当前位置:网站首页>Learn CV two loss function from scratch (4)
Learn CV two loss function from scratch (4)
2022-07-08 02:19:00 【pogg_】
notes : Most of the content of this blog is not original , But I sort out the data I collected before , And integrate them with their own stupid solutions , Convenient for review , All references have been cited , And has been praised and collected ~
To continue : Learn from scratch CV Part II loss function (3)
1.3 Sphereface
The Sphereface First mentioned out of CVPR 2017 Of 《SphereFace: Deep Hypersphere Embedding for Face Recognition》, Also known as A-Softmax Loss function , Thesis link :
https://arxiv.org/abs/1704.08063
The author thinks that :
- triplet loss You need to build triples carefully , inflexible ;
- center loss The loss function only emphasizes the degree of aggregation within the class , Pay insufficient attention to the separability between classes .
therefore , The author raises questions : Is the loss function based on Euclidean distance suitable for the model to learn distinguishing features ?
First , Take a look at it again softmax loss Loss function ( namely softmax+ Cross entropy ):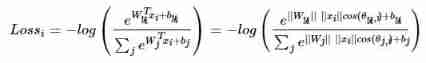
among , θ j , i ( 0 ≤ θ j , i ≤ π ) θ_{j,i} (0\leqθ_{j,i}\leq\pi) θj,i(0≤θj,i≤π) It's a vector W j W_j Wj and x i x_i xi The angle between . You can see , Loss function and ∣ ∣ W j ∣ ∣ ||W_j|| ∣∣Wj∣∣, θ j , i \theta_{j,i} θj,i and b j b_j bj of , Make ∣ ∣ W j ∣ ∣ = 1 ||W_j||=1 ∣∣Wj∣∣=1 and b j = 0 b_j=0 bj=0 , You can get modified-softmax Loss function , Pay more attention to angle information :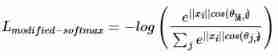
Although the use of modified-softmax The loss function can learn that the feature has angle discrimination , But this distinction is still not strong enough . therefore , stay θ j , i θ_{j,i} θj,i Multiply by a greater than 1 The integer of , To improve the discrimination :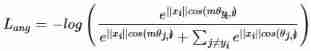
such , It can expand the distance between classes , It can also reduce the distance within the class .
In short, it's in margin softmax loss On the basis of this, two restrictions are added ||W||=1 and b=0, Make the forecast only depend on W and x The angle between .
The picture below is margin softmax,modified softmax and A-Softmax Experimental comparison of three loss functions on the same batch of data .
The following figure shows the experimental results of the paper , Explain from the perspective of hypersphere , Different m The result of the value . among , Dots of different colors represent different categories . It can be seen that , Use A-Softmax Loss function , Will map the learned vector features to the hypersphere ,m=1 It means to degenerate into modified-softmax Loss function , It can be seen that , Although each category has obvious distribution , But the distinction is not obvious . With m The increase of , The distinction will become more and more , But it's getting harder and harder to train .
1.4 Cosface
Cosface My proposal is in Tencent AI Lab Published in CVPR 2018 The paper of 《CosFace: Large Margin Cosine Loss for Deep Face Recognition》, Thesis link :
https://arxiv.org/pdf/1801.09414.pdf
Cosface Loss function , Also known as Large Margin Cosine Loss(LMCL), This method is based on cos Maximize the interval , To expand the distance between classes , Reduce the distance within the class .
from softmax set out ( And Sphereface similar ), The author found , In order to achieve effective feature learning , ∣ ∣ W j = 1 ∣ ∣ ||Wj=1|| ∣∣Wj=1∣∣ It is necessary to , That is, normalize the weight . meanwhile , In the test phase , The score of the face pair used in the test is usually calculated according to the cosine similarity between the two feature vectors . This shows that , ∣ ∣ x ∣ ∣ ||x|| ∣∣x∣∣ It has little effect on score calculation , therefore , During the training phase ∣ ∣ x ∣ ∣ = s ||x||=s ∣∣x∣∣=s Fixed ( In the paper ,s=64):
among L n s L_{ns} Lns Represents normalized version softmax loss, θ j , i θ_{j,i} θj,i Express W j W_j Wj And x x x The angle between . In order to increase differentiation , similar Sphereface equally , Introduce constant m: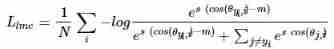
among , W = W ∗ ∣ ∣ W ∗ ∣ ∣ , x = x ∗ ∣ ∣ x ∗ ∣ ∣ , c o s ( θ j , i ) = W j T x i W=\frac{W^*}{||W^*||},x=\frac{x^*}{||x^*||},cos(\theta _j,i)=W^T_jx_i W=∣∣W∗∣∣W∗,x=∣∣x∗∣∣x∗,cos(θj,i)=WjTxi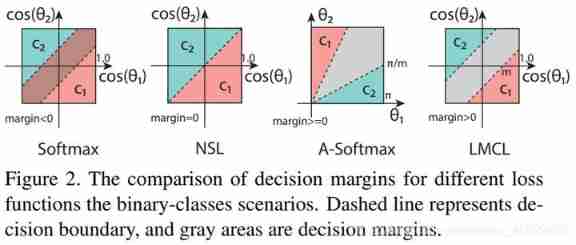
The above figure is the author's explanatory diagram :
- The first one means normal sotfmax loss, It can be seen that the classification boundaries of the two categories overlap , That is, the distinction is not strong ;
- The second represents the normalized version softmax loss, At this time, the boundary is already obvious , There is no overlap , However, there are still deficiencies in differentiation ;
- The third means A-softmax, At this time, the horizontal and vertical coordinates become θ θ θ, Explain from this perspective , Use two lines as the dividing boundary , The author also suggests that , The disadvantage of this loss function is discontinuity (A-Softmax It's the right angle θ θ θ Constraint , So now c o s ( θ ) cos(θ) cos(θ) In the coordinates of , It's a fan-shaped page demarcation area . however A-Softmax Of margin It's not continuous , With θ θ θ Reduction ,margin It's also decreasing , When θ θ θ be equal to 0 When margin Even disappear );
- The fourth means Cosface, stay cos(θ) Next , Use two lines as the dividing boundary , There is no intersection between features , The distinction is quite obvious .
With m Value increases , The distinction will become more and more obvious , But the training will be more difficult .
1.5 Arcface
The Arcface The loss function is proposed from 《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》, Thesis link :
https://arxiv.org/abs/1801.07698
Be similar to Sphereface and Cosface,Arcface It also needs to be ordered ∣ ∣ W ∣ ∣ = 1 , ∣ ∣ x ∣ ∣ = s ||W||=1,||x||=s ∣∣W∣∣=1,∣∣x∣∣=s , Constants are also introduced m, But unlike the previous two , there m It's right θ θ θ Make changes :
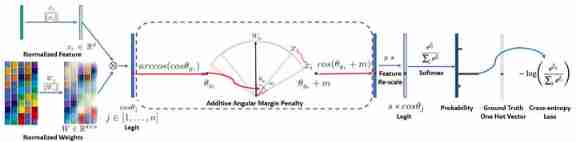
The picture below is Arcface Calculation flow chart of , First of all, x x x And W W W Standardize , Then multiply to get c o s ( θ j , i ) cos(θ_{j,i}) cos(θj,i) , adopt a r c c o s ( c o s ( θ j , i ) ) arccos(cos(θ_{j,i})) arccos(cos(θj,i)) To get the angle θ j , i θ_{j,i} θj,i , Add the constant m To increase the spacing to get θ j , i + m θ_{j,i}+m θj,i+m , Calculated after c o s ( θ j , i + m ) cos(θ_{j,i}+m) cos(θj,i+m) And multiply by the constant s, The last part softmax Functions and cross entropy loss To deal with .
The pseudocode given by the author is as follows :
In fact, I think ,arcface The more important thing is to promote mxnet This framework , Now, ,mxnet It is indeed one of the commonly used frameworks for face recognition .
Analyze from the perspective of spatial characteristics ,ArcFace Than Softmax The feature distribution is more compact , The decision boundary is more obvious .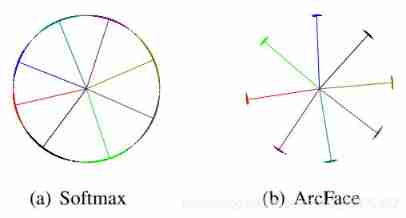
Add :
arcface The paper experiment is done in great detail , The ideas elaborated in this paper are as follows :
- ArcFace loss:Additive Angular Margin Loss( Plus angular spacing loss function ), Normalize eigenvectors and weights , Yes θ θ θ Plus angular spacing m , The influence of angle interval on angle is greater than cosine interval More direct . There is a constant linear angle in geometry margin.
- ArcFace Is directly in angular space θ θ θ Maximize classification boundaries in , and CosFace It's in cosine space c o s ( θ ) cos(θ) cos(θ) Maximize classification boundaries in . Preprocessing ( Face alignment ): The face key points are determined by MTCNN testing , Then the cropped aligned face is obtained by similarity transformation .
- Training ( Face classifier ):ResNet50 + ArcFace loss
- test : From face classifier FC1 Extract... From the output of the layer 512 Embedding feature of dimension ( What we often say Embeding), Calculate the cosine distance for the two input features , Then face verification and face recognition .
- The training time in the actual code is resnet + arcface loss + softmax + cross entropy loss.resnet
Extracting images ( It's also a face ) features ( Multidimensional tensor );arcface loss Add the angle spacing to the feature and weight parameters , Then output the prediction label ;softmax + cross entropy loss Calculate the error between the prediction label and the actual ( That is, the prediction value of the estimation model we mentioned in the previous article f ( x ) f(x) f(x) And the real value y y y The degree of inconsistency ).
2. summary
In this article, we talk about several loss functions commonly used in face recognition , Borrow here Arcface The illustrations and knowledge in the paper Mengcius Several views in the boss are supplemented by image explanation :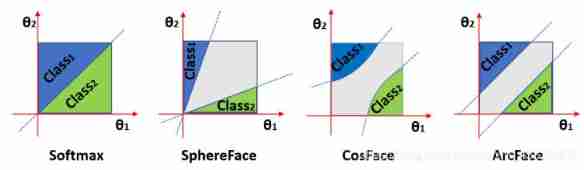
- ArcFace Of has a linear angle in the whole interval margin, The proposed additive angular spacing has good geometric properties .
- CosFace Of margen There are nonlinear angular intervals in angular space , But in cos It is a straight line in space ;
- SphereFace Of margin It's a fan-shaped page demarcation area , But discontinuous , With θ θ θ Reduction ,margin It's also decreasing , When θ θ θ
be equal to 0 When margin Even disappear ; - Normalized version softmax loss No, margin perhaps margin The distinction is not obvious .
Reference resources :
[1] https://www.cnblogs.com/dengshunge/p/12252820.html
[2] https://blog.csdn.net/u014380165/article/details/76946380
[3] https://zhuanlan.zhihu.com/p/45153595
边栏推荐
- 如何用Diffusion models做interpolation插值任务?——原理解析和代码实战
- 发现值守设备被攻击后分析思路
- 1331:【例1-2】后缀表达式的值
- COMSOL --- construction of micro resistance beam model --- final temperature distribution and deformation --- addition of materials
- Node JS maintains a long connection
- Introduction to Microsoft ad super Foundation
- Unity 射线与碰撞范围检测【踩坑记录】
- Key points of data link layer and network layer protocol
- CV2 read video - and save image or video
- Principle of least square method and matlab code implementation
猜你喜欢

Unity 射线与碰撞范围检测【踩坑记录】
JVM memory and garbage collection -4-string
Nmap tool introduction and common commands

"Hands on learning in depth" Chapter 2 - preparatory knowledge_ 2.2 data preprocessing_ Learning thinking and exercise answers

ClickHouse原理解析与应用实践》读书笔记(8)
Can you write the software test questions?
![[knowledge map paper] Devine: a generative anti imitation learning framework for knowledge map reasoning](/img/c1/4c147a613ba46d81c6805cdfd13901.jpg)
[knowledge map paper] Devine: a generative anti imitation learning framework for knowledge map reasoning
![[knowledge map paper] r2d2: knowledge map reasoning based on debate dynamics](/img/e5/646ae977b8a0dc1b1ac2250602a2b9.jpg)
[knowledge map paper] r2d2: knowledge map reasoning based on debate dynamics

2022年5月互联网医疗领域月度观察

JVM memory and garbage collection-3-runtime data area / heap area

随机推荐
metasploit
Ml backward propagation
COMSOL --- construction of micro resistance beam model --- final temperature distribution and deformation --- addition of materials
Ml self realization / logistic regression / binary classification
burpsuite
LeetCode精选200道--数组篇
LeetCode精选200道--链表篇
Key points of data link layer and network layer protocol
leetcode 865. Smallest Subtree with all the Deepest Nodes | 865. The smallest subtree with all the deepest nodes (BFs of the tree, parent reverse index map)
企业培训解决方案——企业培训考试小程序
BizDevOps与DevOps的关系
文盘Rust -- 给程序加个日志
鱼和虾走的路
CorelDRAW2022下载安装电脑系统要求技术规格
th:include的使用
分布式定时任务之XXL-JOB
MQTT X Newsletter 2022-06 | v1.8.0 发布,新增 MQTT CLI 和 MQTT WebSocket 工具
Can you write the software test questions?
谈谈 SAP iRPA Studio 创建的本地项目的云端部署问题
Many friends don't know the underlying principle of ORM framework very well. No, glacier will take you 10 minutes to hand roll a minimalist ORM framework (collect it quickly)