当前位置:网站首页>read文件一个字节实际会发生多大的磁盘IO?
read文件一个字节实际会发生多大的磁盘IO?
2020-11-08 16:12:00 【张彦飞allen】
不管你用的是啥语言,C/PHP/GO、还是Java,相信大家都有过读取文件的经历。我们来思考两个问题,如果我们读取文件中的一个字节:
- 是否会发生磁盘IO?
- 发生的话,Linux实际向磁盘读取多少字节了呢?
为了便于理解问题,我们把c的代码也列出来:
int main()
{
char c;
int in;
in = open("in.txt", O_RDONLY);
read(in,&c,1);
return 0;
}
如果不是从事c/c++开发工作的同学,这个问题想深度理解起来确实不那么容易。因为目前常用的主流语言,PHP/Java/Go啥的封装层次都比较高,把内核的很多细节都给屏蔽的比较彻底。要想把上面的两个问题搞的比较清楚,需要剖开Linux的内部来理解Linux的IO栈。
Linux IO栈简介
废话不多说,我们直接把Linux IO栈的一个简化版本画出来:(官方的IO栈参考这个Linux.IO.stack_v1.0.pdf)
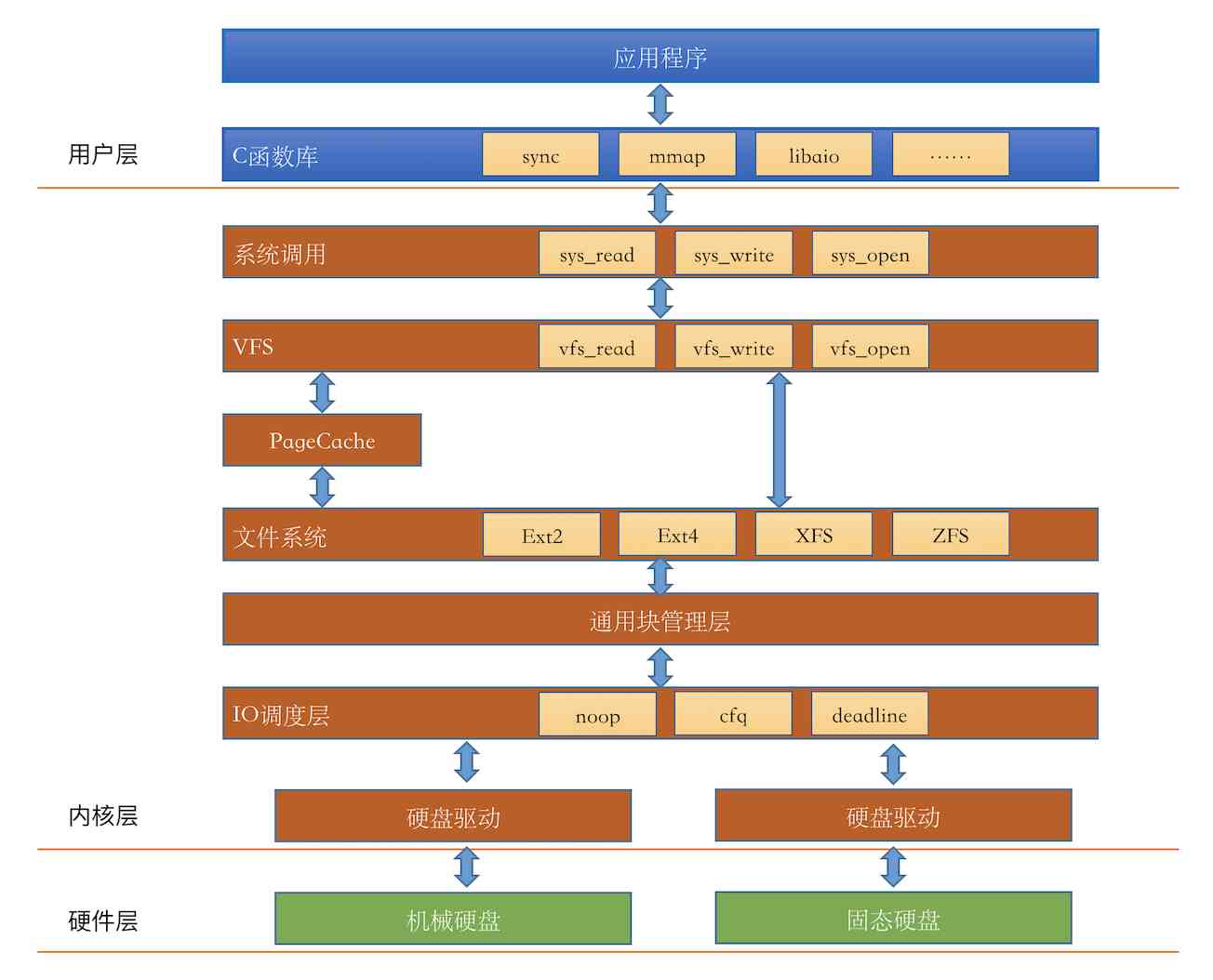
我们在前面也分享了几篇文章讨论了上图图中的硬件层,还有文件系统模块。但通过这个IO栈我们发现,我们对Linux文件的IO的理解还是远远不够,还有好几个内核组件:IO引擎、VFS、PageCache、通用块管理层、IO调度层等模块我们并没有了解太多。别着急,让我们一一道来:
IO引擎
我们开发同学想要读写文件的话,在lib库层有很多种函数可以选择,比如read,write,mmap等。这事实上就是在选择Linux提供的IO引擎。我们最常用的read、write函数是属于sync引擎,除了sync,还有map、psync、vsync、libaio、posixaio等。 sync,psync都属于同步方式,libaio和posixaio属于异步IO。
当然了IO引擎也需要VFS、通用块层等更底层的支持才能实现。在sync引擎的read函数里会进入VFS提供的read系统调用。
VFS虚拟文件系统
在内核层,第一个看到的是VFS。VFS诞生的思想是抽象一个通用的文件系统模型,对我们开发人员或者是用户提供一组通用的接口,让我们不用care具体文件系统的实现。VFS提供的核心数据结构有四个,它们定义在内核源代码的include/linux/fs.h和include/linux/dcache.h中。
- superblock:Linux用来标注具体已安装的文件系统的有关信息
- inode:Linux中的每一个文件都有一个inode,你可以把inode理解为文件的身份证
- file:内存中的文件对象,用来保存进程和磁盘文件的对应关系
- desty:目录项,是路径中的一部分,所有的目录项对象串起来就是一棵Linux下的目录树。
围绕这这四个核心数据结构,VFS也都定义了一系列的操作方法。比如,inode的操作方法定义inode_operations(include/linux/fs.h),在它的里面定义了我们非常熟悉的mkdir和rename等。
struct inode_operations {
......
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*mkdir) (struct inode *,struct dentry *,umode_t);
int (*rmdir) (struct inode *,struct dentry *);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *, unsigned int);
......
在file对应的操作方法file_operations里面定义了我们经常使用的read和write:
struct file_operations {
......
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
......
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
Page Cache
在VFS层往下看,我们注意到了Page Cache。它的中文译名叫页高速缓存,是Linux内核使用的主要磁盘高速缓存,是一个纯内存的工作组件,其作用就是来给访问相对比较慢的磁盘来进行访问加速。如果要访问的文件block正好存在于Page Cache内,那么并不会有实际的磁盘IO发生。如果不存在,那么会申请一个新页,发出缺页中断,然后用磁盘读取到的block内容来填充它 ,下次直接使用。Linux内核使用搜索树来高效管理大量的页面。
如果你有特殊的需求想要绕开Page Cache,只要设置DIRECT_IO就可以了。有两种情况需要绕开:
- 测试磁盘IO的真实性能
- 节约使用Page Cache时系统调用陷入到内核态,以及内核内存向用户进程内存拷贝到开销。
文件系统
在我在之前的文章《新建一个空文件占用多少磁盘空间?》、《理解格式化原理》里讨论的都是具体的文件系统。文件系统里最重要的两个概念就是inode和block,这两个我们在之前的文章里也都见过了。一个block是多大呢,这是运维在格式化的时候决定的,一般默认是4KB。
除了inode和block,每个文件系统还会定义自己的实际操作函数。例如在ext4中定义的ext4_file_operations和ext4_file_inode_operations如下:
const struct file_operations ext4_file_operations = {
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.mmap = ext4_file_mmap,
.open = ext4_file_open,
......
};
const struct inode_operations ext4_file_inode_operations = {
.setattr = ext4_setattr,
.getattr = ext4_file_getattr,
......
};
通用块层
通用块层是一个处理系统中所有块设备IO请求的内核模块。它定义了一个叫bio的数据结构来表示一次IO操作请求(include/linux/bio.h)。
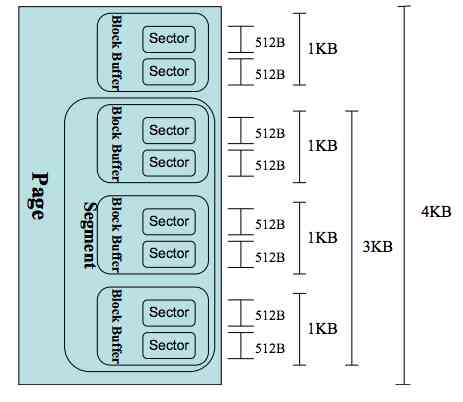
那么一次bio里对应的IO大小单位是页面,还是扇区呢?都不是,是段!每个bio可能会包含多个段。一个段是一个完整的页面,或者是页面的一部分,具体请参考https://www.ilinuxkernel.com/files/Linux.Generic.Block.Layer.pdf。
为什么要搞出个段这么让人费解的东西呢?这是因为在磁盘中连续存储的数据,到了内存Page Cache里的时候可能内存并不连续了。这种状况出现是正常的,不能说磁盘中连续的数据我在内存中就非得用连续的空间来缓存。段就是为了能让一次内存IO DMA到多“段”地址并不连续的内存中的。
一个常见的扇区/段/页的大小对比如下图:
IO调度层
当通用块层把IO请求实际发出以后,并不一定会立即被执行。因为调度层会从全局出发,尽量让整体磁盘IO性能最大化。大致的工作方式是让磁头类似电梯那样工作,先往一个方向走,到头再回来,这样磁盘效率会比较高一些。具体的算法有noop,deadline和cfg等。
在你的机器上,通过dmesg | grep -i scheduler来查看你的Linux支持的算法,并在测试的时候可以选择其中的一种。
读文件过程
我们已经把Linux IO栈里的各个内核组件都介绍一边了。现在我们再从头整体过一下读取文件的过程
- lib里的read函数首先进入系统调用sys_read
- 在sys_read再进入VFS里的vfs_read、generic_file_read等函数
- 在vfs里的generic_file_read会判断是否缓存命中,命中则返回
- 若不命中内核在Page Cache里分配一个新页框,发出缺页中断,
- 内核向通用块层发起块I/O请求,块设备屏蔽了磁盘、U盘的差异
- 通用块层把用bio代表的I/O请求放到IO请求队列中
- IO调度层通过电梯算法来调度队列中的请求
- 驱动程序向磁盘控制器发出读取命令控制,DMA方式直接填充到Page Cache中的新页框
- 控制器发出中断通知
- 内核将用户需要的1个字节填充到用户内存中
- 然后你的进程被唤醒
可以看到,如果Page Cache命中的话,根本就没有磁盘IO产生。所以,大家不要觉得代码里出现几个读写文件的逻辑就觉得性能会慢的不行。操作系统已经替你优化了很多很多,内存级别的访问延迟大约是ns级别的,比机械磁盘IO快了2-3个数量级。如果你的内存足够大,或者你的文件被访问的足够频繁,其实这时候的read操作极少有真正的磁盘IO发生。
我们再看第二种情况,如果Page Cache不命中的话,Linux实际进行了多少个字节的磁盘IO。整个IO过程中涉及到了好几个内核组件。 而每个组件之间都是采用不同长度的块来管理磁盘数据的。
- Page Cache是以页为单位的,Linux页大小一般是4KB(避免有大神挑刺,这里说下Linux能设置大内存页)
- 文件系统是以块为单位来管理的。使用
dumpe2fs可以查看,一般一个块默认是4KB - 通用块层是以段为单位来处理磁盘IO请求的,一个段为一个页或者是页的一部分
- IO调度程序通过DMA方式传输N个扇区到内存,扇区一般为512字节
- 硬盘也是采用“扇区”的管理和传输数据的
可以看到,虽然我们从用户角度确实是只读了1个字节(开篇的代码中我们只给这次磁盘IO留了一个字节的缓存区)。但是在整个内核工作流中,最小的工作单位是磁盘的扇区,为512字节,比1个字节要大的多。另外block、page cache等高层组件工作单位更大,所以实际一次磁盘读取是很多字节一起进行的。假设段就是一个内存页的话,一次磁盘IO就是4KB(8个512字节的扇区)一起进行读取。
Linux内核中我们没有讲到的是还有一套复杂的预读取的策略。所以,在实践中,可能比8更多的扇区来一起被传输到内存中。
最后
操作系统的本意是做到让你简单可依赖, 让你尽量把它当成一个黑盒。你想要一个字节,它就给你一个字节,但是自己默默干了许许多多的活儿。我们虽然国内绝大多数开发都不是搞底层的,但如果你十分关注你的应用程序的性能,你应该明白操作系统的什么时候悄悄提高了你的性能,是怎么来提高的。以便在将来某一个时候你的线上服务器扛不住快要挂掉的时候,你能迅速找出问题所在。
我们再扩展一下,假如Page Cache没有命中,那么一定会有传动到机械轴上的磁盘IO吗?
其实也不一定,为什么,因为现在的磁盘本身就会带一块缓存。另外现在的服务器都会组建磁盘阵列,在磁盘阵列里的核心硬件Raid卡里也会集成RAM作为缓存。只有所有的缓存都不命中的时候,机械轴带着磁头才会真正工作。

开发内功修炼之硬盘篇专辑:
- 1.磁盘开篇:扒开机械硬盘坚硬的外衣!
- 2.磁盘分区也是隐含了技术技巧的
- 3.我们怎么解决机械硬盘既慢又容易坏的问题?
- 4.拆解固态硬盘结构
- 5.新建一个空文件占用多少磁盘空间?
- 6.只有1个字节的文件实际占用多少磁盘空间
- 7.文件过多时ls命令为什么会卡住?
- 8.理解格式化原理
- 9.read文件一个字节实际会发生多大的磁盘IO?
- 10.write文件一个字节后何时发起写磁盘IO?
- 11.机械硬盘随机IO慢的超乎你的想象
- 12.搭载固态硬盘的服务器究竟比搭机械硬盘快多少?
我的公众号是「开发内功修炼」,在这里我不是单纯介绍技术理论,也不只介绍实践经验。而是把理论与实践结合起来,用实践加深对理论的理解、用理论提高你的技术实践能力。欢迎你来关注我的公众号,也请分享给你的好友~~~
版权声明
本文为[张彦飞allen]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4746202/blog/4707203
边栏推荐
- Builder pattern
- It's just right. It's the ideal state
- 技术总监7年总结,如何进行正确的沟通?
- 3、 The parameters of the function
- [open source]. Net uses ORM to access Huawei gaussdb database
- Tencent, which is good at to C, how to take advantage of Tencent's cloud market share in these industries?
- Application of four ergodic square of binary tree
- uni-app实战仿微信app开发
- CSP考试须知与各种小技巧
- 擅长To C的腾讯,如何借腾讯云在这几个行业云市场占有率第一?
猜你喜欢
构建者模式(Builder pattern)

2035 we will build such a country
后端程序员必备:分布式事务基础篇
Gopherchina 2020 Conference
Essential for back-end programmers: distributed transaction Basics
佛萨奇forsage以太坊智能合约是什么?以太坊全球滑落是怎么回事
The first open source Chinese Bert pre training model in the financial field
Workers, workers soul, draw lifelong members, become a person!
laravel8更新之维护模式改进
二叉树的四种遍历方应用
随机推荐
Restfulapi learning notes -- father son resources (4)
TypeScript(1-2-2)
What is the database paradigm
Leancloud changes in October
laravel8更新之维护模式改进
I used Python to find out all the people who deleted my wechat and deleted them automatically
Alibaba cloud accelerates its growth and further consolidates its leading edge
构建者模式(Builder pattern)
vim-配置教程+源码
Arduino ide build esp8266 development environment, slow file download solution | esp-01 make WiFi switch tutorial, transform dormitory lights
Google's AI model, which can translate 101 languages, is only one more than Facebook
Application of four ergodic square of binary tree
Comics: looking for the best time to buy and sell stocks
谷歌开源能翻译101种语言的AI模型,只比Facebook多一种
How to cooperate with people in software development? |Daily anecdotes
We made a medical version of the MNIST dataset, and found that the common automl algorithm is not so easy to use
Flink的sink实战之一:初探
关于update操作并发问题
Gopherchina 2020 Conference
C + + things: from rice cookers to rockets, C + + is everywhere