当前位置:网站首页>Common MySQL interview questions (1) (written MySQL interview questions)
Common MySQL interview questions (1) (written MySQL interview questions)
2022-07-05 15:05:00 【Back end regular developers】
List of articles
- 1. Optimization you can think of MYSQL Database method
- 2. The application has a lot of data , Mainly for users , There are few update operations , Then the storage engine uses MyISAM Good or not InnoDB good , Why? ?
- 3. Write an infinite classification table structure , There is no limit to the number of tables ( Table field name and description are ok , No scripts are required )
- 4. surface user, Field USER_ ID,USER_ NAME,BIRTHDAY
- 5. One sheet adopted Innodb Of User surface , among id Primary key ,name For general index , Try to analyze the data structure of the index , The following two statements ( Both return a record ) What are the differences in the retrieval process ?
- 6. There is a statistical website for the needs of independent visitors , More than one million traffic , Such as IP For the identity , You can view the real-time of the day or specify a certain day IP Count ( Need to be heavy ), Only use MySQL To achieve , that :
- 7.mySql Execution order of
1. Optimization you can think of MYSQL Database method
- Avoid using select *, The query is specific to the field
- The design data sheet is reasonable , Reduce linked table queries
- Build a reasonable index
- Read write separation of database
- Use redis Cache to reduce the query pressure of the database
2. The application has a lot of data , Mainly for users , There are few update operations , Then the storage engine uses MyISAM Good or not InnoDB good , Why? ?
Use MyISAM, because MyISAM Has a higher insert 、 Query speed .
- Storage structure :MyISAM Store three files on disk . and InnoDB All tables are stored in the same data file , It's usually 2GB
- Transaction support :MyISAM No transaction support .InnoDB Provide transaction support transaction .
- Watch lock difference :MyISAM Only table level locks are supported .InnoDB Support transaction and row level locks .
- Full-text index :MyISAM Support FULLTEXT Full-text index of type ( Not applicable to Chinese , So want to use sphinx Full text indexing engine ).InnoDB I won't support it .
- The specific number of rows in the table :MyISAM Holds the total number of rows in a table , Inquire about count(*) Soon .InnoDB The total number of rows in a table is not saved , You have to recalculate .
3. Write an infinite classification table structure , There is no limit to the number of tables ( Table field name and description are ok , No scripts are required )
id、pid、name、orders、create_time、update_time
4. surface user, Field USER_ ID,USER_ NAME,BIRTHDAY
| USER_ID(int10) | USER_NAME(varchar100) | BIRTHDAY(varchar100) |
|---|---|---|
| 1 | Name01 | 10 September 1980 |
| 2 | Name01 | 1988-02-09 |
| 3 | Name03 | 1112564781 |
| 4 | Name04 | 2/3/1983 |
- Write sql The script takes out two pieces of data and presses USER_ID Reverse order
SELECT * FROM user ORDER BY user_id DESC LIMIT 2;
- Write sql The script can randomly fetch a piece of data
SELECT * FROM
userORDER BY RAND() LIMIT 1;SELECT * FROM user AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(user_id) FROM
user)-(SELECT MIN(user_id) FROM user))+(SELECT MIN(user_id) FROM user)) AS user_id) AS t2 WHERE t1.user_id >= t2. user_id ORDER BY t1. user_id LIMIT 1;SELECT * FROM user WHERE user_id >= ((SELECT MAX(user_id) FROM user)-(SELECT MIN(user_id) FROM user)) * RAND() + (SELECT MIN(user_id) FROM user) LIMIT 1
- Write sql The data extracted by the script USER_NAME Can't have the same name
SELECT DISTINCT user_name FROM `user`;
( Remove keywords distinct. Note that this keyword must be next to select keyword .)
- Write sql The data extracted by the script BIRTHDAY Greater than 1983-01-01
answer ( Incomplete ):
SELECT * FROM `user` WHERE (birthday LIKE '%-%-%' AND STR_TO_DATE(birthday, '%Y-%m-%d') > '1983-01-01') OR
(birthday LIKE '%/%/%' AND STR_TO_DATE(birthday, '%d/%m/%Y') > '1983-01-01');
5. One sheet adopted Innodb Of User surface , among id Primary key ,name For general index , Try to analyze the data structure of the index , The following two statements ( Both return a record ) What are the differences in the retrieval process ?
Sql 1: SELECT id, name, address FROM User WHERE name
"smith’
Sql 2: SELECT id, name, address FROM User WHERE id = 1;
sql2 Higher performance .
because name For general index , Secondary index , because Innodb The data of the secondary index in stores the value of the clustered index , Therefore, when using auxiliary index for query , When the data is found , You also need to use the primary key to query the clustered index again , Therefore, the index will be queried twice , and sql2 You only need to query once .
6. There is a statistical website for the needs of independent visitors , More than one million traffic , Such as IP For the identity , You can view the real-time of the day or specify a certain day IP Count ( Need to be heavy ), Only use MySQL To achieve , that :
- How do you design tables and indexes ?( written words 、sql All possible , The scheme is as efficient as possible )
IP Address translation to plastic storage , Sub table by date , With (IP, date ) As a joint index .
- How to store data , How to query the real-time data of that day and that day ?( Write sql sentence )
redis Queue cache -> MySQL Bulk warehousing
Inquiry day :
select count(distinct ip) as ip_num from log_{yyyymmdd} where TO_DAYS(add_time)=TO_DAYS(now());
Query a day :
select count(distinct ip) as ip_num from visit_log_{yyyymmdd} where TO_DAYS(add_time) = {yyyy-mm-dd};
7.mySql Execution order of
mysql perform sql The order is from From Start , The following is the sequence of execution
FROM table1 left join table2 on take table1 and table2 The data in produces the Cartesian product , Generate Temp1
JOIN table2 So first of all, make sure that the table , And then determine the correlation conditions
ON table1.column = table2.columu Determine the binding conditions of the table from Temp1 Generate intermediate tables Temp2
WHERE On the middle watch Temp2 The results are filtered Generate intermediate tables Temp3
GROUP BY On the middle watch Temp3 Grouping , Generate intermediate tables Temp4
HAVING Aggregate the grouped records Generate intermediate tables Temp5
SELECT On the middle watch Temp5 Do column filtering , Generate intermediate tables Temp6
DISTINCT On the middle watch Temp6 Deduplication , Generate intermediate tables Temp7
ORDER BY Yes Temp7 Sort data in , Generate intermediate tables Temp8
LIMIT On the middle watch Temp8 paging , Generate intermediate tables Temp9
边栏推荐
- Change multiple file names with one click
- Interpretation of Apache linkage parameters in computing middleware
- P6183 [USACO10MAR] The Rock Game S
- Reconnaissance des caractères easycr
- Super wow fast row, you are worth learning!
- Stop B makes short videos, learns Tiktok to die, learns YouTube to live?
- Coding devsecops helps financial enterprises run out of digital acceleration
- Your childhood happiness was contracted by it
- [recruitment position] Software Engineer (full stack) - public safety direction
- [12 classic written questions of array and advanced pointer] these questions meet all your illusions about array and pointer, come on!
猜你喜欢
Creation and use of thymeleaf template
![P6183 [USACO10MAR] The Rock Game S](/img/f4/d8c8763c27385d759d117b515fbf0f.png)
P6183 [USACO10MAR] The Rock Game S

Visual task scheduling & drag and drop | scalph data integration based on Apache seatunnel
![[JVM] operation instruction](/img/f5/85580495474ef58eafbb421338e93f.png)
[JVM] operation instruction

Crud of MySQL
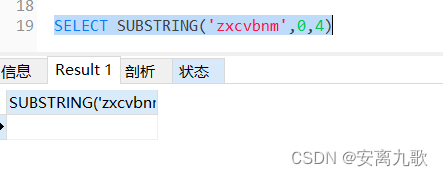
Mysql---- function

PyTorch二分类时BCELoss,CrossEntropyLoss,Sigmoid等的选择和使用
Huawei Hubble incarnation hard technology IPO harvester
FR练习题目---简单题

729. My schedule I: "simulation" & "line segment tree (dynamic open point) &" block + bit operation (bucket Division) "
随机推荐
Talking about how dataset and dataloader call when loading data__ getitem__ () function
PyTorch二分类时BCELoss,CrossEntropyLoss,Sigmoid等的选择和使用
Au - delà du PARM! La maîtrise de l'Université de Pékin propose diverse pour actualiser complètement le classement du raisonnement du NLP
"Sequelae" of the withdrawal of community group purchase from the city
Photoshop插件-动作相关概念-ActionList-ActionDescriptor-ActionList-动作执行加载调用删除-PS插件开发
漫画:优秀的程序员具备哪些属性?
Coding devsecops helps financial enterprises run out of digital acceleration
Where is the operation of convertible bond renewal? Is it safer and more reliable to open an account
Dark horse programmer - software testing -10 stage 2-linux and database -44-57 why learn database, description of database classification relational database, description of Navicat operation data, de
超级哇塞的快排,你值得学会!
sql server char nchar varchar和nvarchar的区别
Un week - end heureux
如何将电脑复制的内容粘贴进MobaXterm?如何复制粘贴
Select sort and bubble sort
Shanghai under layoffs
漫画:程序员不是修电脑的!
STM32+BH1750光敏传感器获取光照强度
浅谈Dataset和Dataloader在加载数据时如何调用到__getitem__()函数
Crud de MySQL
Brief introduction of machine learning framework