In high concurrency 、 Asynchronous and other scenarios , The use of thread pool can be said to be everywhere . Thread pools are essentially , That is to exchange space for time , Because the creation and destruction of threads will consume resources and time , For scenarios where threads are heavily used , Using pooling management can delay thread destruction , Greatly improve the reusability of single thread , Further improve overall performance .
There is a typical online problem today , It's just about thread pools , There are also deadlocks involved 、jstack Use of commands 、JDK Different thread pools suitable for scenarios and other knowledge points , At the same time, the whole investigation idea can be used for reference , I would like to record and share .
01 Business background description
The online problem occurs in the core fee deduction service of the advertising system , First of all, a brief account of the general business process , Easy to understand the problem .

The green box part is the position of the fee deduction service in the advertising recall fee deduction process , Simple understanding : When a user clicks on an ad , From C The client initiates a real-time fee deduction request (CPC, Click deduction mode ), The fee deduction service undertakes the core business logic of the action : Including the implementation of anti cheating strategies 、 Create a deduction record 、click Log burying point, etc .
02 Problem phenomenon and business impact
12 month 2 No. In the evening 11 P.m. , We received an online alert notification : The thread pool task queue size of the fee deduction service far exceeds the set threshold , And the queue size continues to grow over time . The detailed alarm contents are as follows :

Corresponding , Our advertising indicators : clicks 、 There has also been a very obvious decline in income , Almost at the same time, the service alarm notification is sent out . among , The curve corresponding to the number of hits is shown as follows :

The failure of this line occurs at the peak of traffic , It lasted for nearly 30 It took minutes to get back to normal .
03 Problem investigation and accident resolution process
The investigation and analysis process of the whole accident is described in detail below .
The first 1 Step : After receiving an alert from the thread pool task queue , We first looked at the real-time data of each dimension of the fee deduction service : Including the service usage 、 Timeout amount 、 Error log 、JVM monitor , No abnormality was found .
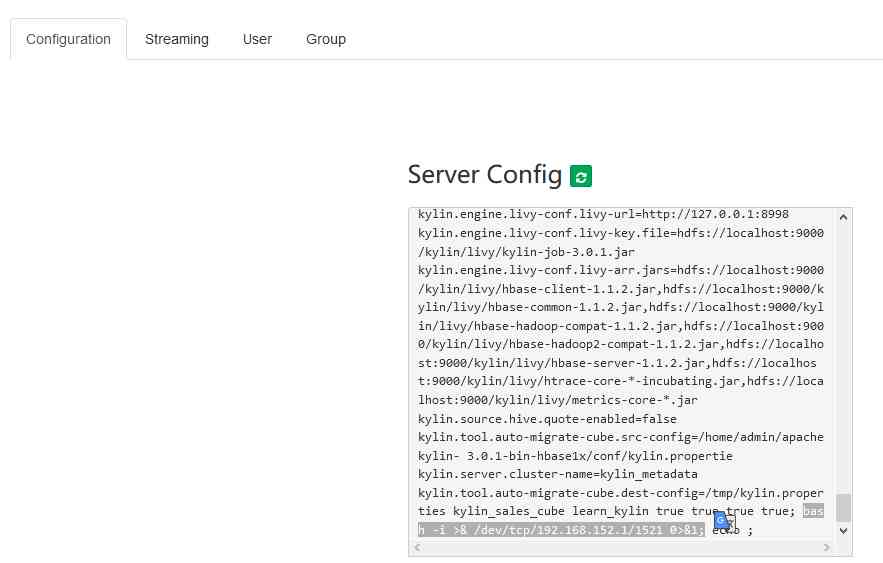
The first 2 Step : Then it further investigates the storage resources that the fee deduction service depends on (mysql、redis、mq), External service , A large number of slow database queries were found during the accident .
The above slow query comes from a big data extraction task just launched during the accident , From the deduction service mysql In the database, a large number of concurrent data extraction to hive surface . Because the deduction process also involves writing mysql, Guess at this time mysql All of the read and write performance of has been affected , Sure enough, it was found that insert The operation time is much longer than normal period .

The first 3 Step : We suspect that slow database queries affect the performance of the fee deduction process , This creates a backlog of task queues , So we decided to set up the task of big data extraction immediately . But it's strange : After stopping the extraction task , Database insert Performance is back to normal , But the size of the blocking queue continues to grow , The alarm didn't go away .
The first 4 Step : Considering that advertising revenue is still falling sharply , Further analysis of the code takes a long time , So I decided to restart the service immediately to see if it worked . To keep the scene of the accident , We kept a server that didn't restart , Just took this machine off the service management platform , So it won't receive a new deduction request .
Sure enough, the killer mace to restart the service works , All business indicators are back to normal , The alarm did not appear again . thus , The whole online fault has been solved , It lasted for about 30 minute .
04 The process of analyzing the root cause of the problem
Let's talk about the analysis process of the root cause of the accident in detail .
The first 1 Step : The next day after work , We guess the server that kept the scene of the accident , The backlog of tasks in the queue should be disposed of by the thread pool , So try to mount this server again to verify our guess , It turned out to be the opposite of what was expected , The backlog is still there , And come in with new requests , The system alarm immediately reappeared , So I took this server off immediately .
The first 2 Step : Thousands of tasks in the thread pool , after 1 I haven't been processed by the thread pool for a whole night , We guess there should be a deadlock . So I plan to pass jstack command dump Do a detailed analysis of the thread .
# Find the process number of the fee deduction service
$ ps aux|grep "adclick"
# By process number dump Thread snapshot , Output to a file
$ jstack pid > /tmp/stack.txthstay jstack In the log file of , Immediately found out : All threads in the business thread pool for fee deduction are in waiting state , The thread is all stuck in the red box in the screenshot , This line of code calls countDownLatch Of await() Method , That is, wait for the counter to change to 0 Then release the shared lock .

The first 3 Step : After finding the above anomalies , It's close to finding the root cause , Let's go back to the code and continue investigating , First look at the business code used in newFixedThreadPool Thread pool , The number of core threads is set to 25. in the light of newFixedThreadPool,JDK The description of the document is as follows :
Create a thread pool that can reuse a fixed number of threads , Run these threads in a shared, unbounded queue . If you submit a new task while all threads are active , Before there are available threads , The new task will wait in the queue .
About newFixedThreadPool, The core includes two points :
1、 Maximum number of threads = Number of core threads , When all core threads are working on tasks , The new task will be submitted to the task queue to wait ;2、 Unbounded queue is used : The size of the task queue submitted to the thread pool is unlimited , If the task is blocked or processing slows down , So obviously the queue is going to get bigger and bigger .
therefore , The further conclusion is that : All core threads are deadlocked , New tasks are not pouring into the boundless queue , As a result, the task queue keeps increasing .
The first 4 Step : What is the cause of deadlock , Let's go back to jstack Log file prompt that line of code for further analysis . Here is my simplified sample code :
/*** Perform the deduction task */
public Result<Integer> executeDeduct(ChargeInputDTO chargeInput) {
ChargeTask chargeTask = new ChargeTask(chargeInput);
bizThreadPool.execute(() -> chargeTaskBll.execute(chargeTask ));
return Result.success();
}
/*** The specific business logic of the deduction task */
public class ChargeTaskBll implements Runnable {
public void execute(ChargeTask chargeTask) {
// First step : Parameter checking
verifyInputParam(chargeTask);
// The second step : Perform the anti cheating subtask
executeUserSpam(SpamHelper.userConfigs);
// The third step : Execution deduction
handlePay(chargeTask);
// Other steps : Click on the buried point and so on ...
}
}
/*** Perform the anti cheating subtask */
public void executeUserSpam(List<SpamUserConfigDO> configs) {
if (CollectionUtils.isEmpty(configs)) {
return;
} try {
CountDownLatch latch = new CountDownLatch(configs.size());
for (SpamUserConfigDO config : configs) {
UserSpamTask task = new UserSpamTask(config,latch);
bizThreadPool.execute(task);
}
latch.await();
} catch (Exception ex) {
logger.error("", ex);
}
}By the above code , Can you find out how the deadlock happened ? The root cause is : One deduction belongs to the parent task , At the same time, it contains multiple subtasks : Subtasks are used to execute anti cheating strategies in parallel , The parent task and child task use the same business thread pool . When the thread pool is full of executing parent tasks , And all the parent tasks exist, and the child tasks are not completed , This will cause deadlock . Pass below 1 Let's take a look at the deadlock situation :

Suppose the number of core threads is 2, At present, we are carrying out the fee deduction task of the parent 1 and 2. in addition , Anti cheating subtask 1 performed , Anti cheating subtask 2 and 4 They're all stuck in the task queue waiting to be scheduled . Because the anti cheating subtask 2 and 4 It's not finished , So the fee is deducted from the parent task 1 and 2 It's impossible to execute , So there's a deadlock , The core thread can never release , As a result, the task queue keeps growing , Until the program OOM crash.
When the cause of the deadlock is clear , There's another question : The above code has been running online for a long time , Why is it that the problem is now exposed ? In addition, is it directly related to slow database query ?
For the time being, we haven't confirmed it yet , But it can be inferred that : The above code must have the probability of deadlock , Especially in the case of high concurrency or slow task processing , The probability will be greatly increased . Slow database query should be the fuse that led to the accident .
05 Solution
After finding out the root cause , The simplest solution is : Add a new business thread pool , Used to isolate father and son tasks , The existing thread pool is only used to process the deduction task , The new thread pool is used to handle anti cheating tasks . In this way, deadlock can be completely avoided .
06 The problem summary
Review the solution of the accident and the technical proposal of fee deduction , There are several points to be optimized :
1、 A thread pool with a fixed number of threads exists OOM risk , In Alibaba Java It is also clearly stated in the development manual that , And the words are 『 Don't allow 』 Use Executors Creating a thread pool . But through ThreadPoolExecutor To create , This allows students to write more clearly the running rules and core parameters of the thread pool , Avoid the risk of resource depletion .
2、 Advertising deduction scene is an asynchronous process , Through the thread pool or MQ To implement asynchronous processing is optional . in addition , Very few click requests are lost without deduction from business , However, it is not allowed to discard a large number of requests without processing and without compensation scheme . After using the bounded queue , Rejection policy can consider sending MQ Try again .--- end ---
Author's brief introduction :985 master , Former Amazon Java The engineer , present 58 Transfer to technical director .
Keep sharing articles on technology and management . If you are interested , But WeChat scanned the following two-dimensional code to pay attention to my official account :『IT People's career advancement 』