当前位置:网站首页>深度学习分类优化实战
深度学习分类优化实战
2022-07-02 06:25:00 【wxplol】
文章目录
近期做了一些与分类相关得实验,主要研究了模型有过过程中的一些优化手段,这里记录下,本文对相关模型和算法进行了实现并运行测试,整体来说,有的优化手段可以增加模型的准确率,有的可能没啥效果,总的记录如下文。本文使用得数据集为CIFAR-100 。
代码地址:传送门
一、优化策略
1、CIFAR-100 数据集简介
首先,我们需要拿到数据和明确我们的任务。这里以cifar-100为例,它是8000万个微小图像数据集的子集,他们由Alex Krizhevsky,Vinod Nair和Geoffrey Hinton收集。CIFAR -100数据集(100 个类别)是 Tiny Images 数据集的子集,由 60000 个 32x32 彩色图像组成。CIFAR-100 中的 100 个类分为 20 个超类。每个类有 600 张图像。每个图像都带有一个“精细”标签(它所属的类)和一个“粗略”标签(它所属的超类)。每个类有 500 个训练图像和 100 个测试图像。
简单来说,我们需要针对CIFAR-100 数据集,设计、搭建、训练机器学习模型,能够尽可能准确地分辨出测试数据地标签。
参考连接:
2、模型评估指标
对于分类模型,最主要的是看模型的准确率。当然,光从准确率不能完全评估模型的性能,我还需要从混淆矩阵来看每一类的分类情况,PR曲线分析我们模型的准确率和召回率,ROC曲线评估模型的泛化能力。具体实现可以参考本文代码utils/metric.py。
- 混淆矩阵

通过观察,可以看出模型对每一类都能很好的进行分类。
- PR曲线

- ROC曲线
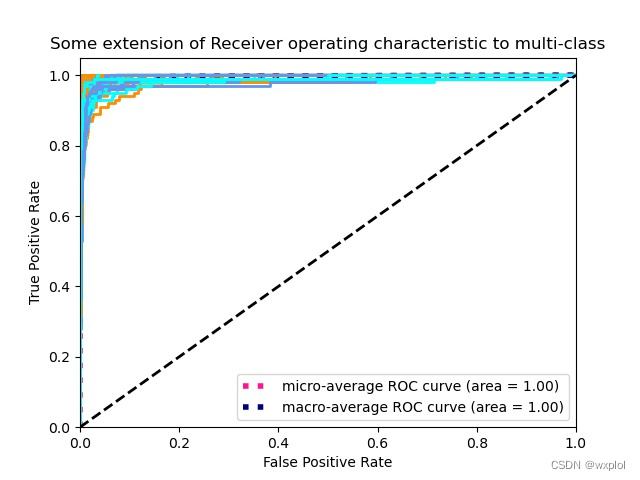
3、数据!数据!数据!
3.1、数据增强
数据增强是解决过拟合一个比较好的手段,它的本质是在一定程度上扩充训练数据样本,避免模型拟合到训练集中的噪声,所以设计一个好的数据增强方案尤为必要。在CV任务中,常用的数据增强包括RandomCrop(随机扣取)、Padding(补丁)、RandomHorizontalFlip(随机水平翻转)、ColorJilter(颜色抖动)等。还有一些其他高级的数据增强技巧,比如RandomEreasing(随机擦除)、MixUp、CutMix、AutoAugment,以及最新的AugMix和GridMask等。在实际训练中,如何选择,需要以具体实验为主,主要需要参考一些优秀论文,借鉴何使用。在此次任务中我们除了一些常用的增强方法外,也选择了一些加分点的优化手段,然后通过选择实验对比,选择较合适的数据增强方案。具体实现utils/augment/augment.py。
主要对比如下:
| method | acc |
|---|---|
| RandomCrop+RandomHorizontalFlip+RandomRotation | 0.78 |
| RandomCrop+RandomHorizontalFlip+RandomRotation+random_erase | 0.79 |
| RandomCrop+RandomHorizontalFlip+RandomRotation+random_erase+autoaugment | 0.81 |
3.2、数据分布
本文使用的CIFAR-100数据集的每一个类属于数据比较均衡的,但在实际分类中,大多数是不均衡的长尾数据,这个时候需要减少这种不均衡对预测的影响。当然,除了长尾分布的影响,还有类间相似的影响,比如两个类比较接近,无论形状、大小或颜色等,需要算法进一步区分或尽量减少对分类的影响。常用的解决长尾分布手手段有:重采样(需要在不影响原始分布的情况,如异常检测,这种情况重采样会改变数据原始分布,反而会降低准确率,因为本来就是正/负样本多)、重新设计loss(如Focal loss、OHEM、Class Balanced Loss)、或者转化为异常检测以及One-class分类模型等。
对于多类别问题,同一张图片可能有多个类,此时传统的CE loss的设计就有一定缺陷了。因为在多标签分类中,一个数据点中可以有多个正确的类。因此,多标签分类问题的需要检测图像中存在的每个对象。而CE loss会尽可能拟合one-hot标签,容易造成过拟合,无法保证模型的泛化能力,同时由于无法保证标签百分百正确,可能存在一些错误标签,但模型也会拟合这些错误标签,由于以上原因,提出了标签平滑,为软标签,属于正则化的一种,可以防止过拟合。label smoothing标签平滑实现见utils/losses.py。
参考链接:
4、模型选择
模型的选择优先考虑最新最好的模型,可以参考传送门,选择合适的模型。这里,我选择的ResNet模型作为baseline backbone。
这里我们进行不同的模型比较,实验如下:
| method | acc |
|---|---|
| resnet18 | 0.75 |
| resnet50 | 0.78 |
| resnet101 | 0.79 |
可以看出模型越复杂,能提升我们的模型准确率。所以后续我们也选择了wideresnet这样的大的模型来训练这个对模型的准确率也有很大的提升。当然,后续还可以选择当前最新的transformer模型,如:VIT、Swin、CaiT等,作为我们的训练模型。
参考链接:
一文窥探近期大火的Transformer以及在图像分类领域的应用_果菌药的博客-程序员ITS401_transformer图像分类
Transformer小试牛刀(一):Vision Transformer
5、模型优化
5.1、学习率选择
我们通过枚举不同学习率下的loss值选择最优学习率(具体实现tool/lr_finder.py),绘制曲线如下:

通过观察可知,lr=0.1时loss最低,此时学习率最优。
5.2、优化器选择
对于深度学习来说,优化器比较多,如:SGD、Adagrad、Adadelta、RMSprop、Adam等。当然,也有最新的优化器,如:Ranger、SAM等(具体实现utils/optim.py)。
这里我们对不同的优化器比较,实验如下:
| method | acc |
|---|---|
| SGD | 0.79 |
| adam | 0.79 |
| ranger | 0.65 |
| SAM | 0.8311 |
通过观察可知,选择SAM优化器最优。
参考链接:
深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
5.3、学习率更新策略选择
这里我们选择warmup预热更新策略,具体实现utils/scheduler.py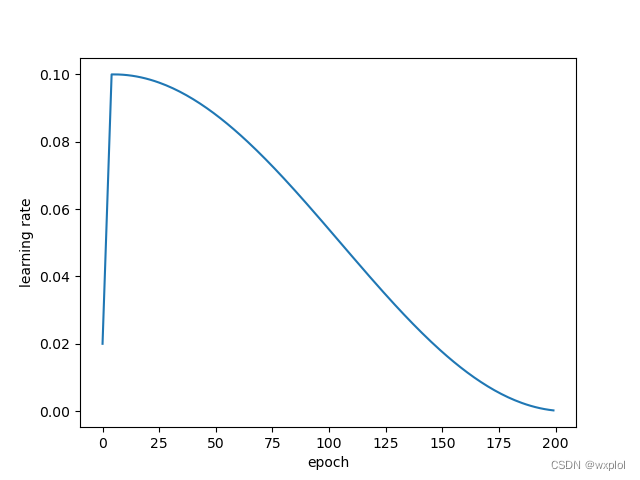
5.4、loss选择
在前面的数据分析中,我们讨论了数据分布的问题,由于我们的数据是多分类问题,所以我们需要在交叉熵损失函数的基础上加入标签平滑,这样能够更好的训练,防止过拟合。
这里我们对不同的损失函数比较,实验如下:
| method | acc |
|---|---|
| CE | 0.8311 |
| smooth_CE | 0.833 |
6、整体思路
- lr:
- warmup (5 epoch)
- cosine lr decay
- lr=0.1
- total epoch(200 epoch)
- bs=128
- aug:
- Random Crop and resize
- Random left-right flipping
- Random rotation
- AutoAugment
- Normalization
- Random Erasing
- weight decay=5e-4 (bias and bn undecayed)
- kaiming weight init
- optimizer: SAM
- loss: smooth_CE
- TTA
我们初步训练resnet50作为基础模型,实验测试过程如下:
| network | method | acc |
|---|---|---|
| resnet18 | SGD+warmup+CE | 0.75 |
| resnet50 | SGD+warmup+CE | 0.78 |
| resnet101 | SGD+warmup+CE | 0.79 |
| resnet50 | SGD+warmup+random_erase+CE | 0.79 |
| resnet50 | SGD+warmup+random_erase+autoaugment+CE | 0.815 |
| resnet50 | adam+warmup+random_erase+autoaugment+CE | 0.79 |
| resnet50 | ranger+warmup+random_erase+autoaugment+CE | 0.65 |
| resnet50 | SAM+warmup+random_erase+autoaugment+CE | 0.8311 |
| resnet50 | SAM+warmup+random_erase+autoaugment+smooth_CE | 0.833 |
| wideresnet40_10 | SAM+warmup+random_erase+autoaugment+smooth_CE | 0.840 |
| wideresnet40_10 | SAM+warmup+random_erase+autoaugment+smooth_CE+TTA | 0.8437 |
通过实验,我们最终选择wideresnet40_10作为特征提取模型,实验过程中将Accuracy由78%提升到84.37%。
二、pytorch实战
安装要求
- python3.6
- pytorch1.6.0+cu101
- tensorboard 2.2.2(optional)
运行tensorboard
$ mkdir runs
$ tensorboard --logdir='runs' --port=6006 --host='localhost'
- 训练模型
$ python train.py -gpu
- 测试模型
$ python test.py
模型参考链接:
- vgg Very Deep Convolutional Networks for Large-Scale Image Recognition
- googlenet Going Deeper with Convolutions
- inceptionv3 Rethinking the Inception Architecture for Computer Vision
- inceptionv4, inception_resnet_v2 Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- xception Xception: Deep Learning with Depthwise Separable Convolutions
- resnet Deep Residual Learning for Image Recognition
- resnext Aggregated Residual Transformations for Deep Neural Networks
- resnet in resnet Resnet in Resnet: Generalizing Residual Architectures
- densenet Densely Connected Convolutional Networks
- shufflenet ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- shufflenetv2 ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
- mobilenet MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- mobilenetv2 MobileNetV2: Inverted Residuals and Linear Bottlenecks
- residual attention network Residual Attention Network for Image Classification
- senet Squeeze-and-Excitation Networks
- squeezenet SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
- nasnet Learning Transferable Architectures for Scalable Image Recognition
- wide residual networkWide Residual Networks
- stochastic depth networksDeep Networks with Stochastic Depth
边栏推荐
- oracle-外币记账时总账余额表gl_balance变化(上)
- Conda 创建,复制,分享虚拟环境
- Drawing mechanism of view (I)
- Using MATLAB to realize: power method, inverse power method (origin displacement)
- Oracle EBS数据库监控-Zabbix+zabbix-agent2+orabbix
- RMAN incremental recovery example (1) - without unbacked archive logs
- [torch] the most concise logging User Guide
- JSP intelligent community property management system
- spark sql任务性能优化(基础)
- MySQL无order by的排序规则因素
猜你喜欢
Play online games with mame32k

ORACLE EBS中消息队列fnd_msg_pub、fnd_message在PL/SQL中的应用

SSM student achievement information management system
![[introduction to information retrieval] Chapter 1 Boolean retrieval](/img/78/df4bcefd3307d7cdd25a9ee345f244.png)
[introduction to information retrieval] Chapter 1 Boolean retrieval

Classloader and parental delegation mechanism

ORACLE EBS ADI 开发步骤
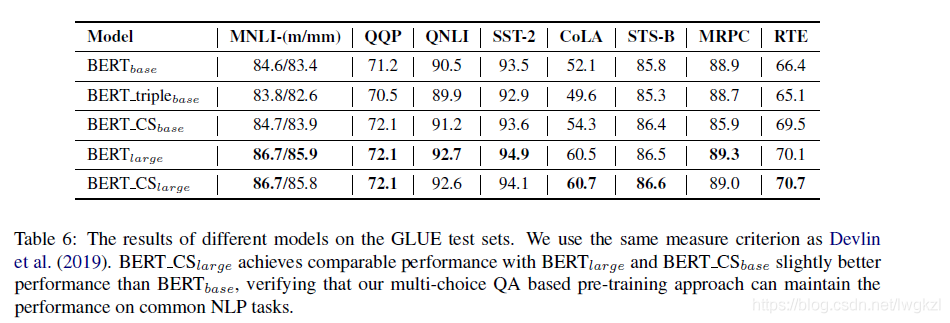
【BERT,GPT+KG调研】Pretrain model融合knowledge的论文集锦

ssm超市订单管理系统
使用MAME32K进行联机游戏
中年人的认知科普
随机推荐
Tencent machine test questions
離線數倉和bi開發的實踐和思考
Cloud picture says | distributed transaction management DTM: the little helper behind "buy buy buy"
【BERT,GPT+KG调研】Pretrain model融合knowledge的论文集锦
Oracle RMAN automatic recovery script (migration of production data to test)
【Torch】最简洁logging使用指南
SSM second hand trading website
Pyspark build temporary report error
Feeling after reading "agile and tidy way: return to origin"
一份Slide两张表格带你快速了解目标检测
oracle apex ajax process + dy 校验
[introduction to information retrieval] Chapter 3 fault tolerant retrieval
【Torch】解决tensor参数有梯度,weight不更新的若干思路
Oracle APEX 21.2 installation et déploiement en une seule touche
Implementation of purchase, sales and inventory system with ssm+mysql
Oracle apex Ajax process + dy verification
[tricks] whiteningbert: an easy unsupervised sentence embedding approach
CRP实施方法论
【调参Tricks】WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach
优化方法:常用数学符号的含义