当前位置:网站首页>基于购买行为数据对超市顾客进行市场细分(RFM模型)
基于购买行为数据对超市顾客进行市场细分(RFM模型)
2022-07-06 06:29:00 【啥也不会(sybh)】
目录
题目:
基于购买行为数据对超市顾客进行市场细分:现有超市顾客购买行为的RFM数据集(数据文件:RFM数据.txt),请利用各种聚类算法实现顾客群细分。完成下列问题:
1)分析顾客购买行为的RFM数据集中,R\F\M这三个变量有怎样的分布特征?(10分)
2)尝试将购买分成4类,并分析各顾客的购买行为特征。(10分)
3)评价模型,并分析聚成4类是否恰当。(30分)
一、什么叫RFM?
RFM是一种对用户质量进行聚类的模型,对应于三个指标
R(Recency):用户最近一次消费的时间间隔,衡量用户是否存在流失可能性
F(Frequency)
:用户最近一段时间内累计消费频次,衡量用户的粘性
M(Money): 用户最近一段时间内累计消费金额,衡量用户的消费能力和忠诚度
二、聚类
# 项目一:电商用户质量RFM聚类分析
from sklearn.cluster import KMeans
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn import preprocessing
# 导入并清洗数据
data = pd.read_table('RFM数据.txt',sep=" ")
# data=pd.read_table("RFM数据.txt",encoding="gbk",sep=" ")
# data.user_id = data.user_id.astype('str')
print(data.info())
print(data.describe())
X = data.values[:,1:]
# 数据标准化(z_score)
Model = preprocessing.StandardScaler()
X = Model.fit_transform(X)
# 迭代,选择合适的K
ch_score = []
ss_score = []
inertia = []
for k in range(2,10):
clf = KMeans(n_clusters=k,max_iter=1000)
pred = clf.fit_predict(X)
ch = metrics.calinski_harabasz_score(X,pred)
ss = metrics.silhouette_score(X,pred)
ch_score.append(ch)
ss_score.append(ss)
inertia.append(clf.inertia_)
# 做图对比
fig = plt.figure()
ax1 = fig.add_subplot(131)
plt.plot(list(range(2,10)),ch_score,label='ch',c='y')
plt.title('CH(calinski_harabaz_score)')
plt.legend()
ax2 = fig.add_subplot(132)
plt.plot(list(range(2,10)),ss_score,label='ss',c='b')
plt.title('轮廓系数')
plt.legend()
ax3 = fig.add_subplot(133)
plt.plot(list(range(2,10)),inertia,label='inertia',c='g')
plt.title('inertia')
plt.legend()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.serif'] = ['SimHei'] # 设置正常显示中文
plt.show()
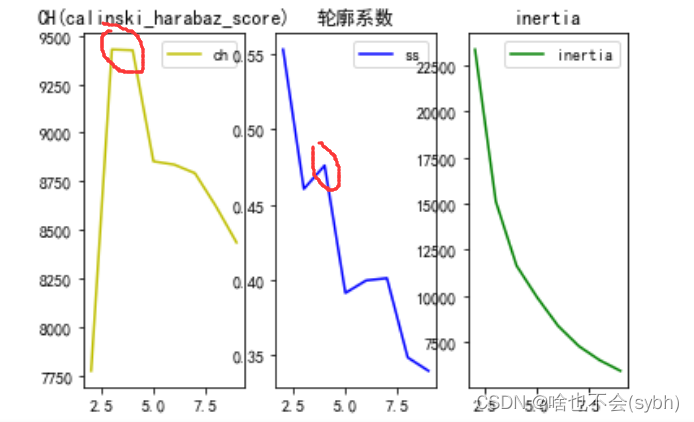
本次采用3个指标综合判定聚类质量,CH,轮廓系数和inertia分数,第1和第3均是越大越好,轮廓系数是越接近于1越好,综合来看,聚为4类效果比较好
CH指标越大,聚类效果越好
clf.inertia_是一种聚类评估指标,我常见有人用这个。说一下他的缺点:这个评价参数表示的是簇中某一点到簇中距离的和,这种方法虽然在评估参数最小时表现了聚类的精细性,但是这种情况会出现划分过于精细的状况,并且未考虑和簇外点的距离最大化,因此,我推荐使用方法二:
使用轮廓系数法进行K值的选择,在此,我需要解释一下轮廓系数,以及为何选用轮廓系数作为内部评价的标准,轮廓系数的公式为:S=(b-a)/max(a,b),其中a是单个样本离同类簇所有样本的距离的平均数,b是单个样本到不同簇所有样本的平均。
# 根据最佳的K值,聚类得到结果
model = KMeans(n_clusters=4,max_iter=1000)
model.fit_predict(X)
labels = pd.Series(model.labels_)
centers = pd.DataFrame(model.cluster_centers_)
result1 = pd.concat([centers,labels.value_counts().sort_index(ascending=True)],axis=1) # 将聚类中心和聚类个数拼接在一起
result1.columns = list(data.columns[1:]) + ['counts']
print(result1)
result = pd.concat([data,labels],axis=1) # 将原始数据和聚类结果拼接在一起
result.columns = list(data.columns)+['label'] # 修改列名
pd.options.display.max_columns = None # 设定展示所有的列
print(result.groupby(['label']).agg('mean')) # 分组计算各指标的均值
# 对聚类结果做图
fig = plt.figure()
ax1= fig.add_subplot(131)
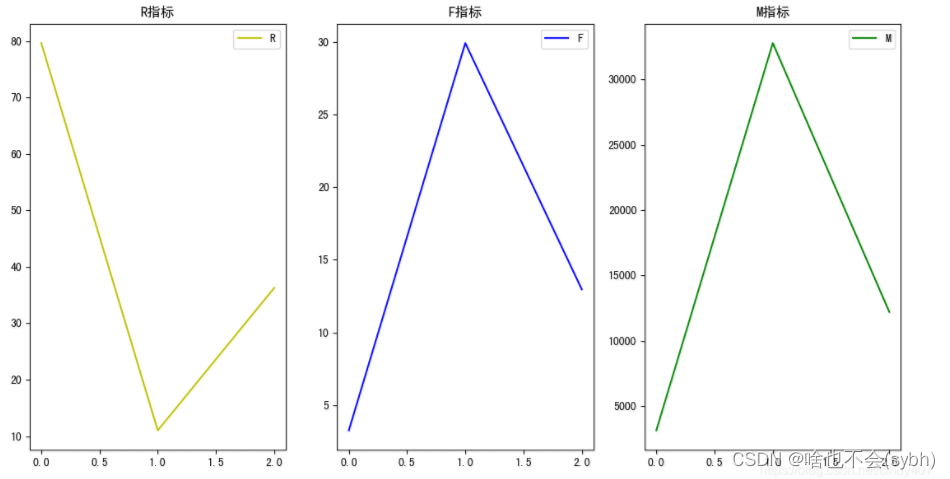
ax1.plot(list(range(1,5)),result1.R,c='y',label='R')
plt.title('R指标')
plt.legend()
ax2= fig.add_subplot(132)
ax2.plot(list(range(1,5)),result1.F,c='b',label='F')
plt.title('F指标')
plt.legend()
ax3= fig.add_subplot(133)
ax3.plot(list(range(1,5)),result1.M,c='g',label='M')
plt.title('M指标')
plt.legend()
plt.show()三、结果分析

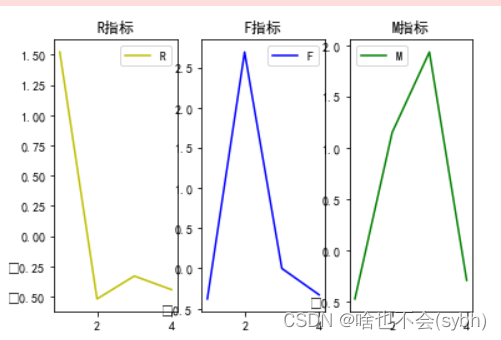
1.流失顾客:消费周期长、消费次数少、消费能力几乎为零
2.活跃顾客:消费周期短、消费次数多、消费能力强
3.VIP顾客:消费周期一般、消费次数一般、消费能力非常强
4.闲逛顾客:消费周期一般、消费次数少、消费能力一般
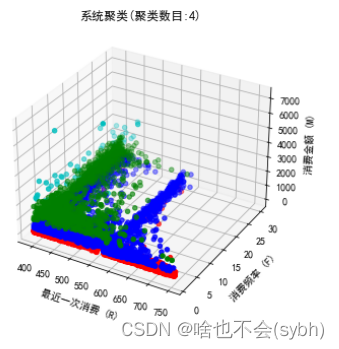
1.流失顾客:消费周期长、消费次数少、消费能力几乎为零
2.vip顾客:消费周期短、消费次数多、消费能力非常强
3.普通顾客:消费周期一般、消费次数一般、消费能力一般
边栏推荐
- Py06 字典 映射 字典嵌套 键不存在测试 键排序
- In English translation of papers, how to do a good translation?
- How effective is the Chinese-English translation of international economic and trade contracts
- LeetCode每日一题(1997. First Day Where You Have Been in All the Rooms)
- Suspended else
- Thesis abstract translation, multilingual pure human translation
- Private cloud disk deployment
- Apple has open source, but what about it?
- 模拟卷Leetcode【普通】1296. 划分数组为连续数字的集合
- Delete the variables added to watch1 in keil MDK
猜你喜欢
Redis core technology and basic architecture of actual combat: what does a key value database contain?

论文摘要翻译,多语言纯人工翻译

基于JEECG-BOOT制作“左树右表”交互页面

How to convert flv file to MP4 file? A simple solution
Making interactive page of "left tree and right table" based on jeecg-boot
CS通过(CDN+证书)powershell上线详细版
SQL Server manager studio(SSMS)安装教程
Technology sharing | common interface protocol analysis
Selenium source code read through · 9 | desiredcapabilities class analysis

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
随机推荐
Is the test cycle compressed? Teach you 9 ways to deal with it
How much is the price for the seal of the certificate
CS通过(CDN+证书)powershell上线详细版
Chinese English comparison: you can do this Best of luck
leetcode 24. Exchange the nodes in the linked list in pairs
论文摘要翻译,多语言纯人工翻译
Grouping convolution and DW convolution, residuals and inverted residuals, bottleneck and linearbottleneck
JDBC requset corresponding content and function introduction
模拟卷Leetcode【普通】1314. 矩阵区域和
mysql的基础命令
Phishing & filename inversion & Office remote template
Lecture 8: 1602 LCD (Guo Tianxiang)
How to do a good job in financial literature translation?
Simulation volume leetcode [general] 1219 Golden Miner
Mise en œuvre d’une fonction complexe d’ajout, de suppression et de modification basée sur jeecg - boot
Postman core function analysis - parameterization and test report
[Tera term] black cat takes you to learn TTL script -- serial port automation skill in embedded development
Simulation volume leetcode [general] 1414 The minimum number of Fibonacci numbers with a sum of K
女生学软件测试难不难 入门门槛低,学起来还是比较简单的
The internationalization of domestic games is inseparable from professional translation companies