当前位置:网站首页>Spark: calculate the average value of the same key in different partitions (entry level - simple implementation)
Spark: calculate the average value of the same key in different partitions (entry level - simple implementation)
2022-07-27 03:24:00 【One's cow】
Calculate the same in different partitions key Average value .
aggregateByKey Realization 、combineByKey Realization .
aggregateByKey
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Operator_Transform_aggregateByKey {
def main(args: Array[String]): Unit = {
//TODO Create an environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//TODO RDD operator ——key-value——aggregateByKey
// Calculate the same in different partitions key Average value
val rdd = sc.makeRDD(List(
("A", 1), ("B", 2), ("C", 3), ("D", 4), ("A", 5), ("B", 6), ("C", 7), ("A", 8)
), 2)
val newRDD = rdd.aggregateByKey((0, 0))(
(t, v) => {
(t._1 + v, t._2 + 1)
},
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val RDD1 = newRDD.mapValues {
case (num, c) => {
num / c
}
}
RDD1.collect().foreach(println)
//TODO Shut down the environment
sc.stop()
}
}
combineByKey
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Operator_Transform_combineByKey {
def main(args: Array[String]): Unit = {
//TODO Create an environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//TODO RDD operator ——key-value——combineByKey
// Calculate the same in different partitions key Average value
val rdd = sc.makeRDD(List(
("A", 1), ("B", 2), ("C", 3), ("D", 4), ("A", 5), ("B", 6), ("C", 7), ("A", 8)
), 2)
// first : Will be the same key The first data structure transformation
// the second : Calculation rules within a partition
// Third : Calculation rules between partitions
val newRDD = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val RDD1 = newRDD.mapValues {
case (num, c) => {
num / c
}
}
RDD1.collect().foreach(println)
//TODO Shut down the environment
sc.stop()
}
}
边栏推荐
- 周全的照护 解析LYRIQ锐歌电池安全设计
- Technology vane | interpretation of cloud native technology architecture maturity model
- opiodr aborting process unknown ospid (21745) as a result of ORA-609
- Functions that should be selected for URL encoding and decoding
- 数据库使用安全策略
- Fastboot刷机
- Post responsibilities of safety officer and environmental protection officer
- Message rejected MQ
- Worthington果胶酶的特性及测定方案
- redis秒杀案例,跟着b站尚硅谷老师学习
猜你喜欢

Deep learning vocabulary embedded, beam search

$128million! IQM, a Finnish quantum computing company, was supported by the world fund

阶乘末尾0的数量
太强了,一个注解搞定接口返回数据脱敏

spark学习笔记(四)——sparkcore核心编程-RDD

安全员及环保员岗位职责

Hcip day 14 notes
消息被拒MQ

Practice of online problem feedback module (XV): realize the function of online updating feedback status
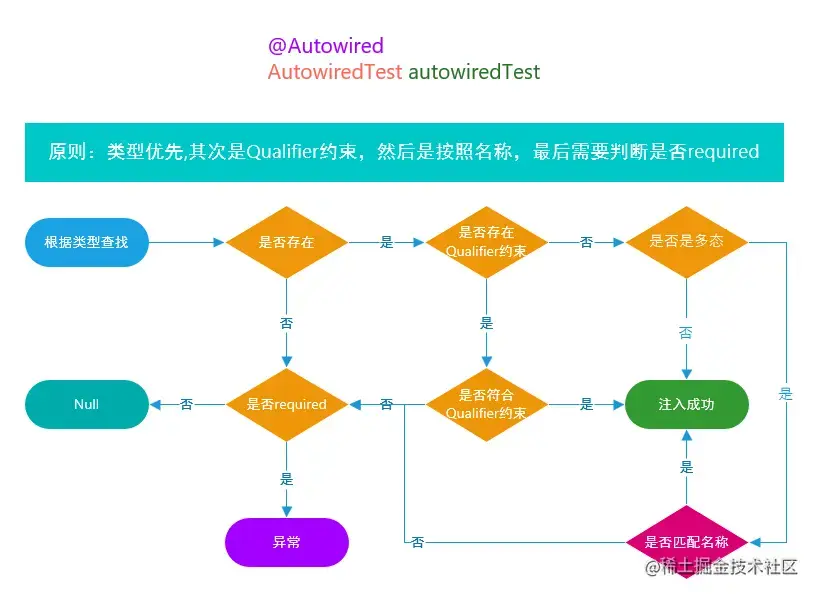
Annotation summary of differences between @autowired and @resource
随机推荐
Worthington过氧化物酶活性的6种测定方法
impala 执行计划详解
$128million! IQM, a Finnish quantum computing company, was supported by the world fund
docker 创建mysql 8.x容器,支持mac ,arm架构芯片
Call jshaman's Web API interface to realize JS code encryption.
Yilingsi T35 FPGA drives LVDS display screen
Deep learning vocabulary embedded, beam search
Source code analysis of warning notification for skywalking series learning
Acwing 2074. Countdown simulation
HCIP第十四天笔记
Explain
[learning notes, dog learning C] string + memory function
[flask] the server obtains the request header information of the client
数据湖(二十):Flink兼容Iceberg目前不足和Iceberg与Hudi对比
Common events of window objects
Attention should be paid to the first parameter of setTimeout
基于.NetCore开发博客项目 StarBlog - (16) 一些新功能 (监控/统计/配置/初始化)
字节一面:TCP 和 UDP 可以使用同一个端口吗?
Worthington果胶酶的特性及测定方案
Single case mode (double check lock)