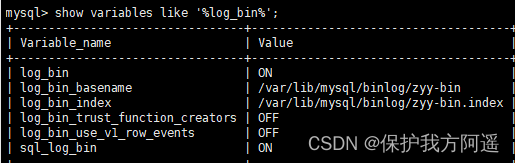
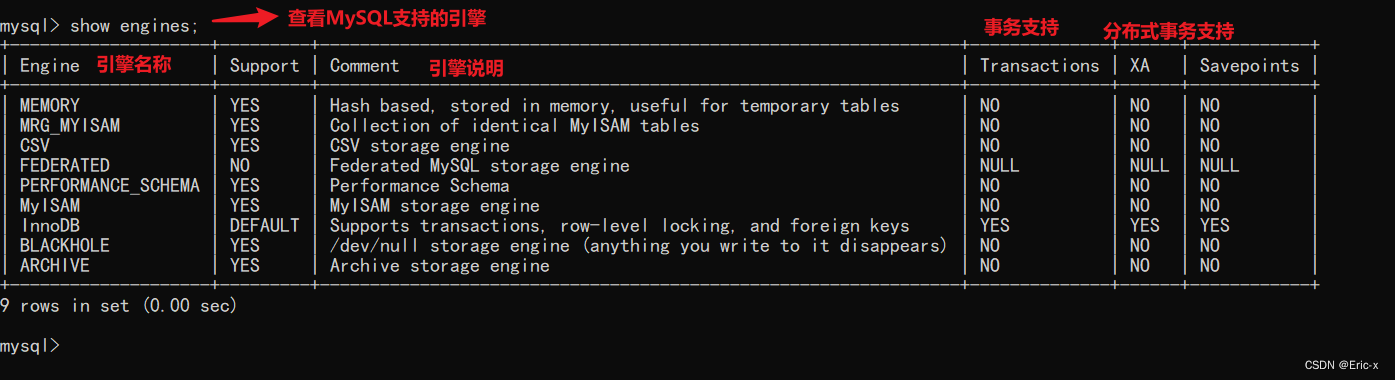
当前位置:网站首页>Mysql24 index data structure
Mysql24 index data structure
2022-07-06 10:33:00 【Protect our party a Yao】
One . Why index
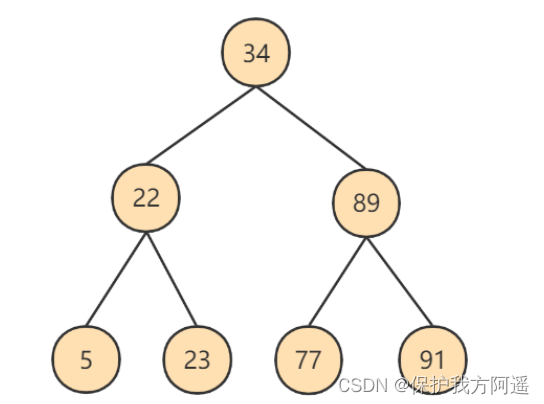
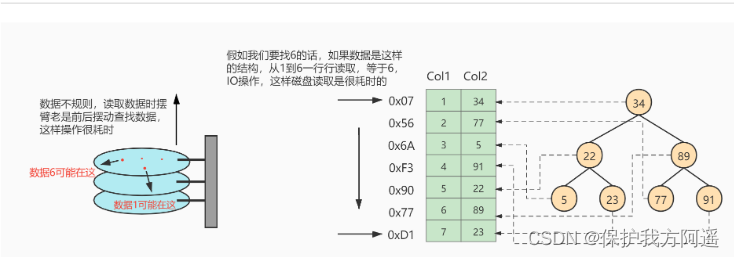 If used for data Binary tree Such a data structure for storage , As shown in the figure below
If used for data Binary tree Such a data structure for storage , As shown in the figure below 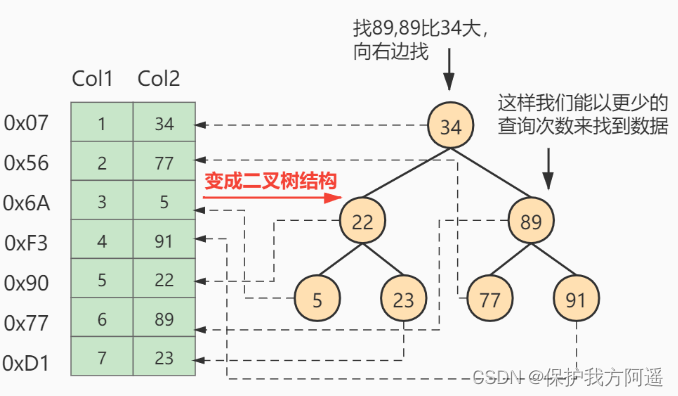
Two . Index and its advantages and disadvantages
2.1. Index Overview
MySQL The official definition of index is : Indexes (Index) Help MySQL Data structure for efficient data acquisition .
The essence of index : An index is a data structure . You can simply understand it as “ Quickly find data structures in order ”, Meet specific search algorithms . These data structures point to data in some way , In this way, it can be realized on the basis of these data structures Advanced search algorithm .
2.2. advantage
- It's similar to building a bibliographic index in a university library , Improve the efficiency of data retrieval , Reduce Database IO cost , This is also the main reason for creating indexes .
- By creating a unique index , It can ensure that every row in the database table The uniqueness of data .
- In terms of reference integrity of data , Sure Connection between accelerometers and meters . let me put it another way , When the dependent child table and parent table are jointly queried , Can improve the query speed .
- When using grouping and sorting clauses for data queries , It can be significant Reduce the time of grouping and sorting in queries , To reduce the CPU Consumption of .
2.3. shortcoming
There are also many disadvantages to increasing the index , Mainly in the following aspects :
- Creating and maintaining an index requires Time consuming , And as the amount of data increases , The time spent will also increase .
- Index needs to occupy disk space , In addition to the fact that data tables occupy data space , Each index takes up a certain amount of physical space , Stored on disk , If there are a lot of indexes , The index file may reach the maximum file size faster than the data file .
- Although the index greatly improves the query speed , At the same time Reduce the speed of updating tables . When adding data in the table 、 When deleting and modifying , Index should also be maintained dynamically , This reduces the speed of data maintenance .
- therefore , When choosing to use index , We need to consider the advantages and disadvantages of index .
3、 ... and . InnoDB Deduction of index in
3.1. Search before index
Let's start with an example of exact matching :
SELECT [ List of names ] FROM Table name WHERE Name = xxx;
- Search in a page
- Find... In many pages
Without index , Whether it's based on the values of primary key columns or other columns , Because we can't quickly locate the page where the record is , So only From the first page Along Double linked list Keep looking down , In each page, find the specified record according to our search method above . Because you have to traverse all the data pages , So this way is obviously Super time consuming Of . What if a watch has 100 million records ? here Indexes emerge as the times require .
3.2. Design index
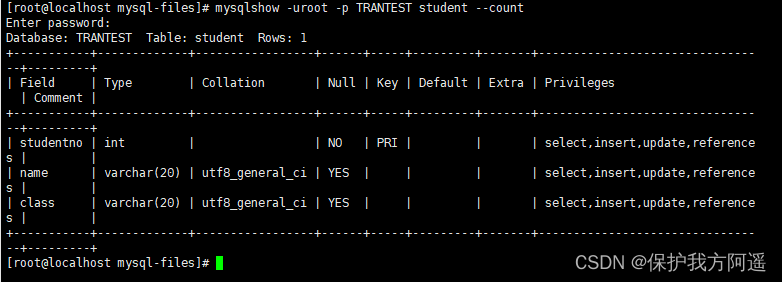
Build a watch :
mysql> CREATE TABLE index_demo(
-> c1 INT,
-> c2 INT,
-> c3 CHAR(1),
-> PRIMARY KEY(c1)
-> ) ROW_FORMAT = Compact;
This new index_demo Table has 2 individual INT Column of type ,1 individual CHAR(1) Column of type , And we have rules c1 List as primary key , This watch uses Compact Line format to actually store records . Here we simplify index_demo Table row format diagram :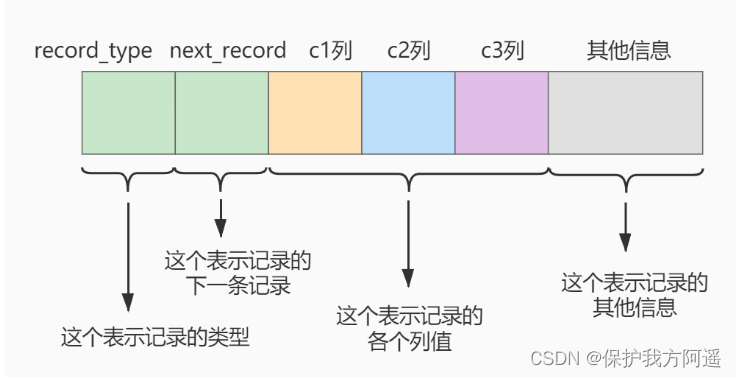 We only show these parts of the record in the schematic diagram :
We only show these parts of the record in the schematic diagram :
- record_type : An attribute that records header information , Indicates the type of record , 0 It means ordinary record 、 2 Represents the minimum record 、 3 Indicates the maximum record 、 1 I haven't used it yet , Here is .
- next_record : An attribute that records header information , Represents the address offset of the next address relative to this record , We use arrows to indicate who the next record is .
- The value of each column : This is only recorded in index_demo Three columns in the table , Namely c1 、 c2 and c3 .
- Other information : In addition to the above 3 All information except information , Including the values of other hidden columns and the extra information recorded .
The effect of temporarily removing other information items of the record format diagram and erecting it is like this :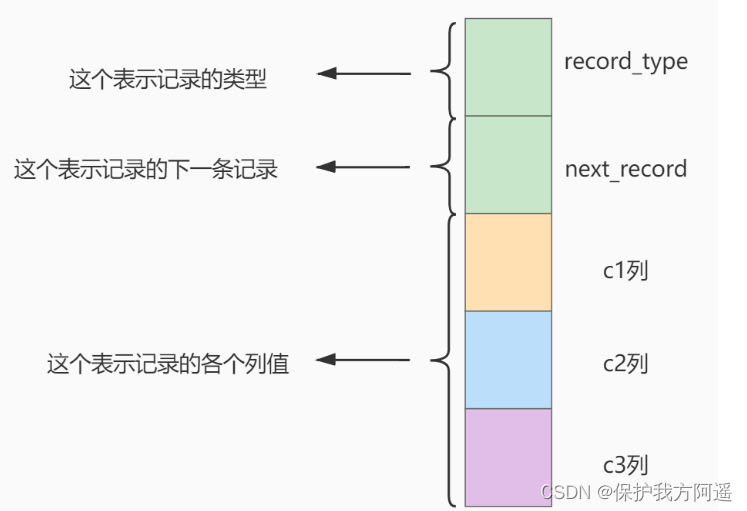
The diagram of putting some records on the page is :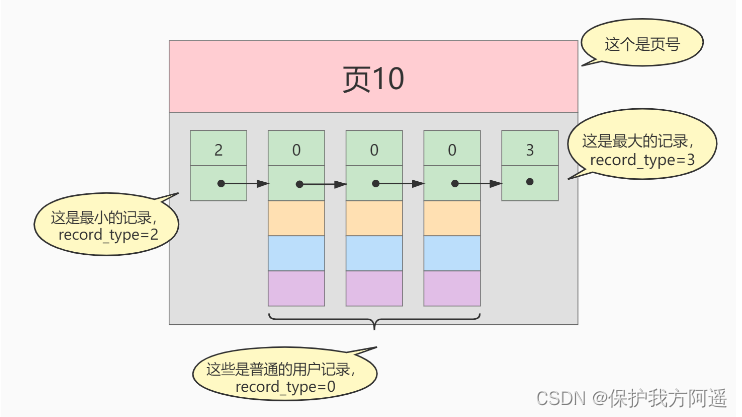
3.2.1. A simple index design scheme
Why should we traverse all the data pages when looking for some records according to a certain search condition ? Because the records in each page are irregular , We don't know which pages our search criteria match the records in , So you have to traverse all the data pages in turn . So if we Want to quickly locate the data pages of the records you need to find What to do in ? We can quickly locate the data page where the record is located Create a directory , To build this directory, you must complete the following things :
- The primary key value of the user record in the next data page must be greater than the primary key value of the user record in the previous page .
- Create a directory entry for all pages .
So the table of contents we made for the upper pages is like this :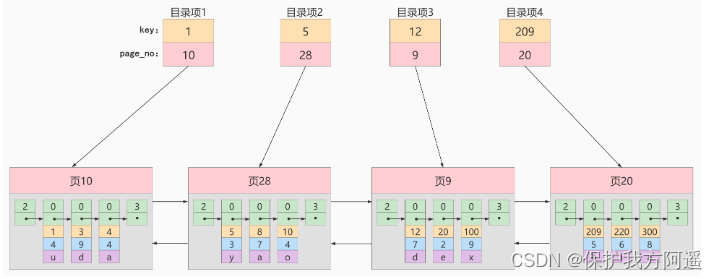 With page 28 For example , It corresponds to Catalog items 2 , This directory entry contains the page number of the page 28 And the minimum primary key value of the user record in the page 5 . We only need to store a few catalog items in physical memory ( such as : Array ), You can quickly find a record based on the primary key value . such as : The search key value is 20 The record of , The specific search process is divided into two steps :
With page 28 For example , It corresponds to Catalog items 2 , This directory entry contains the page number of the page 28 And the minimum primary key value of the user record in the page 5 . We only need to store a few catalog items in physical memory ( such as : Array ), You can quickly find a record based on the primary key value . such as : The search key value is 20 The record of , The specific search process is divided into two steps :
- First from the directory entry according to Dichotomy Quickly determine that the primary key value is 20 It's recorded in Catalog items 3 in ( because 12 < 20 <209 ), Its corresponding page is page 9 .
- Then according to the way of finding records in the page mentioned above page 9 To locate specific records .
thus , A simple directory for data pages is done . This directory has an alias , be called Indexes .
3.2.2. InnoDB Index scheme in
① iteration 1 Time : Page of directory entry record
This is how we put the catalog items we used in the front into the data page :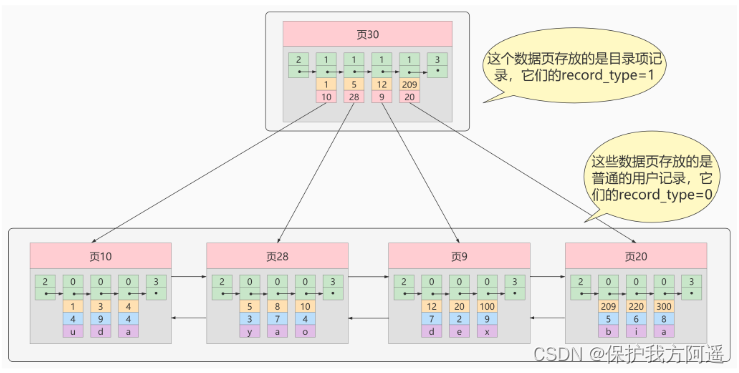 It can be seen from the picture that , We have newly assigned a number to 30 To store directory entry records . Here again Catalog entry records and common User record The difference between :
It can be seen from the picture that , We have newly assigned a number to 30 To store directory entry records . Here again Catalog entry records and common User record The difference between :
- Catalog item record Of record_type The value is 1, and Ordinary user records Of record_type The value is 0.
- Directory entry records only have Primary key value and page number Two columns , The columns of ordinary user records are user-defined , May contain Many columns , And then there is InnoDB Hidden columns added by yourself .
- understand : There is another one in the header called min_rec_mask Properties of , Only in storage Catalog item record The page with the smallest primary key value Catalog item record Of min_rec_mask The value is 1 , Other records min_rec_mask Values are 0 .
The same thing : Both use the same data page , Will be generated for the primary key value Page Directory ( Page directory ), Thus, when searching according to the primary key value, you can use Dichotomy To speed up the query .
Now find the primary key as 20 For example , The steps of finding records according to a certain primary key value can be roughly divided into the next two steps : - First come storage Catalog item record Page of , That's the page 30 Pass through Dichotomy Quickly navigate to the corresponding directory entry , because 12 < 20 <209 , Therefore, the page where the corresponding record is located is page 9.
- Then go to the page where user records are stored 9 According to the Dichotomy Quickly locate the primary key value as 20 The user record of .
② iteration 2 Time : Pages of multiple directory entry records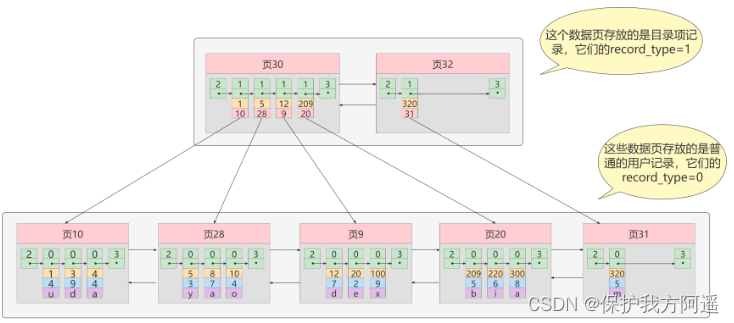
As you can see from the diagram , We inserted a message with a primary key value of 320 Two new data pages are required after the user record :
- A new... Was generated to store the user record page 31 .
- Because the original storage of directory entry records page 30 The capacity of is full ( Let's assume that we can only store 4 Directory entry records ), So we have to need a new page 32 To hold the page 31 The corresponding catalog item .
Now, because there is more than one page storing directory entry records , So if we want to find a user record based on the primary key value, we need to 3 A step , To find the primary key value 20 For example :
- determine Catalog item record page
We now have two pages for storing directory item records , namely page 30 and page 32 , And because of the page 30 Represents the range of the primary key values of the catalog items [1, 320) , page 32 Indicates that the primary key value of the directory item is not less than 320 , So the primary key value is 20 The directory entry corresponding to the record of is recorded in page 30 in . - Record the page through the table of contents entry Determine the page where the user record is actually located .
In a store Catalog item record The way of locating a directory entry record through the primary key value in the page of . - Locate the specific record in the page where the user record is actually stored .
③ iteration 3 Time : The catalog page of the catalog item record page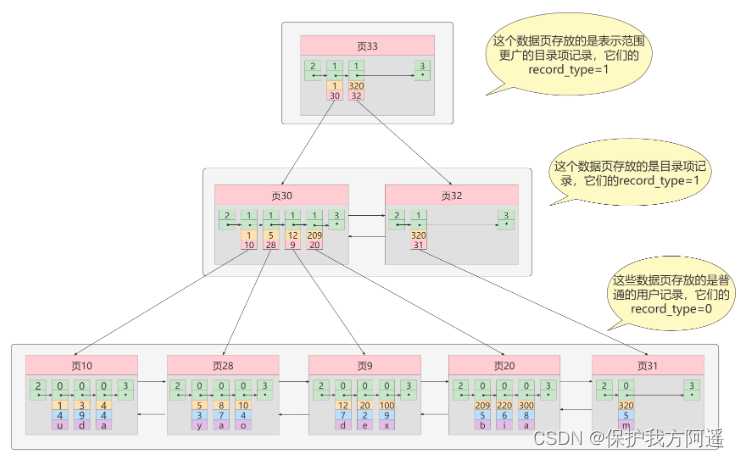
Pictured , We have generated a... That stores more advanced catalog items page 33 , The two records in this page represent page 30 And page 32, If the primary key value of the user record is [1, 320) Between , To page 30 Find more detailed catalog entry records in , If the primary key value Not less than 320 Words , That's it 32 Find more detailed catalog entry records in .
We can use the figure below to describe it :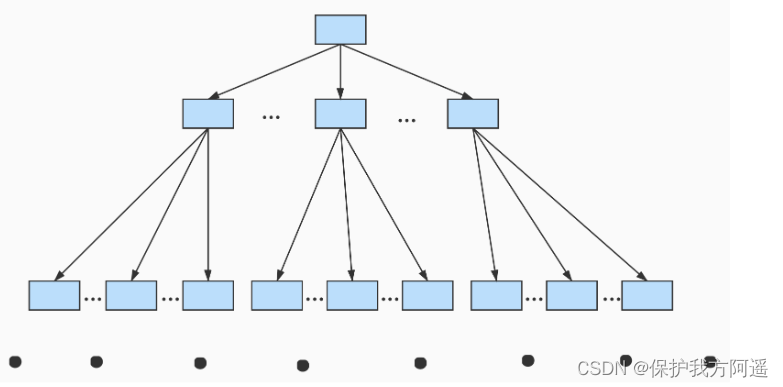 This data structure , Its name is B+ Trees .
This data structure , Its name is B+ Trees .
④ B+Tree
One B+ The nodes of the tree can be divided into many layers , Specify the bottom layer , That is to say, the layer where our user records are stored is the 0 layer , Then add... In turn . We made a very extreme assumption before : A page for storing user records At most 3 Bar record , The page that holds the catalog entry record At most 4 Bar record . In fact, the number of records stored in a page in the real environment is very large , It is assumed that the data pages represented by all leaf nodes storing user records can be stored 100 User records , The data pages represented by all internal nodes storing directory item records can be stored 1000 Directory entry records , that :
- If B+ The tree has nothing but 1 layer , It's just 1 Nodes for storing user records , Can store at most 100 Bar record .
- If B+ The tree has 2 layer , Can store at most 1000×100=10,0000 Bar record .
- If B+ The tree has 3 layer , Can store at most 1000×1000×100=1,0000,0000 Bar record .
- If B+ The tree has 4 layer , Can store at most 1000×1000×1000×100=1000,0000,0000 Bar record . Quite a lot of records !!!
Your watch can store 100000000000 Records ? So in general , We Use of B+ No tree will surpass 4 layer , Then we can find a record through the primary key value. At most, we only need to do 4 Find within pages ( lookup 3 A directory entry page and a user record page ), And because there are so-called Page Directory ( Page directory ), So in the page, you can also use Dichotomy Realize fast positioning and recording .
3.3. Common indexing concepts
The index is physically implemented , The index can be divided into 2 Kind of : Clustering ( Gather ) And non clustering ( Non aggregation ) Indexes . We also call a nonclustered index a secondary index or a secondary index .
3.3.1. Cluster index
characteristic :
- Use the size of the record primary key value to sort records and pages , This includes three meanings :
- On page The records of are arranged in one order according to the size of the primary key One way linked list .
- Each store Page of user record It is also arranged according to the primary key size of user records in the page Double linked list .
- Deposit Page of directory entry record Divided into different levels , The pages in the same hierarchy are also arranged in one order according to the primary key size of the directory item records in the page Double linked list .
- B+ Treelike Leaf node What is stored is a complete user record .
The so-called complete user record , It means that the values of all columns are stored in this record ( Include hidden columns ).
advantage :
- Data access is faster , Because the clustered index keeps the index and data in the same B+ In the tree , So getting data from clustered indexes is faster than non clustered indexes .
- Clustering index for primary key Sort search and Range lookup Very fast .
- Sort by cluster index , When a query displays a certain range of data , Because the data is tightly connected , The database doesn't have to extract data from multiple data blocks , therefore Save a lot of io operation .
shortcoming : - The insertion speed depends heavily on the insertion order , Inserting in the order of the primary keys is the fastest way , Otherwise, there will be page splitting , Seriously affect performance . therefore , about InnoDB surface , We usually define a self increasing ID List as primary key .
- It's expensive to update the primary key , Because it will cause the updated row to move . therefore , about InnoDB surface , We generally define the primary key as non updatable .
- Secondary index access requires two index lookups , Find the primary key value for the first time , The second time, find the row data according to the primary key value .
3.3.2. Secondary indexes ( Secondary index 、 Nonclustered index )
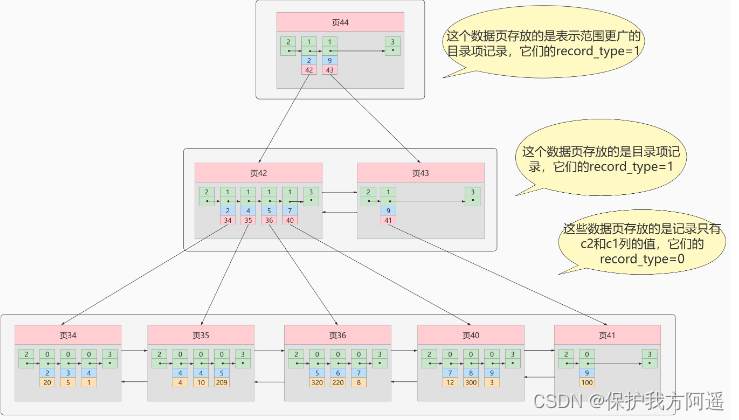 Concept : Back to the table Based on this, we take c2 Sort by column size B+ The tree can only determine the primary key value of the record we are looking for , So if we want to be based on c2 If the value of the column finds the complete user record , Still need to Cluster index Check again in , This process is called Back to the table . That is to say, according to c2 The value of the column is used to query a complete user record 2 Tree B+ Trees !
Concept : Back to the table Based on this, we take c2 Sort by column size B+ The tree can only determine the primary key value of the record we are looking for , So if we want to be based on c2 If the value of the column finds the complete user record , Still need to Cluster index Check again in , This process is called Back to the table . That is to say, according to c2 The value of the column is used to query a complete user record 2 Tree B+ Trees !
problem : Why do we need another Back to the table Operation? ? Directly put the complete user record into the leaf node, which is unnecessary OK Do you ?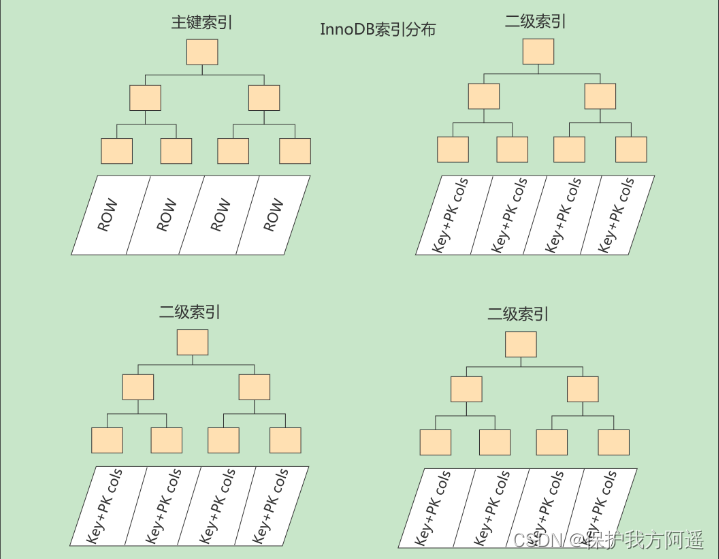
3.3.3. Joint index
We can also use the size of multiple columns as the sorting rule at the same time , That is, index multiple columns at the same time , Let's say we want B+ The tree follows c2 and c3 Column Sort the size of , This has two meanings :
- First, follow the records and pages c2 Sort columns .
- On record c2 In the same case , use c3 Sort columns .
Be careful. , With c2 and c3 The size of the column is set up by the collation B+ The tree is called Joint index , It's essentially a secondary index . Its meaning and distinction are c2 and c3 The expression of indexing columns separately is different , The differences are as follows : - establish Joint index It's just going to build something like the one above 1 Tree B+ Trees .
- by c2 and c3 Columns are indexed separately with c2 and c3 The size of the column is set up for the collation 2 Tree B+ Trees .
3.4. InnoDB Of B+ Considerations for tree indexing
- The location of the root page remains unchanged for ten thousand years .
- The uniqueness of the directory entry record in the inner node .
- A page stores at least 2 Bar record .
Four . MyISAM Index scheme in
4.1. B Tree index is suitable for storage engine
B The applicable storage engine of tree index is shown in the table :
| Indexes / Storage engine | MyISAM | InnoDB | Memory |
|---|---|---|---|
| B-Tree Indexes | Support | Support | Support |
Even if multiple storage engines support the same type of index , But their implementation principle is also different .Innodb and MyISAM The default index is Btree Indexes ; and Memory The default index is Hash Indexes .
MyISAM Engine USES B+Tree As an index structure , Leaf node data Domain stores The address of the data record .
4.2. MyISAM The principle of indexing
The picture below is MyISAM Schematic diagram of index :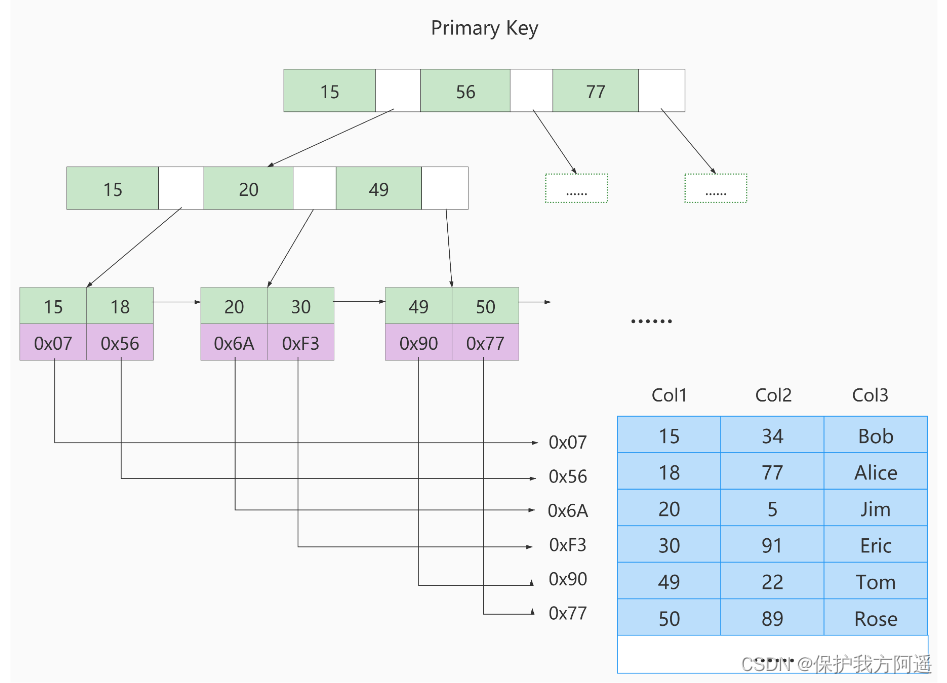
If we were Col2 Build a secondary index on , The structure of this index is shown in the figure below :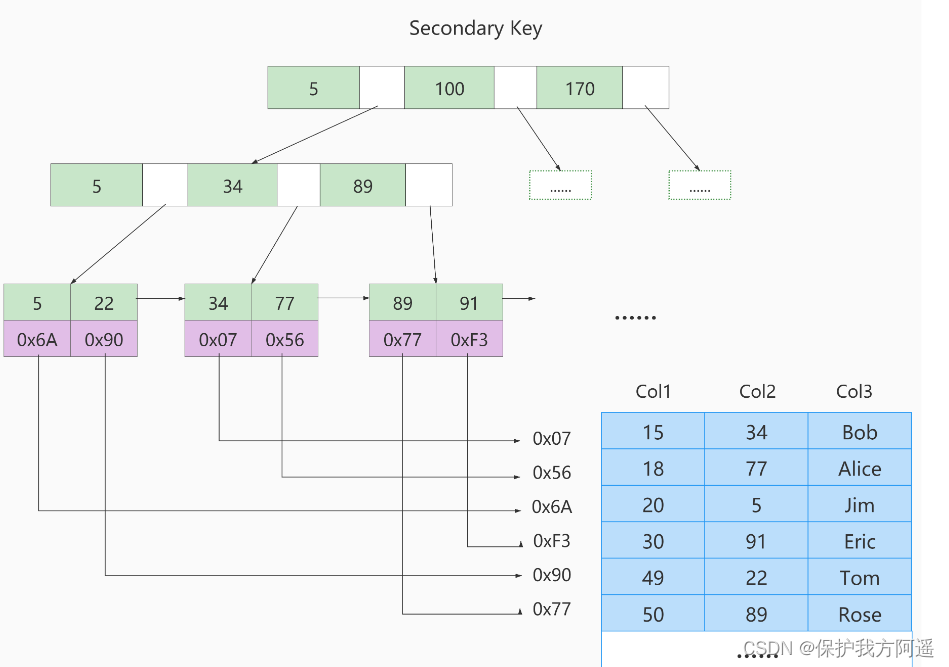
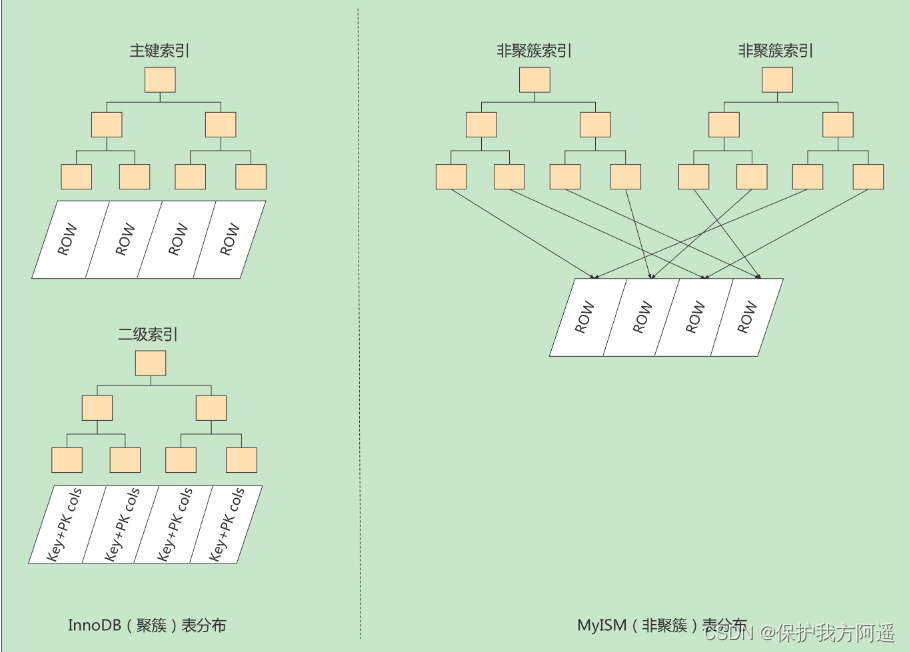
4.3. MyISAM And InnoDB contrast
MyISAM The indexing methods are “ It's not clustering ” Of , And InnoDB contain 1 Cluster indexes are different . Summarize the differences between indexes in the two engines :
- stay InnoDB In the storage engine , We just need to match... According to the primary key value Cluster index A search will find the corresponding record , And in the MyISAM But it needs to be done once Back to the table operation , signify MyISAM The index established in is equivalent to all Secondary indexes .
- InnoDB The data file itself is the index file , and MyISAM Index files and data files are The separation of , Index file only holds the address of the data record .
- InnoDB The nonclustered index of data The domain stores the corresponding records The value of the primary key , and MyISAM The index records Address . let me put it another way ,InnoDB All non clustered indexes of refer to the primary key as data Domain .
- MyISAM The operation of returning tables is very Fast Of , Because it takes the address offset to get the data directly from the file , take the reverse into consideration InnoDB After obtaining the primary key, you can find records in the cluster index , Although it's not slow , It's better to visit the address directly than not .
- InnoDB List of requirements Must have primary key ( MyISAM There can be no ). If not explicitly specified , be MySQL The system will automatically select a column that can be non empty and uniquely identify data records as the primary key . If there is no such column , be MySQL Automatically for InnoDB Table generates an implicit field as the primary key , The length of this field is 6 Bytes , Type is long .
5、 ... and . The cost of indexing
Index is a good thing , You can't build it indiscriminately , It consumes space and time :
- The cost of space
Every time you build an index, you have to create a B+ Trees , Every tree B+ Each node of the tree is a data page , A page will occupy by default 16KB Storage space , A big one B+ A tree consists of many data pages , That's a lot of storage space . - The cost of time
The data in the table is checked every time increase 、 Delete 、 Change In operation , All need to be modified B+ Tree index . And we talked about ,B+ The nodes in each layer of the tree are based on the value of the index column Sort from small to large And make up Double linked list . Whether it's a record in a leaf node , Or the record in the inner node ( That is, whether it is a user record or a directory entry record ) Are in accordance with the index column values from small to large order and form a one-way linked list . And increase 、 Delete 、 Changing operations may damage the sorting of nodes and records , So the storage engine needs extra time to do some Record shift , Page splitting 、 Page recycling And other operations to maintain the sorting of nodes and records . If we build many indexes , Each index corresponds to B+ All trees need to be maintained , It will slow down performance .
6、 ... and . MySQL Rationality of data structure selection
6.1. Full table traversal
6.2. Hash structure
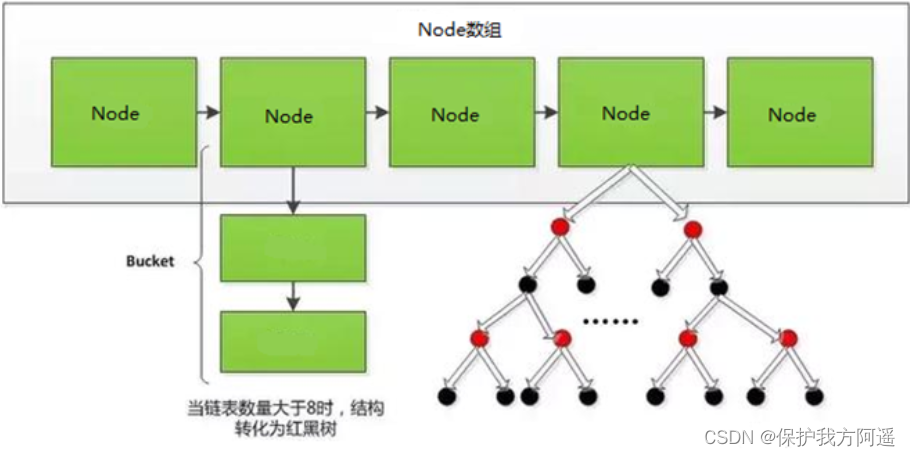
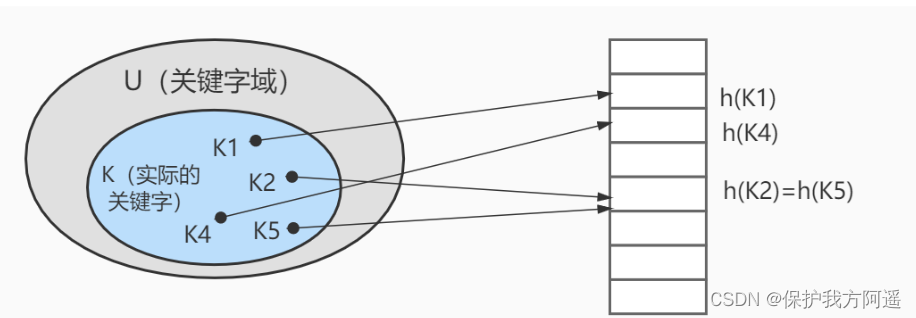
The hash function in the figure above h It is possible to map two different keywords to the same location , It's called Collision , Generally used in the database Link method To solve . In the link method , Put the elements hashed to the same slot in a linked list , As shown in the figure below :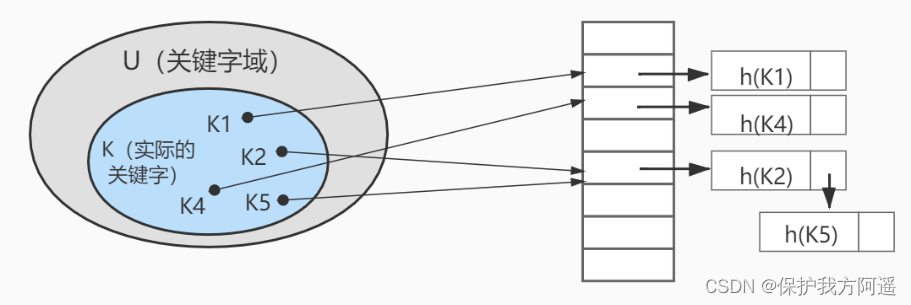
experiment : Experience arrays and hash Efficiency differences in table lookup
/ The algorithm complexity is O(n)
@Test
public void test1(){
int[] arr = new int[100000];
for(int i = 0;i < arr.length;i++){
arr[i] = i + 1;
}
long start = System.currentTimeMillis();
for(int j = 1; j<=100000;j++){
int temp = j;
for(int i = 0;i < arr.length;i++){
if(temp == arr[i]){
break;
}
}
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start)); //time: 823
}
// The algorithm complexity is O(1)
@Test
public void test2(){
HashSet<Integer> set = new HashSet<>(100000);
for(int i = 0;i < 100000;i++){
set.add(i + 1);
}
long start = System.currentTimeMillis();
for(int j = 1; j<=100000;j++) {
int temp = j;
boolean contains = set.contains(temp);
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start)); //time: 5
}
Hash High structural efficiency , Then why should the index structure be designed as a tree ?
Hash The index is applicable to the storage engine, as shown in the table :
| Indexes / Storage engine | MyISAM | InnoDB | Memory |
|---|---|---|---|
| HASH Indexes | I won't support it | I won't support it | Support |
Hash Applicability of index :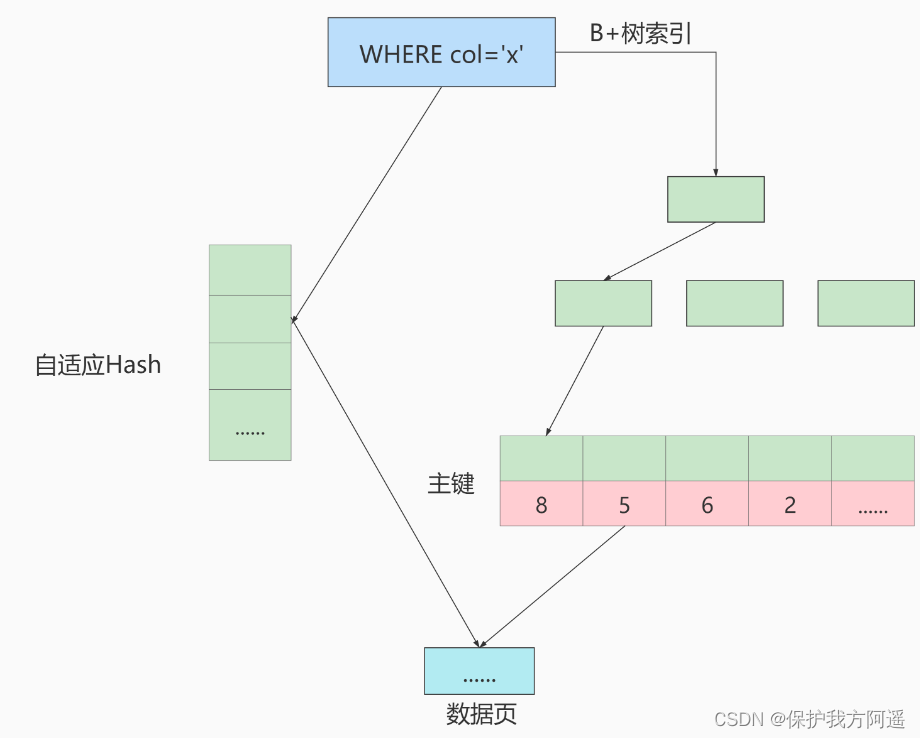
Use adaptive Hash The purpose of the index is to facilitate the indexing according to SQL The query conditions accelerate the positioning to leaf nodes , Especially when B+ When the tree is deep , Through adaptation Hash Indexing can significantly improve the efficiency of data retrieval .
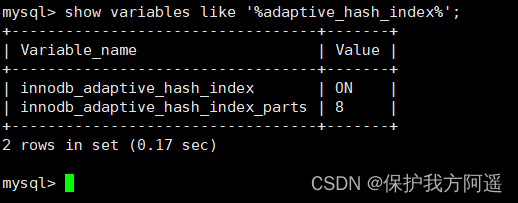
We can go through innodb_adaptive_hash_index Variable to see if adaptation is turned on Hash, such as :
show variables like '%adaptive_hash_index';
6.3. Binary search tree
If we use a binary tree as an index structure , So the disk IO The number of times is related to the height of the index tree .
- Features of binary search tree ;
- Find the rules ;
The binary search tree created is shown in the figure below :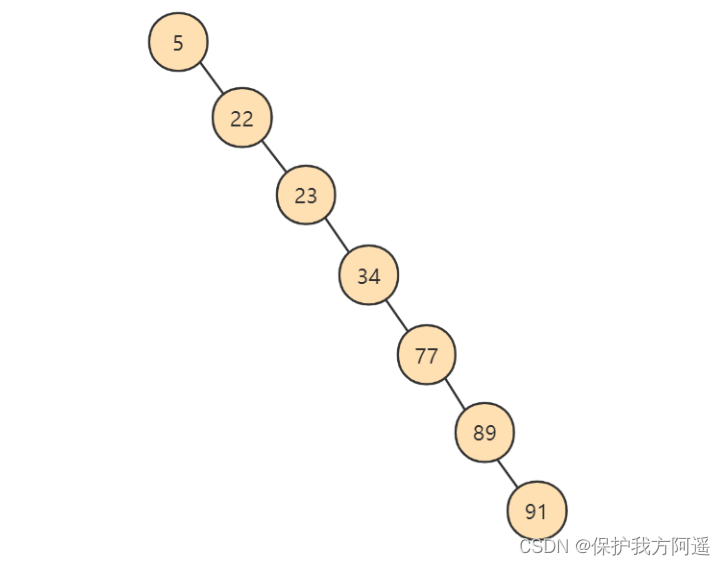
In order to improve the query efficiency , Need Reduce disk IO Count . To reduce the number of disks IO The number of times , You need to try to Lower the height of the tree , We need to turn the original “ Lanky ” The tree structure has changed “ Short and fat ”, The more forks in each layer of the tree, the better .
6.4. AVL Trees
 For the same data , If we change the binary tree to M Fork tree (M>2) Well ? When M=3 when , alike 31 Nodes can be stored by the following trigeminal tree :
For the same data , If we change the binary tree to M Fork tree (M>2) Well ? When M=3 when , alike 31 Nodes can be stored by the following trigeminal tree :
6.5. B-Tree
B The structure of the tree is shown in the figure below :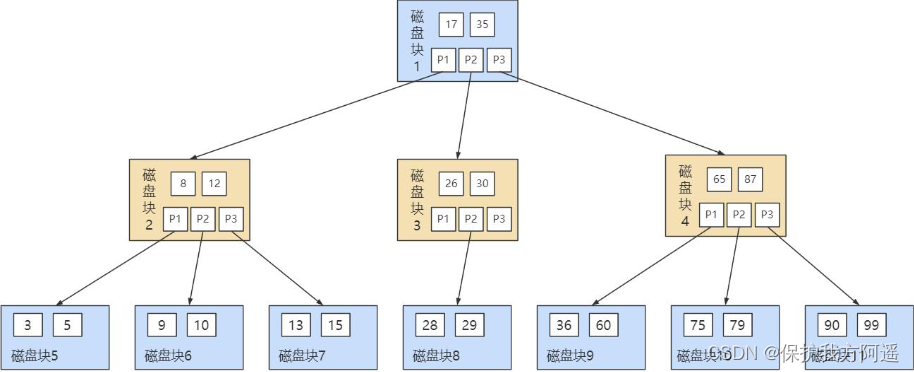 One M Step B Trees (M>2) It has the following characteristics :
One M Step B Trees (M>2) It has the following characteristics :
- The range of the number of sons of the root node is [2,M].
- Each intermediate node contains k-1 Two keywords and k A child , The number of children = Number of keywords +1,k The value range of is [ceil(M/2), M].
- Leaf nodes include k-1 Key words ( Leaf node has no children ),k The value range of is [ceil(M/2), M].
- Suppose the keyword of the intermediate node node is :Key[1], Key[2], …, Key[k-1], And the keywords are sorted in ascending order , namely Key[i]<Key[i+1]. when k-1 Keywords are equivalent to partitioning k Range , Which means k A pointer to the , That is to say :P[1], P[2], …,P[k], among P[1] The pointing keyword is less than Key[1] The subtree of ,P[i] Pointing to the keyword belongs to (Key[i-1], Key[i]) The subtree of ,P[k] The pointing keyword is greater than Key[k-1] The subtree of .
- All leaf nodes are on the same layer .
The picture above shows B A tree is a tree 3 Step B Trees . We can look at the disk blocks 2, The keyword inside is (8,12), It has 3 A child (3,5),(9,10) and (13,15), You can see (3,5) Less than 8,(9,10) stay 8 and 12 Between , and (13,15) Greater than 12, Just in line with the characteristics we just gave .
Then let's see how to use B Tree to find . Suppose we want to The search key is 9 , Then the steps can be divided into the following steps :
- We have keywords with the root node (17,35) Compare ,9 Less than 17 So get the pointer P1;
- Follow the pointer P1 Find the disk block 2, Keyword is (8,12), because 9 stay 8 and 12 Between , So we get the pointer P2;
- Follow the pointer P2 Find the disk block 6, Keyword is (9,10), And then we found the keyword 9.
You can see that the B During the search of the tree , We don't compare many times , But if you read out the data and compare it in memory , Time is negligible . Reading the disk block itself requires I/O operation , It takes more time than it takes to compare in memory , It is an important factor in the time of data search . B Compared with the balanced binary tree, the tree is more important I/O Operate less , It is more efficient than balanced binary tree in data query . therefore As long as the height of the tree is low enough ,IO Enough times , You can improve query performance .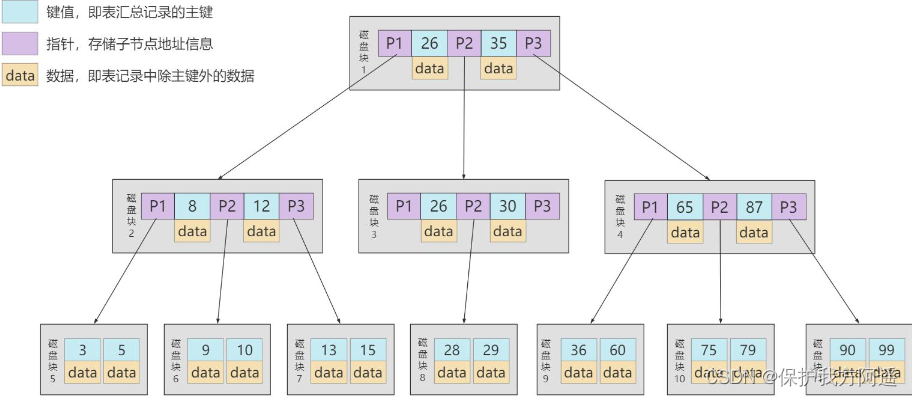
6.6. B+Tree
B+ Trees and B The difference between trees :
- Yes k A child's node has k Key words . That's the number of children = Key words , and B In the tree , The number of children = Key words +1.
- Keywords that are not leaf nodes also exist in child nodes , And it is the largest of all keywords in the child node ( Or the smallest ).
- Non leaf nodes are only used for indexing , Don't save data records , The information related to the record is placed in the leaf node . and B In the tree , A non leaf node holds both indexes , It also keeps data records .
- All keywords appear in the leaf node , Leaf nodes form an ordered list , And the leaf node itself links according to the size of keywords from small to large .
B Trees and B+ Trees can be used as data structures for indexes , stay MySQL It is used in B+ Trees .
but B Trees and B+ Each tree has its own application scenarios , Can't say B+ Trees are more than B Good tree , vice versa .
Thinking questions 1: In order to reduce the IO, Will the index tree be loaded at one time ?
Database indexes are stored on disk , If the amount of data is large , Inevitably, the size of the index will be very large , More than a few G.
When we use index queries , It's impossible to put all of them G All indexes are loaded into memory , All we can do is : Load each disk page one by one , Because the disk page corresponds to the node of the index tree .
Thinking questions 2:B+ What is the storage capacity of the tree ? Why do you usually look up row records , At most 1~3 Secondary disk IO
InnoDB The page size in the storage engine is 16KB, The primary key type of a general table is INT( Occupy 4 Bytes ) or BIGINT( Occupy 8 Bytes ),
The pointer type is also generally 4 or 8 Bytes , That is to say, a page (B+Tree One of the nodes in ) About storage in 6KB/(8B+8B)=1K Key value ( Because it's valuation ,
For ease of calculation , there K The value is 103. That is to say, a depth is 3 Of B+Tree Indexes can be maintained 103 *103 *103=10 One hundred million records .
( It is assumed that a data page also stores 103 Rows of data have been recorded ) In practice, each node may not be full ,
So in the database ,B+Tree The height of is usually in 2~4 layer .MySQL Of InnoDB The storage engine is designed to keep the root node in memory ,
That is to say, to find the row record of a key value, you only need to 1~3 Secondary disk IO operation .
Thinking questions 3: Why do you say B+ Tree ratio B- Tree is more suitable for file index and database index of operating system in practical application ?
1. B+ Tree's disk read and write costs less
B+ The internal node of the tree does not point to the specific information of the keyword . So its internal nodes are relative B The trees are smaller .
If all the keywords of the same internal node are stored in the same disk block , Then the disk block can hold more keywords .
The more keywords you need to look up when you read them into memory at one time . relatively speaking I0 The number of reading and writing is also reduced .
2. B+ Tree query efficiency is more stable
Because non endpoints are not the nodes that ultimately point to the contents of the file , It's just the index of keywords in the leaf node .
So any keyword search must take a path from root node to leaf node . All keyword queries
The path length is the same , The query efficiency of each data is equivalent .
Thinking questions 4:Hash Index and B+ The difference between tree indexes ?
1.Hash Index cannot be used for range queries , and B+ Trees can . This is because Hash The data that the index points to is out of order ,
and B+ The leaf node of a tree is an ordered list .
2.Hash Indexes do not support the leftmost principle of Federated indexes ( In other words, some indexes of the union index cannot be used ), and B+ Trees can .
For federated indexes ,Hash The index is calculating Hash When the value is the index key is merged and then calculated together Hash value ,
So it's not calculated separately for each index Hash value . So if you use one or more indexes of a federated index ,
The federated index cannot be used .
3.Hash Index does not support ORDER BY Sort , because Hash The data that the index points to is out of order ,
So it can't work as a sort optimization , and B+ The tree index data is ordered ,
Can play on the field ORDER BY The role of sorting optimization . Empathy ,
We can't use Hash Index for fuzzy query , and B+ Trees use LIKE When making fuzzy queries ,
LIKE After the fuzzy query ( such as % ending ) Then it can play an optimization role .
4.InnoDB Hash index is not supported .
Thinking questions 5:Hash Index and B+ Is the tree index manually specified when building the index ?
in the light of MySQL The default storage engine InnoDB, Or use MyISAM Storage engines will use B+ Tree to store , Can't use Hash Indexes .
InnoDB Provide adaptive Hash It doesn't need to be specified manually .
If it is Memory/Heap, Or is it NDB Storage engine , It's optional (Hash still B+ Trees ).
6.7. R Trees
R-Tree stay MySQL Rarely used , Support only geometry data type , The only storage engine that supports this type is myisam、bdb、innodb、ndb、archive several . Take up a R Examples that trees can solve in the real world : lookup 20 All restaurants within miles . without R What would you do with the tree ? In general, we will put the coordinates of the restaurant (x,y) It is divided into two fields and stored in the database , A field records longitude , Another field records latitude . In this way, we need to traverse all restaurants to get their location information , Then calculate whether the requirements are met . If an area has 100 In a restaurant , We're going to do 100 The second position calculation operation , If applied to Google 、 Baidu map is a huge database , This method must not be feasible .R Trees are good It solves the problem of high-dimensional space search . It is the B The idea of tree is well extended to multi-dimensional space , Adopted B The idea of tree dividing space , And add 、 Merge is used when deleting 、 Method of decomposing nodes , Ensure the balance of the tree . therefore ,R A tree is a tree used to A balanced tree that stores high-dimensional data . be relative to B-Tree,R-Tree The advantage is range finding .
| Indexes / Storage engine | MyISAM | InnoDB | Memory |
|---|---|---|---|
| R-Tree Indexes | Support | Support | I won't support it |
appendix : The time complexity of the algorithm
The same problem can be solved by different algorithms , The quality of an algorithm will affect the efficiency of the algorithm and even the program . The purpose of algorithm analysis is to select suitable algorithm and improve algorithm .
| data structure | lookup | Insert | Delete | Traverse |
|---|---|---|---|---|
| Array | O(N) | O(1) | O(N) | ----- |
| Ordered array | O(logN) | O(N) | O(N) | O(N) |
| Linked list | O(N) | O(1) | O(N) | ----- |
| Ordered list | O(N) | O(N) | O(N) | O(N) |
| Binary tree ( General situation ) | O(logN) | O(logN) | O(logN) | O(N) |
| Binary tree ( The worst ) | O(N) | O(N) | O(N) | O(N) |
| Balance tree ( General and worst case ) | O(logN) | O(logN) | O(logN) | O(N) |
| Hashtable | O(1) | O(1) | O(1) | ----- |
边栏推荐
- text 文本数据增强方法 data argumentation
- MySQL27-索引優化與查詢優化
- pytorch的Dataset的使用
- Export virtual machines from esxi 6.7 using OVF tool
- Technology | diverse substrate formats
- MySQL ERROR 1040: Too many connections
- MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?
- 再有人问你数据库缓存一致性的问题,直接把这篇文章发给他
- Baidu Encyclopedia data crawling and content classification and recognition
- [programmers' English growth path] English learning serial one (verb general tense)
猜你喜欢
![[Julia] exit notes - Serial](/img/d0/87f0d57ff910a666fbb67c0ae8a838.jpg)
随机推荐
Mysql35 master slave replication
Baidu Encyclopedia data crawling and content classification and recognition
Google login prompt error code 12501
MySQL实战优化高手10 生产经验:如何为数据库的监控系统部署可视化报表系统?
MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd0 in position 0成功解决
Redis集群方案应该怎么做?都有哪些方案?
14 医疗挂号系统_【阿里云OSS、用户认证与就诊人】
Use of dataset of pytorch
Pytoch LSTM implementation process (visual version)
软件测试工程师发展规划路线
简单解决phpjm加密问题 免费phpjm解密工具
16 医疗挂号系统_【预约下单】
数据库中间件_Mycat总结
MySQL底层的逻辑架构
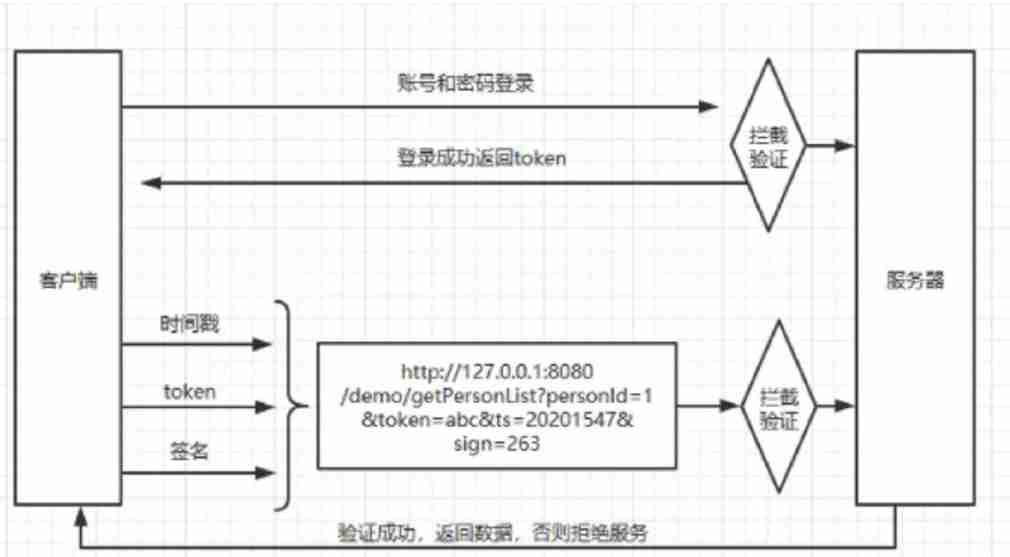
Security design verification of API interface: ticket, signature, timestamp
[after reading the series] how to realize app automation without programming (automatically start Kwai APP)
MySQL30-事务基础知识
Mysql34 other database logs
[C language] deeply analyze the underlying principle of data storage