当前位置:网站首页>应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设
应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设
2022-07-07 21:39:00 【InfoQ】
业务背景
业务介绍
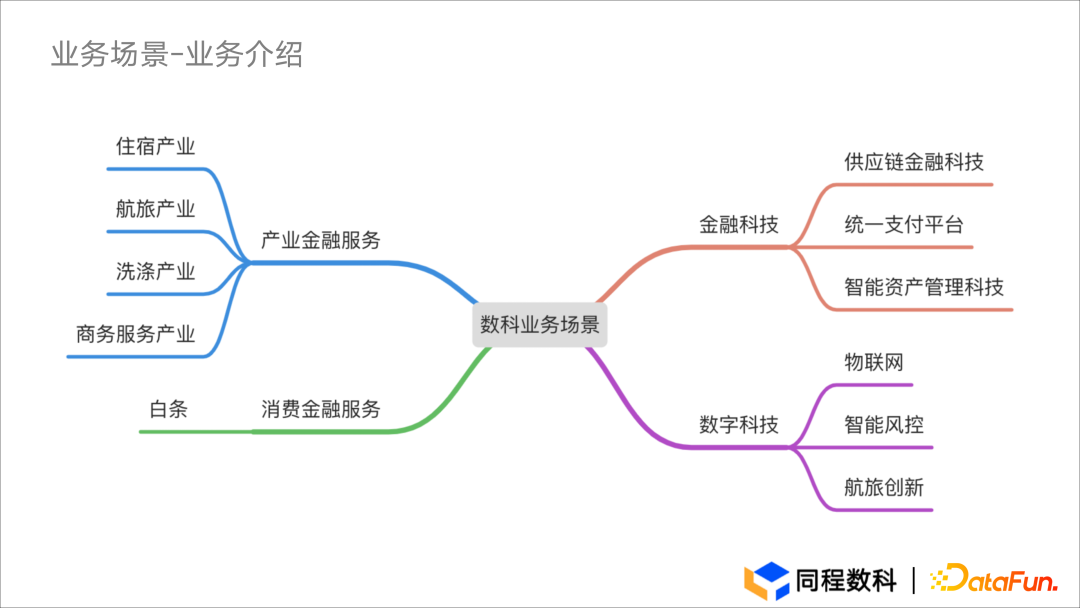
业务需求
- 看板类:主要包括业务实时驾驶舱以及 T+1 业务看板等。
- 预警类:主要包括风控熔断、资金异常以及流量监控等。
- 分析类:主要包括及时性数据查询分析以及临时取数等。
- 财务类:主要包括清算以及支付对账需求。

架构演进之 1.0
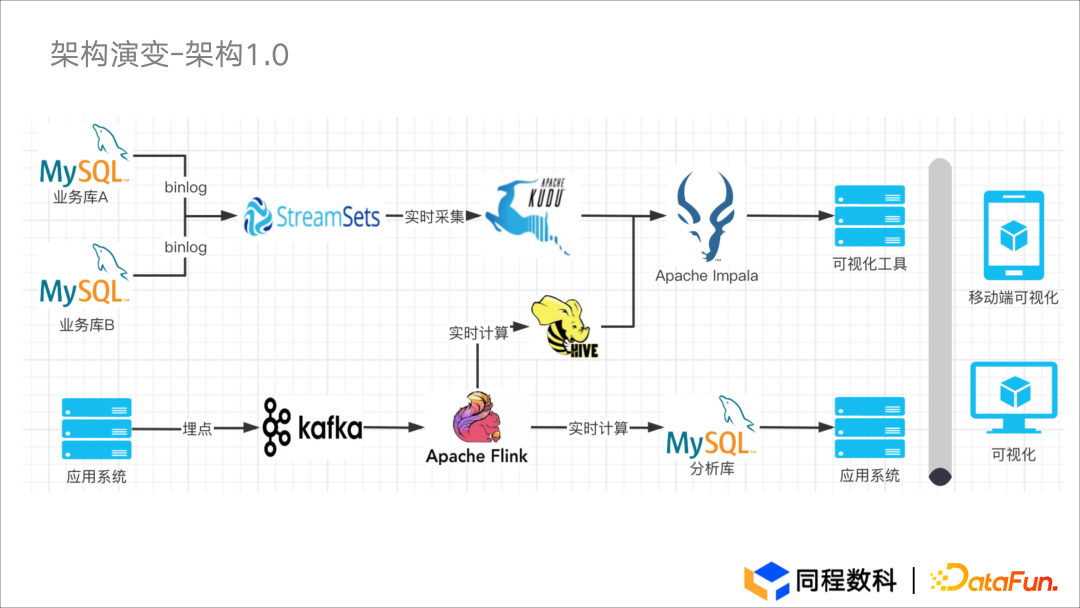
工作流程
优势与不足

优势:
- 架构1.0 选择了 CDH 全家桶。CDH 提供了众多大数据组件,可以相互集成并投入使用,同时其配置相对灵活。
- 使用的 SteamSets 支持可视化拖拉式与配置式的开发方式,因此开发人员对 SteamSets 的接受程度较高。。
不足:
- 组件引入过多,维护成本随之增加;当数据出现问题时,排查与修复链路相对较长。
- 多种技术架构和过长的开发链路,提高了数仓人员的学习成本与要求,数仓人员需要在不同地方转换后再进行开发,导致开发流程不顺畅、开发效率降低。
- Apache Kudu 在大表关联 Join 方面性能差强人意。
- 由于架构使用 CDH 构建,离线集群和实时集群未进行分离,形成资源相互竞争;离线跑批的过程中对 IO 或磁盘消耗较大,无法保证实时数据的及时性。
- 虽然 SteamSets 配备了预警能力,但作业恢复能力仍相对欠缺。配置多个任务时对 JVM 的消耗较大,导致恢复速度较慢。
架构演进之 2.0
工作流程
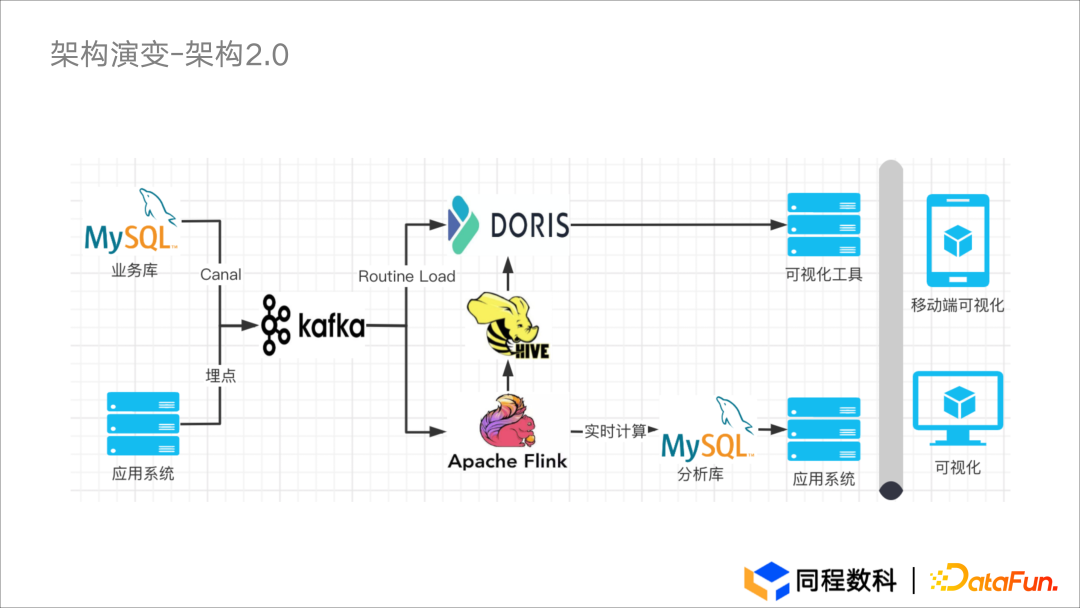
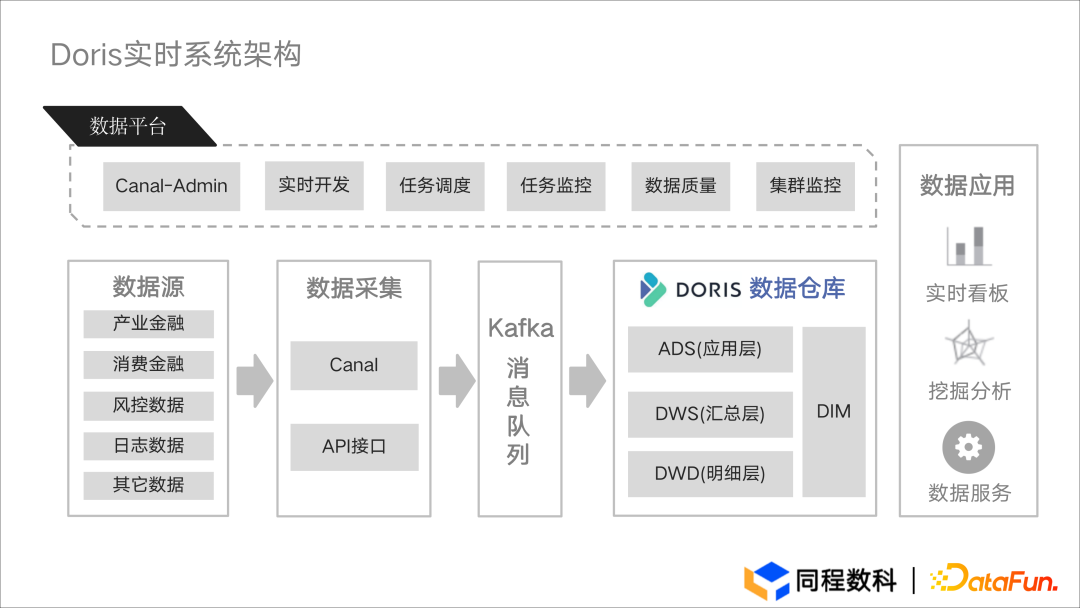
- 通过 Canal 的 CDC 能力,将 MySQL 数据采集到 Kafka 中。因 Apache Doris 与 Kafka 的契合度较高,可以便捷地使用 Routine Load 进行数据加载与接入。
- 对原有离线计算的数据链路进行了细微调整。对于存储在 Hive 中的数据,Apahce Doris 支持通过 Broker Load 将 Hive 数据引入进来,因此离线集群的数据可以直接加载进 Doris 之中。
选型 Doris
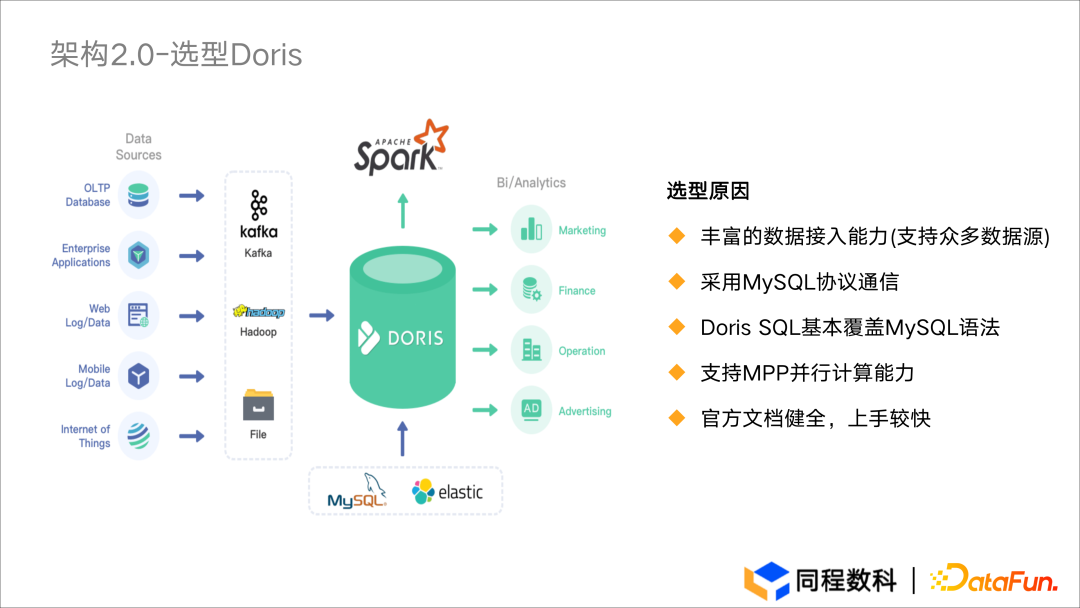
- 数据接入:提供了丰富的数据导入方式,能够支持众多数据源的接入。
- 数据连接:Doris 支持 JDBC 与 ODBC 等连接方式,对 BI 工具的可视化展示比较友好,能够便捷地与 BI 工具进行连接,另外 Doris 实现了 MySQL 协议层,可以通过各类 Client 工具直接访问 Doris。
- SQL 语法:Doris 支持标准 SQL,语法向 MySQL 兼容,对于数仓人员学习成本较低;
- MPP 并行计算:Doris 基于 MPP 架构提供了非常优秀的并行计算能力,对于大表 Join 支持得非常好。
- 最重要的一点:Doris 官方文档非常健全,对于用户而言上手较快。
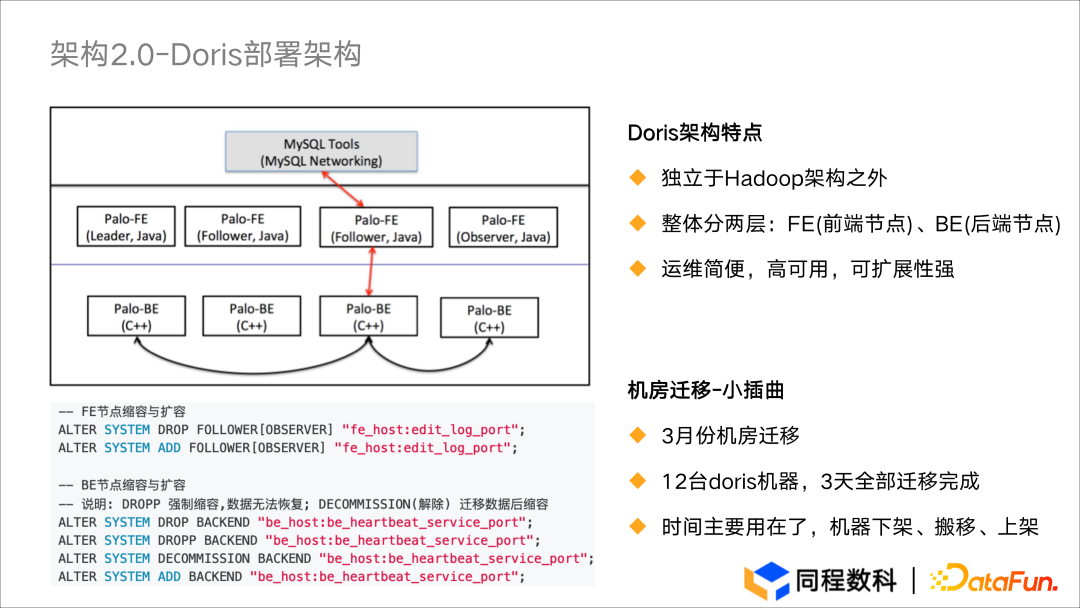
Doris 部署架构
Doris 实时系统架构
Doris 新数仓特点

- Routine Load:主要用于业务数据的接入并作为消费 Kafka 的常驻任务存在。当我们提交 Rountine Load 任务时,Doris 内部会有一个常驻进程实时消费 Kafka ,不断从 Kafka 中读取数据导入进 Doris中。
- Broker Load:进行如基础维度表及历史数据等离线数据导入任务。
- Insert Into:用于定时跑批作业,负责将 DWD 层数据处理,形成 DWS 层以及 ADS 层。
- Unique 模型在 DWD 层接入时使用,可以有效防止重复消费数据。
- Aggregate 模型用作聚合。在 Doris 中,Aggregate 支持如 Sum、Replace、Min 、Max 4 种方式的聚合模型,聚合的过程中使用 Aggregate 底层模型可以减少很大部分 SQL 代码量,不再需要自己做 Sum、Min、Max 等动作,对于从 DWD 层到 DWS/ADS 层较为友好。
- 支持 MySQL 协议,支持标准 SQL,查询语法高度兼容 MySQL,对分析人员较为友好。
- 支持物化视图与 Rollup 物化索引。物化视图底层类似 Cube 的概念与预计算的过程,与 Kylin 中以空间换时间的方式类似,均是在底层生成特殊的表,在查询中命中物化视图时将快速响应。
- 系统只有 BE 和 FE 两个模块,不依赖如 Zookeeper 等三方组件,部署简单。
- 针对 FE 和 BE 的操作进行了监控配置,发生异常时会进行及时性重启。
Doris 经验总结

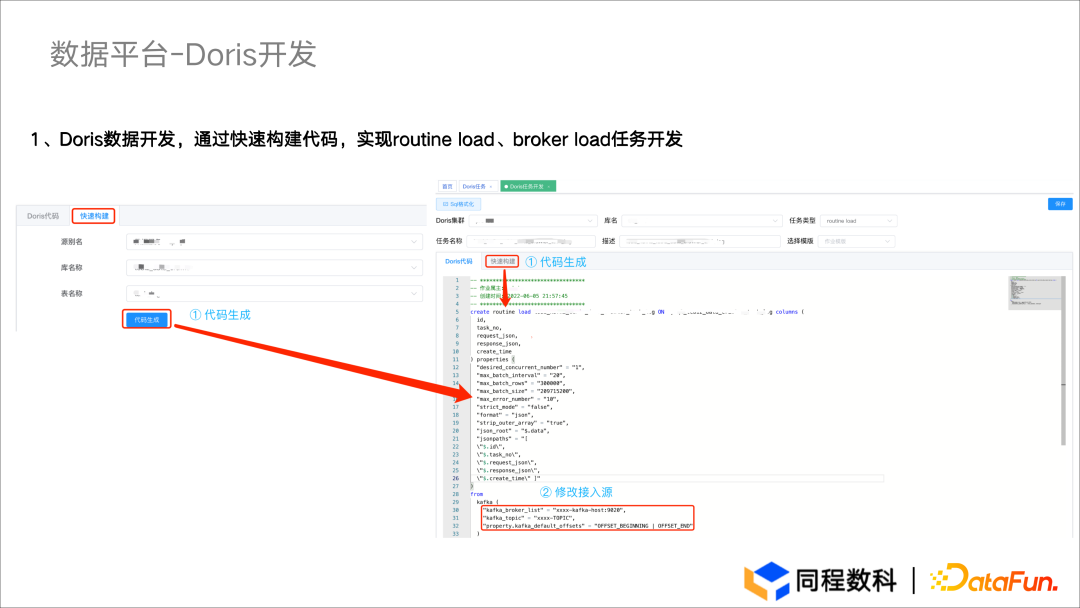
- 开发方面:如何将外部数据接入 Doris 并快速实现 ETL 开发,这会影响开发人员的报表产出速度。
- 调度管理:开发人员不希望在开发完成并上线任务后,出现报错或不稳定的情况,需要保证任务调度的稳定性以及调度恢复能力。
- 数据查询:由于生产与办公网络中间有隔断,办公网络不能直接使用生产网络的连接,并且无法通过客户端的形式解决网络隔断,只能通过 Web 形式解决,如何安全便捷地进行查询和分析成为开发人员关注的问题。
- 集群管理:集群出现异常状况时能够及时进行捕捉及自动化处理。
Doris 开发优化
数据接入
提交动作和维护管理
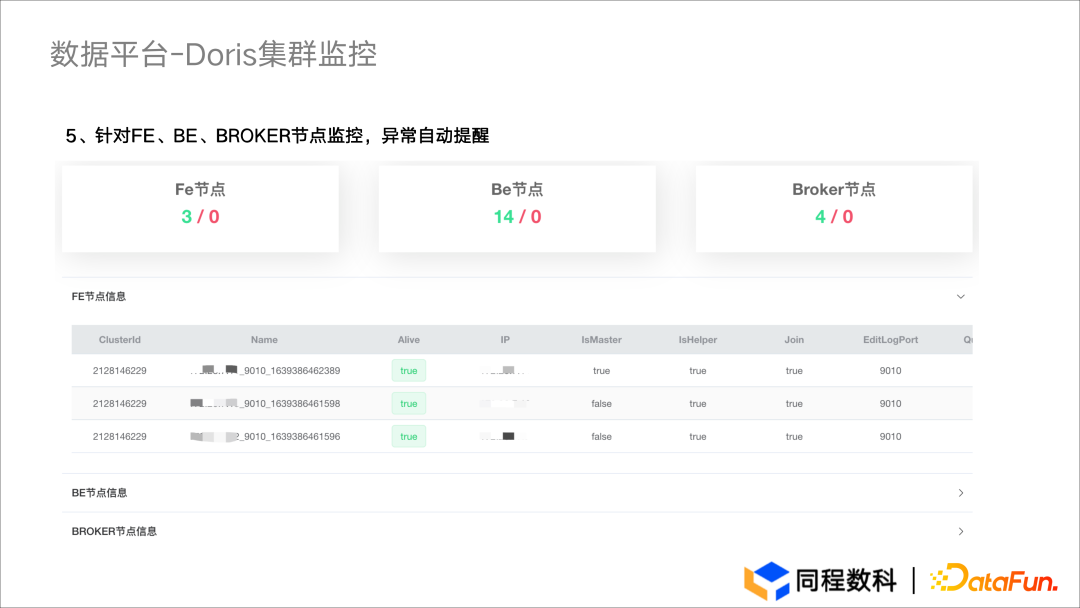
监控与管理
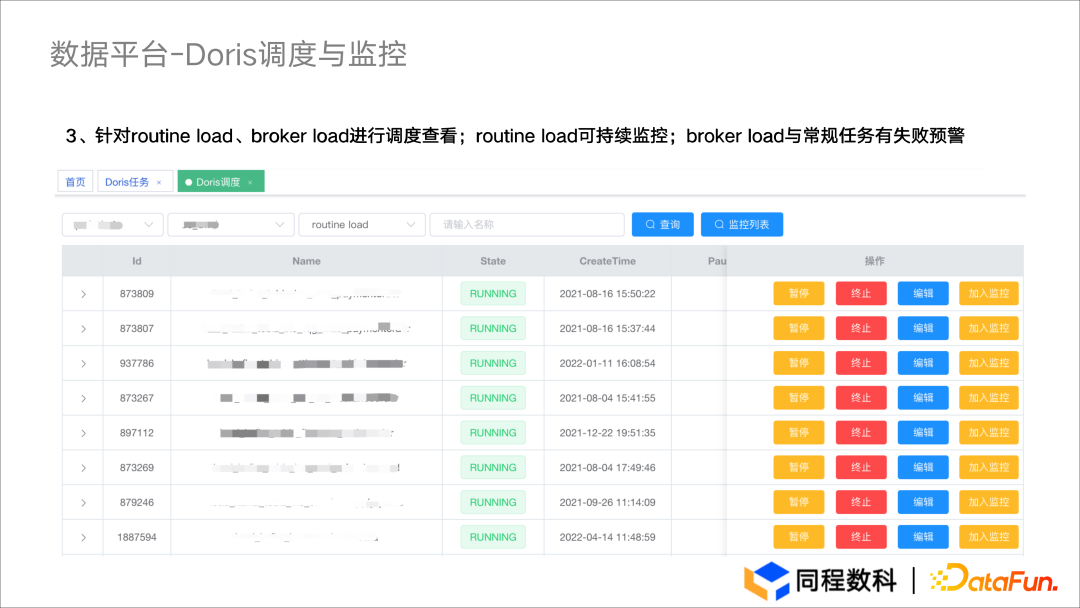
自研查询页面,集成 Doris Help 功能
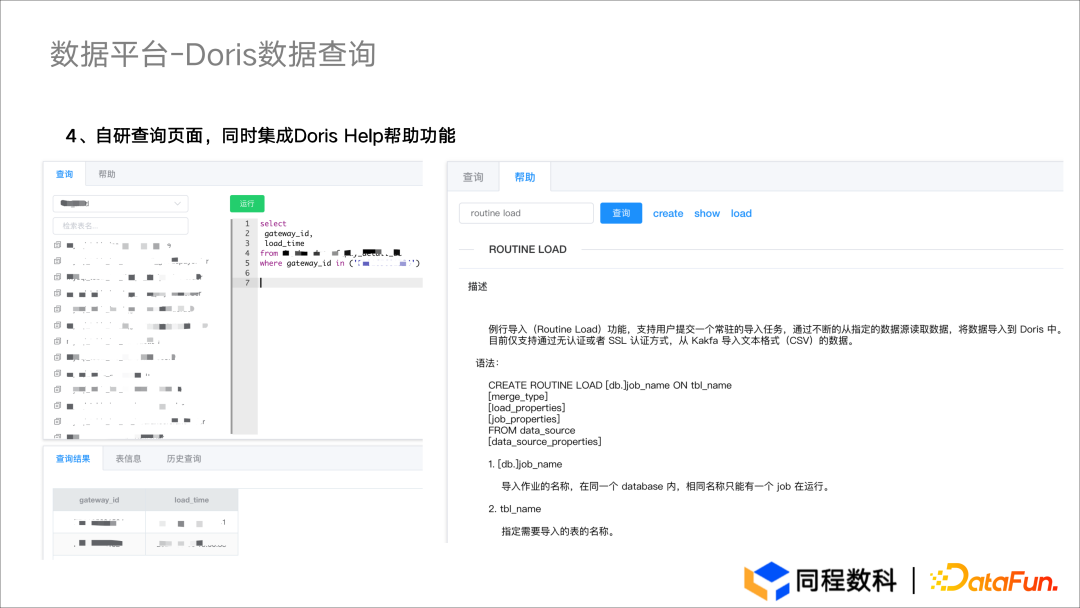
Doris 集群监控页面
新架构的收益

- 数据接入:在早期通过 SteamSets 进行数据接入的过程中需要手动建立 Kudu 表。由于缺乏工具,整个建表和创建任务的过程需要 20-30 分钟。如今可以通过平台与快速构建语句实现数据快速接入,每张表的接入过程从之前的20-30分钟缩短到现在的 3-5 分钟,性能提升了 5-6 倍。
- 数据开发:在早期架构中进行聚合或其他动作时,需要写大量长篇幅 SQL 代码。使用 Doris之后,我们可以直接使用 Doris 中自带的 Unique、Aggregate 等数据模型及可以很好支持日志类场景的 Duplicate 模型,在 ETL 过程中大幅度加快开发过程。
- 查询分析:Doris 底层带有物化视图及 Rollup 物化索引等功能,可以提升查询效率,同时 Doris 底层对于大表关联进行了诸多优化策略,如 Runtime Filter 以及其他 Join 和自定义优化策略。相较于 Doris,Apache Kudu 则需要有较为深入的优化经验才能更好地使用。
- 数据报表:最初使用 Kudu 报表查询需要 1-2 分钟才能够完成渲染,而 Doris 则是秒级甚至是毫秒级的响应速度。
- 环境维护:Doris 没有 Hadoop 生态系统的复杂度,整个链路较为清晰,维护成本远低于 Hadoop,尤其是在集群迁移过程中,Doris 的运维便捷性尤为突出。
未来展望

- 尝试引入 Doris Manager:社区中正在进行关于 Doris Manager 宣导,后续我们也准备引入并积极参与 Doris Manager 进行集群维护与管理。
- 实现基于 Flink CDC 的数据接入:当前架构中没有引入 Flink CDC ,而是继续沿用了 Canal 采集到 Kafka 后再采集到 Doris 中的架构,链路相对来说较长。采用 Flink CDC 虽然可以继续精简整体架构,但是还需要写一定代码量,对于 BI 人员直接使用感受并不友好,我们希望数仓人员只需要 SQL 或在页面上完成操作就可以使用。在 3.0 架构的规划中,我们计划引入 Flink CDC 功能并对上层应用进行扩充。Flink CDC 的引入为大家带来“快就是慢,慢就是快”的思想理念,当然Flink社区的发展速度很快,只有在充分学习大家的经验后,才可以更友好地引入,并在学习经验的过程中对架构进行迭代与优化。
- 紧跟社区迭代计划:我们正在使用的 Doris 版本相对较老,现在新版本 Doris 在内存管理、查询性能等方面有了较大幅度的提升,后续我们将紧跟社区迭代节奏对集群进行升级并体现新特性。
- 强化建设相关体系:我们现在的指标体系管理如报表元数据、业务元数据等维护与管理依旧有待提高。数据质量监控方面,虽然目前包含了数据质量监控功能,但对于整个平台监控与数据自动化监控方面还需要强化与改善。
加入社区

边栏推荐
- How to turn on win11 game mode? How to turn on game mode in win11
- Main functions of OS, Sys and random Standard Libraries
- The difference between NPM uninstall and RM direct deletion
- Redis - basic use (key, string, list, set, Zset, hash, geo, bitmap, hyperloglog, transaction)
- Restapi version control strategy [eolink translation]
- 海外代理推荐
- How much does it cost to develop a small program mall?
- Demon daddy A1 speech listening initial challenge
- DBSync新增对MongoDB、ES的支持
- Virtual machine network configuration in VMWare
猜你喜欢
![[JDBC Part 1] overview, get connection, CRUD](/img/53/d79f29f102c81c9b0b7b439c78603b.png)
[JDBC Part 1] overview, get connection, CRUD
QT compile IOT management platform 39 alarm linkage
Win11时间怎么显示星期几?Win11怎么显示今天周几?
Usage of MySQL subquery keywords (exists)
SQL injection error report injection function graphic explanation
Use camunda to do workflow design and reject operations
Node:504 error reporting

使用 BlocConsumer 同时构建响应式组件和监听状态
Two kinds of updates lost and Solutions
NVR硬盤錄像機通過國標GB28181協議接入EasyCVR,設備通道信息不顯示是什麼原因?

随机推荐
Use br to recover backup data on azure blob storage
L2:ZK-Rollup的现状,前景和痛点
Backup tidb cluster to persistent volume
An overview of the latest research progress of "efficient deep segmentation of labels" at Shanghai Jiaotong University, which comprehensively expounds the deep segmentation methods of unsupervised, ro
SAR影像质量评估
Jerry's manual matching method [chapter]
Ten thousand word summary data storage, three knowledge points
Matplotlib drawing interface settings
Reinforcement learning - learning notes 8 | Q-learning
Ad domain group policy management
【Azure微服务 Service Fabric 】因证书过期导致Service Fabric集群挂掉(升级无法完成,节点不可用)
Demon daddy C
The difference between NPM uninstall and RM direct deletion
Prometheus remote_ write InfluxDB,unable to parse authentication credentials,authorization failed
Node:504 error reporting
Focusing on safety in 1995, Volvo will focus on safety in the field of intelligent driving and electrification in the future
Arlo's troubles
[开源] .Net ORM 访问 Firebird 数据库
NVR硬盤錄像機通過國標GB28181協議接入EasyCVR,設備通道信息不顯示是什麼原因?
建立自己的网站(18)