.4基于注意力的识别分支
从共享主干特性和Bezieralign中受益,我们设计了一个轻量级识别分支,如表1所示,以便更快地执行。 它由6个卷积层、1个双向LSTM层和一个基于注意力的识别模块组成。 在会议版本[16]中,我们将CTC损失[59]应用于预测和基本真理之间的文本字符串对齐,但我们发现基于注意力的识别模块[10]、[60]、[83]、[84]更强大,可以导致更好的结果。 在推断阶段,用检测到的Bezier曲线代替ROI区域,如§3.1所示。 注意,在[16]中,我们只使用生成的Bezier曲线来提取训练过程中的ROI特征。 在本文中,我们也利用了检测结果(见§3.5)。
注意机制采用零RNN初始状态和初始符号的嵌入特征进行序列预测。 在每一步中,递归地使用C-类别Softmax预测(表示预测的特征)、先前的隐藏状态和裁剪的Bezier曲线特征的加权和来计算结果。 预测继续进行,直到预测到序列末尾(EOS)符号。 英语课程的班级人数设为96人(不包括EOS符号),而双语课程的班级人数则设为5462人。 形式上,在时间步骤t中,注意力权重由以下方法计算:

其中,HT-1是最后的隐藏状态,K、W、U和B是可学习的权重矩阵和参数。 序列特征向量的加权和表示为:
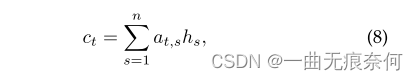
其中at,s定义为:
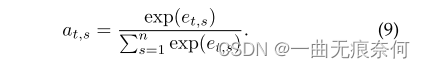
然后,可以更新隐藏状态,如下所示:
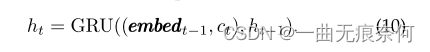
这里,Embedt-1是由分类器生成的先前解码结果yt的嵌入向量:

表1-识别分支的结构,这是CRNN的简化版本[58]。 对于所有卷积层,填充大小限制为1。 n表示批量大小。 C表示通道大小。 h和w表示输出特征图的高度和宽度,nclass表示预测类的个数。

因此,我们用Softmax函数来估计概率分布P(ut)。
![]()
其中v表示要学习的参数。 为了稳定训练,我们还使用了教师强制策略[85],在我们的实现中,在预定义的概率设置为0.5的情况下,该策略传递一个基本事实字符来代替下一个预测的GRU预测。
3.5自适应端到端训练
在我们发表的会议版本[16]中,我们在训练阶段只使用基本真相来Bezieralign用于文本识别分支。 在测试阶段,利用检测结果进行特征裁剪。 根据观测结果,当检测结果不如地面真值Bezier曲线包围盒精确时,可能会产生一些误差。 为了缓解这些问题,我们提出了一种简单而有效的策略,称为自适应端到端训练(AET)。 在形式上,首先用置信阈值抑制检测结果,然后用NMS消除冗余检测结果。 然后,基于控制点坐标的距离的最小总和,将相应的识别地面真值分配给每个检测结果:
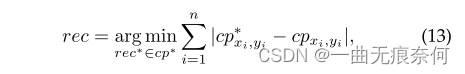
其中cp*是控制点的地面真值。 n是控制点的数目。 在对检测结果进行识别标注后,我们简单地将新目标连接到原始的地面真值集中进行进一步的识别训练。
3.6文本定位量化
场景文本阅读应用通常要求具有实时性; 然而,很少有研究尝试将量化技术应用于场景文本识别。 模型量化的目的是在不影响网络性能的前提下,将全精度张量离散为低比特张量。 有限数量的表示级别(量化级别)可用。 给定量化比特宽度为B比特,量化电平的数目为2B。 很容易看出,随着量化比特宽度变低,深度学习模型可能会遭受显著的性能下降。 为保持精度,离散化误差应尽量减少:
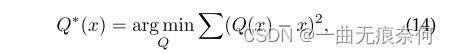
其中q(x)是量子化函数。 在LSQ[86]的激励下,本文采用以下方程作为激活量词。 具体地说,对于来自激活张量xa的任何数据xa,其量化值q(xa)是通过一系列变换计算的。
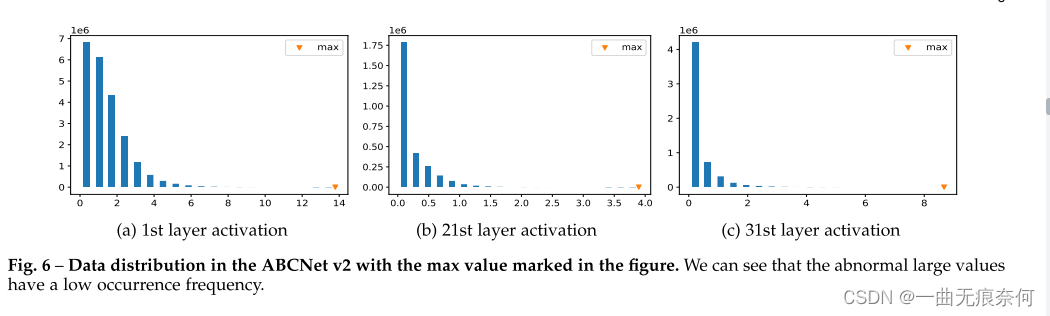
首先,正如工作契约[87]所指出的,并非所有的全精度数据都应该线性映射到量化值。 发现一些异常的大值是常见的,在全精度张量中很少出现。 我们在图6中进一步可视化了ABCNet v2中一些层的数据分布,并观察到了类似的现象。 因此,分配一个可学习参数αa来动态地描述离散化范围,并将超出的数据剪裁到边界:
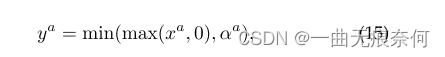
其次,裁剪范围(所谓量化区间)中的数据被线性映射到附近的整数,如等式(16)所示:
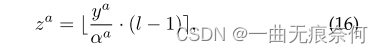
其中l=2b是上面提到的量化级的个数,·是最近的舍入函数。 第三,为了保持量化前后的数据幅值相似,我们在ZA上应用相应的比例因子,通过以下方法得到Q(xa):
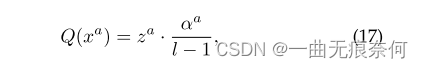
总之,激活的量化可以写成:
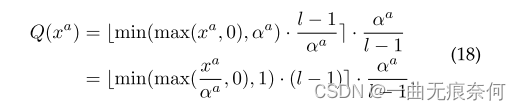
与激活不同的是,权重参数通常包含正和负值,因此在离散化之前引入额外的线性变换,如下所示:
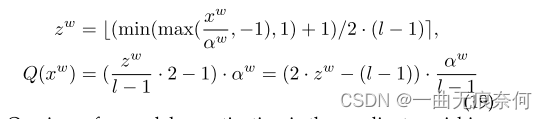
模型量化的一个问题是由圆函数引起的梯度消失(·). 这是因为圆函数几乎处处都有零梯度。采用直通估计器(STE)来解决这一问题。具体来说,我们将舍入函数的导数不断重写为1(∂· = 1). 我们使用小批量梯度下降优化器来训练每一层中与量化相关的参数αa和αw以及来自网络的原始参数。应注意,对于每个卷积层,其量化引入参数αa和αw分别为输入激活张量Xa和权重张量Xw中的所有元素共享。因此,可以在网络前向传播期间交换计算顺序,如等式20所示,以获得更好的效率。通过交换,耗时的卷积计算仅以整数格式操作(所有元素za∈ Za和zw∈ Zw是b位整数)。因此,与相应的浮点型相比,可以在延迟、内存占用和能耗方面实现优势。
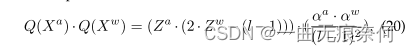
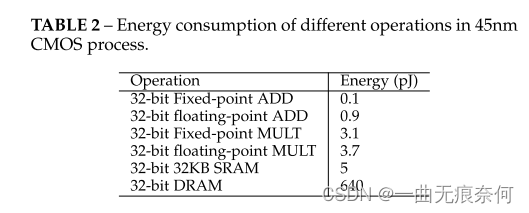
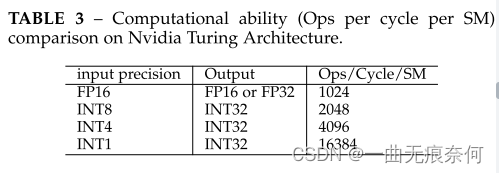
理论上,对于 b 位量化网络,输入激活和权重可以节省 32 b × 内存。对于能耗,我们在表 2 中列出了不同类型片上操作的估计能耗成本。我们可以看到,浮点 ADD 和 MULT 的能耗成本远大于定点操作的能耗成本。此外,与 ALU 操作相比,DRAM 访问消耗的能量要高出一个数量级。因此,很明显,与全精度模型相比,量化模型有可能节省大量能量。在推理延迟方面,量化模型对全精度模型的实际加速取决于平台上定点算术与浮点算术的计算能力。表 3 显示了 Nvidia Turing 架构上每个 SM 的每个周期的操作。我们可以从表 3 中了解到,与平台上的全精度对应物相比,8 位网络有可能实现 2 倍的加速。更令人印象深刻的是,4 位网络和二元神经网络(1 位)的运行速度分别比全精度模型快 4 倍和 16 倍。
4、实验
为了评估ABCNet V2的有效性,我们在多种场景文本基准上进行了实验,包括多面向场景文本基准ICDAR'15[32]、MSRA-TD500[26]、RECTS[39]以及两个任意形状的基准Total-Text[41]和SCUT-CTW1500[42]。 在Total-Text和SCUT-CTW1500上进行了烧蚀研究,以验证我们提出的方法的每个组成部分。
4.1实验细节
除非另有说明,否则此处工作的主干遵循与大多数先前工作一样的通用设置,即 ResNet-50 [88] 和特征金字塔网络 (FPN) [89]。对于检测分支,我们在 5 个特征图上应用 RoIAlign,分辨率分别为输入图像的 1/8、1/16、1/32、1/64 和 1/128,而对于识别分支,BezierAlign 在三个特征图上进行大小分别为 1/4、1/8 和 1/16,采样网格的宽度和高度分别设置为 8 和 32。对于纯英语数据集,预训练数据是从公开可用的基于英语单词级别的数据集中收集的,包括下一节中描述的 150K 合成数据、7K ICDARMLT 数据 [38] 以及每个数据集的相应训练数据。然后在目标数据集的训练集上微调预训练模型。请注意,我们之前的手稿 [16] 中的 15k COCO-Text [90] 图像未在此改进版本中使用。对于 ReCTS 数据集,我们采用 LSVT [91]、ArT [92]、ReCTS [39] 和合成的预训练数据来训练模型。此外,我们还采用了数据增强策略,例如随机尺度训练,短尺寸从 640 到 896(间隔为 32)唯一选择,长尺寸小于 1600;和随机裁剪,我们确保裁剪图像不会剪切文本实例(对于一些难以满足条件的特殊情况,我们不应用随机裁剪)。我们使用 4 个 Tesla V100 GPU 训练我们的模型,图像批量大小为 8。最大迭代次数为 260K;初始化学习率为 0.01,在第 160K 次迭代时降至 0.001,在第 220K 次迭代时降至 0.0001。

4.2基准
Bezier曲线合成数据集150k.对于端到端场景文本发现方法,始终需要大量的免费合成数据。但是,现有的800k SynText数据集 [93] 仅为大多数直文本提供了一个四边形边界框。为了使任意形状的场景文本多样化和丰富,我们做了一些努力,用VGG合成方法合成了150K个图像的数据集 (94,723图像包含大部分直文本,54,327图像包含大部分弯曲文本) [93]。特别地,我们从COCO-text [90] 中筛选出40k无文本背景图像,然后为以下文本渲染准备每个背景图像的分割蒙版和场景深度。为了扩大合成文本的形状多样性,我们通过使用各种艺术字体和语料库合成场景文本来修改VGG合成方法,并为所有文本实例生成多边形注释。然后,通过 § 3.1.1中描述的生成方法,将注释用于生成Bezier曲线基本真理。我们的综合数据示例如图8所示。对于中文预训练,我们按照与上述相同的方法合成了100K个图像,其中一些示例如图9所示。
Total-Text 数据集 [41] 是 2017 年提出的最重要的任意形状的场景文本基准之一,它是从各种场景中收集的,包括类似文本的场景复杂性和低对比度背景。 它包含 1,555 张图像,其中 1,255 张用于训练,300 张用于测试。 为了模拟真实世界的场景,该数据集的大多数图像都包含大量的常规文本,同时保证每张图像至少有一个弯曲的文本。 文本实例使用基于单词级别的多边形进行注释。 它的扩展版本[41]通过在文本识别序列之后用固定的十个点注释每个文本实例来改进其对训练集的注释。 数据集仅包含英文文本。 为了评估端到端结果,我们遵循与以前的方法相同的度量标准,使用 F-measure 来衡量单词准确度。 SCUT-CTW1500 数据集 [42] 是 2017 年提出的另一个重要的任意形状场景文本基准。与 Total-Text 相比,该数据集包含英文和中文文本。 此外,注释是基于文本行级别的,它还包括一些类似文档的文本,即许多小文本可能堆叠在一起。 SCUT-CTW1500 包含 1k 个训练图像和 500 个测试图像。
ICDAR2015数据集[32]提供了在现实世界中偶然捕获的图像。 与以前的ICDAR数据集不同,在以前的ICDAR数据集中,文本是干净的,捕获良好的,并且在图像中水平居中。 该数据集包括1000幅训练图像和500幅复杂背景的测试图像。 一些文本也可能以任何方向和任何位置出现,大小较小或分辨率较低。 注释是基于词级的,它只包括英语样本。


MSRA-TD500 数据集 [26] 包含 500 张多向中英文图像,其中 300 张图像用于训练,200 张图像用于测试。 大多数图像是在室内拍摄的。 为了克服训练数据的不足,我们使用上面提到的合成中文数据进行模型预训练。 ICDAR'19-ReCTs 数据集 [39] 包含 25k 个带注释的招牌图像,其中 20k 个图像用于训练集,其余用于测试集。 与英文文本相比,中文文本的类数通常要多得多,常用字符6k多,排版复杂,字体繁多。 该数据集主要包含商店标志的文本,并为每个字符提供注释。 ICDAR'19-ArT 数据集 [92] 是目前最大的任意形状场景文本数据集。 它是Total-text和SCUT-CTW1500的结合和延伸。 新图像还包含每个图像至少一个任意形状的文本。 在文本方向方面存在很大差异。 Art 数据集被拆分为一个训练集,其中包含 5,603 个图像和 4,563 个用于测试集。 所有的英文和中文文本实例都用紧密的多边形注释。 ICDAR'19-LSVT 数据集 [91] 提供了前所未有的大量街景文本。 它总共提供了 450k 图像,具有丰富的真实场景信息,其中 50k 被完整注释(30k 用于训练,其余 20k 用于测试)。 与 Art [92] 类似,该数据集还包含一些用多边形注释的弯曲文本。

4.3消融研究
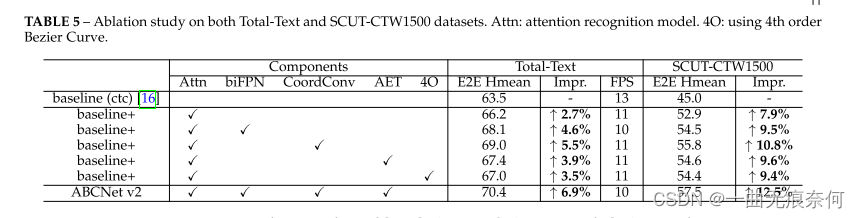
为了评估所提出的组件的有效性,我们在两个数据集上进行了烧蚀研究,Total-Text和SCUT-CTW1500。 我们发现,由于初始化的不同,存在一些训练误差。 另外,文本识别任务要求所有字符都能被正确识别。 为了避免这些问题,我们对每种方法进行三次训练,并报告平均结果。 结果如表5所示,它表明所有模块都可以在两个数据集上对基线模型产生明显的改进。 我们可以看到,使用基于注意力的识别模块,在Total-Text和SCUT-CTW1500上的识别结果分别提高了2.7%和7.9%。 然后,我们使用基于注意力的识别分支评估所有其他模块。 一些结论如下:
使用 biFPN 架构,结果可以额外提高 1.9% 和 1.6%,而推理速度仅降低 1 FPS。因此,我们在速度和准确性之间取得了更好的平衡。
• 使用§3.2 中提到的坐标卷积,在两个数据集上的结果可以分别显着提高 2.8% 和 2.9%。请注意,这种改进不会引入明显的计算开销。
• 我们还测试了§3.5 中提到的AET 策略,结果分别提高了1.2% 和1.7%。
• 最后,我们进行了实验来展示贝塞尔曲线阶数的设置如何影响结果。具体来说,我们使用 4 阶贝塞尔曲线为相同的合成图像和真实图像重新生成所有基本事实。然后,我们通过回归控制点并使用 4 阶 BezierAlign 来训练 ABCNet v2。其他部分保持与 3 阶设置相同。表 5 所示的结果表明,增加顺序有利于文本定位结果,尤其是在采用文本行注释的 SCUT-CTW1500 上。在相同的实验设置下,我们在 Totaltext 数据集上使用 5 阶 Bezier 曲线进一步进行实验;然而,与基线相比,我们发现就 E2E Hmean 而言,性能从 66.2% 下降到 65.5%。根据观察,我们假设下降可能是因为极高的阶数可能导致控制点的剧烈变化,这可能会加剧回归的难度。使用四阶贝塞尔曲线的一些结果如图 10 所示。我们可以看到检测边界框可以更紧凑,从而可以更准确地裁剪文本特征以供后续识别。
我们通过将Bezieralign与以前的采样方法进行比较来进一步评估它,如图5所示。 为了公平和快速的比较,我们使用了一个小的训练和测试量表。 表4中显示的结果表明,Bezieralign可以显著改善端到端的结果。 定性的例子如图11所示。 另一个烧蚀研究是评估Bezier曲线检测的时间消耗,我们观察到Bezier曲线检测与标准包围盒检测相比只引入了可以忽略的计算开销。
4.4与最先进水平的比较
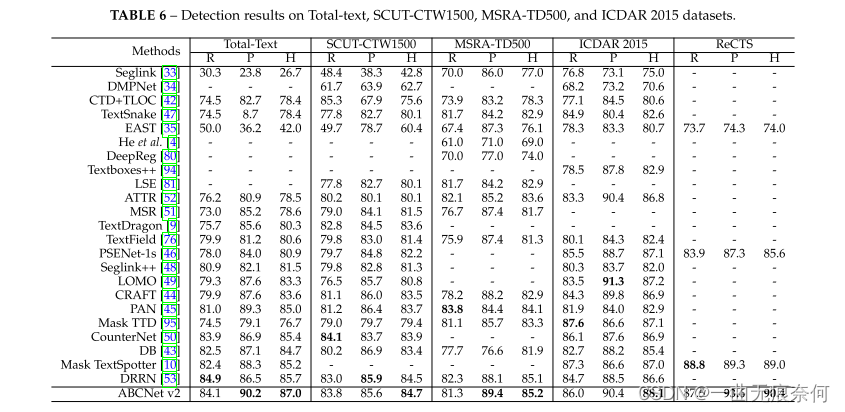
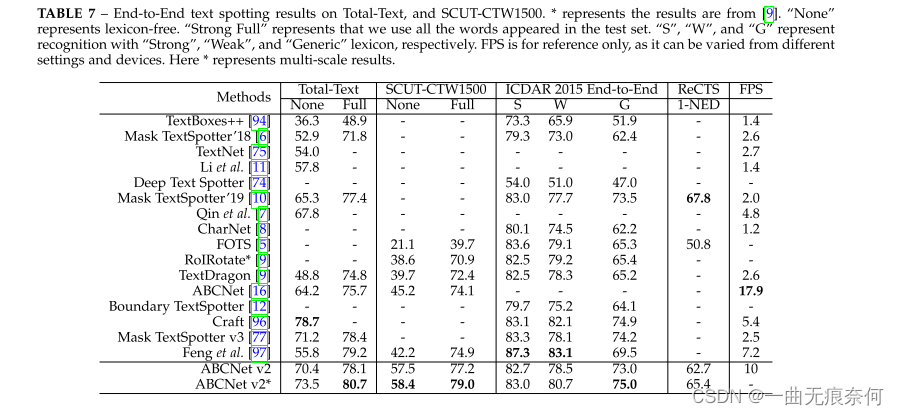
在检测和端到端文本定位任务上,我们将我们的方法与以前的方法进行了比较。 利用网格搜索确定了包括推理阈值和测试规模在内的最优设置。 对于检测任务,我们在四个数据集上进行了实验,包括两个任意形状的数据集(Total-Text和SCUT-CTW1500)、两个多面向的数据集(MSRA-TD500和ICDAR2015)和一个双语数据集RECTS。 表6中的结果表明,我们的方法可以在所有四个数据集上实现最先进的性能,优于以前的最先进的方法。
对于端到端的场景文本定位任务,ABCNet v2在SCUT-CTW1500和ICDAR 2015数据集上实现了最佳性能,显著优于以前的方法。 结果如表7所示。 虽然我们的方法在RECTS数据集上的1-NED方面比Mask TextSpotter[10]差,但我们认为我们没有使用所提供的CharacterLevel包围盒,在推理速度方面我们的方法显示出明显的优势。 另一方面,根据表6,与掩码TextSpotter[10]相比,ABCNet v2仍然可以实现更好的检测性能。 测试集的定性结果如图7所示。 从图中我们可以看到,ABCNet v2实现了对各种文本的强大回忆能力,包括水平、多面向和弯曲文本,或长而密集的文本呈现样式。
4.5与Mask TextSpotter V3的全面比较
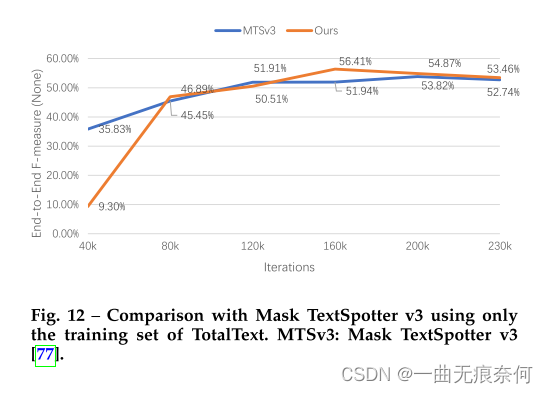
使用少量数据进行比较。 我们发现所提出的方法仅使用少量训练数据就可以实现有希望的定位结果。 为了验证有效性,我们使用 Mask TextSpotter v3 [77] 的官方代码,并按照相同的设置进行实验,仅使用 TotalText 的官方训练数据训练模型。 具体来说,我们方法的优化器和学习率 (0.002) 设置为与 Mask TextSpotter v3 相同。 批量大小设置为 4,两种方法都经过 23 万次迭代训练。 为确保这两种方法的最佳设置,Mask TextSpotter v3 的最小尺寸为 800、1000、1200 和 1400,最大尺寸为 2333。测试以最小尺寸 1000 和最大尺寸 4000 进行。 方法的最小尺寸为 640 到 896,间隔为 32,最大尺寸设置为 1600。为了稳定训练,少样本训练不使用 AET 策略。 测试的最小尺寸为 1000,最大尺寸为 1824。我们还进行网格搜索以找到 Mask TextSpotter v3 的最佳阈值。 不同迭代的结果如图 12 所示。我们可以看到,虽然 Mask TextSpotter v3 一开始收敛得更快,但我们方法的最终结果更好(56.41% vs. 53.82%)。



使用大规模数据进行比较。 我们还使用了足够的训练数据来与Mask TextSpotter V3进行更彻底的比较。 在形式上,我们使用Bezier曲线合成数据集(150K)、MLT(7K)和TotalText仔细地训练Mask TextSpotter V3,它们与我们的方法完全相同。 训练规模、批量大小、迭代次数和其他都设置为4.1节中提到的相同。 网格搜索还用于为掩码TextSpotter V3找到最佳阈值。 结果如表8所示,从中我们可以看到Mask TextSpotter V3在F-度量方面优于ABCNet V1 0.9,ABCNet V2可以优于Mask TextSpotter V3(65.1%对70.4%)。 在相同的测试尺度(最大尺寸设置为1824)和设备(RTX A40)下测量了推理时间,进一步证明了该方法的有效性。
4.6有限性
进一步对预测错误的样本进行误差分析。 我们观察到两种常见错误,它们可能会限制ABCNet v2的场景文本定位性能。
第一个显示在图 13 的示例中。文本实例包含两个字符。对于每个字符,阅读顺序是从左到右。但是对于整个实例,阅读顺序是从上到下。由于 Bezier 曲线是在文本实例的较长边内插的,因此 BezierAlign 特征与其原始特征相比将是一个旋转特征,这可能导致完全不同的含义。另一方面,这种情况只占整个训练集的一小部分,很容易被错误地识别或预测为看不见的类别,如第二个字符的“”表示。第二个错误出现在不同的字体中,如图 13 中间所示。前两个字符是用不寻常的书法字体书写的,因此难以识别。一般来说,这个挑战只能通过更多的训练图像来缓解。我们还发现CTW1500的测试集中有一个极端弯曲的情况,在同一个文本实例中存在三个以上的波峰,如图13的第三行所示。在这种情况下,低阶例如三次贝塞尔曲线可能会受到限制,因为由于形状表示不准确,字符“i”被错误地识别为大写“I”。但是,这种情况很少见,尤其是对于那些使用单词级边界框的数据集。

4.7推理速度
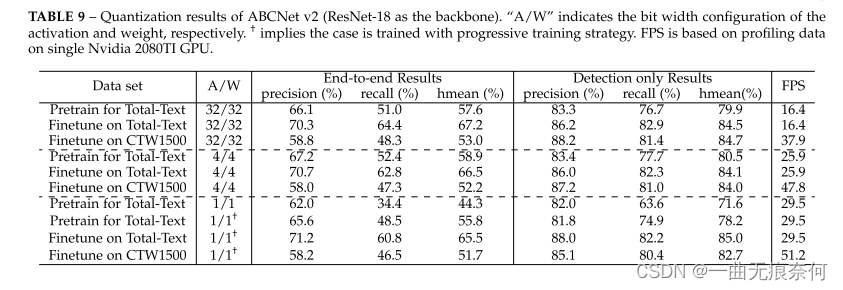
为了进一步测试所提出方法的潜在实时性能,我们利用量化技术来显着提高推理速度。基线模型采用与基线相同的设置,具有表 5 中所示的基于注意力的识别分支。主干被 ResNet-18 取代,这显着提高了速度,但只降低了边际精度。表 9 中报告了具有各种量化位配置(4/1 位)的量化网络的性能。还列出了全精度性能以进行比较。为了训练量化网络,我们首先在合成数据集上预训练了低位模型。然后,我们在专用数据集 TotalText 和 CTW1500 上微调网络以获得更好的性能。报告了预训练模型和微调模型的准确性结果。在预训练期间,训练了 260K 迭代,批量大小为 8。初始学习率设置为 0.01,在 160K 和 220K 迭代时除以 10。对于 TotalText 数据集的微调,批量大小保持为 8,初始学习率设置为 0.001。仅微调了 5K 次迭代。在 CTW1500 数据集上进行微调时,批量大小和初始学习率相同。但是,总迭代次数设置为 120k,并且在迭代 80k 时学习率除以 10。与之前的量化工作类似,我们量化了网络中的所有卷积层,除了输入和输出层。如果没有特别说明,网络将使用全精度对应物进行初始化。
从表9中,我们可以了解到,采用我们的量化方法的4位模型能够获得与全精度模型相当的性能。例如,在合成数据集上预训练的4位模型的端到端hmean甚至优于全精度模型(57.6%对58.9%)。微调后,TotalText和CTW1500上4位模型的端到端hmean分别比全精度模型低0.7%(67.2%对66.5%)和0.8%(53.0%对52.2%)。事实上,4位模型的性能几乎没有下降(在图像分类和目标检测任务上也进行了同样的观察[98]),这表明全精度场景文本定位模型中有相当多的冗余。然而,二进制网络的性能有很大的下降,端到端hmean仅为44.3%。为了补偿,我们建议使用渐进式训练来训练BNN(二进制神经网络)模型,其中量化比特宽度逐渐减小(例如,4bit→ 2比特→ 1位)。使用新的训练策略(表中带有†的策略),二进制网络的性能得到显著改善。例如,使用BNN模型在合成数据集上训练的端到端hmean仅比全精度对应的hmean低1.8%(57.6%对55.8%)。除了性能评估之外,我们还比较了量化模型和全精度模型的总体速度。在实践中,只有量化卷积层与其他层一起加速,例如保持完全精度的LSTM。从表9可以看出,在性能下降有限的情况下,ABCNet v2的二进制网络能够实时运行TotalText和CTW1500数据集。
5结论
我们提出了ABCNet V2--一种实时的端到端方法,它使用Bezier曲线来进行任意形状的场景文本点击。 ABCNet V2通过参数化Bezier曲线重构任意形状的场景文本,实现了用Bezier曲线检测任意形状的场景文本。 与标准包围盒检测相比,我们的方法引入了可以忽略的计算代价。 利用这种Bezier曲线包围盒,我们可以通过一个新的Bezieralign层自然地连接一个轻量级的识别分支,这对于准确地提取特征是至关重要的,尤其是对于弯曲的文本实例。 在不同数据集上的综合实验证明了所提出的组件的有效性,包括使用注意力识别模块、BIFPN结构、坐标卷积和一种新的自适应端到端训练策略。 最后,我们提出了将量化技术应用于实时任务的模型部署,显示了广泛的应用潜力。
边栏推荐
- 实现微信公众号H5消息推送的超级详细步骤
- [after reading the series] how to realize app automation without programming (automatically start Kwai APP)
- Zsh configuration file
- MySQL storage engine
- Solve the problem of remote connection to MySQL under Linux in Windows
- MySQL实战优化高手02 为了执行SQL语句,你知道MySQL用了什么样的架构设计吗?
- 14 medical registration system_ [Alibaba cloud OSS, user authentication and patient]
- MySQL combat optimization expert 09 production experience: how to deploy a monitoring system for a database in a production environment?
- How to build an interface automation testing framework?
- Hugo blog graphical writing tool -- QT practice
猜你喜欢
![[one click] it only takes 30s to build a blog with one click - QT graphical tool](/img/f0/52e1ea33a5abfce24c4a33d107ea05.jpg)
[one click] it only takes 30s to build a blog with one click - QT graphical tool
Contest3145 - the 37th game of 2021 freshman individual training match_ C: Tour guide
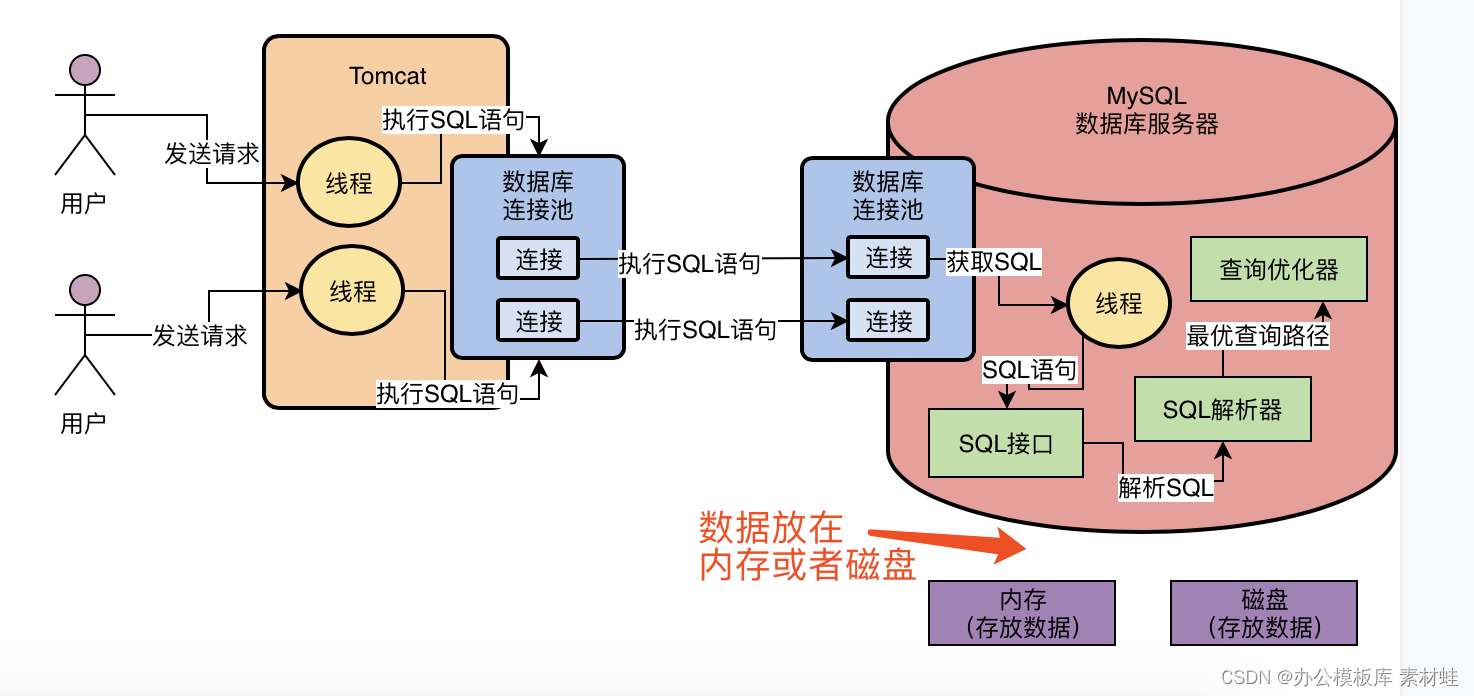
MySQL combat optimization expert 02 in order to execute SQL statements, do you know what kind of architectural design MySQL uses?

Sichuan cloud education and double teacher model
![[after reading the series] how to realize app automation without programming (automatically start Kwai APP)](/img/e1/bad9cfa70d3c533cfaddeee40b96f1.jpg)
[after reading the series] how to realize app automation without programming (automatically start Kwai APP)
cmooc互联网+教育
在CANoe中通過Panel面板控制Test Module 運行(初級)

PR 2021 quick start tutorial, first understanding the Premiere Pro working interface

Write your own CPU Chapter 10 - learning notes

Use xtrabackup for MySQL database physical backup
随机推荐
Hugo blog graphical writing tool -- QT practice
Safety notes
MySQL实战优化高手07 生产经验:如何对生产环境中的数据库进行360度无死角压测?
华南技术栈CNN+Bilstm+Attention
Const decorated member function problem
MySQL ERROR 1040: Too many connections
寶塔的安裝和flask項目部署
[after reading the series] how to realize app automation without programming (automatically start Kwai APP)
Super detailed steps for pushing wechat official account H5 messages
Solve the problem of remote connection to MySQL under Linux in Windows
What is the current situation of the game industry in the Internet world?
Vscode common instructions
Competition vscode Configuration Guide
Redis集群方案应该怎么做?都有哪些方案?
C杂讲 双向循环链表
13 医疗挂号系统_【 微信登录】
Constants and pointers
Sichuan cloud education and double teacher model
Set shell script execution error to exit automatically
Implement context manager through with