当前位置:网站首页>Es FAQ summary
Es FAQ summary
2022-07-07 07:59:00 【Immature programmers】
1、elasticsearch To understand how much , Talk about your company es Cluster architecture of , Index data size , How many pieces are there , And some Tuning Tools .
interviewer : I want to know what I have been in touch with before ES Use scenarios 、 scale , Have you ever done a relatively large-scale index design 、 planning 、 tuning . answer : Answer according to your own practice . such as :ES Cluster architecture 13 Nodes , Indexes are based on different channels 20+ Indexes , According to the date , Increase daily 20+, Indexes :10 Fragmentation , Increase daily 1 Billion + data , Index size control per channel per day :150GB within .
Only index level tuning means
1.1、 Design phase tuning
1) According to the incremental demand of business , Take index creation based on date template , adopt roll over API Scroll index ;
2) Use aliases for index management ;
3) Do the index regularly every morning force_merge operation , To free up space ;
4) Take the cold and hot separation mechanism , Hot data stored in SSD, Improve retrieval efficiency ; Cold data is done on a regular basis shrink operation , To reduce storage ;
5) take curator Index life cycle management ;
6) Only for fields that need word segmentation , Set up the word breaker reasonably ;
7)Mapping The stage fully combines the properties of each field , Need to retrieve 、 Need to store etc . ………
1.2、 Write tuning
1) The number of copies before writing is set to 0;
2) Close before writing refresh_interval Set to -1, Disable refresh mechanism ;
3) While writing : take bulk Batch write ;
4) Number of recovery copies after write and refresh interval ;
5) Try to use auto generated id.
1.3、 Query tuning
1) Ban wildcard;
2) Disable batch terms( Hundreds of scenes );
3) Make full use of inverted index mechanism , can keyword Type as much as possible keyword;
4) When there's a lot of data , The index can be determined based on time before retrieval ;
5) Set up a reasonable routing mechanism .
1.4、 Other tuning
Deployment tuning , Business promotion, etc .
Part of the above mentioned , The interviewer will basically evaluate your previous practice or operation and maintenance experience .
2、elasticsearch What is the inverted index of
#### interviewer : Want to understand your understanding of basic concepts . answer : A popular explanation will do .
Our traditional retrieval is through articles , One by one to find the location of the corresponding keywords . And inverted index , It's through word segmentation , It forms the mapping table of words and articles , This kind of Dictionary + The mapping table is the inverted index . With inverted index , Can achieve o(1) Time complexity efficiency of retrieving articles , Greatly improve the efficiency of retrieval .
The academic solution :
Inverted index , On the contrary, what words does an article contain , It starts with words , It records the documents in which the word appeared , It's made up of two parts —— Dictionaries and inverted tables .
pluses : The underlying implementation of inverted index is based on :FST(Finite State Transducer) data structure . lucene from 4+ The data structures that have been widely used since the release are FST.FST There are two advantages :
1) Small space occupation . Through the reuse of prefixes and suffixes in dictionaries , Compressed storage space ;
2) Fast query speed .O(len(str)) The query time complexity of .
3、elasticsearch What to do if there is too much index data , How to tune , Deploy
interviewer : Want to understand the operation and maintenance capacity of large data volume . answer : Planning of index data , We should make a plan in the early stage , As the saying goes “ Design first , Code after ”, In this way, we can effectively avoid the impact on online customer retrieval or other businesses caused by the sudden data explosion resulting in the lack of cluster processing power . How to tune , Just like the question 1 said , Let's zoom in here :
3.1 Dynamic index level
Based on the template + Time +rollover api Scroll to create index , give an example : Design phase definition :blog The template format of the index is :blog_index_ The form of timestamps , Increasing data every day .
The benefits of doing this : It is not necessary to increase the data volume so that the data volume of a single index is very large , Close to online 2 Of 32 The next power -1, Index storage has reached TB+ Even larger .
Once a single index is large , Storage and other risks come with it , So think ahead + Avoid... Early .
3.2 Storage level
Separate storage of hot and cold data , Thermal data ( Like recently 3 Days or weeks of data ), The rest is cold data . No new data will be written for cold data , Consider regular force_merge Add shrink The compact operation , Save storage space and retrieval efficiency .
3.3 Deployment level
Once there's no plan , This is the emergency strategy . combination ES Its own features of supporting dynamic expansion , Dynamic addition of machines can relieve the cluster pressure , Be careful : If the previous master node planning is reasonable , Dynamic addition can be completed without restarting the cluster .
4、elasticsearch How to achieve master Elected
interviewer : Want to know ES The underlying principle of clustering , No longer focusing on the business side . answer : The premises :
1) Only candidate primary nodes (master:true) The node of can become the master node .
2) Minimum number of master nodes (min_master_nodes) The aim is to prevent brain crack .
I've read all kinds of online analysis versions and source code analysis books , The fog . Check the code , The core entrance is findMaster, Select the master node to return the corresponding Master, Otherwise return to null. The election process is roughly described as follows :
First step : Confirm that the number of candidate main nodes is up to the standard ,elasticsearch.yml Set the value of the discovery.zen.minimum_master_nodes;
The second step : Compare : First, determine whether there is master Qualifications , Priority return with candidate master node qualification ; If both nodes are candidate primary nodes , be id A small value will be the primary node . Notice the id by string type .
Digression : Access to the node id Methods .
5、 Describe in detail Elasticsearch The process of Indexing Documents
interviewer : Want to know ES The underlying principle of , No longer focusing on the business side . answer : The index document here should be understood as document writing ES, The process of creating an index . Document write contains : Single document writing and batch bulk write in , Here's just an explanation : Single document writing process .
Remember this picture in the official document .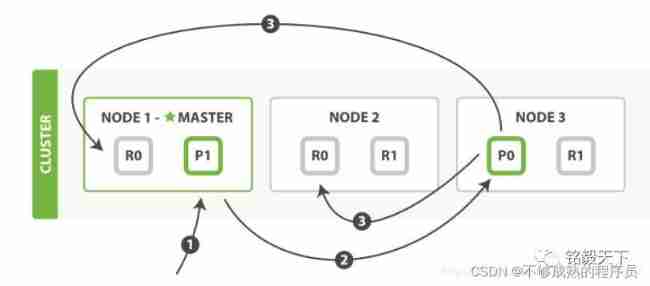
First step : The client writes data to a node of the cluster , Send a request .( If no route is specified / Coordinate nodes , The requested node acts as the routing node .)
The second step : node 1 After receiving the request , Using document _id To make sure that the document belongs to fragment 0. The request will be transferred to another node , Suppose the node 3. So slice 0 The main partition of is assigned to the node 3 On .
The third step : node 3 Perform write operations on the main shard , If it works , Then forward the request to the node in parallel 1 And nodes 2 Copy on shard , Wait for the result to return . All copies are reported as successful , node 3 Will be directed to the coordination node ( node 1) Report success , node 1 Report write success to requesting client .
If the interviewer asks again : In the second step, the process of document segmentation ? answer : Get... By routing algorithm , Routing algorithm is based on Routing and documents id Calculate the slice of the target id The process of .
1shard = hash(_routing) % (num_of_primary_shards)
6、 Describe in detail Elasticsearch The search process ?
interviewer : Want to know ES The underlying principle of search , No longer focusing on the business side .
answer : The search is broken down into “query then fetch” Two phases . query The purpose of the phase : Positioning to position , But not . The steps are as follows :
1) Suppose an index data has 5 Lord +1 copy common 10 Fragmentation , A request will hit ( In the main or copy shards ) One of the .
2) Each segment is queried locally , The result is returned to the local ordered priority queue .
3) The first 2) The result of the step is sent to the coordination node , The coordination node generates a global sort list .
fetch The purpose of the phase : Take the data . The routing node gets all the documents , Return to the client .
7、Elasticsearch At deployment time , Yes Linux What are the optimization methods for the setting of
interviewer : Want to know right ES The operation and maintenance capacity of the cluster . answer :
1) Turn off caching swap;
2) Heap memory is set to :Min( Node memory /2, 32GB);
3) Set the maximum number of file handles ;
4) Thread pool + The queue size is adjusted according to the business needs ;
5) Disk storage raid The way —— Storage conditional use RAID10, Increase single node performance and avoid single node storage failure .
Reprint article connection
边栏推荐
- 2022焊工(初级)判断题及在线模拟考试
- Idea add class annotation template and method template
- 【VHDL 并行语句执行】
- Solution: could not find kf5 (missing: coreaddons dbusaddons doctools xmlgui)
- Iterable、Collection、List 的常见方法签名以及含义
- 图解GPT3的工作原理
- 【经验分享】如何为visio扩展云服务图标
- Linux server development, SQL statements, indexes, views, stored procedures, triggers
- php导出百万数据
- Kbu1510-asemi power supply special 15A rectifier bridge kbu1510
猜你喜欢
![[2022 ciscn] replay of preliminary web topics](/img/1c/4297379fccde28f76ebe04d085c5a4.png)
[2022 ciscn] replay of preliminary web topics
【斯坦福计网CS144项目】Lab3: TCPSender
Force buckle 145 Binary Tree Postorder Traversal
![[mathematical notes] radian](/img/43/2af510adb24fe46fc0033d11d60488.jpg)
[mathematical notes] radian
图解GPT3的工作原理
有 Docker 谁还在自己本地安装 Mysql ?
解决问题:Unable to connect to Redis
Linux server development, SQL statements, indexes, views, stored procedures, triggers

What are the positions of communication equipment manufacturers?
Detailed explanation of uboot image generation process of Hisilicon chip (hi3516dv300)
随机推荐
开源生态|打造活力开源社区,共建开源新生态!
[webrtc] M98 screen and window acquisition
【经验分享】如何为visio扩展云服务图标
[matlab] when matrix multiplication in Simulink user-defined function does not work properly, matrix multiplication module in module library can be used instead
Figure out the working principle of gpt3
[SUCTF 2019]Game
Linux server development, SQL statements, indexes, views, stored procedures, triggers
LeetCode 90:子集 II
Most elements
Cnopendata geographical distribution data of religious places in China
Linux server development, MySQL index principle and optimization
C language flight booking system
[mathematical notes] radian
Operation suggestions for today's spot Silver
2022焊工(初级)判断题及在线模拟考试
Thinkcmf6.0安装教程
Leetcode 43 String multiplication (2022.02.12)
[unity] several ideas about circular motion of objects
Linux server development, redis source code storage principle and data model
leetcode:105. Constructing binary trees from preorder and inorder traversal sequences