当前位置:网站首页>Redis master-slave mode
Redis master-slave mode
2022-07-05 11:44:00 【We've been on the road】
One 、Redis Necessity of medium and high availability design
Redis As a high performance Nosq middleware , There will be a lot of hot data stored in Redis in , once Redis-server Something goes wrong , It will cause problems in all related business access . in addition , Even if the database is designed to reveal the bottom of the scheme , A large number of requests for access to the database can easily lead to a bottleneck in the database , Cause greater disaster .
besides ,Redis Cluster deployment can also bring additional benefits :
- load ( performance ),Redis Of itself QPS It's already high , But if the concurrency is very high , Performance will still be affected . At this time we hope to have more Redis Service to get the job done
- Capacity expansion ( Horizontal expansion ), The second is for storage . because Redis All data is in memory , If you have a lot of data , It's easy to be limited by hardware . The cost to benefit ratio of upgrading hardware is too low , So we need to have a way to scale out
Two 、 The benefits of master-slave replication
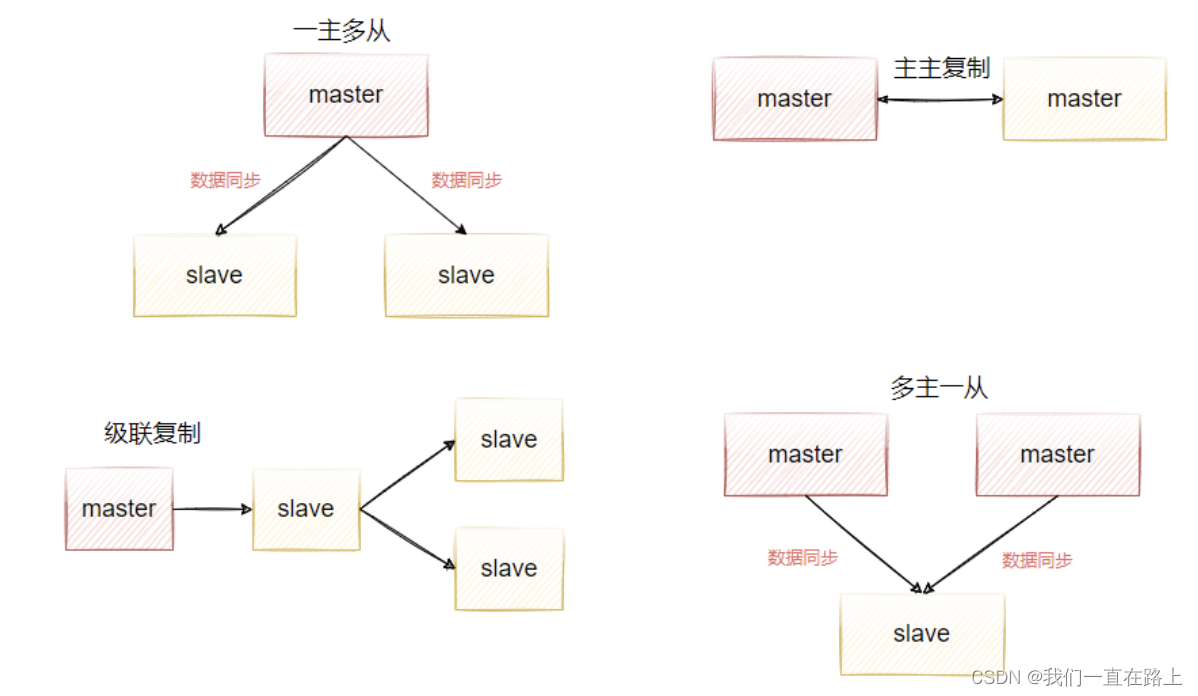
- data redundancy , The master-slave replication realizes the hot standby of data , It is another way of data redundancy besides persistence mechanism .
- Read / write separation , Enable databases to support greater concurrency . It's especially important in reports . Because part of the report sql The sentences are very slow , Cause the watch to lock , Affect front desk service . If the front desk uses master, Report use slave, Then report sql Will not cause front desk lock , Guaranteed the front desk speed .
- Load balancing , On the basis of master-slave replication , With the read-write separation mechanism , Write service can be provided by the master node , Provide services from nodes . In the context of reading more and writing less , You can add slave nodes to share redis-server Load capacity of read operations , So as to greatly improve redis-server The concurrency value
- Guaranteed high availability , As a backup database , If the primary node fails , You can switch to continue working from the node , Guarantee redisserver High availability .
3、 ... and 、redis How to build master-slave
We need to pay attention to ,Redis Master-slave replication of , It is directly initiated from the node , The master node does not need to do anything
1. stay Redis There are three ways to start master-slave replication
- From the server's redis.conf Add the following configuration to the configuration file
replicaof <masterip> <masterport>
- Configure... By starting the command , That is to start slave Execute the following command when the node
./redis-server ../redis.conf --replicaof <masterip> <masterport>
- start-up redis-server after , Directly execute the following command in the client window
redis>replicaof <masterip> <masterport>
After successful startup , Use the following command to view the cluster status
redis> info replication
You can see... In the startup log , During the start-up process, it has been from master Node copied information .
66267:S 12 Jul 2021 22:21:46.013 * Loading RDB produced by version 6.0.9
66267:S 12 Jul 2021 22:21:46.013 * RDB age 50 seconds
66267:S 12 Jul 2021 22:21:46.013 * RDB memory usage when created 0.77 Mb
66267:S 12 Jul 2021 22:21:46.013 * DB loaded from disk: 0.000 seconds
66267:S 12 Jul 2021 22:21:46.013 * Ready to accept connections
66267:S 12 Jul 2021 22:21:46.013 * Connecting to MASTER 192.168.221.128:6379
66267:S 12 Jul 2021 22:21:46.014 * MASTER <-> REPLICA sync started
66267:S 12 Jul 2021 22:21:46.015 * Non blocking connect for SYNC fired the
event.
66267:S 12 Jul 2021 22:21:46.016 * Master replied to PING, replication can
continue...
66267:S 12 Jul 2021 22:21:46.017 * Partial resynchronization not possible
(no cached master)
66267:S 12 Jul 2021 22:21:46.039 * Full resync from master:
acb74093b4c9d6fb527d3c713a44820ff0564508:0
66267:S 12 Jul 2021 22:21:46.058 * MASTER <-> REPLICA sync: receiving 188
bytes from master to disk
66267:S 12 Jul 2021 22:21:46.058 * MASTER <-> REPLICA sync: Flushing old
data
66267:S 12 Jul 2021 22:21:46.058 * MASTER <-> REPLICA sync: Loading DB in
memory
66267:S 12 Jul 2021 22:21:46.060 * Loading RDB produced by version 6.2.4
66267:S 12 Jul 2021 22:21:46.060 * RDB age 0 seconds
66267:S 12 Jul 2021 22:21:46.060 * RDB memory usage when created 1.83 Mb
66267:S 12 Jul 2021 22:21:46.060 * MASTER <-> REPLICA sync: Finished with
success
If you don't open the log , It can be opened by the following methods
- find Redis Configuration file for redis.conf
- Open the profile , vi redis.conf;
- adopt linux The query command found (loglevel below )logfile " " ; Enter the log path in the colon , such as logfile “/usr/local/redis/log/redis.log”, You need to create directories and files in advance ,redis This file will not be created by default .
By default ,slave The server is read-only , If you are directly in slave Make changes on the server , Will report a mistake . But it can be in slave Server's redis.conf Found a property in , allow slave The server can write , But it's not recommended . because slave Changes on the server cannot be made to master Up sync , It will cause the problem of data synchronization
slave-read-only no
3、 ... and 、Redis Principle analysis of master-slave replication
Redis There are two types of master-slave replication , One is full replication , The other is incremental replication .
1. Copy in full
As shown in the figure , Express Redis Overall sequence diagram of master-slave full replication , Full scale replication generally occurs in Slave Node initialization phase , This time we need to put master Make a copy of all the data on , The specific steps are :
- Connect from the slave server to the master server , send out SYNC command ;
- Received by the primary server SYNC Named after the , Start execution BGSAVE Command to generate RDB File and use the buffer to record all write commands executed since ;
- master server BGSAVE After the execution , Send snapshot files to all the slave servers , And continue to record the write commands executed during the send ( Express RDB Data changes during asynchronous snapshot generation );
- Discard all old data after receiving the snapshot file from the server , Load the received snapshot ;
- After the primary server snapshot is sent, write commands are sent to the buffer from the slave server ;
- The snapshot is loaded from the server , Start receiving command requests , And execute the write command from the host server buffer ;
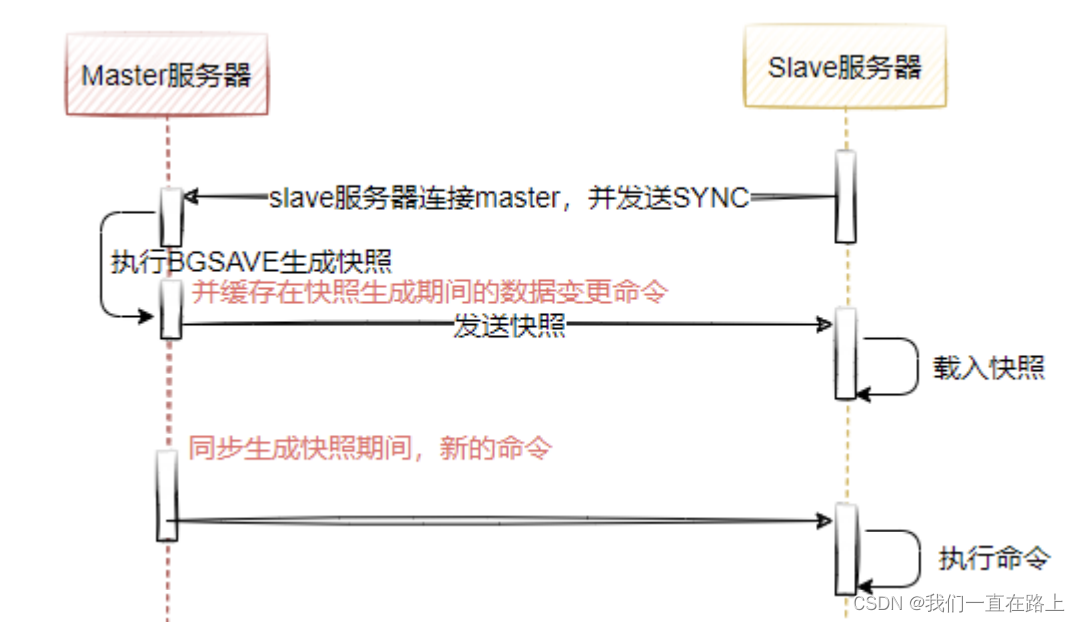
problem : Generate RDB period ,master What to do with the received command ?
To start generating RDB When you file ,master All the new Write commands are cached in memory in . stay slave node Save the RDB after , Copy the new write command to slave node.( Follow AOF The idea during rewriting is the same )
After completing the above steps slave All operations of server data initialization ,savle The server can now receive a read request from the user , meanwhile , The master-slave node enters the command propagation stage , At this stage, the master node sends the write command executed by itself to the slave node , Receive command from node and execute , So as to ensure the consistency of master-slave node data . In the command propagation phase , In addition to sending write commands , The master-slave node also maintains the heartbeat mechanism :PING and REPLCONF ACK, Let's demonstrate the specific implementation .
- stay slave The server redis cli On the implementation REPLCONF listening-port 6379 ( Send... To the master database replconf The command specifies its own port number )
- Start syncing , towards master Server send sync Command to start synchronization , here master The command of snapshot file and cache will be sent .
127.0.0.1:6379> sync
Entering replica output mode... (press Ctrl-C to quit)
SYNC with master, discarding 202 bytes of bulk transfer...
SYNC done. Logging commands from master.
"ping"
"ping"
- slave The received content will be written to a temporary file on the hard disk , When writing is completed, the temporary file will be used to replace the original RDB Snapshot file . It should be noted that , In the process of synchronization slave It doesn't block , You can still handle client commands . By default slave It will respond to the command with the data before synchronization , If we want to read data without dirty data , So it can be redis.conf Configure the following parameters in the file , To make slave Before synchronizing all commands , All replied incorrectly :SYNC with master in progress
slave-serve-stale-data no
- At the end of the replication phase ,master Any non query statements executed are sent asynchronously to slave. Can be in master Node execution set command , Can be in slave The node sees the following synchronization instructions .
redis > sync
"set","11","11"
"ping"
Another thing to note :
master/slave The replication strategy is to adopt optimistic replication , In other words, it can be tolerated for a certain period of time master/slave The content of the data is different , But the data of the two will eventually be synchronized successfully . say concretely ,redis The master-slave synchronization process itself is asynchronous , signify master After executing the command requested by the client, the result will be returned to the client immediately , Then asynchronously synchronize the command to slave. This feature ensures that master/slave after master The performance of will not be affected . But on the other hand , If during this data inconsistent window ,master/slave Disconnected due to network problems , And this time ,master It is impossible to know how many commands are finally synchronized slave database . however redis A configuration item is provided to limit the number of only data synchronized to at least slave When ,master Is writable : modify master redis Service redis.conf, Open these two configurations , Restart to see the effect
min-replicas-to-write 3 Only when 3 One or more slave Connect to master,master Is writable
min-replicas-max-lag 10 It means to allow slave Maximum time to lose connection , If 10 Seconds yet slave The sound of
Should be , be master Think that slave To disconnect
2. Incremental replication
from Redis2.8 Start , The master-slave node supports incremental replication , And it is an incremental copy that supports breakpoint continuation , In other words, if there is a replication exception or the network connection is disconnected, the replication is interrupted , After the system is restored, you can still continue to synchronize according to the last replication , Instead of full replication .
Its specific principle is : The master and slave maintain a copy offset, respectively (offset), Represents the number of bytes passed from the master node to the slave node ; Every time the master node propagates to the slave node N Bytes of data , The master node offset increase N; Each time the slave node receives a message from the master node N Bytes of data , From node's offset increase N. The offset of master and slave nodes can be saved in :master_repl_offset:78130 and slave_repl_offset In these two fields , You can view it with the following command .
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.221.128
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:77864
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:acb74093b4c9d6fb527d3c713a44820ff0564508
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:77864
second_repl_offset:-1
repl_backlog_active:1 # Turn on the copy buffer
repl_backlog_size:1048576 # Maximum buffer length
repl_backlog_first_byte_offset:771 # Starting offset , Calculate the available range of the current cache
repl_backlog_histlen:77094 # To save the effective length of the data
3. Diskless replication
We said earlier ,Redis How replication works is based on RDB The persistence of the method is realized , That is to say master Save in the background RDB snapshot ,slave Received rdb File and load , But there are some problems with this approach .
- When master Ban RDB when , If replication initialization is performed ,Redis It will still generate RDB snapshot , When master Execute this command the next time you start RDB Recovery of files , But because the time of replication is uncertain , So the recovered data may be at any point in time . Will cause data problems
- When the performance of the hard disk is slow ( Network hard disk ), Then the initialization replication process will have an impact on performance
therefore 2.8.18 Later versions ,Redis Introduced no hard disk copy option , You don't have to go through RDB File desynchronization , Send data directly , Enable this function through the following configuration :
repl-diskless-sync yes
master Create... Directly in memory rdb, And send it to slave, I won't land the disk in my own place
4. Precautions for master-slave replication
Master-slave mode solves data backup and performance ( Separate by reading and writing ) The problem of , But there are still some shortcomings :
- The first time you create a copy, it must be a full copy , Therefore, if the primary node has a large amount of data , Then the replication latency is longer , At this time, we should try to avoid the peak flow , Avoid blocking ; If there are multiple slave nodes that need to establish replication of the master node , Consider staggering several slave nodes , Avoid using too much bandwidth of the primary node . Besides , If there are too many slave nodes , You can also adjust the topology of master-slave replication , From one master to many, from the structure to the tree structure .
- In the case of one master and one slave or one master and many slaves , If the primary server hangs up , External services are not available , A single problem has not been solved . If you manually switch the previous slave server to the master server every time , This is more time-consuming and laborious , It will also make the service unavailable for a certain period of time .
边栏推荐
- Dynamic SQL of ibatis
- 13.(地图数据篇)百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换
- [singleshotmultiboxdetector (SSD, single step multi frame target detection)]
- Programmers are involved and maintain industry competitiveness
- iTOP-3568开发板NPU使用安装RKNN Toolkit Lite2
- go语言学习笔记-初识Go语言
- 石油化工企业安全生产智能化管控系统平台建设思考和建议
- 谜语1
- Project summary notes series wstax kt session2 code analysis
- 【使用TensorRT通过ONNX部署Pytorch项目】
猜你喜欢
idea设置打开文件窗口个数
COMSOL -- 3D casual painting -- sweeping

The most comprehensive new database in the whole network, multidimensional table platform inventory note, flowus, airtable, seatable, Vig table Vika, flying Book Multidimensional table, heipayun, Zhix
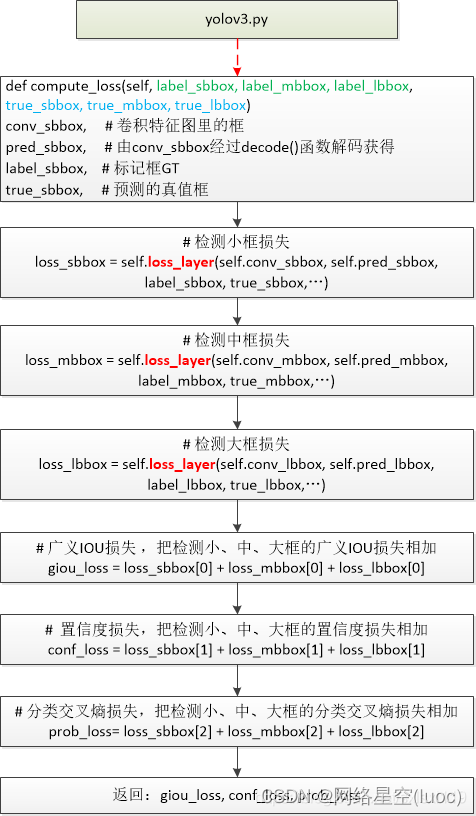
【yolov3损失函数】
Idea set the number of open file windows
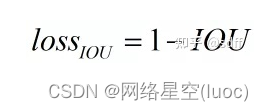
yolov5目標檢測神經網絡——損失函數計算原理
全网最全的新型数据库、多维表格平台盘点 Notion、FlowUs、Airtable、SeaTable、维格表 Vika、飞书多维表格、黑帕云、织信 Informat、语雀
yolov5目标检测神经网络——损失函数计算原理
![[mainstream nivida graphics card deep learning / reinforcement learning /ai computing power summary]](/img/1a/dd7453bc5afc6458334ea08aed7998.png)
[mainstream nivida graphics card deep learning / reinforcement learning /ai computing power summary]

Pytorch training process was interrupted
随机推荐
yolov5目標檢測神經網絡——損失函數計算原理
程序员内卷和保持行业竞争力
龙蜥社区第九次运营委员会会议顺利召开
Redis集群的重定向
阻止瀏覽器後退操作
Yolov 5 Target Detection Neural Network - Loss Function Calculation Principle
POJ 3176 cow bowling (DP | memory search)
[crawler] bugs encountered by wasm
C operation XML file
[upsampling method opencv interpolation]
紫光展锐全球首个5G R17 IoT NTN卫星物联网上星实测完成
How to make your products as expensive as possible
【L1、L2、smooth L1三类损失函数】
[leetcode] wild card matching
高校毕业求职难?“百日千万”网络招聘活动解决你的难题
Mysql统计技巧:ON DUPLICATE KEY UPDATE用法
Pytorch MLP
redis集群中hash tag 使用
Prevent browser backward operation
Project summary notes series wstax kt session2 code analysis