当前位置:网站首页>[knowledge map paper] Devine: a generative anti imitation learning framework for knowledge map reasoning
[knowledge map paper] Devine: a generative anti imitation learning framework for knowledge map reasoning
2022-07-08 02:08:00 【Wwwilling】
Article
Literature title :DIVINE: A Generative Adversarial Imitation Learning Framework for Knowledge Graph Reasoning
Document time :2019
Journal Publishing :EMNLP
Abstract
- Knowledge map (KGs) Often suffer from sparsity and incompleteness . Knowledge map reasoning provides a feasible method to solve such problems . Recent research on knowledge edge graph reasoning shows that , Based on Reinforcement Learning (RL) The method can provide the most advanced performance . However , Existing based on RL Our method requires a lot of path finding experiments , And it relies heavily on meticulous reward projects to adapt to specific data sets , This is for the rapid development of KG It's inefficient and laborious . In this paper , We proposed DIVINE, It's based on Generative confrontation imitation learning New plug and play framework , Used to enhance existing RL Methods . DIVINE Guide the pathfinding process , And imitate from KG The demonstration of automatic sampling in self-adaptive learning reasoning strategy and reward function . The experimental results on two benchmark data sets show that , Our framework proves that the existing framework is based on RL The performance of the method .
introduction
- Knowledge map , It usually consists of a large number of relational triples , It is a useful resource for many downstream naturallanguageprocessing applications , For example, information extraction and question answering . Despite the existing KG It has a very large scale , But they are still highly incomplete (Min etc. ,2013 year ), Led to extensive research work , That is, automatically infer missing information from observed evidence . In this paper , We focus on KG Multi hop reasoning in , It learns explicit reasoning formulas from existing triples to complete the missing triples .
- To solve multi hop reasoning , Various path based methods (Lao et al., 2011; Gardner et al., 2013, 2014; Guu et al., 2015; Neelakantan et al., 2015; Toutanova et al., 2016; Das et al., 2017) Has been proposed , It USES KG The carefully selected relationship path is used as reasoning evidence . However , Such evidence path is obtained by random walk , This inevitably introduces poor or even noisy paths . To solve this problem , be based on RL Methods , Such as Deep Path (Xiong et al., 2017) and MINERVA (Das et al., 2018), Strive for a more reliable evidence path through strategic conditional walking , And realize the state - The most advanced performance . They express the path finding problem as a Markov decision process , Among them, the policy based agent continuously selects the most promising state transition relationship according to the current state and reasoning strategy . Once the relationship path is found , The reasoning strategy will be updated by the reward function according to the path quality . Last , Through this trial and error process , Well trained policy based agents can be used to find the evidence path of prediction .
- However , These are based on RL The method still has the following pain points . First , They often need to do many experiments from scratch to find a reliable evidence path , Because of KG Complexity , The action space may be very large , This leads to poor convergence . secondly , And the most important ,RL Effective trial and error optimization in requires Manually design the reward function To fit a specific data set . However , This kind of reward project relies on fine manual design with domain expertise , This may be very challenging in practice (Ng et al., 2000). especially , These are based on RL Methods Extremely sensitive to its reward function , A slight change may lead to significant fluctuations in reasoning performance . therefore , For different data sets ,RL The reward function in requires manual adjustment to achieve good performance , This is not only inefficient 、 Laborious , And it is difficult to adapt to the real world KG The rapid evolution of (Shi and Weninger,2018 year ).
- In this paper , We propose a kind of imitation learning based on generative antagonism (GAIL) (Ho and Ermon, 2016) New plug and play framework , Used to enhance existing RL Methods , The framework is called DIVINE, be used for “ Deep reasoning ” By imitating non-human experts ”. DIVINE By using generative confrontation training, a reasoner composed of generator and discriminator is trained from the demonstration , among The generator can be an existing one based on RL Any policy based agent in the method of , The discriminator can be considered as an adaptive reward function . such , For different data sets , The reward function can be automatically adjusted to approach the best performance , Thus eliminating additional incentive projects and human intervention . especially , In order to enable policy based agents to find more different prediction evidence paths , We propose a path based GAIL Method , This method can learn reasoning strategies by imitating the path level semantic features of the demonstration . Besides , In order to get a demonstration without extra labor , We designed a for our framework Automatic sampler , From... Dynamically according to the specific environment of each entity KG Sampling relationship path in as a demonstration .
- All in all , Our contribution has three aspects :
- We propose a method based on GAIL Plug and play framework , Learn reasoning strategies and reward functions by imitating demonstrations , To enhance KG The existing ones in are based on RL The reasoning of . As far as we know , We are the first to GAIL People who introduce knowledge map reasoning .
- We propose a path based GAIL Methods to encourage the diversity of evidence paths , And design an automatic sampler for our framework to sample the demo , Without extra labor .
- We have conducted extensive experiments on two benchmark data sets . Experimental results show that , Our framework improves the current state-of-the-art based on RL The performance of the method , At the same time, it eliminates additional incentive projects .
Related work
- KG Automatic reasoning has always been a long-term task of natural language processing . In recent years , Various embedding based methods use tensor decomposition (Nickel et al., 2011; Bordes et al., 2013; Riedel et al., 2013; Yang et al., 2014; Trouillon et al., 2017) Or neural network model (Socher et al., 2013) Has been developed , They learned a projection , Map triples into a continuous vector space , For further tensor operations . Despite their impressive results , But most of them lack the ability to capture the chain of multi hop reasoning patterns contained in the path .
- In order to solve the limitations of embedding based methods , A series of path based methods have been proposed , They take the selected relationship path as reasoning evidence . Lao wait forsomeone (2011) A path sorting algorithm using random walk for path search is proposed (PRA). Gardner wait forsomeone (2013, 2014) Put forward PRA A variant of , It calculates the feature similarity in vector space . In order to combine embedding based methods , Several neural multi hop models for hybrid reasoning are proposed . However , The evidence path they used was collected by random walk , This may be inferior and noisy .
- lately ,DeepPath (Xiong et al., 2017) and MINERVA (Das et al., 2018) It is proposed to solve the above problems by using reinforcement learning , They are committed to learning a strategy to guide agents to find more and better evidence paths to maximize the expected reward . say concretely ,DeepPath The strategy is parameterized using a fully connected neural network , And use manual reward criteria ( Including global accuracy 、 Efficiency and diversity ) To evaluate the path quality . In the training phase ,DeepPath Apply the linear combination of these criteria as a positive reward , At the same time, the manual constant is used as the negative penalty . as for MINERVA, It uses short - and long-term memory networks (LSTM) Parameterize its strategy , And regard path effectiveness as the only reward standard . In the training phase ,MINERVA The Boolean value is used as the terminal signal to evaluate whether the current path reaches the target entity , And manually adjust the moving average of cumulative discount rewards on different data sets to reduce variance .
Preliminary training
Knowledge graph reasoning
- Given an incomplete knowledge graph G = { ( h , r , t ) ∣ h ∈ E , t ∈ E , r ∈ R } G = \{ (h, r, t)|h \in E, t \in E, r \in R \} G={ (h,r,t)∣h∈E,t∈E,r∈R}, among E E E and R R R Represent entity set and relation set respectively . Knowledge graph reasoning has two main tasks , That is, link prediction and fact prediction . Link prediction involves entities in a given header h h h Queries and relationships r q r_q rq Infer the tail entity t t t, And fact prediction aims to predict unknown facts ( h , r q , t ) (h, r_q, t) (h,rq,t) Is it true . lately , be based on RL Reasoning has become a popular method of knowledge graph reasoning , It achieves the most advanced performance . Generally speaking , be based on RL The reasoning method tries to find the relationship path to adjust its reasoning strategy to predict , The path finding problem is expressed as a Markov decision process (MDP). In such a process , Policy based agents infer strategies based on them π π π Decide from the current state ( That is, the current entity and its context information ) s ∈ S s \in S s∈S take action a ∈ A a \in A a∈A Get to the next , The action space is defined as G G G All relationships in . Specially , Each relationship chain in the relationship path can be considered as a reasoning chain .
Imitation learning
- Imitation learning focuses on learning policy from demonstration , Great success has been achieved in solving the incentive project . The classic method is through inverse reinforcement learning (IRL) (Russel l, 1998; Ng et al., 2000) Find the best reward function to explain the expert's behavior . However ,IRL It needs to be solved in the learning cycle RL, This can be expensive to run in large environments . therefore , Recently, generative confrontation simulation learning was proposed (GAIL) (Ho and Ermon, 2016), It generates confrontation Networks (GAN) Learn expert strategies (Goodfellow et al., 2014), Eliminates any middle IRL step .
- stay GAIL in , generator G θ G_θ Gθ Trained to generate tracks that match the distribution of expert tracks ( Demonstration ). Each track τ τ τ Indicates the status - Action sequence [ ( s t , a t ) ] t = 0 ∞ ( s t ∈ S , a t ∈ A ) [(s_t , a_t)]_{t=0}^∞ (s_t \in S, a_t \in A) [(st,at)]t=0∞(st∈S,at∈A). Besides , I also learned a discriminator D ω D_ω Dω To distinguish the generated strategies π θ π_θ πθ And expert strategies π E π_E πE. For each training period , First use the gradient update discriminator :
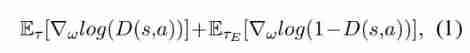
- among τ E τ_E τE By π E π_E πE Generated expert tracks , The trajectory is expected to be in γ γ γ The infinite horizon of discount is calculated as :

- The discriminator here can be interpreted as a local reward function , Provide feedback for the strategy learning process . then , The generator uses trust zone policy to optimize (TRPO) Update cost function l o g ( D ( s , a ) ) log(D(s, a)) log(D(s,a)) (Schulman et al., 2015). After full confrontation training ,GAIL You can find the best strategy π ^ \hat{\pi} π^ Rationalize expert strategies π E π_E πE.
Method
Framework Overview
- Pictured 1 Shown , Our framework DIVINE It consists of two modules , That is, generate confrontation reasoner and demonstration sampler . Specially , The reasoner consists of a generator and a discriminator . The generator can be an existing one based on RL Any policy based agent in the method of , The discriminator can be interpreted as an adaptive reward function . For each query relationship , Samplers and generators are used to automatically extract demos from a given KG Generate relationship paths in . Then use the discriminator to evaluate the semantic similarity between the generated path and the presentation to update the generator .
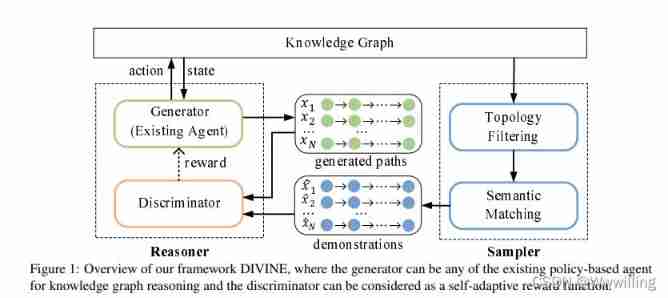
- figure1: Our framework DIVINE summary , The generator can be any existing policy based knowledge graph reasoning agent , The discriminator can be regarded as an adaptive reward function .
- After sufficient confrontation training between generator and discriminator , Well trained policy based agents ( That is, generator. ) It can be used to find the evidence path matching the demonstration distribution , And predict by synthesizing these evidence paths .
Generate confrontation inference engine
- In our framework , The reasoner learns from the demonstration by generating confrontation training . A direct method is to apply GAIL To train the reasoner . especially , Policy based agents in the reasoner are trained to simulate each expert's trajectory ( Demonstration ) The state of - Action pairs to find the evidence path . however , This method may lead to poor performance . The main reason is that the agent tends to choose the same action as the expert track in some states , Many valuable evidence paths that are semantically similar to expert tracks but contain different reasoning chains are ignored .
- therefore , To encourage agents to find more diverse evidence paths , It's best to imitate every track rather than every state - Action pairs train agents . Besides , In the scenario of knowledge map reasoning , Because the reasoning chain is only composed of relationships , Therefore, the presentation does not necessarily contain status information . let me put it another way , The demo can only consist of relational paths .
- Based on the above analysis , We propose a path based GAIL Method , This method learns the reasoning strategy by imitating the path level semantic features of the demonstration composed of only relational paths .
- In the following , We first describe two components of the reasoner , Generator and discriminator . then , We show how to extract path level semantic features .
generator
- The generator can be an existing one based on RL Any policy based agent in the method of . We strive to enable the generator to find more diverse evidence paths that match the presentation distribution in the semantic space .
Judging device
- In order to better distinguish the generated path from the presentation in semantics , We choose convolutional neural network (CNN) To build our discriminator D D D, because CNN It shows high performance in extracting semantic features from natural language (Kim, 2014).
Semantic feature extraction
- For each positive entity pair , We package the currently generated path and the corresponding demo in the same package In form . To contain N N N Each of the relationship paths package P = { x 1 , x 2 , . . . , x N } P = \{ x_1, x_2, ..., x_N \} P={ x1,x2,...,xN}, We will package Encoded as a real valued matrix :
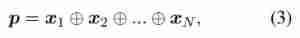
- among x n ∈ R k x_n \in R^k xn∈Rk yes k k k Dimension path embedding , ⊕ ⊕ ⊕ Express package Express p ∈ R N × k p \in R^{N×k} p∈RN×k Connection operator of . especially , Given a relationship path x = { r 1 , r 2 , . . . r t , . . . } x = \{ r_1, r_2, ...r_t , ...\} x={ r1,r2,...rt,...}, Embedded path x x x Encoded as :

- Each of these relationships r t r_t rt Map to by TransE Real value embedding of pre training r t ∈ R k r_t \in R^k rt∈Rk (Bor des et al., 2013).
- After packing , We will express the package p p p Enter our discriminator D D D To parameterize its semantic features D ( p ) D(p) D(p). say concretely , First use by ReLU Nonlinear activation of convolution layer through sliding kernel ω ∈ R h × l ω \in R^{h×l} ω∈Rh×l To extract local features , To get a new feature map :

- among b c b_c bc Represents the offset term . then , A fully connected hidden layer and an output layer are used for further semantic feature extraction :

- For brevity , The corresponding deviation is not shown above , The output layer consists of sigmoid Function normalization , Other layers are made of ReLU Nonlinear activation .
Demo sampler
- For imitation learning , The first premise is to have high-quality demonstrations . However , because KG The scale and complexity of , Manually building a large number of reasoning demonstrations requires a lot of time and expert efforts . therefore , We have designed an automatic sampler to take samples from KG Sampling reliable reasoning demonstration , Without supervision and extra labor .
Static demo sampling
- For each query relationship , We use all positive entity pairs from a given KG Medium sampling demonstration candidates . say concretely , For each positive entity pair , We use two-way breadth first search to explore the shortest path between two entities . especially , Because shorter paths tend to characterize the more direct correlation between two entities , We prefer to use them for initialization to ensure the quality of presentation candidates . As for the longer path , Despite their potential utility value , But they are more likely to contain worthless or even noisy reasoning steps , So we only learn them in the training stage . To do so , We can get a demo set Ω E Ω_E ΩE, It includes all the candidates we sampled . Last , In order to adapt to the discriminator D D D Fixed input dimension , We can simply select a subset P e ⊆ Ω E P_e ⊆ Ω_E Pe⊆ΩE, Its highest frequency is N N N, among N N N Usually much less than ∣ Ω E ∣ |Ω_E| ∣ΩE∣.
Dynamic demo sampling
- Although the static demonstration sampling method is very simple , But the demonstration obtained by this method is fixed , And ignores the given KG The specific environment of each entity in . therefore , We propose an improved method of dynamic sampling demonstration by considering the topological correlation of entities .
- Given a positive entity pair * e h e a d , e t a i l * *e_{head},e_{tail}* *ehead,etail*, We introduce a relation set R h R_h Rh, It includes all and e h e a d e_{head} ehead Directly related relationship . For every inference attempt , R h R_h Rh It can be regarded as the region of interest where the agent starts reasoning (ROI), with ROI The relevant path is often more relevant to the current entity pair . therefore , We filter out from R h R_h Rh Start the demo to optimize the demo set :
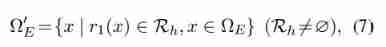
- among Ω E Ω_E ΩE Generated by static demonstration sampling method , r 1 ( x ) r_1(x) r1(x) Represents the relationship path x = { r 1 , r 2 , . . . r t , . . . } x = \{ r_1, r_2, ...r_t, ...\} x={ r1,r2,...rt,...} The first relationship in .
- in the majority of cases , We can do it in Ω E ′ Ω^′_E ΩE′ Get enough demos to select subsets P e ⊆ Ω E ′ P_e ⊆ Ω^′_E Pe⊆ΩE′, The method is the same as the static demonstration sampling method . However , because KG Sparsity of data in , We may not be able to get enough demonstrations on long tail entities . To solve this problem , We perform semantic matching to explore the remaining candidates C E = Ω E \ Ω E ′ C_E = Ω_E \backslash Ω^′_E CE=ΩE\ΩE′ More demos of . Because the reasoning strategy is updated according to the semantic similarity between the generated path and the presentation , Therefore, candidates that are semantically similar to the current demonstration also have guiding significance for the imitation process .
- Inspired by the neighborhood attention of one-time imitation learning (Duan et al., 2017), We use KaTeX parse error: Expected group after '^' at position 2: Ω^̲'_E To query other candidate dates related to itself . We use dot product to measure the semantic matching similarity between two path embeddings :
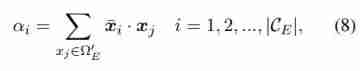
- among α i α_i αi Indicates the current candidate x ˉ i \bar{x}_i xˉi And Ω E ′ Ω'_E ΩE′ Sum of matching scores between existing demonstrations in . Last , We iteratively choose to have the highest α α α Candidates to fill the detailed demo set Ω E ′ Ω^′_E ΩE′, Until the required input dimension is met N N N.
Training
- In the training phase , All positive entity pairs are used to generate demonstration candidates for the imitation learning process Ω E Ω_E ΩE. say concretely , For every positive entity pair , First of all, you need to select the corresponding demo for the demo sampler , At the same time, guide the generator to generate some relationship paths . then , Package the presentation into a package P e P_e Pe in , The generated path is packaged to different package ages according to its validity { P g ∣ P g ⊆ Ω G } \{ P_g | P_g ⊆ Ω_G\} { Pg∣Pg⊆ΩG} in , That is, whether the agent can reach the target entity along the current path , among Ω G Ω_G ΩG Is a collection of all generation paths .
- For each package pair * P g , P e * *P_g,P_e* *Pg,Pe*, We train the discriminator by minimizing its loss D D D, And expect it to become a distinction P e P_e Pe and P g P_g Pg Expert . Besides , In order to make the confrontation training process more stable and effective , We use WGAN-GP (Gulrajani et al.,2017) To update the discriminator :

- among L C L_C LC 、 L P L_P LP and L D L_D LD Respectively represents the loss of the original critic 、 Gradient penalty and discriminator loss , λ λ λ Is the gradient penalty coefficient t t t and p ~ \tilde{p} p~ Along the p g p_g pg and p e p_e pe The straight lines between are evenly sampled . According to the feedback of the discriminator , We calculate rewards R G R_G RG by :
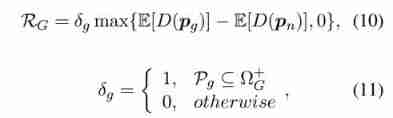
- among p n p_n pn Represents a noise embedding consisting of random noise with continuous uniform distribution , δ g δ_g δg It's a token package P g P_g Pg The characteristic function of effectiveness , Ω G + Ω^+_G ΩG+ Is a collection of all valid generation paths . We only embed for at least specific noise p n p_n pn Some effective paths with higher expectations are given positive rewards , Noise embedding p n p_n pn Filter out poor quality paths , To improve the convergence efficiency of the training process . Once you get the reward , We use Monte-Carlo Policy gradient ( namely REINFORCE) Maximize the expected cumulative rewards to update the generator G G G(Williams,1992).
experiment
Data sets and evaluation indicators
- The experiment was carried out on two benchmark data sets :NELL-995 (Xiong et al, 2017) and FB15K-237 (Toutanova et al, 2015). The details of the two datasets are shown in table 1 Described in . especially ,NELL-995 Is a simple data set known for reasoning tasks , It's from NELL The first part of the system 995 Sub iteration (Carlson etc. ,2010) By choosing to have the previous 200 Generated by triples with frequent relationships . And NELL 995 comparison ,FB15K-237 More challenging , Closer to the real scene , The fact is from FB15K (Bordes et al, 2013) Created , Deleted redundant relationship . For each triple ( h , r , t ) (h, r, t) (h,r,t), Both datasets contain inverse triples ( h , r − 1 , t ) (h, r^{−1} , t) (h,r−1,t), So the agent can KG Take a step back , This makes it possible to recover from potentially wrong decisions made before . For each with a query relationship r q r_q rq Reasoning task , All have r q r_q rq or r q − 1 {r_q}^{−1} rq−1 All triples of are from KG Delete in , And divided into training and testing samples .
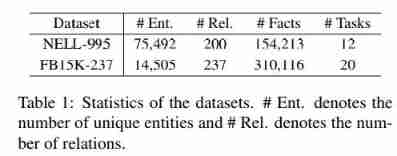
- surface 1: Statistics of the data set . # Ent: Represents the number of unique entities and #Rel: Indicates the number of relationships .
- Similar to recent work (Das wait forsomeone ,2018;X iong wait forsomeone ,2017), We use average precision (MAP)、 Average reciprocal ranking (MRR) and [email protected] To evaluate reasoning performance , among [email protected] It's at the top of the list k k k The proportion of positive instances of bits .
Baseline and implementation details
- In our experiment , We will base two of the most advanced on RL As a baseline :DeepPath (Xiong et al., 2017) and MINERVA (Das et al., 2018). The depth path provides the collected evidence path to PRA (Lao et al., 2011), Used to link prediction and fact prediction tasks , and MINERVA Apply trained agents directly to link prediction tasks for question and answer . about Deep Path, We use Xiong wait forsomeone (2017) Released code . about MINERVA, We use Das wait forsomeone (2018) Released code . The experimental setup of the baseline is based on the suggestions in the original paper .
- In the implementation of our framework , We will package each path P P P Path number of N N N Set to 5, And the path dimension k k k Set to 200, This is the same as the relationship dimension in the baseline . For discriminators , We set the convolution kernel size to 3×5, The size of the hidden layer is 1024, The size of the output layer is the path dimension k k k, At the same time, the gradient penalty coefficient λ λ λ Set to 5,L2 Regularization is also used to avoid over fitting .
- During the test , We also associate answer triples with DeepPath and MINERVA The negative triples used in . especially , Each positive triple has about 10 Corresponding negative triples . Each negative triplet is created by using a false t ′ t' t′ Replace the answer entity t t t Generated , Given a positive triple ( h , r , t ) (h, r, t) (h,r,t).
result
- The main results of the two data sets are shown in table 2 Shown . We use “Div()” Indicates the adoption of our framework DIVINE Based on the RL Methods “”. For a fair comparison , We are in accordance with the MINERVA The report [email protected] and MRR fraction ( use “†” Express ) To evaluate the link prediction performance of question answering , It ranks entities according to the probability that agents can reach entities along the evidence path . Besides , We also follow DeepPath Report the fact of the prediction task MAP fraction ( use “‡” Express ), It directly ranks all positive and negative triples of a given query relationship .

- surface 2:NELL-995 and FB15K-237 The overall result of . “†” Indicates the result with question and answer settings ,“‡” Represents the result of direct sorting of all positive and negative triples of a given query relationship .
- From the table 2 As can be seen from the results shown in , Our framework is based on RL The method of has produced consistent improvements to varying degrees . One side , For the existing system based on RL Methods , They are FB15K-237 The result on is usually lower than NELL-995 The result on , because FB15K-237 More complicated , And it can be said that it is more difficult to manually design an appropriate reward function . However , Our framework alleviates this problem to a certain extent through dynamic learning of superior reward function , So we are facing the challenging FB15K-237 Made greater improvements . On the other hand , For different data sets , Our framework is right DeepPath The improvement of varies greatly , and MINERVA Otherwise . This is because MINERVA When calculating the cumulative discount reward, its super parameters will be manually adjusted , and DeepPath remain unchanged . obviously , It validates the existing RL It is necessary to adjust its reward function accordingly to adapt to different data sets . Enhanced through our framework , These are based on RL The method of no longer requires additional manual adjustment of different data sets , This shows great robustness .
- With the existing based on RL Is similar to , We also report the decomposition results of link prediction , And use MAP Assessment form 3 in NELL-995 Performance of each query relationship on . From the results , We can observe that the results of different relationships have high square differences , Enhanced based on RL Our method achieves better or comparable performance for all query relationships .
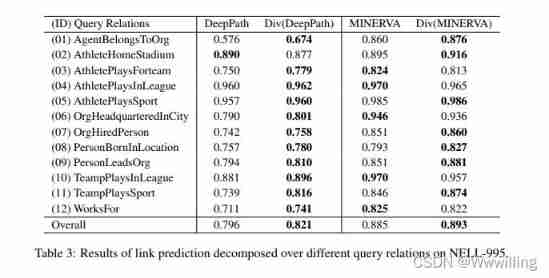
- surface 3:NELL-995 Link prediction results of different query relationship decomposition on .
Path based GAIL The effectiveness of the method
- In order to study path based GAIL The effectiveness of the method , We use path based GAIL Method and primitive GAIL Method in NELL-995 Training DeepPath Policy based agents in . especially , In the original GAIL Methods in the process of training agents , The presentation consists of status - Action track composition . For each state - The action is right ( s t , a t ) (s_t, a_t) (st,at), State means s t s_t st from ( e t , e t a i l − e t ) (e_t, e_{tail} - e_t) (et,etail−et) Calculation , among e t e_t et and e t a i l e_{tail} etail Represents the embedding of the current entity and the tail entity respectively . In the figure 2 in , We show a different set of evidence paths found by agents than demonstrated P n e w P_{new} Pnew Statistical information . In the table 4 in , We compared P n e w P_{new} Pnew The average number of paths and the reasoning performance of the two prediction tasks .

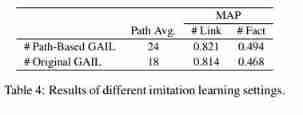
- Pictured 2 And table 4 Shown , We can observe that , Our path based GAIL Method obtains more evidence paths for most query relationships , And it has achieved better performance in link and fact prediction , This verifies our path based GAIL The effectiveness of the method and the rationality of encouraging agents to find more diverse evidence paths .
Melting research
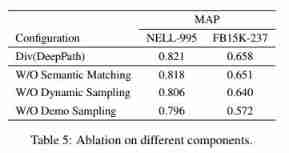
- We pass the will Deep Path Embedded into our framework for ablation research , To quantify the role of components . say concretely , We retrain our framework by ablating certain components :
- W/O Semantic Matching, No semantic matching on long tailed entities . contrary , We directly select the remaining demonstration candidates according to their frequency of occurrence CE Extract some paths from .
- W/O Dynamic Sampling, Do not perform dynamic demo sampling to combine with the local environment of the entity . in other words , We only use static demo sampling to get demos .
- W/O Demo Sampling, There is no use of demonstration for imitation learning , It is generated to DeepPath.
- We use MAP Assessment form 5 in NELL-995 and FB15K-237 Link prediction performance on . We can observe the results from :(1) Based on imitation learning , Our framework can effectively improve reasoning performance , Even if we use static demo sampling to get demos ;(2) High quality demonstrations are essential for imitation learning , This shows that both topology filtering and semantic matching play an important role in the demo sampler of our framework .
Conclusion
- In this paper , We propose a new plug and play framework DIVINE, For knowledge graph reasoning based on generative confrontation imitation learning , This makes the existing system based on RL The method can adaptively learn reasoning strategies and reward functions , To adapt to the real world KG The rapid evolution of . Experimental results show that , Our framework improves the existing framework based on RL The performance of the method , At the same time, it eliminates additional incentive projects .
边栏推荐
- EMQX 5.0 发布:单集群支持 1 亿 MQTT 连接的开源物联网消息服务器
- Keras' deep learning practice -- gender classification based on inception V3
- If time is a river
- Direct addition is more appropriate
- Anan's judgment
- VR/AR 的产业发展与技术实现
- 云原生应用开发之 gRPC 入门
- Mouse event - event object
- I don't know. The real interest rate of Huabai installment is so high
- nmap工具介绍及常用命令
猜你喜欢
JVM memory and garbage collection -4-string

文盘Rust -- 给程序加个日志

给刚入门或者准备转行网络工程师的朋友一些建议
#797div3 A---C

C语言-Cmake-CMakeLists.txt教程

Key points of data link layer and network layer protocol

MQTT X Newsletter 2022-06 | v1.8.0 发布,新增 MQTT CLI 和 MQTT WebSocket 工具

2022国内十大工业级三维视觉引导企业一览
Nmap tool introduction and common commands
Talk about the realization of authority control and transaction record function of SAP system
随机推荐
《通信软件开发与应用》课程结业报告
For friends who are not fat at all, nature tells you the reason: it is a genetic mutation
神经网络与深度学习-5- 感知机-PyTorch
If time is a river
Remote sensing contribution experience sharing
Redismission source code analysis
力争做到国内赛事应办尽办,国家体育总局明确安全有序恢复线下体育赛事
How to fix the slip ring
CV2 read video - and save image or video
leetcode 869. Reordered Power of 2 | 869. 重新排序得到 2 的幂(状态压缩)
leetcode 865. Smallest Subtree with all the Deepest Nodes | 865.具有所有最深节点的最小子树(树的BFS,parent反向索引map)
Why did MySQL query not go to the index? This article will give you a comprehensive analysis
MQTT X Newsletter 2022-06 | v1.8.0 发布,新增 MQTT CLI 和 MQTT WebSocket 工具
EMQX 5.0 发布:单集群支持 1 亿 MQTT 连接的开源物联网消息服务器
《ClickHouse原理解析与应用实践》读书笔记(7)
JVM memory and garbage collection-3-object instantiation and memory layout
Introduction à l'outil nmap et aux commandes communes
Nmap tool introduction and common commands
XMeter Newsletter 2022-06|企业版 v3.2.3 发布,错误日志与测试报告图表优化
数据链路层及网络层协议要点