当前位置:网站首页>redis主从中的Master自动选举之Sentinel哨兵机制
redis主从中的Master自动选举之Sentinel哨兵机制
2022-07-05 11:31:00 【我们一直在路上】
一、什么是哨兵
顾名思义,哨兵的作用就是监控Redis系统的运行状况,它的功能包括两个
- 监控master和slave是否正常运行
- master出现故障时自动将slave数据库升级为master
哨兵是一个独立的进程,使用哨兵后的架构如图所示,同时为了保证哨兵的高可用,我们会对Sentinel做集群部署,因此Sentinel不仅仅监控Redis所有的主从节点,Sentinel也会实现相互监控。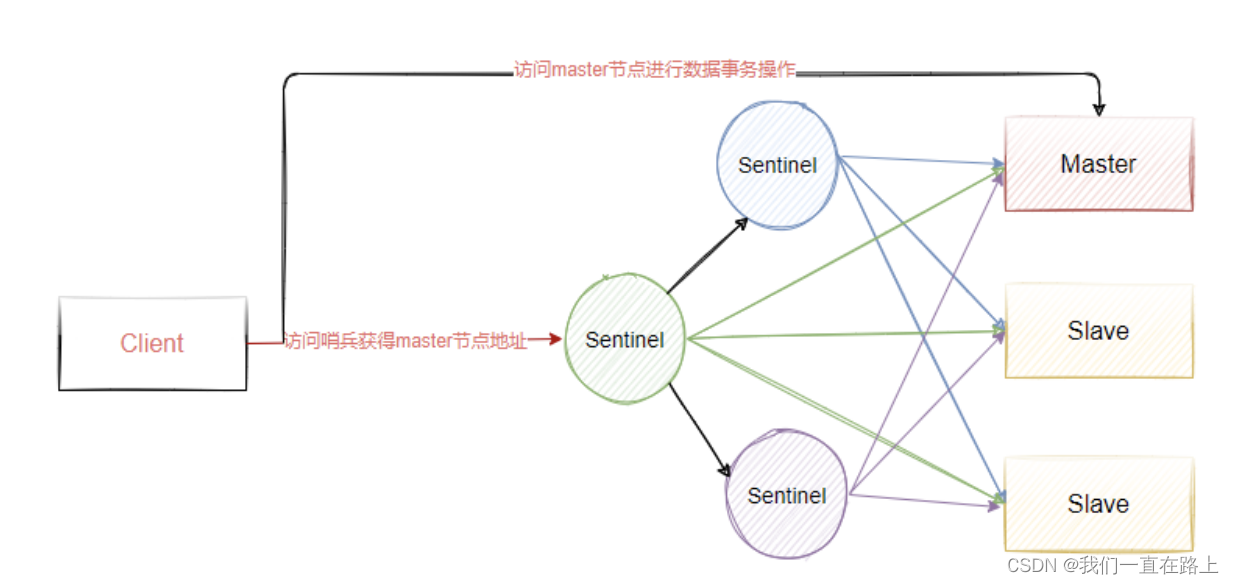
二、配置哨兵集群
在前面主从复制的基础上,增加三个sentinel节点,来实现对redis中master选举的功能。
192.168.221.128(sentinel)
192.168.221.129(sentinel)
192.168.221.130(sentinel)
sentinel哨兵的配置方式如下:
- 从redis-6.0.9源码包中拷贝sentinel.conf文件到redis/bin安装目录下
cp /data/program/redis-6.0.9/sentinel.conf /data/program/redis/sentinel.conf
- 修改以下配置
# 其中name表示要监控的master的名字,这个名字是自己定义,ip和port表示master的ip和端口
号,最后一个2表示最低通过票数,也就是说至少需要几个哨兵节点认为master下线才算是真的下线
sentinel monitor mymaster 192.168.221.128 6379 2
sentinel down-after-milliseconds mymaster 5000 # 表示如果5s内mymaster没响应,
就认为SDOWN
sentinel failover-timeout mymaster 15000 # 表示如果15秒后,mysater仍没活
过来,则启动failover,从剩下的slave中选一个升级为master
logfile "/data/program/redis/logs/sentinels.log" # 需要提前创建好文件
- 通过下面这个命令启动sentinel哨兵
./redis-sentinel ../sentinel.conf
- 启动成功后,得到一下信息,表示哨兵启动成功并且开始监控集群节点
103323:X 13 Jul 2021 15:16:28.624 # Sentinel ID is
2e9b0ac7ffbfca08e80debff744a4541a31b3951
103323:X 13 Jul 2021 15:16:28.624 # +monitor master mymaster 192.168.221.128
6379 quorum 2
103323:X 13 Jul 2021 15:16:28.627 * +slave slave 192.168.221.129:6379
192.168.221.129 6379 @ mymaster 192.168.221.128 6379
103323:X 13 Jul 2021 15:16:28.628 * +slave slave 192.168.221.130:6379
192.168.221.130 6379 @ mymaster 192.168.221.128 6379
103323:X 13 Jul 2021 15:16:48.765 * +fix-slave-config slave
192.168.221.130:6379 192.168.221.130 6379 @ mymaster 192.168.221.128 6379
103323:X 13 Jul 2021 15:16:48.765 * +fix-slave-config slave
192.168.221.129:6379 192.168.221.129 6379 @ mymaster 192.168.221.128 6379
其他两个节点的配置和上面完全相同,都去监视master节点即可,主要,sentinel.conf文件中master节点的ip一定不能输127.0.0.1,否则其他sentinel节点无法和它通信
当其他sentinel哨兵节点启动后,第一台启动的sentinel节点还会输出如下日志,表示有其他sentinel节点加入进来。
+sentinel sentinel d760d62e190354654490e75e0b427d8ae095ac5a 192.168.221.129
26379 @ mymaster 192.168.221.128 6379
103323:X 13 Jul 2021 15:24:31.421
+sentinel sentinel dc6d874fe71e4f8f25e15946940f2b8eb087b2e8 192.168.221.130
26379 @ mymaster 192.168.221.128 6379
三、模拟master节点故障
我们直接把redis主从复制集群的master节点,通过 ./redis-cli shutdown 命令停止,于是我们观察三个sentinel哨兵的日志,先来看第一台启动的sentinel日志,得到如下内容。
103625:X 13 Jul 2021 15:35:01.241 # +new-epoch 9
103625:X 13 Jul 2021 15:35:01.244 # +vote-for-leader
d760d62e190354654490e75e0b427d8ae095ac5a 9
103625:X 13 Jul 2021 15:35:01.267 # +odown master mymaster 192.168.221.128 6379
#quorum 2/2
103625:X 13 Jul 2021 15:35:01.267 # Next failover delay: I will not start a
failover before Tue Jul 13 15:35:31 2021
103625:X 13 Jul 2021 15:35:02.113 # +config-update-from sentinel
d760d62e190354654490e75e0b427d8ae095ac5a 192.168.221.129 26379 @ mymaster
192.168.221.128 6379
103625:X 13 Jul 2021 15:35:02.113 # +switch-master mymaster 192.168.221.128 6379
192.168.221.130 6379
103625:X 13 Jul 2021 15:35:02.113 * +slave slave 192.168.221.129:6379
192.168.221.129 6379 @ mymaster 192.168.221.130 6379
103625:X 13 Jul 2021 15:35:02.113 * +slave slave 192.168.221.128:6379
192.168.221.128 6379 @ mymaster 192.168.221.130 6379
103625:X 13 Jul 2021 15:35:07.153 # +sdown slave 192.168.221.128:6379
192.168.221.128 6379 @ mymaster 192.168.221.130 6379
+sdown表示哨兵主观认为master已经停止服务了。
+odown表示哨兵客观认为master停止服务了(关于主观和客观,后面会给大家讲解)。接着哨兵开始进行故障恢复,挑选一个slave升级为master,其他哨兵节点的日志。
76274:X 13 Jul 2021 15:35:01.240 # +try-failover master mymaster 192.168.221.128
6379
76274:X 13 Jul 2021 15:35:01.242 # +vote-for-leader
d760d62e190354654490e75e0b427d8ae095ac5a 9
76274:X 13 Jul 2021 15:35:01.242 # d760d62e190354654490e75e0b427d8ae095ac5a
voted for d760d62e190354654490e75e0b427d8ae095ac5a 9
76274:X 13 Jul 2021 15:35:01.247 # dc6d874fe71e4f8f25e15946940f2b8eb087b2e8
voted for d760d62e190354654490e75e0b427d8ae095ac5a 9
76274:X 13 Jul 2021 15:35:01.247 # 2e9b0ac7ffbfca08e80debff744a4541a31b3951
voted for d760d62e190354654490e75e0b427d8ae095ac5a 9
76274:X 13 Jul 2021 15:35:01.309 # +elected-leader master mymaster
192.168.221.128 6379
76274:X 13 Jul 2021 15:35:01.309 # +failover-state-select-slave master mymaster
192.168.221.128 6379
76274:X 13 Jul 2021 15:35:01.400 # +selected-slave slave 192.168.221.130:6379
192.168.221.130 6379 @ mymaster 192.168.221.128 6379
76274:X 13 Jul 2021 15:35:01.400 * +failover-state-send-slaveof-noone slave
192.168.221.130:6379 192.168.221.130 6379 @ mymaster 192.168.221.128 6379
76274:X 13 Jul 2021 15:35:01.477 * +failover-state-wait-promotion slave
192.168.221.130:6379 192.168.221.130 6379 @ mymaster 192.168.221.128 6379
76274:X 13 Jul 2021 15:35:02.045 # +promoted-slave slave 192.168.221.130:6379
192.168.221.130 6379 @ mymaster 192.168.221.128 6379
76274:X 13 Jul 2021 15:35:02.045 # +failover-state-reconf-slaves master mymaster
192.168.221.128 6379
76274:X 13 Jul 2021 15:35:02.115 * +slave-reconf-sent slave 192.168.221.129:6379
192.168.221.129 6379 @ mymaster 192.168.221.128 6379
76274:X 13 Jul 2021 15:35:03.070 * +slave-reconf-inprog slave
192.168.221.129:6379 192.168.221.129 6379 @ mymaster 192.168.221.128 6379
76274:X 13 Jul 2021 15:35:03.070 * +slave-reconf-done slave 192.168.221.129:6379
192.168.221.129 6379 @ mymaster 192.168.221.128 6379
76274:X 13 Jul 2021 15:35:03.133 # +failover-end master mymaster 192.168.221.128
6379
76274:X 13 Jul 2021 15:35:03.133 # +switch-master mymaster 192.168.221.128 6379
192.168.221.130 6379
76274:X 13 Jul 2021 15:35:03.133 * +slave slave 192.168.221.129:6379
192.168.221.129 6379 @ mymaster 192.168.221.130 6379
76274:X 13 Jul 2021 15:35:03.133 * +slave slave 192.168.221.128:6379
192.168.221.128 6379 @ mymaster 192.168.221.130 6379
76274:X 13 Jul 2021 15:35:08.165 # +sdown slave 192.168.221.128:6379
192.168.221.128 6379 @ mymaster 192.168.221.130 6379
+try-failover表示哨兵开始进行故障恢复
+failover-end 表示哨兵完成故障恢复
+slave表示列出新的master和slave服务器,我们仍然可以看到已经停掉的master,哨兵并没有清除已停止的服务的实例,这是因为已经停止的服务器有可能会在某个时间进行恢复,恢复以后会以slave角色加入到整个集群中。
四、实现原理
- 每个Sentinel以每秒钟一次的频率向它所知的Master/Slave以及其他 Sentinel 实例发送一个 PING命令
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-aftermilliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
- 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
- 当有足够数量的 Sentinel(大于等于配置文件指定的值:quorum)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO命令
- 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 ,若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。
- 若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
主观下线:Subjectively Down,简称 SDOWN,指的是当前 Sentinel 实例对某个redis服务器做出的下线判断。
客观下线:Objectively Down, 简称 ODOWN,指的是多个 Sentinel 实例在对Master Server做出SDOWN 判断,并且通过 SENTINEL之间交流后得出Master下线的判断。然后开启failover
五、谁来完成故障转移
当redis中的master节点被判定为客观下线之后,需要重新从slave节点选择一个作为新的master节点,那现在有三个sentinel节点,应该由谁来完成这个故障转移过程呢?所以这三个sentinel节点必须要通过某种机制达成一致,在Redis中采用了Raft算法来实现这个功能。
每次master出现故障时,都会触发raft算法来选择一个leader完成redis主从集群中的master选举功能。
1.常见的数据一致性算法
- paxos,paxos应该是最早也是最正统的数据一致性算法,也是最复杂难懂的算法。
- raft,raft算法应该是最通俗易懂的一致性算法,它在nacos、sentinel、consul等组件中都有使用。
- zab协议,是zookeeper中基于paxos算法上演变过来的一种一致性算法
- distro,Distro协议。Distro是阿里巴巴的私有协议,目前流行的Nacos服务管理框架就采用了Distro协议。Distro 协议被定位为 临时数据的一致性协议
2.Raft协议说明
Raft算法动画演示地址: http://thesecretlivesofdata.com/raft/
Raft算法的核心思想:先到先得,少数服从多数。
3.故障转移过程
怎么让一个原来的slave节点成为主节点?
- 选出Sentinel Leader之后,由Sentinel Leader向某个节点发送slaveof no one命令,让它成为独立节点。
- 然后向其他节点发送replicaof x.x.x.x xxxx(本机服务),让它们成为这个节点的子节点,故障转移完成。
如何选择合适的slave节点成为master呢?
- 断开连接时长,如果与哨兵连接断开的比较久,超过了某个阈值,就直接失去了选举权
- 优先级排序,如果拥有选举权,那就看谁的优先级高,这个在配置文件里可以设置(replicapriority 100),数值越小优先级越高
- 复制数量,如果优先级相同,就看谁从master中复制的数据最多(复制偏移量最大)
- 进程id,如果复制数量也相同,就选择进程id最小的那个
六、Sentinel功能总结
监控:Sentinel会不断检查主服务器和从服务器是否正常运行。
通知:如果某一个被监控的实例出现问题,Sentinel可以通过API发出通知。
自动故障转移(failover):如果主服务器发生故障,Sentinel可以启动故障转移过程。把某台服务器升级为主服务器,并发出通知。
配置管理:客户端连接到Sentinel,获取当前的Redis主服务器的地址。
边栏推荐
- 居家办公那些事|社区征文
- 11. (map data section) how to download and use OSM data
- PHP中Array的hash函数实现
- Detailed explanation of DDR4 hardware schematic design
- IPv6与IPv4的区别 网信办等三部推进IPv6规模部署
- Web API configuration custom route
- [there may be no default font]warning: imagettfbbox() [function.imagettfbbox]: invalid font filename
- sklearn模型整理
- Question and answer 45: application of performance probe monitoring principle node JS probe
- MySQL 巨坑:update 更新慎用影响行数做判断!!!
猜你喜欢



随机推荐
Error assembling WAR: webxml attribute is required (or pre-existing WEB-INF/web.xml if executing in
Pytorch training process was interrupted
FreeRTOS 中 RISC-V-Qemu-virt_GCC 的调度时机
7 themes and 9 technology masters! Dragon Dragon lecture hall hard core live broadcast preview in July, see you tomorrow
Advanced technology management - what is the physical, mental and mental strength of managers
7 大主题、9 位技术大咖!龙蜥大讲堂7月硬核直播预告抢先看,明天见
R3live series learning (IV) r2live source code reading (2)
How to protect user privacy without password authentication?
C # implements WinForm DataGridView control to support overlay data binding
Ffmpeg calls avformat_ open_ Error -22 returned during input (invalid argument)
【无标题】
MFC pet store information management system
7.2 daily study 4
如何让你的产品越贵越好卖
Web API配置自定义路由
CDGA|数据治理不得不坚持的六个原则
Unity xlua monoproxy mono proxy class
Idea set the number of open file windows
13.(地图数据篇)百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换
C#实现WinForm DataGridView控件支持叠加数据绑定