当前位置:网站首页>[paper introduction] r-drop: regulated dropout for neural networks
[paper introduction] r-drop: regulated dropout for neural networks
2022-07-02 07:22:00 【lwgkzl】
executive summary
The starting point of this paper is : Previous dropout There is a problem that the model is inconsistent between training and testing .
Based on this starting point , This paper proposes R-Dropout The way to solve this problem .
Experimental proof ,R-Dropout Valid on multiple datasets ( Both slightly improved )
Yes Dropout Thinking
First of all, we need to understand , Why the previous dropout There is a problem of inconsistency between training and testing . During training ,dropout It's random mask Some nodes of the model , Then use the remaining network to fit the data ( Prevent over fitting ). In different batch In the process of data training , because mask It's random , Therefore, different data may be processed through different networks . Therefore, the whole training process can be regarded as integrated learning of multiple different networks . And when it comes to testing , Because it won't be random mask Drop the node , Therefore, it can be regarded as a complete model to make predictions on the test set , So there is inconsistency .
Because in training , Learning is a sub model , And when testing , A complete model is used to make predictions .
The author's thinking is very strange , Perhaps the intuitive method is to find a way to reduce the gap between the sub model and the complete model , The idea of this article is not so intuitive , But rather : If the inputs of all sub models are the same , Then the output of the complete model and the output of the sub model should also be similar ., Therefore, the optimization goal of this paper is for the same set of inputs , Through the same architecture , But in a different way mask dropout Post model , The output should be consistent .
R-Dropout Introduce

The main idea is shown in the previous section , This picture can also intuitively show his ideas , As shown on the right , For the same input X, After two identical Transformer encoder structure , However, these two structures will be different mask Conduct dropout Then get two outputs P1(y|x) as well as P2(y|x),R-dropout These two outputs are required to be consistent as much as possible . So with these two outputs KL Divergence is optimized as one of the loss functions of the model .
Experiment and conclusion
Standard experimental proof R-Dropout stay 18 There is a little improvement on all data sets (1%–2%).
Among them, ablation experiment is more interesting , Will test several ideas .
idea 1:
Every time R-dropout When , It can be more than the output generated by two modules KL The divergence , Multiple modules can be used at the same time to compare .
Conclusion : The author did three experiments at the same time dropout Module , The effect is slightly better than the two modules , But it doesn't make much sense .
idea 2: These two modules ,dropout The probability can be different , So you can try to do it with different probabilities mask. Get the following matrix .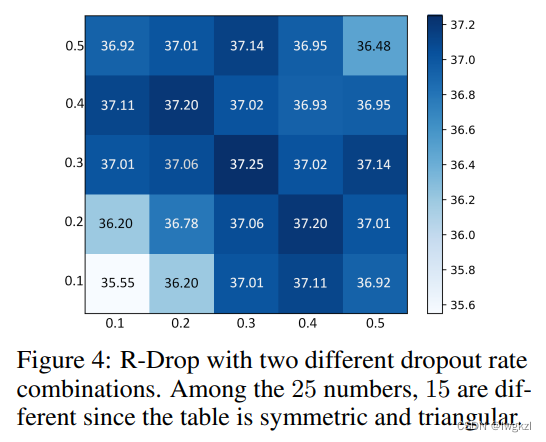 Conclusion : Two module dropout The probability is 0.3-0.5 Between time , The results are not much different .
Conclusion : Two module dropout The probability is 0.3-0.5 Between time , The results are not much different .
Code
import torch.nn.functional as F
# define your task model, which outputs the classifier logits
model = TaskModel()
def compute_kl_loss(self, p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, dim=-1), F.softmax(q, dim=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, dim=-1), F.softmax(p, dim=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
# keep dropout and forward twice
logits = model(x)
logits2 = model(x)
# cross entropy loss for classifier
ce_loss = 0.5 * (cross_entropy_loss(logits, label) + cross_entropy_loss(logits2, label))
kl_loss = compute_kl_loss(logits, logits2)
# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss
In fact, when using , You can put X to copy One copy , Then input to model in , Therefore, there is no need to X Two passes model. namely :
double_x = torch.stack([x,x],0).view(-1,x.size(-1)
tot_logits = model(double_x).view(2, x.size(0), -1)
logits = tot_logits[0]
logits2 = tot_logits[1]
# .....
边栏推荐
- Module not found: Error: Can't resolve './$$_gendir/app/app.module.ngfactory'
- @Transitional step pit
- 图解Kubernetes中的etcd的访问
- Build FRP for intranet penetration
- 【论文介绍】R-Drop: Regularized Dropout for Neural Networks
- 【信息检索导论】第六章 词项权重及向量空间模型
- Oracle EBS interface development - quick generation of JSON format data
- 软件开发模式之敏捷开发(scrum)
- Oracle EBS DataGuard setup
- 【Torch】解决tensor参数有梯度,weight不更新的若干思路
猜你喜欢

Oracle EBS database monitoring -zabbix+zabbix-agent2+orabbix
中年人的认知科普

Implementation of purchase, sales and inventory system with ssm+mysql
使用Matlab实现:Jacobi、Gauss-Seidel迭代

Principle analysis of spark

【模型蒸馏】TinyBERT: Distilling BERT for Natural Language Understanding
Alpha Beta Pruning in Adversarial Search
使用 Compose 实现可见 ScrollBar

Sqli-labs customs clearance (less2-less5)

Message queue fnd in Oracle EBS_ msg_ pub、fnd_ Application of message in pl/sql
随机推荐
Oracle segment advisor, how to deal with row link row migration, reduce high water level
MapReduce concepts and cases (Shang Silicon Valley Learning Notes)
Oracle general ledger balance table GL for foreign currency bookkeeping_ Balance change (Part 1)
数仓模型事实表模型设计
oracle EBS标准表的后缀解释说明
CRP implementation methodology
SSM学生成绩信息管理系统
MySQL组合索引加不加ID
oracle-外币记账时总账余额表gl_balance变化(上)
Message queue fnd in Oracle EBS_ msg_ pub、fnd_ Application of message in pl/sql
Ceaspectuss shipping company shipping artificial intelligence products, anytime, anywhere container inspection and reporting to achieve cloud yard, shipping company intelligent digital container contr
Oracle EBs and apex integrated login and principle analysis
ssm人事管理系统
Oracle apex 21.2 installation and one click deployment
SSM garbage classification management system
Oracle rman半自动恢复脚本-restore阶段
The first quickapp demo
php中计算两个日期之前相差多少天、月、年
使用Matlab实现:幂法、反幂法(原点位移)
【Torch】解决tensor参数有梯度,weight不更新的若干思路