当前位置:网站首页>Explore Cassandra's decentralized distributed architecture
Explore Cassandra's decentralized distributed architecture
2022-07-07 07:48:00 【Guardian stone】
The father of relational models Edgar F. Codd, stay 1970 year Communications of ACM Published on 《 The relational model of large shared database data 》, It has become an eternal classic , The semantic design of relational model is easy to understand , Syntactically nested 、 closed loop 、 complete , So in the field of database , Relational models have been popular for several years .
After that ,IT There are many very famous RDBMS( Relational database system ), It includes Oracle、MySQL、SQLServer、DB2、PostgreSQL etc. .
1. The distributed bottleneck of traditional relational database
however RDBMS Due to architectural constraints , A lot of problems , for example : The constraints of the relational model must clearly define the attributes before design , It's hard to be like many NoSQL equally , With flexible and variable mode , It is difficult to adapt to the needs of agile iteration .
In fact, the most difficult problem to solve , That is, the distribution of data tables .
Why did this happen ?
Essentially , Due to the strong correlation of the relational model in the early design , As a result, the connection between tables becomes extremely tight .
for example : There is a common business scenario in which connection operations , adopt A->B->C Association search of , However, the chain formed by this connection , will A、B、C Tightly tied together .
So what problems does this close relationship bring ?
That's it RDBMS At the beginning of the design , It is difficult to consider the communication decoupling design of data table in distributed network environment , It's just a simple data table local file IO scanning , And in the past low bandwidth network environment , Distributed model relationships , It's even harder to imagine .
As shown in the figure below :
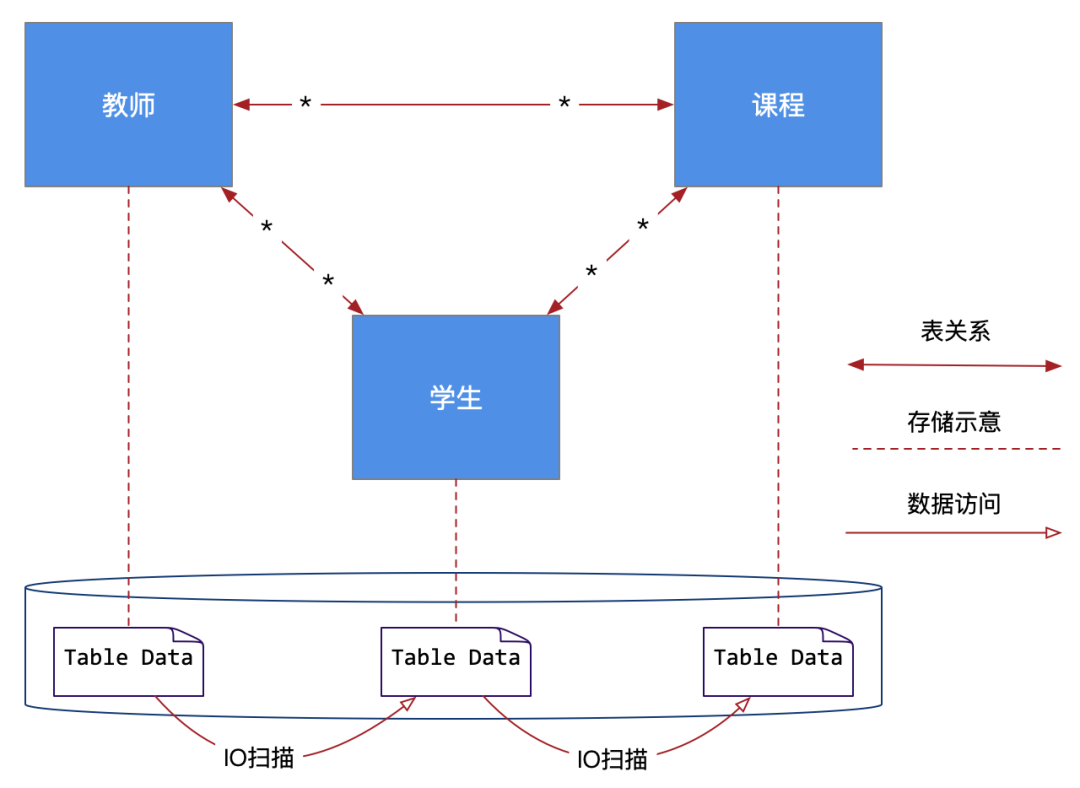
We can see from the picture above , Teachers' 、 The three tables of students and courses have a close relationship of many to many ( There are also some intermediate tables that are not shown ), Then this close relationship is projected to the specific physical files of the database , That is, multiple physical table files in the figure (Table Data), When we query , It is through relational logic that these table files are frequently IO scanning .
In this mode , We'll find a problem , These tables are actually difficult to split distributed across databases , in other words ,RDBMS It's hard to be distributed , Put the teacher list on the server 1 The database of 1 On , Put the student list on the server 2 The database of 2 On , Put the curriculum on the server 3 The database of 3 On .
And what is more difficult is : take 1 Ten thousand students in total 10 The student class data generated by 10000 course activities are divided into 10 individual 1 Ten thousand data sheets , Then distribute the tables in different databases .
As shown in the figure below :
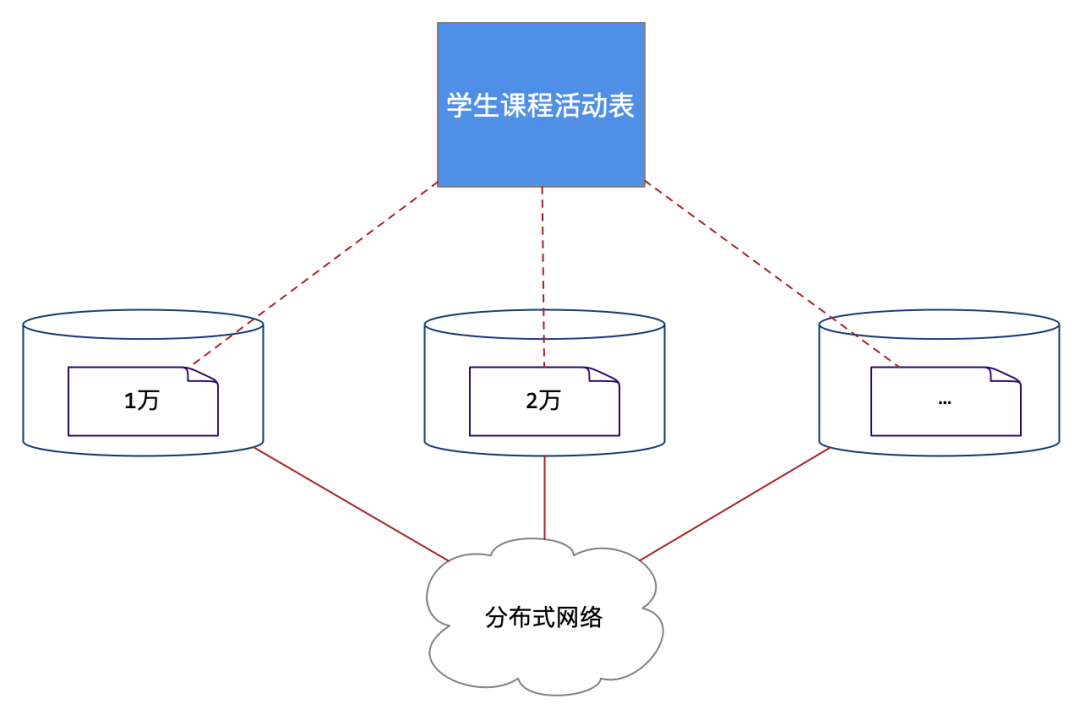
Let's make a hypothesis : If you can split the student course activity table into multiple database instances in the distributed network , Then the load of a single database is greatly reduced . This is very important for the application system with large-scale access and data volume .
However, for RDBMS Come on , The realization of this hypothetical goal is a very painful and difficult thing , for example : We can search a lot about MySQL Sub database sub table article , The theme of this kind of article is right RDBMS Conduct Distributed partition operation .
But this kind of operation is not naturally supported by the database , Professional data engineer team must be established , Spend a lot of time on the precise adjustment of the database , We must solve many problems of distributed clusters by ourselves , for example : Fault tolerance 、 Copy 、 Partition 、 Uniformity 、 Distributed transactions and so on , It's hard to imagine , So this is not the huge maintenance cost that ordinary technology enterprises can bear .
With the development of Internet era , Internet application system is oriented to high concurrency 、 The large-scale trend of massive data is getting stronger ,RDBMS The bottleneck of distributed data table is becoming more and more obvious , And that leads to NoSQL Rapid development in Internet and other fields , Let's focus on NoSQL Solutions for .
2. Disadvantages of centralized distributed architecture
2.1 Hadoop distributed file system (HDFS)
Talking about the distributed database system in the field of big data , It's bound to go around Hadoop,Hadoop In fact, it is a system ecosystem , be based on Hadoop All kinds of distributed databases of the ecosystem depend on a data base ——HDFS, In fact, the earliest Google Invented GFS After the distributed file system , Published papers , Then in the open source world Hadoop distributed file system (HDFS).
As shown in the figure below :GFS/HDFS It is characterized by order 、 Lumped 、 Write data to file block without index , And in the cluster environment by block (block) Evenly distributed storage , When needed , Re pass MapReduce、Spark These batch engines initiate parallel tasks , By block , Read the analysis in batches . This gives full play to the performance of writing and parallel reading , With any index of the database can not match the speed of reading and writing .
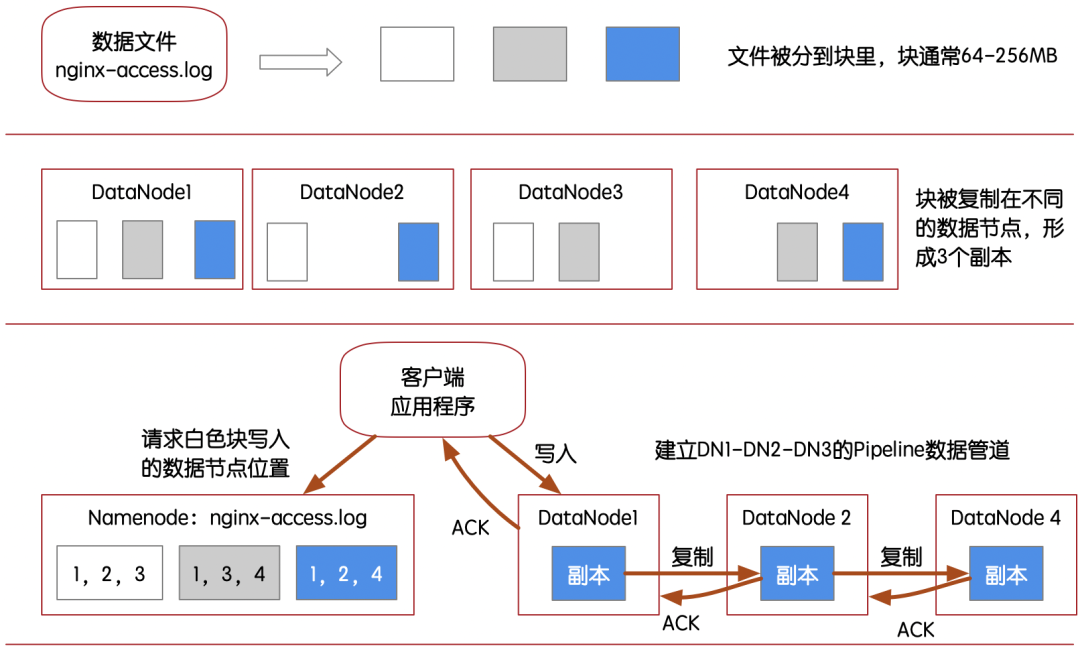
HDFS On multiple data nodes (DataNode) Coordinate the process of writing data , It must be a centralized service that performs global scheduling , That's it NameNode node .
in other words NameNode Nodes can be a single point of risk , If something goes wrong , Whole HDFS The distributed file system cluster will crash .
therefore HDFS in order to NameNode High availability (HA), It realizes extremely complex NameNode HA framework .
however , At the same time , There can only be one NameNode Provide scheduling support for writing all data , That is to say, from the perspective of concurrent load ,NameNode It will always be a bottleneck .
because HDFS As a whole Hadoop Ecological data base , that Hadoop The distributed architecture of is always moving forward on the route of distributed centralization , However, the biggest problem of centralized architecture is that no matter how the superstructure changes , After transmission to the data base ,HDFS As the central manager , It must be in high concurrency 、 In the case of large-scale access, it becomes a bottleneck .
In addition, there are hidden dangers in the scaling and expansion of cluster nodes , The problem comes from metadata in NameNode Overflow may occur in memory .
2.2 Large scale structured distributed database (HBase)
However HDFS It is block oriented big file data , Add read and write without index , It doesn't have the ability to search data randomly , In addition, there is a lack of structural design mechanism , Like a collection of data items scanning 、 Statistics and analysis cannot be supported independently , We must build the upper database system to complete , Therefore, the famous HBase.
As shown in the figure below : We can see from the picture HBase Our data base completely depends on HDFS, In other words, how data is physically distributed is determined by HDFS Determined by .
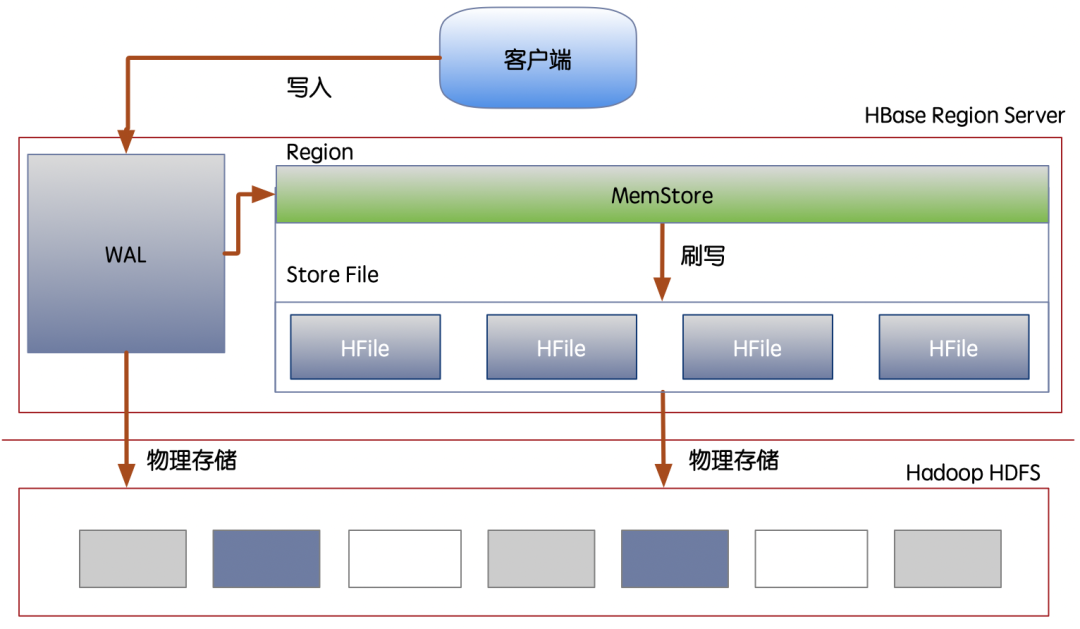
HBase Realize the global sorting K-V Model , Meet the storage conditions of massive data, and locate the results through line keys , Database with millisecond response , Or the statistical grouping is realized by sorting and scanning the primary key .
Even though HBase For writing large-scale structured data 、 Sorting scanning and aggregation analysis have great performance advantages , however HBase The search design goal of is not to solve the large-scale search of secondary index .
We'll see HBase How to complete data segmentation ——Region segmentation , When Region( We can understand it as data table ) After the additional data exceeds the threshold , It's going to be Region Split , Then split out the new Region Distribute to others RegionServer in .
Here are two questions :
1) At the same time to Region The server that writes new data must be unique , Then there will be RegionServer High concurrency access bottleneck .
2) Due to the constraints of distributed architecture design , bring HBase No secondary index , In the process of random search , Only according to the overall situation Region Sort for scanning , This cannot bear Web The real-time performance of random search of applied data .
therefore HBase Generally, it will be imported in the form of large-scale data flow OLAP System .
3. Decentralized distributed architecture analysis
So is there a kind of structured data storage for massive data , Can achieve large scale Web Application supported distributed database architecture ?
It can break through RDBMS The bottleneck of data table in the distributed process , It can solve Hadoop/HBase Hidden dangers in high availability , At the same time, it can also meet the high concurrency 、 On a large scale 、 A wide range of random search requirements .
The answer is yes !
It's the paper that changed the development process of the Internet 《Dynamo: Amazon's Highly Available Key-value Store》, This paper comes from Amazon, Summary of experience in the architecture design of your own database .
Famous distributed open source database Cassandra In terms of distributed design, it also fully inherits the design idea of this paper , But in terms of data model, it draws lessons from Google BigTable Data model of .
Cassandra The core idea of distribution is decentralization , It forms a unique side of the distributed system world .
Our focus is to analyze some core technologies of this decentralized distributed architecture , How powerful it is , Why can we solve the three problems mentioned above :
- Support large-scale structured data
- Solve the distributed read-write storage of data tables
- High concurrency 、 On a large scale 、 Large scale random search .
3.1 What is decentralization ?
The core characteristic of decentralization different from centralization is that any service instance is peer-to-peer in the cluster network 、 Point to point forms exist , There is no hierarchy of service nodes in the cluster , in other words , Any one of them Cassandra Service node , From the perspective of defenders, they all play the same role , This greatly reduces the complexity of maintainer operation and maintenance .
for example : We have to Cassandra All nodes of the database can be called data nodes , The cluster plays the same role .
however HBase/HDFS Not so ,HDFS Clusters are divided into :NameNode、DataNode、JournalNode、ZKFC、Zookeeper Etc. assume different roles of the cluster ;HBase The cluster is divided into :HMaster、HRegionServer、Zookeeper Etc. assume different roles of the cluster .
From the perspective of the maintainer , It must be easier to maintain when the cluster roles are unified .
Another feature of decentralization is high availability , Scalability is also very good , Cluster expansion is almost unlimited .
When there is no central node for scheduling , And ensure such excellent high availability 、 Scalability , So how does it do it ?
In principle Cassandra It is mainly manifested in four aspects :
- The consistent hash ring mechanism is used to realize the partition distribution of data and the data migration of expansion and contraction .
- utilize gossip The protocol maintains the consistency of cluster state under the network propagation of peer nodes .
- utilize anti-entropy( Anti entropy ) The mechanism realizes the comparison between nodes in the process of data reading , Ensure data consistency .
- be based on hinted handoff Mechanism , Follow the pattern of final consistency , It can greatly improve the cluster availability .
The above features are that the network nodes in the cluster are peer-to-peer , Based on consensus mechanism , Instead of the state coordination formed by management scheduling .
Under this mechanism , Cluster has excellent high availability and scalability , in other words , For the whole cluster , Whether it's capacity expansion or adding many network nodes , Or the sudden failure reduces many network nodes , The relationship between network nodes is weak , It will be difficult to form a health impact on other nodes , It is almost imperceptible to users .
From the characteristics of decentralization , Let's compare HBase And what it depends on Hadoop HDFS, This centralized scheduling management based on centralization ,HBase There is a HMaster Cluster single point of failure risk , So in general HBase Of HMaster There can be one or more HA Hot standby , Although introduced HA After HBase The cluster is still robust , It just inevitably introduces higher deployment complexity , The bottom layer depends on HDFS NameNode HA The complexity of service deployment is even more .
Increasing the complexity of distributed systems will only bring more complex and uncertain operation and maintenance problems .
3.2 Zoning mechanism
Cassandra In the process of implementing decentralized architecture , The key application goal is based on the large-scale writing ability of structured data , It can also support random search of large-scale massive data , This is completely different from HBase 了 , in fact HBase Is for OLAP The support of business scenarios achieves a distributed extreme performance .
however Cassandra Then it completely enters another state , That is for large-scale OLTP The business has achieved strong support , It can be in milliseconds 、 Second level 、 The sub second range promises to read 、 Write and distribute transactions SLA( Service level agreements ).
Uniformity Hash Ring
As shown in the figure below :Cassandra The distribution of is based on the ring structure formed by consistent hash .
Each node seems to be distributed on a ring . Each node is peer-to-peer , In the process of reading and writing , Each node is a coordination node facing the client , And directly form a single hop with all other nodes , This is also Amazon Dynamo The key distributed architecture design in this paper .
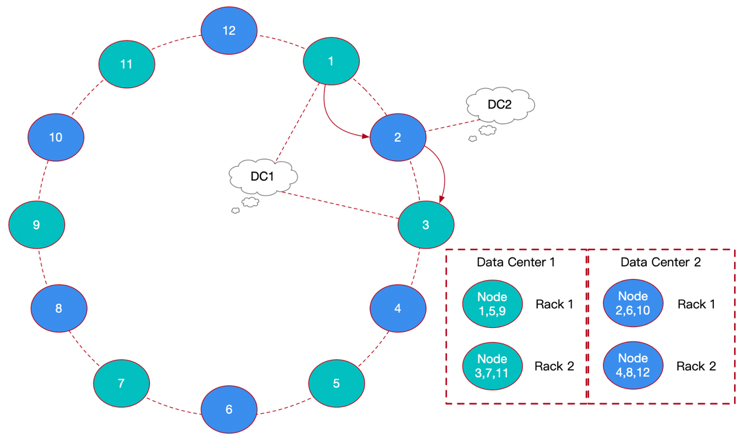
As can be seen from the picture above 12 Nodes are distributed in Data Center1,Data Center2 Four racks in two data centers (Rack) On , And pass DynamoDB The consistency hash ring of the cluster is connected in a distributed database .
The above figure is an example of the data writing process , The first copy is located at the node 1(DC1,Rack1) On , Then the second copy will continue to follow the ring , And locate at the node 2(DC2,Rack1) On , Finally, the third copy needs to be in DC1 Give priority to find Rack2 The node location of , Just positioned at the node 3(DC1,Rack2) On . Find the positioning through the ring clockwise , Three copies in DC1、DC2 Stored separately in , stay DC1 Of Rack1、Rack2 Alternate storage on .
By using this cross data center (DC) Replica configuration mechanism , So that the cluster has a stronger disaster tolerance capability , The support for large application platforms also has the advantages of load balancing and high availability ; The same DC Copies of data will be in different Rack Alternate storage on nodes , In order to consolidate the security of data distribution in the cluster .
So this Hash After partition , What advantages will it bring from the perspective of load balancing ? Let's move on .
Load balancing case
As shown in the figure below : This is an application scenario of an internet medical platform .
We applied Cassandra, The table is designed with a composite primary key ,Group by Hash The partitioning key ,id Is the sort key .
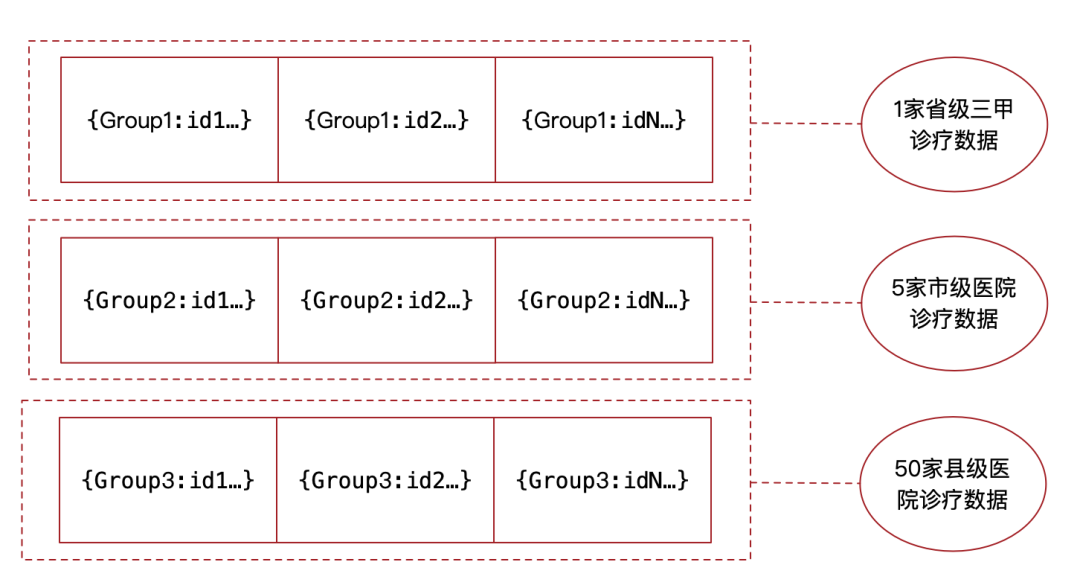
Because we are Cassandra It stores a large number of diagnosis and treatment data between doctors and patients in many hospitals , Tradition RDBMS There will be a single point of writing in the diagnosis and treatment table , The bottleneck that cannot balance the load .
however Cassandra This kind of Hash Partitions are different , We can partition the diagnosis and treatment data into 3 Read and write on different data nodes , Among them, set the most visited 1 Third class hospital Hash The partition key is Group1,5 The number of visits of municipal hospitals is enough to benchmark the provincial third-class hospitals , Put this 5 Family composition Hash The partitioning key Group2, other 50 The number of visits to county-level hospitals has also formed a sufficient number of visits , form Hash The partitioning key Group3.
Then through the Hash Partition form , All diagnosis and treatment data can be segmented in the form of hospital grouping , It's time to balance the load 3 Server Cassandra Data nodes .
Secondly, we use the diagnosis and treatment number (id) As sort key , As long as it is the diagnosis and treatment data of the same partition , No matter which hospital's diagnosis and treatment data is scanned , According to id Perform a sort scan , Sorting data is also easier to statistical analysis .
Fail over
As shown in the figure below : In the consistent hash ring, we set 4 Nodes , Then the hash range is defined as :Node1-Node2,Node2-Node3,Node3-Node4,Node4-Node1.
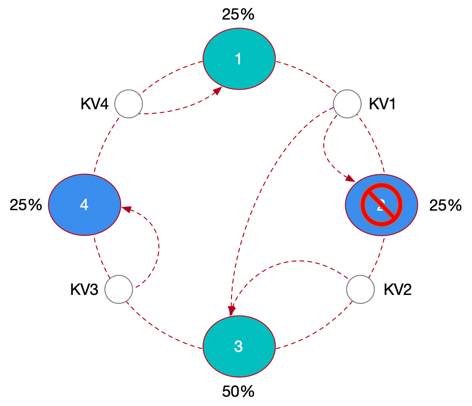
as long as KV The primary key of the data Hash The value falls within a certain range , You will find the node landing at the end of the range clockwise . But here's the problem , node 2 Offline due to fault , Through the backup mechanism, we can connect nodes 2 The data is restored , But according to the consistent hash algorithm , Can only be transferred to node 3 On , Then the node 3 It hosts the whole cluster 50% The amount of data , Obviously, there is a serious tilt in the data distribution .
therefore Cassandra In consistency Hash Virtual nodes are added on the basis of , for example :Cassandra The default partition policy will be created 1024 Virtual nodes (Token), take -2^63~2^63-1 Average the range value of , this 1024 individual Token It is equally distributed to this 4 Nodes , This leads to the phenomenon that all nodes appear alternately and evenly in the consistent hash ring , In this way, if the fault in the above figure occurs again , Fault node 2 The replica data on will not be recovered , Full pressure at node 3 On , But at the node 1、3、4 Digest evenly .
All in all
Cassandra Use the partition key to Hash Partition realizes the load balancing of data in different data nodes , Through improved consistency Hash Algorithm and structure , Make data nodes expand or shrink , Both make the change and migration of the overall data of the cluster very small , It also gracefully forms a remote disaster recovery mechanism for multiple data centers .
We are looking at Cassandra On the core advantages of , It lies in the balance of large-scale data access formed by decentralized peer nodes , And the low-cost maintenance feature of scalability , In essence , They are all very conducive to the formation of non service distributed database services for cloud manufacturers .
3.3 Uniformity
Amazon Dynamo The original intention of this paper is to create a ultimately consistent distributed database system , But it also supports distributed strong consistency .
Again , about Cassandra Application , I do not recommend that strong consistency be the main application consideration , Because strong consistency is important for network bandwidth , Client request latency has large resource consumption and unpredictable problems .
So what is distributed consistency ?
CAP Theorem
We are in the process of researching and applying distributed architecture , about CAP Theory must be used as a basic concept to strengthen understanding .
CAP: Uniformity (Consistency), Usability (Availability) And partition fault tolerance (Partition Tolerance).
I can understand in this way CAP: For clustered systems , The phenomenon of inaccessible network partitions is inevitable in the future , When failure occurs , Just about to carry out a distributed business , For example, multi copy replication , The data of different nodes will be inconsistent .
In order to ensure the fault tolerance of partitions , We have only two choices :
The first is to wait for the partition of the failed node to recover , Otherwise, no feedback will be given to the client , It is proved that we guarantee strong consistency .
The second case is that the partition of the node with unequal failure is restored , First, return the message that the client has completed writing , After the failure node recovers , Then recover the data by yourself , It proves that we guarantee high availability .
So when the partition needs fault tolerance , We only have CP perhaps AP Two options .
For high availability systems , We mainly guarantee AP; For strongly consistent systems , We mainly guarantee CP(HBase Strong consistency design ).
Consistency method comparison
We said before ,Cassandra It mainly meets the final consistency , That is to say, when the data is written to a node or replicated, it does not exceed half the number of cluster replicas , The result of successful writing can be fed back to the client , therefore , The period during which the copy is not completely completed , It is likely that other nodes or the other half of the nodes are still providing expired data for reading by another client .
Actually Cassandra There's another one called QUORUM Consistency of levels , Only after more than half of the nodes are written successfully, the client will be reported as successful , Similarly, when reading, more than half of the nodes must be consistent before returning the reading result , Once there is an intersection between reading and writing , The data that the client always reads is the data written successfully , In fact, this model is the best balance between final consistency and strong consistency .
As shown in the figure below :

The first case in the above figure is Cassandra Of QUORUM Level , When reading a copy , Must read 3 Nodes , If 3 Nodes are inconsistent , It must wait for the last old node to be copied successfully ,3 Nodes will be consistent , To return results .
The second case in the figure above is a typical final consistency , This is a case where less than half of the nodes are written and a success is returned , When the first client write node returns successfully , Without copying to the other half of the node , The data that the second client may read is still two different 2 Expired data of nodes .
All in all
Ultimately, consistency will inevitably lead to less consumption of network resources , It also reduces the unpredictability of network partition errors , Improve the high availability of the cluster . But you may read expired data .
So what kind of application scenario will be suitable for final consistency ? In fact, one of the most common scenes is : The shopping cart !
Shopping cart may be in a very small probability , Read your expired data , But it doesn't affect the user's end use experience , Because shopping cart is not the end of e-commerce process , But it must be one of the most frequently operated businesses , In the end, only when the order is confirmed does it count .
Same as : Social networks 、 game 、 We-Media 、 This is the case with the Internet of things , This large-scale online data business , It is not necessary to ensure strong consistency in reading and writing , In case of inconsistency in reading and writing , Maybe visit again , The data is correct , But the cluster ensures fast response to customers in large-scale access scenarios , At this point , have RDBMS Incomparable natural advantages .
4. Last
The idea of distributed decentralized architecture is not only applied to the distributed database system of massive scale structured data , In fact, it is also applied in other fields .
for example : As a memory dictionary Redis Also has the Redis Cluster This decentralized distributed architecture ,Redis Cluster The main value of is also for better load and high concurrency business , for example : seckill 、 Grab sheet , You can start with Redis Cluster Finish in , Resynchronize to RDBMS among .
But whether it's Redis Cluster, still Cassandra, As a decentralized distributed architecture , It is inseparable from maintaining the state consistency of cluster nodes , Using a virus like Gossip agreement , To a certain extent , It will bring greater state propagation pressure to the cluster network , Another consensus based agreement , If the cluster network node fails in step , The troubleshooting and judgment of operation and maintenance personnel will also cause a lot of inconvenience .
As a cloud technology manufacturer, its ability to maintain decentralized cluster state is far greater than that of ordinary enterprise teams or individuals , So for decentralized cluster architecture , I suggest two application scenarios :
1) For small projects of ordinary small teams , Carry out small-scale cluster applications , Consider deploying Cassandra colony , Maintenance is very convenient , It can also quickly support some massive data query businesses , for example : Many government and scientific research projects .
2) For the gauge modulus with certain data , Large and medium-sized Internet projects with large concurrent visits , You can consider going directly to the cloud , Use cloud vendors Cassandra service , Because there are many nodes in the cluster , The failure rate will increase synchronously , But independent operation and maintenance is not an easy thing .
No matter what you choose , As a database under the distributed decentralized architecture , For our large-scale development of Internet application business , It provides a good choice .
This article is original. , Reprint an article , Be sure to contact the author !
边栏推荐
- Regular e-commerce problems part1
- buuctf misc USB
- What are the positions of communication equipment manufacturers?
- Flutter riverpod is comprehensively and deeply analyzed. Why is it officially recommended?
- Leetcode sword finger offer brush questions - day 20
- Solve could not find or load the QT platform plugin "xcb" in "
- After 95, Alibaba P7 published the payroll: it's really fragrant to make up this
- nacos
- [Stanford Jiwang cs144 project] lab4: tcpconnection
- 自定义类加载器加载网络Class
猜你喜欢
![[Linux] process control and parent-child processes](/img/4c/89f87ee97f0f8e9033b9f0ef46a80d.png)
[Linux] process control and parent-child processes

UWB learning 1
毕设-基于SSM大学生兼职平台系统

nacos
Leetcode-226. Invert Binary Tree
4、 High performance go language release optimization and landing practice youth training camp notes
【斯坦福计网CS144项目】Lab4: TCPConnection
After 95, the CV engineer posted the payroll and made up this. It's really fragrant
Idea add class annotation template and method template

L'externalisation a duré trois ans.
随机推荐
Mutual conversion between InputStream, int, shot, long and byte arrays
Technology cloud report: from robot to Cobot, human-computer integration is creating an era
resource 创建包方式
Build personal website based on flask
4、 High performance go language release optimization and landing practice youth training camp notes
Write CPU yourself -- Chapter 9 -- learning notes
【Unity】物体做圆周运动的几个思路
IO stream file
科技云报道:从Robot到Cobot,人机共融正在开创一个时代
nacos
Wx is used in wechat applet Showtoast() for interface interaction
Weibo publishing cases
Six methods of flattening arrays with JS
Jenkins远程构建项目超时的问题
What are the positions of communication equipment manufacturers?
Codeforces Global Round 19
Bi she - college student part-time platform system based on SSM
[guess-ctf2019] fake compressed packets
[2022 actf] Web Topic recurrence
Route jump in wechat applet