当前位置:网站首页>CUDA与Direct3D 一致性
CUDA与Direct3D 一致性
2022-07-02 06:12:00 【扫地的小何尚】
CUDA与Direct3D 一致性
Direct3D 9Ex、Direct3D 10 和 Direct3D 11 支持 Direct3D 互操作性。
CUDA 上下文只能与满足以下条件的 Direct3D 设备互操作: Direct3D 9Ex 设备必须使用设置为 D3DDEVTYPE_HAL 的 DeviceType 和使用 D3DCREATE_HARDWARE_VERTEXPROCESSING 标志的 BehaviorFlags 创建; Direct3D 10 和 Direct3D 11 设备必须在 DriverType 设置为 D3D_DRIVER_TYPE_HARDWARE 的情况下创建。
可以映射到 CUDA 地址空间的 Direct3D 资源是 Direct3D 缓冲区、纹理和表面。 这些资源使用 cudaGraphicsD3D9RegisterResource()、cudaGraphicsD3D10RegisterResource() 和 cudaGraphicsD3D11RegisterResource() 注册。
以下代码示例使用内核动态修改存储在顶点缓冲区对象中的 2D width x height网格。
Direct3D 9 Version:
IDirect3D9* D3D;
IDirect3DDevice9* device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
IDirect3DVertexBuffer9* positionsVB;
struct cudaGraphicsResource* positionsVB_CUDA;
int main()
{
int dev;
// Initialize Direct3D
D3D = Direct3DCreate9Ex(D3D_SDK_VERSION);
// Get a CUDA-enabled adapter
unsigned int adapter = 0;
for (; adapter < g_pD3D->GetAdapterCount(); adapter++) {
D3DADAPTER_IDENTIFIER9 adapterId;
g_pD3D->GetAdapterIdentifier(adapter, 0, &adapterId);
if (cudaD3D9GetDevice(&dev, adapterId.DeviceName)
== cudaSuccess)
break;
}
// Create device
...
D3D->CreateDeviceEx(adapter, D3DDEVTYPE_HAL, hWnd,
D3DCREATE_HARDWARE_VERTEXPROCESSING,
¶ms, NULL, &device);
// Use the same device
cudaSetDevice(dev);
// Create vertex buffer and register it with CUDA
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
device->CreateVertexBuffer(size, 0, D3DFVF_CUSTOMVERTEX,
D3DPOOL_DEFAULT, &positionsVB, 0);
cudaGraphicsD3D9RegisterResource(&positionsVB_CUDA,
positionsVB,
cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA,
cudaGraphicsMapFlagsWriteDiscard);
// Launch rendering loop
while (...) {
...
Render();
...
}
...
}
void Render()
{
// Map vertex buffer for writing from CUDA
float4* positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions,
&num_bytes,
positionsVB_CUDA));
// Execute kernel
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<<dimGrid, dimBlock>>>(positions, time,
width, height);
// Unmap vertex buffer
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// Draw and present
...
}
void releaseVB()
{
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4* positions, float time,
unsigned int width, unsigned int height)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate uv coordinates
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// Calculate simple sine wave pattern
float freq = 4.0f;
float w = sinf(u * freq + time)
* cosf(v * freq + time) * 0.5f;
// Write positions
positions[y * width + x] =
make_float4(u, w, v, __int_as_float(0xff00ff00));
}
Direct3D 10 Version
ID3D10Device* device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
ID3D10Buffer* positionsVB;
struct cudaGraphicsResource* positionsVB_CUDA;
int main()
{
int dev;
// Get a CUDA-enabled adapter
IDXGIFactory* factory;
CreateDXGIFactory(__uuidof(IDXGIFactory), (void**)&factory);
IDXGIAdapter* adapter = 0;
for (unsigned int i = 0; !adapter; ++i) {
if (FAILED(factory->EnumAdapters(i, &adapter))
break;
if (cudaD3D10GetDevice(&dev, adapter) == cudaSuccess)
break;
adapter->Release();
}
factory->Release();
// Create swap chain and device
...
D3D10CreateDeviceAndSwapChain(adapter,
D3D10_DRIVER_TYPE_HARDWARE, 0,
D3D10_CREATE_DEVICE_DEBUG,
D3D10_SDK_VERSION,
&swapChainDesc, &swapChain,
&device);
adapter->Release();
// Use the same device
cudaSetDevice(dev);
// Create vertex buffer and register it with CUDA
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
D3D10_BUFFER_DESC bufferDesc;
bufferDesc.Usage = D3D10_USAGE_DEFAULT;
bufferDesc.ByteWidth = size;
bufferDesc.BindFlags = D3D10_BIND_VERTEX_BUFFER;
bufferDesc.CPUAccessFlags = 0;
bufferDesc.MiscFlags = 0;
device->CreateBuffer(&bufferDesc, 0, &positionsVB);
cudaGraphicsD3D10RegisterResource(&positionsVB_CUDA,
positionsVB,
cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA,
cudaGraphicsMapFlagsWriteDiscard);
// Launch rendering loop
while (...) {
...
Render();
...
}
...
}
void Render()
{
// Map vertex buffer for writing from CUDA
float4* positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions,
&num_bytes,
positionsVB_CUDA));
// Execute kernel
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<<dimGrid, dimBlock>>>(positions, time,
width, height);
// Unmap vertex buffer
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// Draw and present
...
}
void releaseVB()
{
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4* positions, float time,
unsigned int width, unsigned int height)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate uv coordinates
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// Calculate simple sine wave pattern
float freq = 4.0f;
float w = sinf(u * freq + time)
* cosf(v * freq + time) * 0.5f;
// Write positions
positions[y * width + x] =
make_float4(u, w, v, __int_as_float(0xff00ff00));
}
Direct3D 11 Version
ID3D11Device* device;
struct CUSTOMVERTEX {
FLOAT x, y, z;
DWORD color;
};
ID3D11Buffer* positionsVB;
struct cudaGraphicsResource* positionsVB_CUDA;
int main()
{
int dev;
// Get a CUDA-enabled adapter
IDXGIFactory* factory;
CreateDXGIFactory(__uuidof(IDXGIFactory), (void**)&factory);
IDXGIAdapter* adapter = 0;
for (unsigned int i = 0; !adapter; ++i) {
if (FAILED(factory->EnumAdapters(i, &adapter))
break;
if (cudaD3D11GetDevice(&dev, adapter) == cudaSuccess)
break;
adapter->Release();
}
factory->Release();
// Create swap chain and device
...
sFnPtr_D3D11CreateDeviceAndSwapChain(adapter,
D3D11_DRIVER_TYPE_HARDWARE,
0,
D3D11_CREATE_DEVICE_DEBUG,
featureLevels, 3,
D3D11_SDK_VERSION,
&swapChainDesc, &swapChain,
&device,
&featureLevel,
&deviceContext);
adapter->Release();
// Use the same device
cudaSetDevice(dev);
// Create vertex buffer and register it with CUDA
unsigned int size = width * height * sizeof(CUSTOMVERTEX);
D3D11_BUFFER_DESC bufferDesc;
bufferDesc.Usage = D3D11_USAGE_DEFAULT;
bufferDesc.ByteWidth = size;
bufferDesc.BindFlags = D3D11_BIND_VERTEX_BUFFER;
bufferDesc.CPUAccessFlags = 0;
bufferDesc.MiscFlags = 0;
device->CreateBuffer(&bufferDesc, 0, &positionsVB);
cudaGraphicsD3D11RegisterResource(&positionsVB_CUDA,
positionsVB,
cudaGraphicsRegisterFlagsNone);
cudaGraphicsResourceSetMapFlags(positionsVB_CUDA,
cudaGraphicsMapFlagsWriteDiscard);
// Launch rendering loop
while (...) {
...
Render();
...
}
...
}
void Render()
{
// Map vertex buffer for writing from CUDA
float4* positions;
cudaGraphicsMapResources(1, &positionsVB_CUDA, 0);
size_t num_bytes;
cudaGraphicsResourceGetMappedPointer((void**)&positions,
&num_bytes,
positionsVB_CUDA));
// Execute kernel
dim3 dimBlock(16, 16, 1);
dim3 dimGrid(width / dimBlock.x, height / dimBlock.y, 1);
createVertices<<<dimGrid, dimBlock>>>(positions, time,
width, height);
// Unmap vertex buffer
cudaGraphicsUnmapResources(1, &positionsVB_CUDA, 0);
// Draw and present
...
}
void releaseVB()
{
cudaGraphicsUnregisterResource(positionsVB_CUDA);
positionsVB->Release();
}
__global__ void createVertices(float4* positions, float time,
unsigned int width, unsigned int height)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate uv coordinates
float u = x / (float)width;
float v = y / (float)height;
u = u * 2.0f - 1.0f;
v = v * 2.0f - 1.0f;
// Calculate simple sine wave pattern
float freq = 4.0f;
float w = sinf(u * freq + time)
* cosf(v * freq + time) * 0.5f;
// Write positions
positions[y * width + x] =
make_float4(u, w, v, __int_as_float(0xff00ff00));
}
SLI一致性
在具有多个 GPU 的系统中,所有支持 CUDA 的 GPU 都可以通过 CUDA 驱动程序和运行时作为单独的设备进行访问。然而,当系统处于 SLI 模式时,有如下所述的特殊注意事项。
首先,在一个 GPU 上的一个 CUDA 设备中的分配将消耗其他 GPU 上的内存,这些 GPU 是 Direct3D 或 OpenGL 设备的 SLI 配置的一部分。因此,分配可能会比预期的更早失败。
其次,应用程序应该创建多个 CUDA 上下文,一个用于 SLI 配置中的每个 GPU。虽然这不是严格要求,但它避免了设备之间不必要的数据传输。应用程序可以将 cudaD3D[9|10|11]GetDevices() 用于 Direct3D 和 cudaGLGetDevices() 用于 OpenGL 调用,以识别当前执行渲染的设备的 CUDA 设备句柄和下一帧。鉴于此信息,应用程序通常会选择适当的设备并将 Direct3D 或 OpenGL 资源映射到由 cudaD3D[9|10|11]GetDevices() 或当 deviceList 参数设置为 cudaD3D[9|10 |11]DeviceListCurrentFrame 或 cudaGLDeviceListCurrentFrame。
请注意,从 cudaGraphicsD9D[9|10|11]RegisterResource 和 cudaGraphicsGLRegister[Buffer|Image] 返回的资源只能在发生注册的设备上使用。因此,在 SLI 配置中,当在不同的 CUDA 设备上计算不同帧的数据时,有必要分别为每个设备注册资源。
有关 CUDA 运行时如何分别与 Direct3D 和 OpenGL 互操作的详细信息,请参阅 Direct3D 互操作性和 OpenGL 互操作性。
边栏推荐
- 【程序员的自我修养]—找工作反思篇二
- Contest3147 - game 38 of 2021 Freshmen's personal training match_ 1: Maximum palindromes
- 浅谈三点建议为所有已经毕业和终将毕业的同学
- sudo提权
- 锐捷EBGP 配置案例
- 栈(线性结构)
- LeetCode 83. Delete duplicate elements in the sorting linked list
- Generic classes and parameterized classes of SystemVerilog
- 数据回放伴侣Rviz+plotjuggler
- LeetCode 39. 组合总和
猜你喜欢

Problems encountered in uni app development (continuous update)

Detailed explanation of BGP message
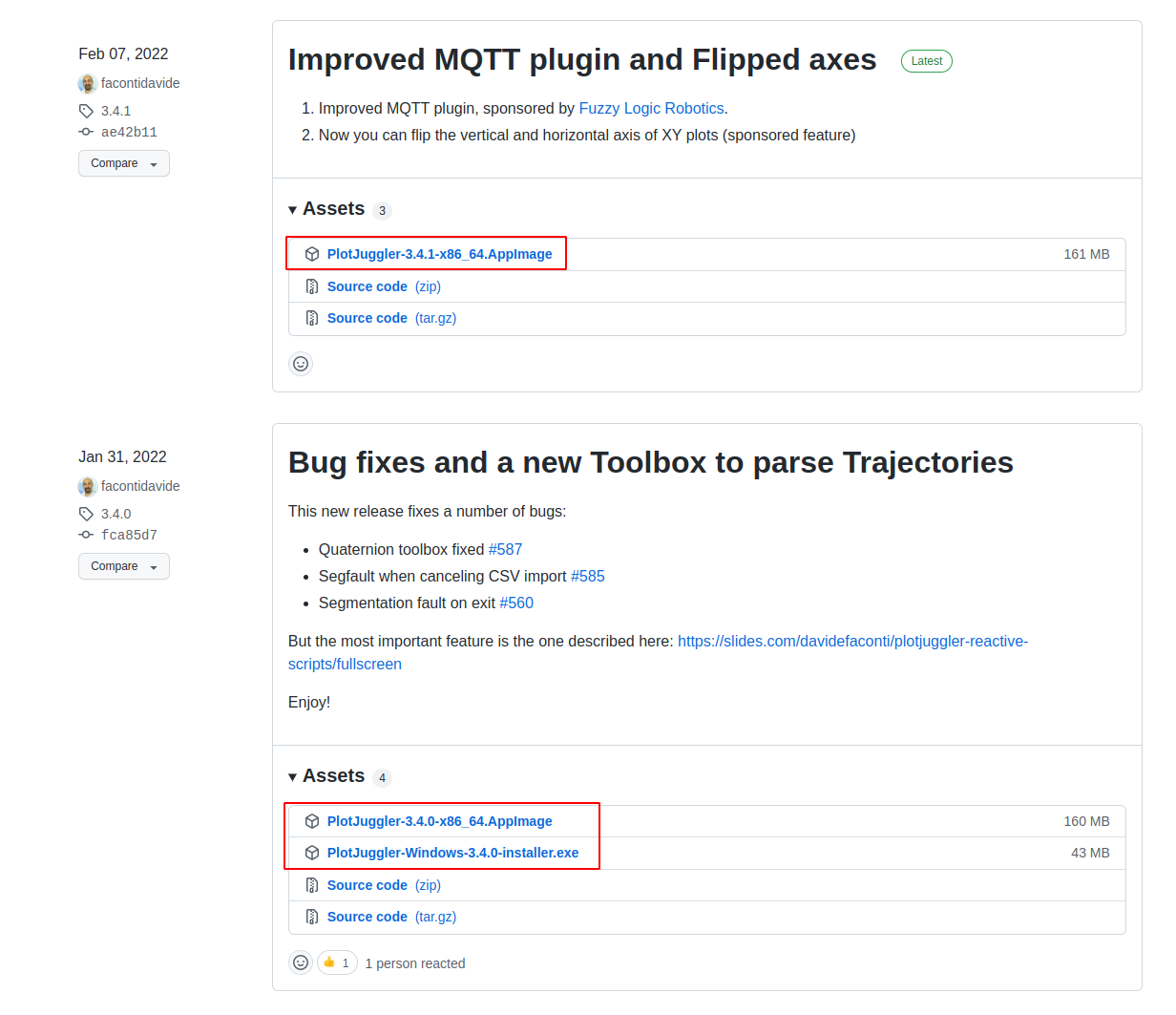
数据回放伴侣Rviz+plotjuggler
来自读者们的 I/O 观后感|有奖征集获奖名单

Amazon AWS data Lake Work Pit 1
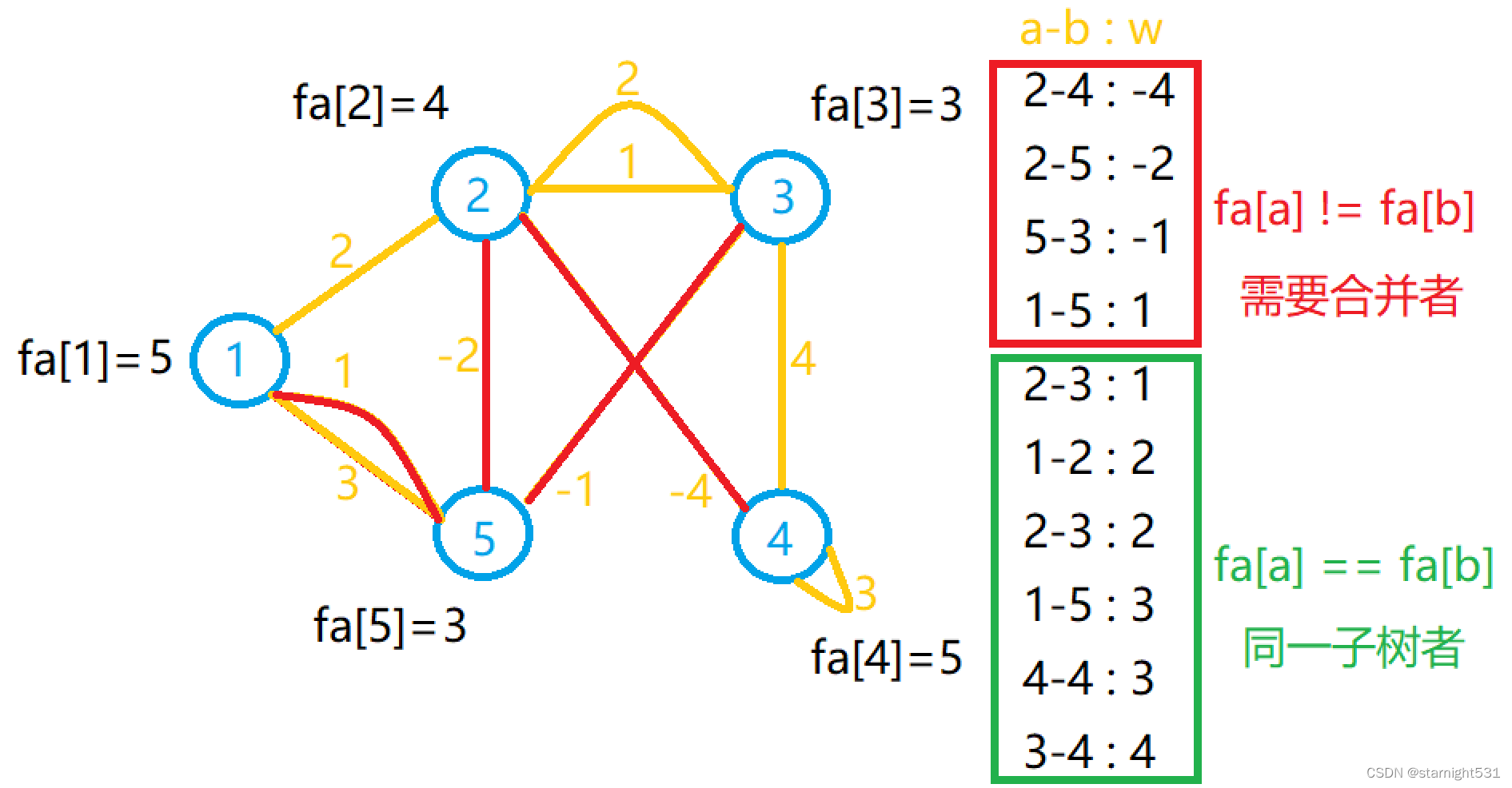
Shenji Bailian 3.53-kruskal

队列(线性结构)

Shenji Bailian 3.54-dichotomy of dyeing judgment
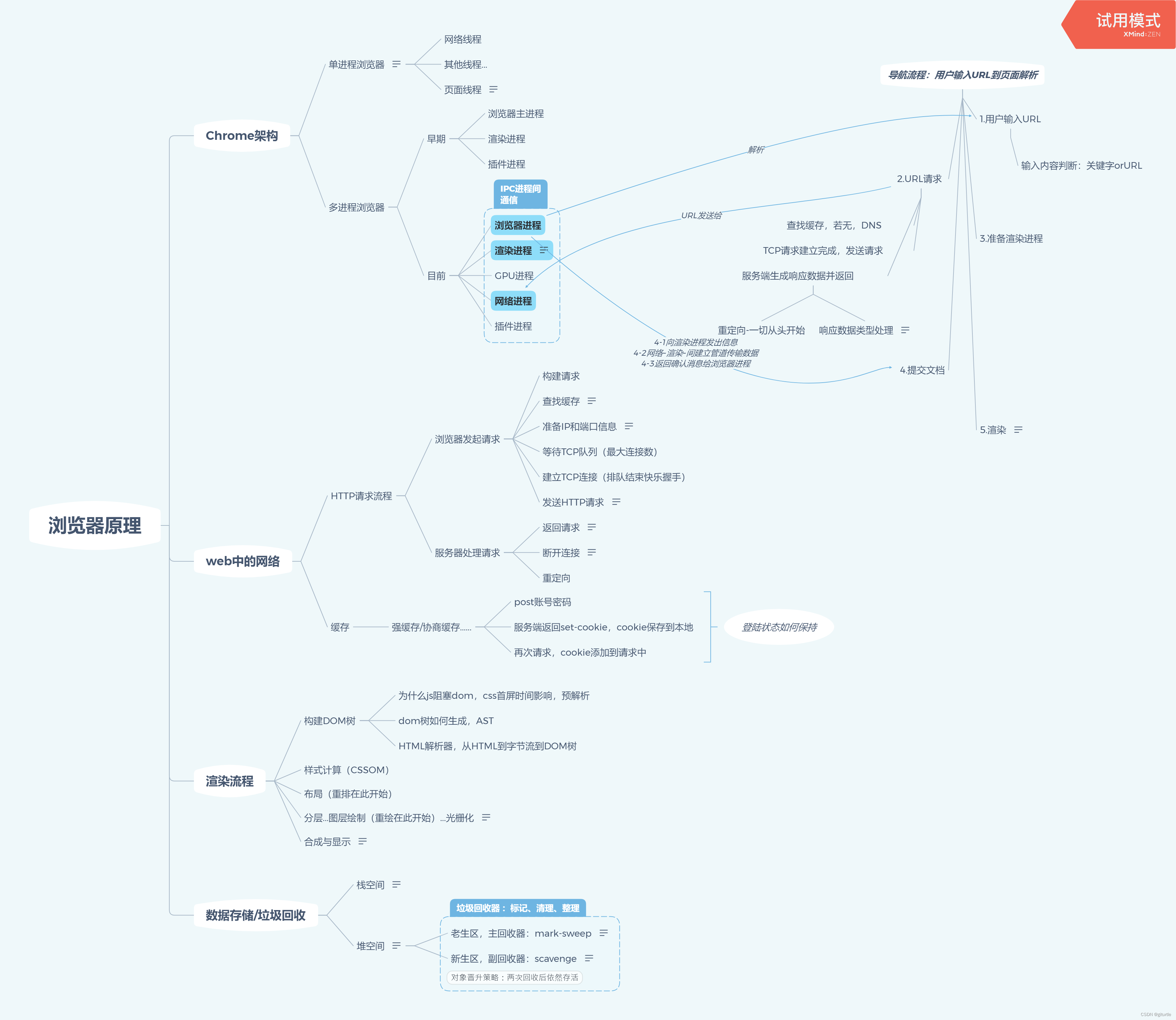
浏览器原理思维导图

Let every developer use machine learning technology
随机推荐
深入学习JVM底层(三):垃圾回收器与内存分配策略
MySQL的10大经典错误
Classic literature reading -- deformable Detr
LeetCode 77. combination
浅谈三点建议为所有已经毕业和终将毕业的同学
LeetCode 90. Subset II
Web components series (VIII) -- custom component style settings
It is said that Kwai will pay for the Tiktok super fast version of the video? How can you miss this opportunity to collect wool?
网络相关知识(硬件工程师)
栈(线性结构)
I/o multiplexing & event driven yyds dry inventory
Use of Arduino wire Library
Top 10 classic MySQL errors
Talking about MySQL database
Scheme and implementation of automatic renewal of token expiration
Reading classic literature -- Suma++
LeetCode 83. 删除排序链表中的重复元素
LeetCode 27. Removing Elements
Arduino Wire 库使用
MySQL的10大經典錯誤