当前位置:网站首页>Interpretation of tiflash source code (IV) | design and implementation analysis of tiflash DDL module
Interpretation of tiflash source code (IV) | design and implementation analysis of tiflash DDL module
2022-07-05 14:03:00 【Tidb community dry goods portal】
The source of the original :https://tidb.net/blog/bf69e04e
author : @ Hong Jianyan TiFlash R & D Engineer
TiFlash yes TiDB The analysis engine of , yes TiDB HTAP The key components of form .TiFlash The source code reading series will introduce you from the source code level TiFlash Internal implementation . In the last issue of source code reading ( Please link to the previous issue ), We introduced TiFlash Storage engine for , This article will introduce TiFlash DDL Module related content , Include DDL Design idea of module , And the specific code implementation .
This article is based on the latest TiFlash v6.1.0 Design and source code analysis . Over time , Some design changes may occur in the new version , Make part of this article invalid , Please pay attention to the readers .TiFlash v6.1.0 The code can be found in TiFlash Of git repo Switch to v6.1.0 tag To view the .
Overview
This chapter , We'll start with DDL The module makes a overview Introduction to , Introduce DDL stay TiFlash Relevant scenarios in , as well as TiFlash in DDL The design idea of the whole module .
This way DDL Module refers to the corresponding responsible processing add column, drop column, drop table recover table Wait for this series DDL Module of statement , It is also responsible for communicating with databases and tables schema Module for dealing with information .
DDL Modules in TiFlash Relevant scenarios in
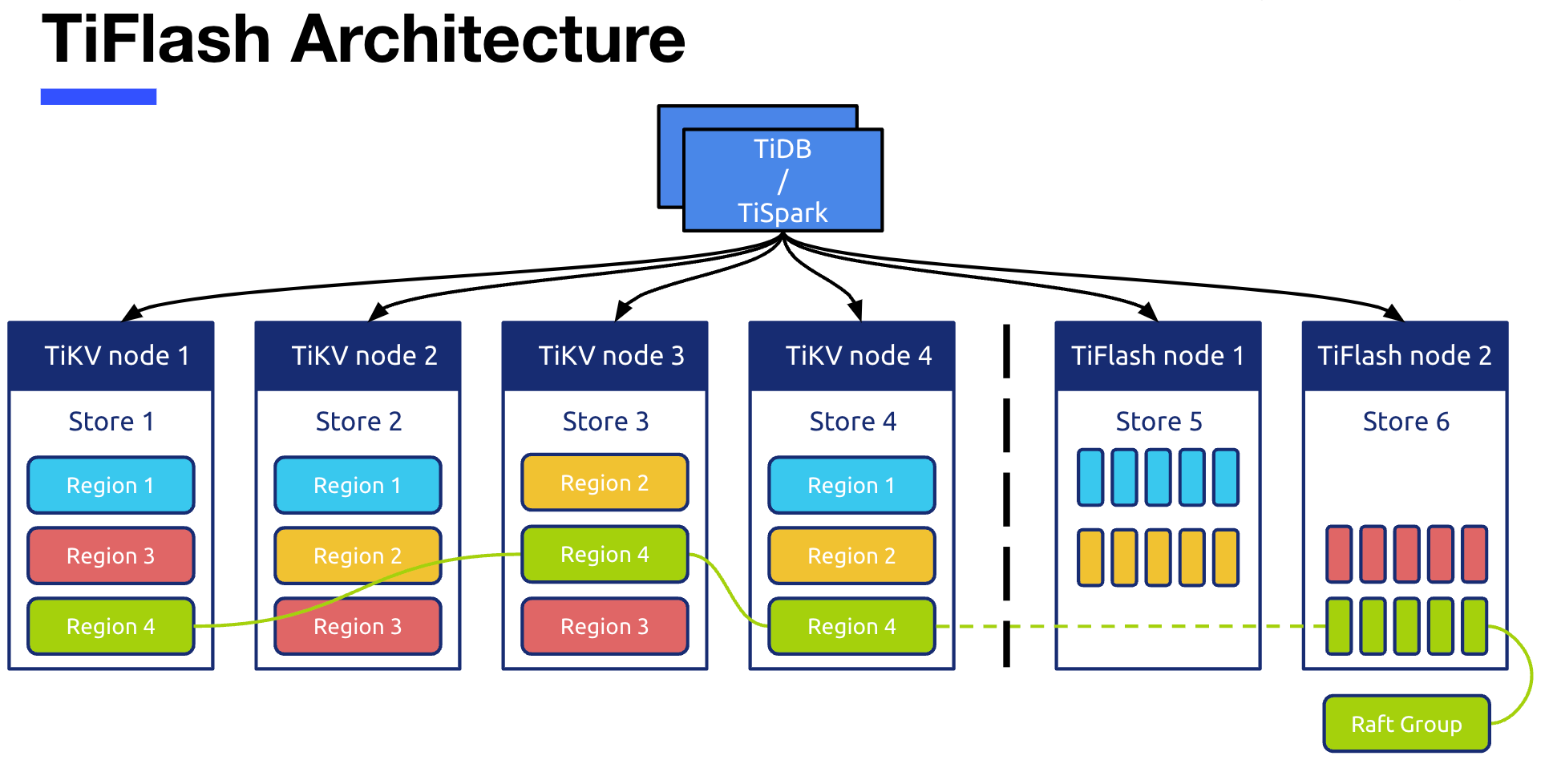
This is a picture TiFlash The architecture of , Above is TiDB/TiSpark Computing layer node , To the left of the dotted line are four TiKV The node of , There are two on the right TiFlash node . This picture shows TiFlash An important design concept : By using Raft The consensus algorithm ,TiFlash Will act as Raft Of Learner Nodes to join Raft group For asynchronous replication of data .Raft Group refer to TiKV More than one region Made up of copies raft leader as well as raft follower Composed of group. from TiKV Synchronize to TiFlash The data of , stay TiFlash It is also in accordance with region The division of , But internally, it will be saved to TiFlash In the columnar storage engine .
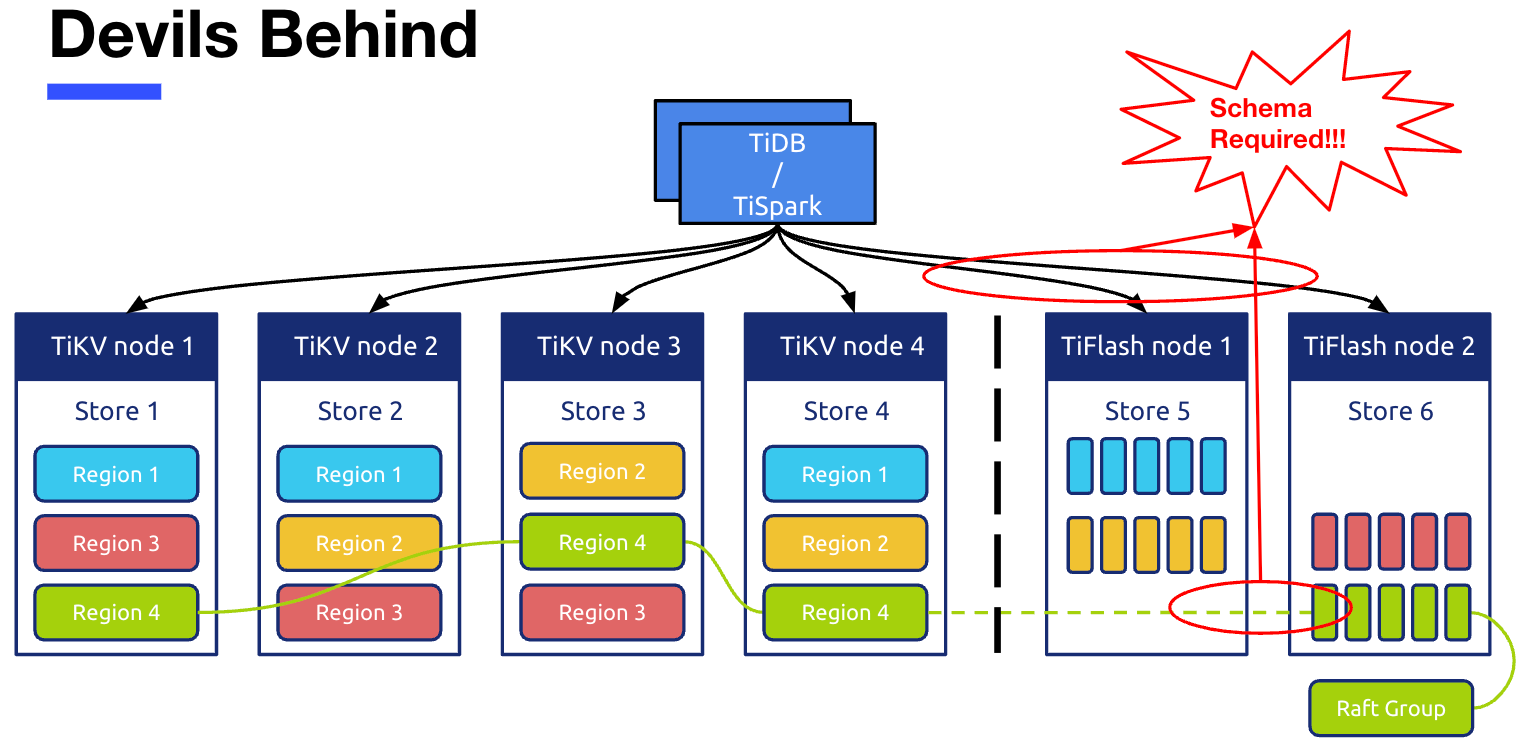
This picture is an overview of the architectural design , Covered up many details . The two red circles in the figure correspond to , Is the protagonist of this article Schema modular .
The red circle below is about TiFlash Write operations for .TiFlash The node is based on learner The role joined TiKV One by one region Corresponding raft group in , adopt raft leader Keep sending raft log perhaps raft snapshot Here it is learner Node synchronization data . But because TiKV The data in is in row storage format , And we TiFlash The data required in is in the format of column storage , therefore TiFlash The node is receiving TiKV After sending the data in row storage format , You need to convert it from row to column , Convert to the required column storage format . And this transformation , You need to rely on the corresponding table schema Information to complete . Again , The red circle above refers to TiDB/TiSpark Come on TiFlash The process of reading data in , The process of reading data also depends on schema To participate in the parsing . therefore ,TiFlash The read and write operations of all require strong dependencies schema Of ,schema stay TiFlash It also plays an important role .
DDL The overall design idea of the module
In specific understanding TiFlash schema Before the overall design idea of the module , So let's see schema Modules in TiDB and TiKV The corresponding situation in , because TiFlash The received schema The change information of is also from TiKV Sent by the node .
TiDB in DDL Basic information of the module
TiDB Of DDL Module is based on Google F1 Online asynchronous schema Change algorithm , In a distributed scenario , Unlocked and online schema change . Specific implementation can refer to TiDB Source reading series of articles ( seventeen )DDL The source code parsing | PingCAP.TiDB Of DDL The mechanism provides two main features :
DDL Operation will be avoided as much as possible data reorg(data reorg It refers to the addition, deletion and modification of data in the table ).
Here is add column In the example of , The original watch has a b Two columns and two rows of data . As we go add column This DDL In operation , We will not add new lines in the original two lines c Fill in the column with the default value . If there is a subsequent read operation, the data of these two lines will be read , We will give... In the result of reading c Fill in the column with the default value . In this way , Let's avoid DDL Occurs during operation data reorg. Such as add column, drop column, And integer type column expansion , There is no need to trigger data reorg Of .
But for those that are detrimental to the change DDL operation , We will inevitably happen data reorg. But in the case of damaging changes , We will not modify or rewrite the data on the original column of the table , Instead, add new columns , Convert on the new column , Finally, delete the original column , Rename the new column DDL operation . The contracted column in the figure below (modify column) In the case of , We have a, b Two , this DDL The operation requires a List from int Type reduction tiny int type . Whole DDL The operation process is :
First add a hidden column _col_a_0.
Put the original a The values in the column are converted and written to the hidden column _col_a_0 On .
After the conversion , Will be original a Column delete , And will _col_a_0 Rename the column to a Column .( The deletion mentioned here a Columns are not physically a The value of the column is deleted , By modification meta The way of information )

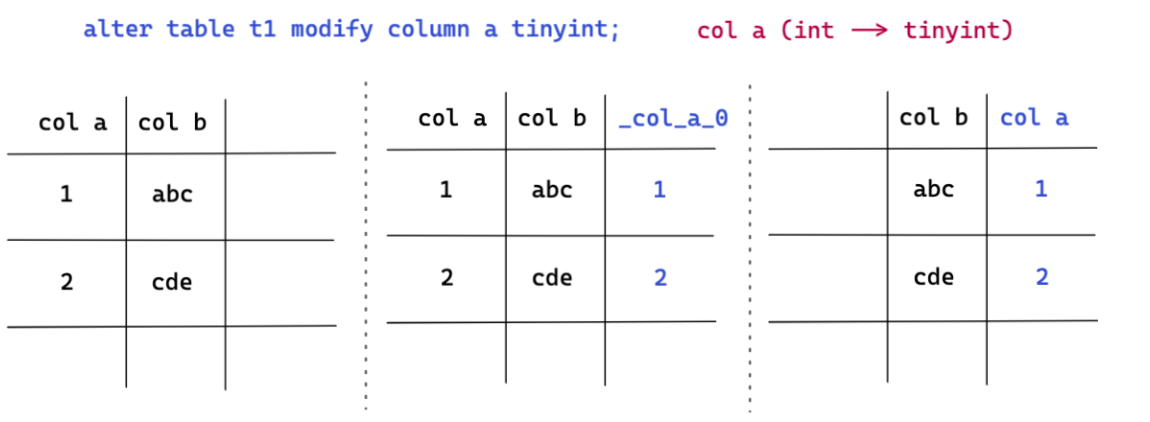
In addition, for the contraction DDL Operation itself , We require that data loss will not occur in the process of column reduction . For example, from int shrink into tinyint when , The value of the original column is required to be in tinyint Within the scope of , It does not support the occurrence of itself beyond tinyint The value of is converted to tinyint type . In the latter case , Will report an error directly overflow, Shrink column operation failed .
** Relative data update schema Old data can always be parsed .** This conclusion is also behind us TiFlash DDL An important guarantee of module dependency . This guarantee depends on the format of our row storage data . When saving data , We are will column id and column value Stored together , Instead of column name and column value Store together . In addition, our line storage format can be simplified as a column_id → data One of the map The way ( In fact, our bank deposit is not a map, It is stored in binary code , For details, please refer to Proposal: A new storage row format for efficient decoding).
- We can use the following figure as an example , To better understand this feature . On the left is a two column original table , adopt DDL operation , We deleted a Column , Added c Column , Convert to the right schema state . At this time , We need new schema Information to analyze the original old data , According to the new schema Each of the column id, We go to the old data to find each column id Corresponding value , among id_2 You can find the corresponding value , but id_3 No corresponding value was found , therefore , Just give it to id_3 Add the default value of this column . For multiple in the data id_1 Corresponding value , Choose to give up directly . In this way , We have correctly parsed the original data .

TiKV in DDL Basic information of the module
TiKV The storage layer of this line , There is no corresponding data table saved in the node schema The information of , because TiKV Its own reading and writing process does not need to rely on its own schema Information .
- TiKV The write operation itself does not need shcema , Because writing TiKV The data of is the data in the format of row storage that the upper layer has completed the conversion ( That is to say kv Medium v).
<!---->
about TiKV Read operation
- If the read operation only needs to put kv read out , You don't need to schema Information .
- If it is necessary to TiKV Medium coprocesser Deal with some TiDB Issue to TiKV When undertaking the downward calculation task ,TiKV Will need schema Information about . But this schema Information , Will be in TiDB The request sent contains , therefore TiKV It can be taken directly TiDB Of the requests sent schema Information to analyze data , And do some exception handling ( If the parsing fails ). therefore TiKV This kind of read operation does not need to be provided by itself schema Relevant information .
TiFlash in DDL Module design idea
TiFlash in DDL The design idea of the module mainly includes the following three points :
- TiFlash The node will save its own schema copy. Part of it is because TiFlash Yes schema With strong dependence , need schema To help parse the data of row to column conversion and the data to be read . On the other hand, because TiFlash Is based on Clickhouse Realized , So many designs are also in Clickhouse Evolved from the original design ,Clickhouse In its own design, it keeps a schema copy.
<!---->
- about TiFlash Saved on the node schema copy, We chose to go through On a regular basis from TiKV Pull the latest schema( The essence is to get TiDB The latest in schema Information ) To update , Because it is constantly updated schema It's very expensive , So we choose to update regularly .
<!---->
- Read and write operations , Meeting Depend on schema copy To parse . If... On the node schema copy Not meet the current needs of reading and writing , We're going to Pull the latest schema Information , To guarantee schema Newer than the data , In this way, it can be correctly and successfully parsed ( This is what I mentioned earlier TiDB DDL The guarantee provided by the mechanism ). Specific reading and writing are right schema copy The needs of , I will introduce it to you in detail in the later part .
DDL Core Process
In this chapter , We will introduce TiFlash DDL The core workflow of the module .
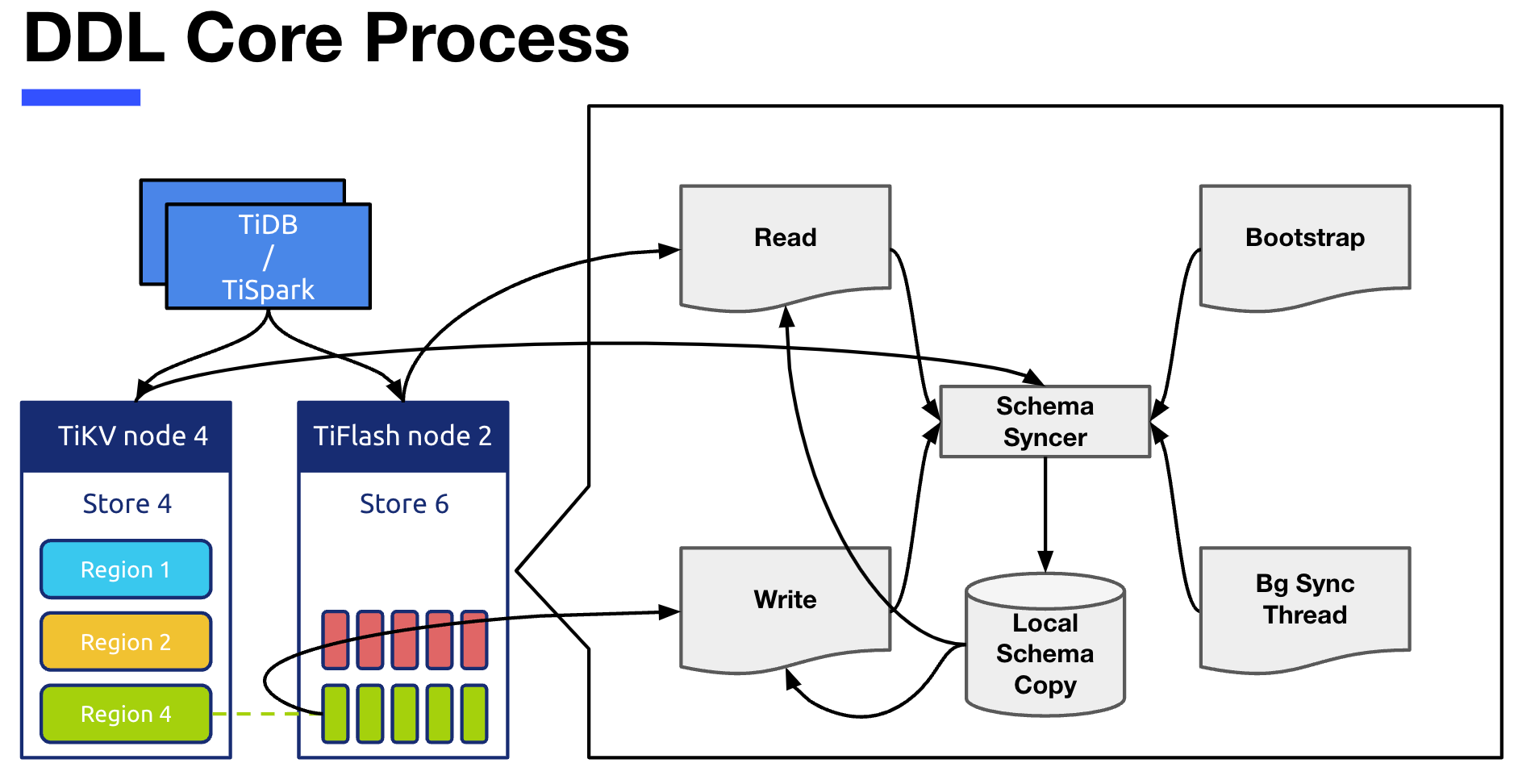
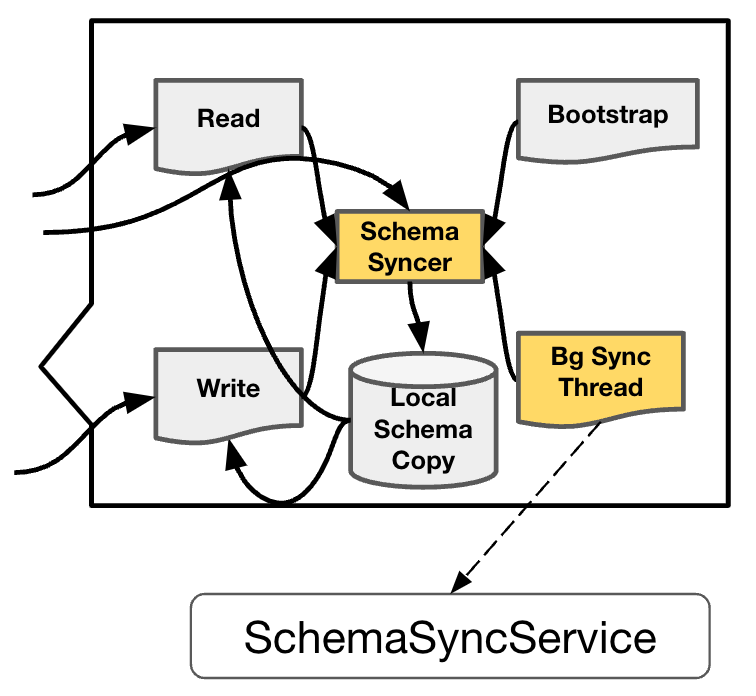
This picture , On the left is a thumbnail display of each node , Zoom in on the right TiFlash Middle heel DDL Related core processes , Respectively :
- Local Schema Copy It refers to the storage on our node schema copy Information about .
<!---->
- Schema Syncer The module is responsible for TiKV Pull Abreast of the times Schema Information , Update based on this Local Schema Copy.
<!---->
- Bootstrap refer to TiFlash Server When it starts , Will be called directly once Schema Syncer, Get all the present schema Information .
<!---->
- Background Sync Thread It is responsible for calling regularly Schema Syncer To update Local Schema Copy modular .
<!---->
- Read and Write The two modules are TiFlash Read and write operations in , Read and write operations will depend on Local Schema Copy, It will also be called when necessary Schema Syncer updated .
Now let's look at how each part is implemented one by one .
Local Schema Copy
TiFlash in schema The most important information is the information related to each data table . stay TiFlash In the storage tier of , Every physical table , There will be one StorageDeltaMerge Instance object of , There are two variables in this object , Is responsible for storing and schema Of relevant information .
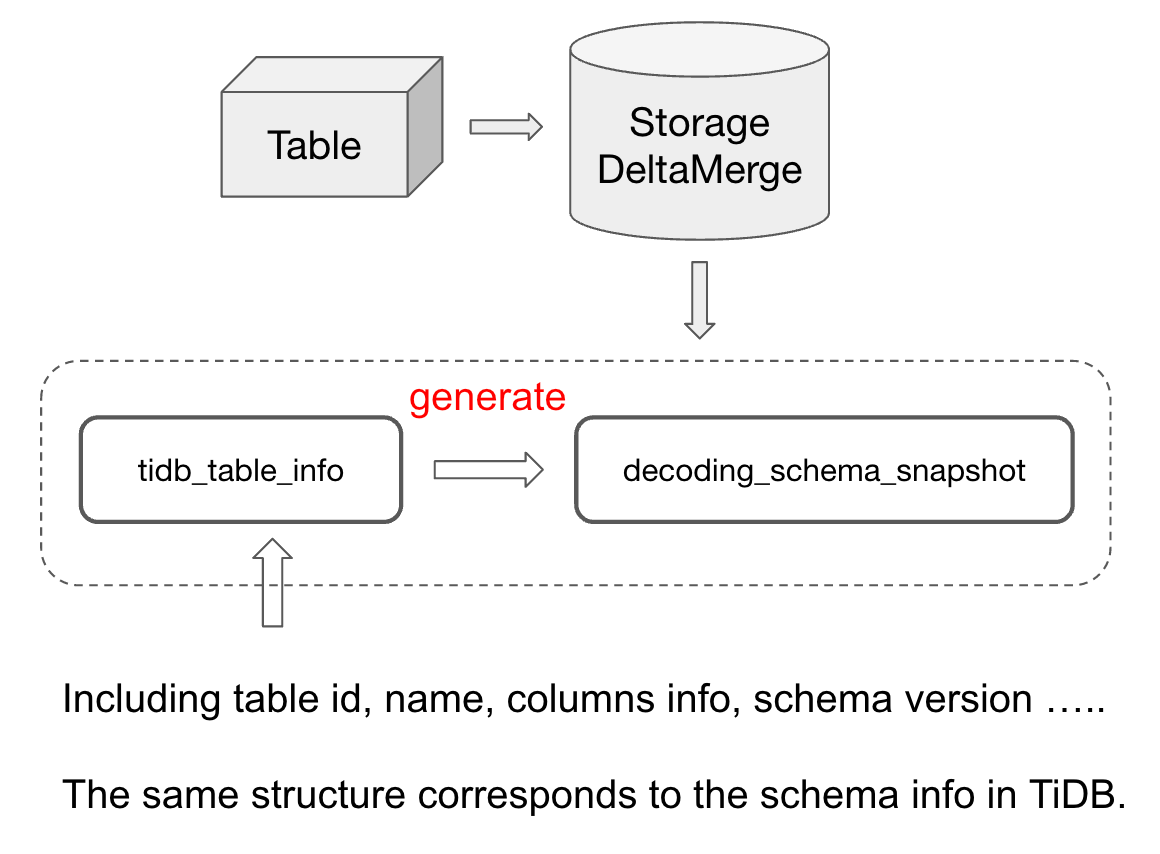
tidb_table_infoThis variable stores table All kinds of schema Information , Include table id,table name,columns infos,schema version wait . alsotidb_table_infoThe storage structure of is similar to TiDB / TiKV Storage in table schema The structure of is completely consistent .
<!---->
decoding_schema_snapshotIt is based ontidb_table_infoas well asStorageDeltaMergeSome of the information in Generate An object of .decoding_schema_snapshotIt is proposed to optimize the performance of row column conversion in the writing process . Because we are doing row to column conversion , If you rely ontidb_table_infoGet the corresponding schema Information , You need to do a series of conversion operations to adapt . in consideration of schema It will not be updated frequently , in order to Avoid repeating these operations every time row to column parsing , We will usedecoding_schema_snapshotThis variable is used to save the converted results , And it depends ondecoding_schema_snapshotTo parse .
Schema Syncer
Schema Syncer This module is made up of TiDBSchemaSyncer This class is responsible for . It passes through RPC Go to TiKV Get the latest schema Updates for . For the acquired schema diffs, Will find every schema diff Corresponding table, stay table Corresponding StorageDeltaMerge Object to update schema Information and related content of the corresponding storage layer .
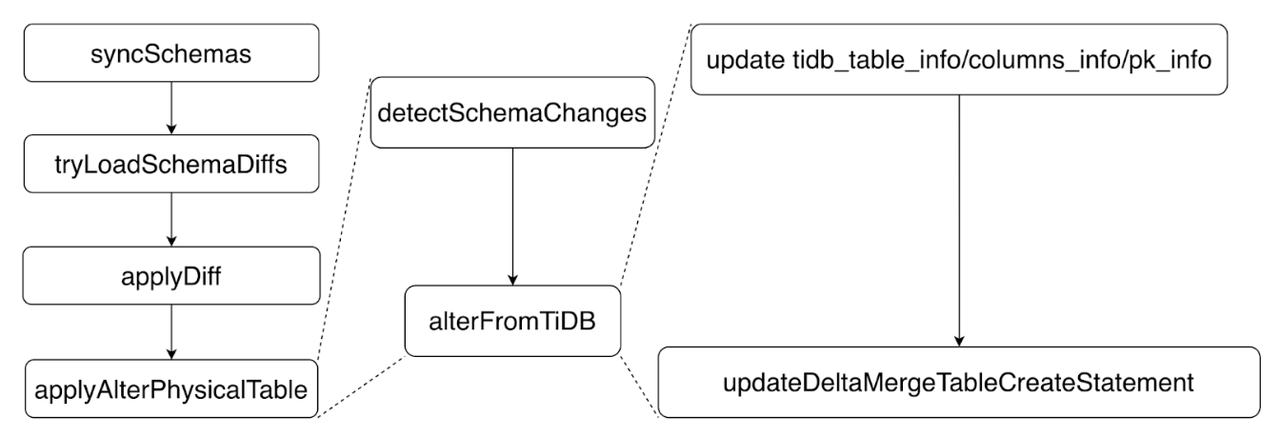
The whole process is through TiDBSchemaSyncer Function of syncSchema To achieve , For the specific process, please refer to this brief flow chart :
- adopt
tryLoadSchemaDiffs, From TiKV Get this round of new schema Change information .
<!---->
- Then traverse all diffs One by one
applyDiff.
<!---->
- For each diff, We will find his corresponding table, Conduct
applyAlterPhysicalTable.
<!---->
- In the Middle East: , We will detect To this round of updates , Everything related to this table schema change , And then call
StorageDeltaMerge::alterFromTiDBCome to the table correspondingStorageDeltaMergeObject changes .
<!---->
- Specific changes , We'll modify
tidb_table_info, dependent columns And primary key information .
<!---->
- In addition, we will update the table creation statement of this table , Because the table itself has changed , Therefore, his statement of creating tables also needs to be changed accordingly , Do this later recover Wait for the operation to work correctly .
Throughout syncSchema In the process of , We will not update decoding_schema_snapshot Of .decoding_schema_snapshot It's using Lazy update The way , Only when the specific data is about to be written , Need to call to decoding_schema_snapshot , It will check whether it is the latest schema Corresponding state , If not , According to the latest tidb_table_info Relevant information to update . In this way , We can reduce many unnecessary conversions . For example, if a table happens frequently schema change, But I didn't do any writing , Then you can avoid tidb_table_info To decoding_schema_snapshot Many calculation conversion operations between .
For the surrounding calls involved Schema Syncer Module ,Read,Write,BootStrap These three modules are all direct calls TiDBSchemaSyncer::syncSchema. and Background Sync Thread It is through SchemaSyncService To be responsible for , stay TiFlash Server The initial stage of startup , hold syncSchema This function is inserted into background thread pool Go inside , Keep about every 10s Call once , To achieve regular updates .
Schema on Data Write
So let's see , The writing process itself needs to deal with the situation . We have a row of data to write , It is necessary to parse each column , Write to the inventory engine . In addition, we have local schema copy To help resolve . however , The data to be written in this line is the same as ours schema copy The order of time is uncertain . Because our data is through raft log / raft snapshot Sent in the form of , It's an asynchronous process .schema copy It is updated regularly , It can also be regarded as an asynchronous process , So the corresponding schema Version and The data written in this line stay TiDB We don't know the sequence of events in . Write operation is to be in such a scenario , Correctly parse the data for writing .
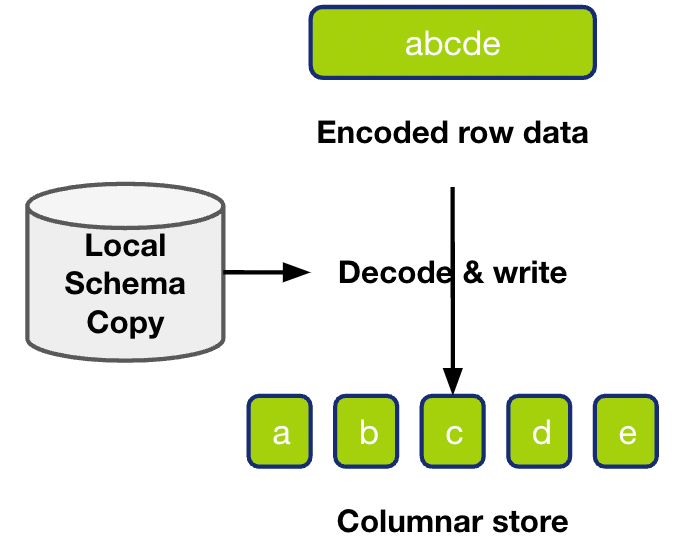
For such a scene , There will be a very direct processing idea : We can do row to column parsing before , Pull the latest one first schema, So as to ensure our schema It must be newer than the data to be written , This must be a successful parsing . But on the one hand schema Not frequently changed , In addition, every time you write, you have to pull schema It's a huge expense , So the final choice of our writing operation is , Let's use the existing schema copy To parse this line of data , If the parsing succeeds, it ends , Parsing failed , Let's get the latest schema To re parse .
When doing the first round of analysis , In addition to the correct parsing completion , We may also encounter the following three situations :
Case one Unknown Column, That is, the ratio of data to be written schema There's an extra column e. There are two possibilities for this to happen .

- The first possibility , As shown in the small figure on the left , The data to be written is larger than schema new . stay TiDB Time line , First, a new column is added e, Then insert (a,b,c,d,e) This line of data . But the inserted data arrived first TiFlash ,add column e Of schema The change hasn't arrived yet TiFlash Side , So there is data ratio schema One more column .
- The second possibility , As shown in the small figure on the right , The data to be written is larger than schema used . stay TiDB Time line , Insert this line of data first (a,b,c,d,e), then drop column e. however drop column e Of schema Changes arrive first TiFlash Side , The inserted data arrives , There will also be data ratio schema One more column .
- under these circumstances , We also have no way to judge which of the above situations , There is no common way to deal with , Therefore, only parsing failure can be returned , To trigger the pull of the latest schema Carry out the second round of analysis .
<!---->
The second case Missing Column, That is, the ratio of data to be written schema A column is missing e. Again , There are also two possibilities .

- The first possibility , As shown in the small figure on the left , The data to be written is larger than schema new . stay TiDB Time line , First drop column e, Then insert the data (a,b,c,d).
- The second possibility , As shown in the small figure on the right , The data to be written is larger than schema used . stay TiDB Time line , First insert the data (a,b,c,d), Then insert e Column .
- Similarly, we have no way to judge what kind of situation it belongs to at this time , Follow the previous practice , We should still return to pull again after parsing failure . But in this case , If more e Column It has a default value or supports filling NULL Of , We can give it directly to e Fill in the column with the default value or NULL To return the successful parsing . Let's look at two possibilities , We fill in the default value or NULL What kind of impact will it have .
- In the first possible case , Because we have drop 了 column e, So all subsequent read operations will not read column e The operation of , So actually, it's for e Enter any value , Will not affect the correctness . For the second possible case , In itself (a,b,c,d) This line of data is missing e The value of the , You need to fill in this line of data when reading e The default value of perhaps NULL Of , So in this case , I directly give this line of data first column e Fill in the default value or NULL, It can also work normally . So in these two cases , We give e Fill in the default value or NULL Can work correctly , So we don't need to return parsing failure . But if there is more e Columns do not support filling in default values or NULL, Then it can only return parsing failure , To trigger the pull of the latest schema Carry out the second round of analysis .
<!---->
The third case Overflow Column, That is, there is a column of data to be written that is larger than our schema The data range of this column in .
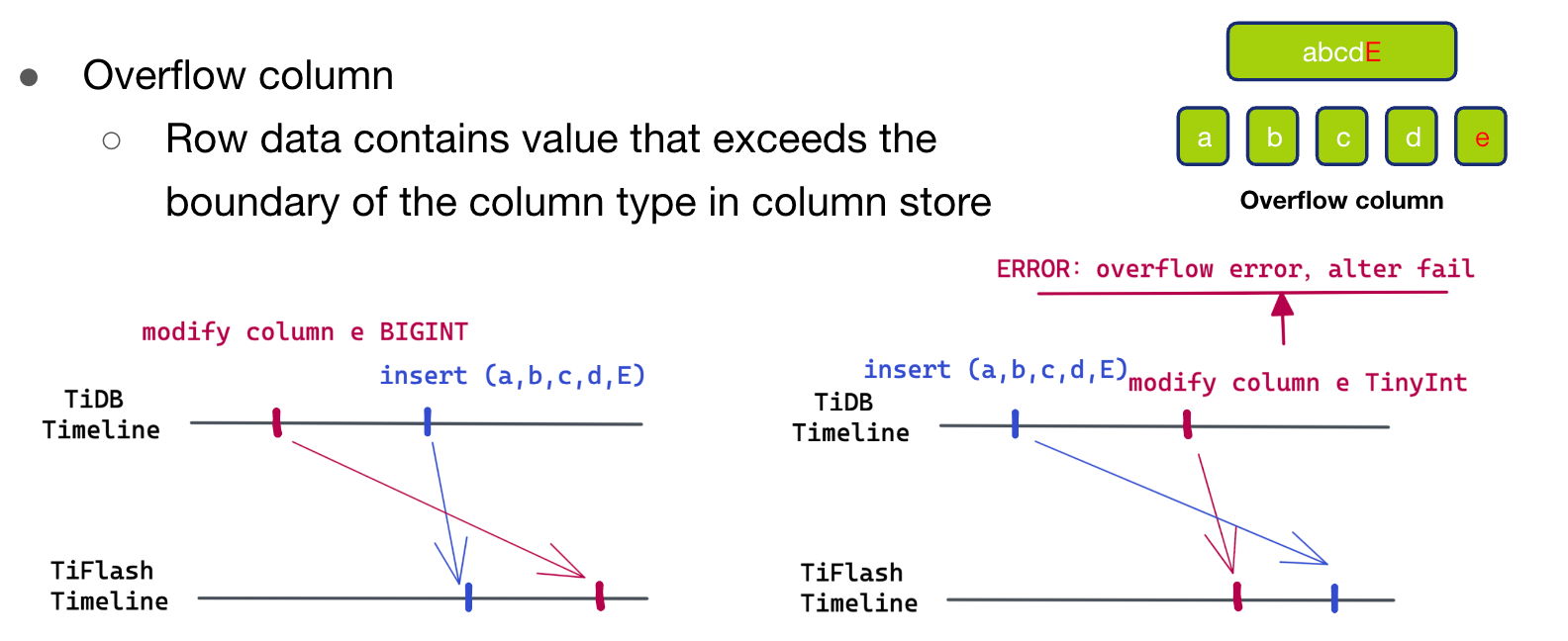
- In this case , Only the picture on the left , That is, expand the column first , Then insert new data , But data precedes schema Arrived at the TiFlash. We can take a look at the figure on the right to understand why it is impossible to insert data first and then trigger column shrinking . If we insert data first (a,b,c,d,E), Then on e The column is shrunk , take e List from int Type reduction tinyint type . And because of the inserted E More than the tinyint The scope of the , So this DDL The operation will report overflow Wrong , operation failed , Therefore, it cannot lead to overflow column This kind of phenomenon .
- So there comes overflow Scene , It can only be the case on our left . But because schema change It has not arrived yet TiFlash, We don't know the specific data range of the new column , So there is no way to put this overflow Value E write in TiFlash Storage engine , So we can only return parsing failure , To trigger the pull of the latest schema Carry out the second round of analysis .
After understanding the three exceptions you may encounter when parsing for the first time , Let's take another look at the first parsing failure , Pull the latest again schema in the future , What will happen in the second round of analysis . alike , In addition to the normal completion of parsing in the second round , We may also encounter the above three situations , But the difference is , In the second round of parsing , Can guarantee our schema It is newer than the data to be written .

- Case one Unknown Column. because schema Than The data to be written is new , So we can be sure that it is because after this line of data , It happened again drop column e The operation of , But this schema change Arrived first TiFlash Side , So it led to Unknown Column Scene . So we just need to put e The column data can be deleted directly .
<!---->
- The second case Missing Column. This situation is due to the add column e Caused by the operation of , Therefore, we can directly fill in the default values for the extra columns .
<!---->
- The third case Overflow Column. Because at present our schema It is newer than the data to be written , So again overflow column The situation of , Something unusual must have happened , So we throw an exception directly .
The above is the overall idea of the data writing process , If you want to know the specific code details , You can search for writeRegionDataToStorage This function . In addition, our row column conversion process depends on RegionBlockReader This class to achieve , This class depends on schema Information is what we mentioned earlier decoding_schema_snapshot. In the process of row column conversion ,RegionBlockReader Take it decoding_schema_snapshot I will check it first decoding_schema_snapshot Whether it is the latest tidb_table_info Versions are aligned , If not aligned , It will trigger decoding_schema_snapshot Update , For specific logic, please refer to getSchemaSnapshotAndBlockForDecoding This function .
Schema on Data Read
What is different from writing is , Before starting the internal reading process , We need to check first schema version. Among the requests sent by our upper layer , There will be schema version Information (Query_Version). The read request verification needs to meet the following requirements: , The table to be read is local schema Information and read request schema version The corresponding information is consistent .
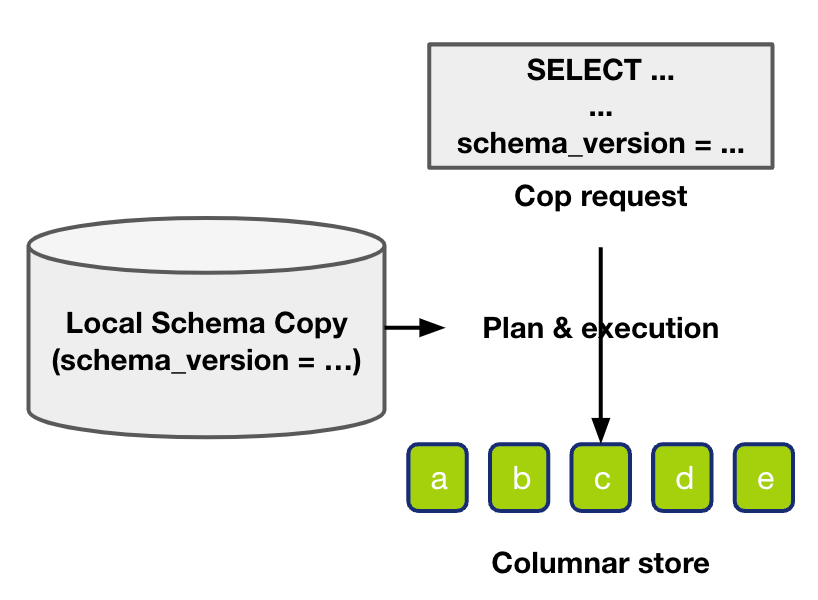
TiFlash Be responsible for pulling schema Of TiDBSchemaSyncer Will record the whole schema version, We call it Local_Version. Therefore, the requirement of read operation is Query_Version = Local_Version. If Query_Version Greater than Local_Version, We will think that local schema The version is behind , So trigger sync schema , Pull the latest schema, Check again . If Query_Version Less than Local_Version, We would think query Of schema Version is too old , Therefore, the read request will be rejected , Let the upper node update schema version Then resend the request .
In this setting , If we have a table that happens very often DDL operation , So his schema version Will be constantly updated . Therefore, if you need to read this table at this time , It is easy to see that the read operation has been Query_Version > Local_Version and Query_Version < Local_Version Alternating back and forth between the two states . For example, reading the request at the beginning schema version Bigger , Trigger TiFlash sync schema, to update local schema copy. Updated local schema version It's newer than reading requests , Therefore, the read request is rejected . Read request update schema version after , We also found that reading requests schema version Than Local schema copy Updated , Go round and begin again .... In this case , We haven't done any special treatment at present . We will think that this situation is very, very rare , Or it won't happen , So if such a special situation happens unfortunately , That can only wait for them to reach a balance , Start reading operation smoothly .
We mentioned the requirements of reading operation Query_Version and Local_Version Completely equal , Therefore, inequality is very easy to occur , As a result, many queries are re initiated or re pulled schema The situation of . In order to reduce the number of such cases , We made a small optimization .
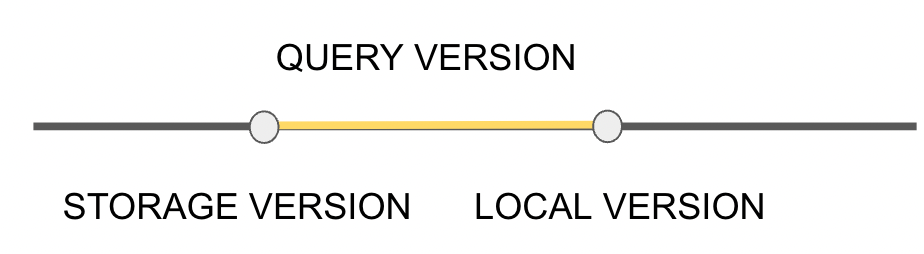
We have nothing but TiFlash As a whole schema version Outside , Each watch also has its own schema version, We call it Storage_Version, And our Storage_Version Always less than or equal to Local_Version Of , Because only in the latest schema When changing , Indeed, this table has been modified ,Storage_Version Will be exactly equal to Local_Version, In other cases ,Storage_Version All are less than Local_Version Of . So in [Storage_Version, Local_Version] In this interval , Of our table schema The information has not changed . That is to say Query_Version As long as [Storage_Version, Local_Version] In this range , Read the form requested by the request schema Information and our current schema The version is exactly the same . So we can put Query_Version < Local_Version This limitation is relaxed to Query_Version < Storage_Version. stay Query_Version < Storage_Version when , You need to update the read request schema Information .
After the verification , The module responsible for reading is based on our corresponding table tidb_table_info To build stream To read .Schema Related processes , We can do it in InterpreterSelectQuery.cpp Of getAndLockStorageWithSchemaVersion as well as DAGStorageInterpreter.cpp Of getAndLockStorages For further understanding . InterpreterSelectQuery.cpp and DAGStorageInterpreter.cpp It's all about being responsible. Right TiFlash Read the table , The former is responsible for clickhouse client The process read under connection , The latter is TiDB The process read in the branch .
Special Case
Finally, let's take an example , Let's see Drop Table and Recover Table Relevant information .
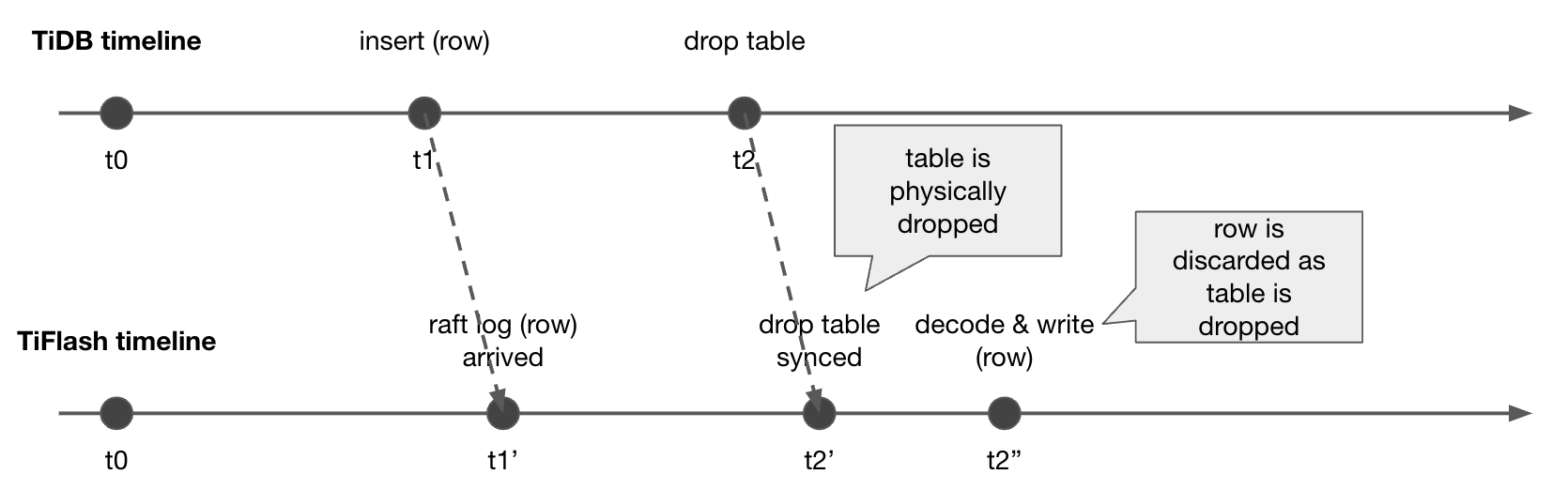
The line above is TiDB Timeline of , The line below is TiFlash Timeline of . stay t1 When ,TiDB the insert The operation of , And then in t2 It's time to do it again drop table The operation of .t1' When ,TiFlash received insert This operation is raft log, But the parsing and writing steps have not yet been carried out , And then in t2' When ,TiFlash Synced to drop column This article schema DDL operation , the schema Update . wait until t2'' When ,TiFlash Start Parse the newly inserted data , But at this time, because the corresponding table has been deleted , So we will throw away this data . So far, there are no problems .
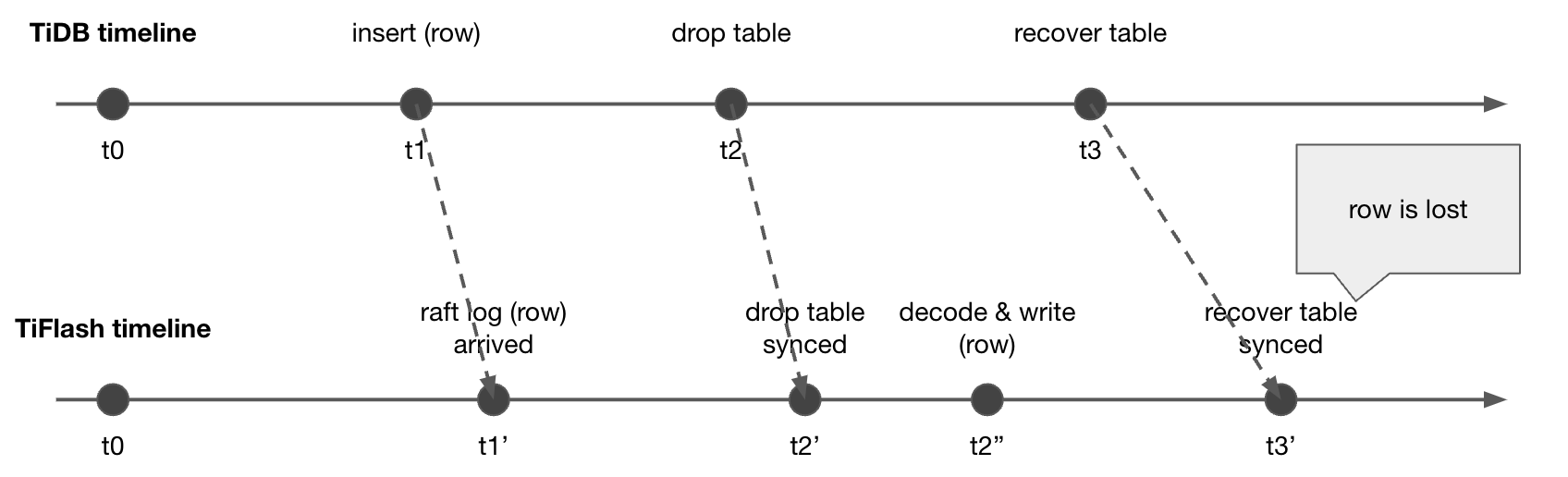
But if t3 At that time, we went on recover The operation of , Restore this table , The last one inserted row The data is lost . Data loss is an unacceptable result . therefore TiFlash about drop table This kind of DDL, This table will be set tombstone, The specific physical recovery is postponed gc It happens again during operation . about drop table There are still write operations on the latter table , We will continue to parse and write , Do this later recover When , We will not lose data .
Summary
This article mainly introduces TiFlash in DDL Module design idea , Specific implementation and core related processes . More code reading content will be gradually expanded in later chapters , Coming soon .
边栏推荐
- Scientific running robot pancakeswap clip robot latest detailed tutorial
- Require, require in PHP_ once、include、include_ Detailed explanation of the efficiency of repeated introduction of once class library
- OSI and tcp/ip protocol cluster
- SAS接口有什么优势特点
- uplad_ Labs first three levels
- laravel-dompdf导出pdf,中文乱码问题解决
- LeetCode_3(无重复字符的最长子串)
- matlab学习2022.7.4
- 国富氢能冲刺科创板:拟募资20亿 应收账款3.6亿超营收
- :: ffff:192.168.31.101 what address is it?
猜你喜欢
Jetpack Compose入门到精通
TiFlash 源码解读(四) | TiFlash DDL 模块设计及实现分析
为什么我认识的机械工程师都抱怨工资低?
Oneconnect listed in Hong Kong: with a market value of HK $6.3 billion, ye Wangchun said that he was honest and trustworthy, and long-term success

SAS接口有什么优势特点

Anchor navigation demo

TDengine 社区问题双周精选 | 第三期
![[cloud resources] what software is good for cloud resource security management? Why?](/img/c2/85d6b4a956afc99c2dc195a1ac3938.png)
[cloud resources] what software is good for cloud resource security management? Why?
TiFlash 面向编译器的自动向量化加速

清大科越冲刺科创板:年营收2亿 拟募资7.5亿
随机推荐
Routing in laravel framework
Elk enterprise log analysis system
Wechat app payment callback processing method PHP logging method, notes. 2020/5/26
Convolutional Neural Networks简述
Detailed explanation of IP address and preparation of DOS basic commands and batch processing
:: ffff:192.168.31.101 what address is it?
2022年机修钳工(高级)考试题模拟考试题库模拟考试平台操作
搭建一个仪式感点满的网站,并内网穿透发布到公网 2/2
3W原则[通俗易懂]
Requset + BS4 crawling shell listings
Kotlin collaboration uses coroutinecontext to implement the retry logic after a network request fails
The forked VM terminated without saying properly goodbye
Zibll theme external chain redirection go page beautification tutorial
关于memset赋值的探讨
Attack and defense world web WP
Oneconnect listed in Hong Kong: with a market value of HK $6.3 billion, ye Wangchun said that he was honest and trustworthy, and long-term success
Zhizhen new energy rushes to the scientific innovation board: the annual revenue is 220million, and SAIC venture capital is the shareholder
Laravel generate entity
Laravel - view (new and output views)
Laravel - model (new model and use model)