当前位置:网站首页>大数据处理黑科技:揭秘PB级数仓GaussDB(DWS) 并行计算技术
大数据处理黑科技:揭秘PB级数仓GaussDB(DWS) 并行计算技术
2020-11-06 21:35:00 【华为云开发者社区】
摘要:通过这篇文章,我们了解了GaussDB(DWS)并行计算技术的原理以及调优策略。希望广大开发者朋友们能够在实践中尝试该技术,更好地进行性能优化。
随着硬件系统的越来越好,数据库运行的CPU、磁盘、内存资源都日渐增大,SQL语句的串行执行由于不能充分利用资源,已经不能满足日益发展的需要。为此,GaussDB(DWS)开发了并行计算技术,在语句执行时可以充分利用硬件资源进行并行加速,提高执行的吞吐率。本文将详细介绍GaussDB(DWS)并行计算技术的原理,以及其在performance信息中的展示,帮助各位开发者朋友更好地分析并行的性能,从而进行并行执行方面的调优。
并行计算的原理很简单,将原本一个线程的工作平均分配到多个线程来完成,示意图如下图所示:图示中的关联操作,原本需要操作四份数据,通过并行度为4的并行计算后,每个子线程仅需要处理一份数据,理论上性能提升可以达到4倍。

通常情况下,理论上的性能提升是达不到的,因为并行计算也有其性能损耗,包括:启动线程的代价,以及线程之间进行数据传输的代价。因此,只能性能损耗较低,大大低于并行带来的收益时,并行计算的收益才比较明显。所以,并行只有在数据量较大的场景下才能获得较高的性能收益,非常适合于分析型的AP场景。
通过上述分析,我们可以看出,并行计算的难点不在于如何并行,而在于如何正确选择并行度。当数据量较小时,也许串行的性能是最好的,当数据量增大时,可以考虑进行并行。对于一个复杂的执行计划来说,可能包含多个算子,每个算子处理的数据量都不一样,如何综合考虑并行度,以及处理好各算子之间的数据收发关系,将成为并行计算技术的关键难点。
GaussDB(DWS)基于代价估算,根据表的数据量信息来为计划片段生成合适的并行度,下面以TPC-DS Q48为例来看一下,GaussDB(DWS)的并行计划长什么样?
select sum (ss_quantity)
from store_sales, store, customer_demographics, customer_address, date_dim
where s_store_sk = ss_store_sk
and ss_sold_date_sk = d_date_sk and d_year = 1998
and
(
(
cd_demo_sk = ss_cdemo_sk
and
cd_marital_status = 'M'
and
cd_education_status = '4 yr Degree'
and
ss_sales_price between 100.00 and 150.00
)
or
(
cd_demo_sk = ss_cdemo_sk
and
cd_marital_status = 'D'
and
cd_education_status = 'Primary'
and
ss_sales_price between 50.00 and 100.00
)
or
(
cd_demo_sk = ss_cdemo_sk
and
cd_marital_status = 'U'
and
cd_education_status = 'Advanced Degree'
and
ss_sales_price between 150.00 and 200.00
)
)
and
(
(
ss_addr_sk = ca_address_sk
and
ca_country = 'United States'
and
ca_state in ('KY', 'GA', 'NM')
and ss_net_profit between 0 and 2000
)
or
(ss_addr_sk = ca_address_sk
and
ca_country = 'United States'
and
ca_state in ('MT', 'OR', 'IN')
and ss_net_profit between 150 and 3000
)
or
(ss_addr_sk = ca_address_sk
and
ca_country = 'United States'
and
ca_state in ('WI', 'MO', 'WV')
and ss_net_profit between 50 and 25000
)
)
;对应的performance信息为:
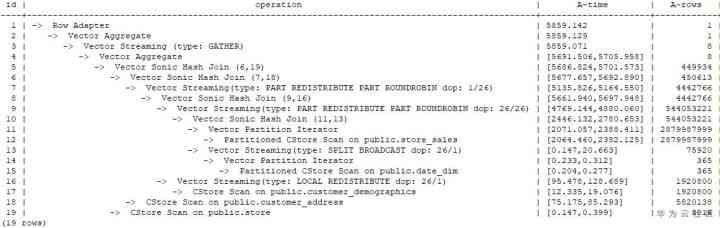
通过将performance信息转变为计划树,可以得到该计划的计划树如下图所示:其中1-3号算子在CN上执行,DN上以跨线程数据传输的Stream算子进行分隔,一共会启动5个线程。GaussDB(DWS)采用pipeline的迭代执行模式,线程4和5从磁盘读取数据,其它每个Stream算子分隔的线程从子线程读取数据,进行执行,并将结果返回给上层算子,顶层DN线程将数据返回给CN处理。通过这个图,我们可以看出,线程1,4,5采用的并行度是1,而线程2,3采用的并行度是26。通过计划信息,我们可以看出,8-13号算子处理的数据量较大,刚好是线程2,3处理的范围,所以选择了较高的并行度。
并行计算的Stream线程仍然沿用DN间的Stream线程进行启动和停止,但DN内部的数据传输改为内存拷贝进行,更节省网络资源,但带来一定程度的内存开销。同时,并行度的增大也使得跨DN间数据传输的数据缓冲区增大,内存开销变大。因此,大内存也是提高并行度的一个必备因素。那么线程之间是如何进行并行度的衔接呢?
通过计划,我们可以看出,并行场景下,Stream线程均显示为:Streaming(type: T dop:N/M),这是在串行场景基础上的扩展,同时也可以以线程为级别看到每个线程执行时间,处理的行数和使用的内存。在串行场景下,我们支持三种类型的Stream算子,分别为redistribute, broadcast和gather, 详细介绍参见《GaussDB(DWS)性能调优系列基础篇二:大道至简explain分布式计划》中第一章节介绍。
并行场景是对串行场景中DN上的redistribute和broadcast类型Stream算子进行扩充,包括以下几类:
1)Streaming(type: SPLIT REDISTRIBUTE):同串行场景下的Redistribute,但以线程为单位进行数据传输,每条元组发送给一个目的线程。
2)Streaming(type: SPLIT BROADCAST):同串行场景下的Broadcast,但以线程为单位进行数据传输,每个线程都将收到全量数据。
3)Streaming(type: LOCAL REDISTRIBUTE):作用是DN内部根据当前分布键进行数据Redistribute。通常作用于基表扫描后,因为基表扫描是按页面进行线程划分,此时线程间并不是按DN的分布键分布的,需要增加该DN内重分布操作。
4)Streaming(type: LOCAL BROADCAST):作用是DN内部进行数据Broadcast,每个线程把数据发送给这个DN的所有线程,每个线程获得该DN的全量数据。5)Streaming(type: LOCAL GATHER):作用是DN内部把数据从多线程汇总到一个线程。
注意:“dop:N/M”表示发送端的dop为M,接收端的dop为N,从而完成从M个线程的并行度转变为N个线程并行度的任务。
在GaussDB(DWS)中,我们增加了参数query_dop,来控制语句的并行度,取值如下:
1)query_dop=1,串行执行,默认值
2)query_dop=[2..N],指定并行执行并行度
3)query_dop=0,自适应调优,根据系统资源和语句复杂度情况自适应选择并行度
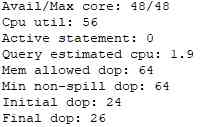
由于开启并行会占用较多的内存,所以目前GaussDB(DWS)的默认并行度为1。在内存较大的环境下,可以通过手动设置query_dop达到并行加速的目的。通常情况下,我们可以考虑首先设置query_dop=0,查看语句的执行计划、performance信息和性能。在performance信息的下方Query Summary一栏,可以看到自适应dop选择的信息,例如:TPC-DS Q48 dop选择信息如下图所示,可以看出初步选定的initial dop为24,最终确定的final dop为26。dop的选择会综合考虑各种因素,其信息也在图中显示出来。
由于自适应选择并行度是根据语句复杂度和系统资源利用情况来进行选择,而系统资源利用情况是获取前一段时间的资源利用情况,有可能出现不准确的情况,此时就需要人为来设置并行度了。人为设置并行度,并不是设置越大越好,dop设置过大,会导致系统中的线程数量急剧增多,导致CPU冲突进行线程切换的额外开销。要想人为设置并行度,同样需要使用单机CPU核数和语句复杂程度进行考量。我们定义单机CPU核数/单机DN数为每个DN可用的CPU核数x,然后根据串行计划中DN Stream算子的个数初步判定语句的复杂度y(例如下图TPC-H Q1计划中只有一个Stream节点,则y为1),单并发时,使用x/y的值设置query_dop。并发场景,再除以并发数p设置query_dop。由于此公式为粗略估计值,因此在设置时可以考虑扩大搜索范围,来寻找合适的并行度。

在并发场景下,GaussDB(DWS)还支持max_active_statements来控制执行语句的个数,当语句的个数超过CPU核数时,可以考虑使用该参数限制并发数,然后再设置合理的query_dop进行调优。还是以刚才的示例为例,单机有96核,2个DN,则每个DN可用48核,则同时执行6个TPC-H Q1查询时,并行度可以设置为8。
通过这篇文章,我们了解了GaussDB(DWS)并行计算技术的原理以及调优策略。希望广大开发者朋友们能够在实践中尝试该技术,更好地进行性能优化。
版权声明
本文为[华为云开发者社区]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4526289/blog/4703708
边栏推荐
- Flink's datasource Trilogy 2: built in connector
- Even liver three all night, jvm77 high frequency interview questions detailed analysis, this?
- 游戏主题音乐对游戏的作用
- [Xinge education] poor learning host computer series -- building step 7 Simulation Environment
- 游戏开发中的新手引导与事件管理系统
- Look! Internet, e-commerce offline big data analysis best practice! (Internet disk link attached)
- WeihanLi.Npoi 1.11.0/1.12.0 Release Notes
- Analysis of ThreadLocal principle
- 理解格式化原理
- Markdown tricks
猜你喜欢

Flink的DataSource三部曲之一:直接API
大道至简 html + js 实现最朴实的小游戏俄罗斯方块
Construction of encoder decoder model with keras LSTM
Discussion on the technical scheme of text de duplication (1)
Use modelarts quickly, zero base white can also play AI!
【自学unity2d传奇游戏开发】如何让角色动起来
Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom

Swagger 3.0 brushes the screen every day. Does it really smell good?
Behind the first lane level navigation in the industry
Even liver three all night, jvm77 high frequency interview questions detailed analysis, this?
随机推荐
大会倒计时|2020 PostgreSQL亚洲大会-中文分论坛议程安排
Python filtering sensitive word records
Discussion on the technical scheme of text de duplication (1)
Markdown tricks
JNI-Thread中start方法的呼叫與run方法的回撥分析
【自学unity2d传奇游戏开发】如何让角色动起来
What are PLC Analog input and digital input
Live broadcast preview | micro service architecture Learning Series live broadcast phase 3
Building and visualizing decision tree with Python
[C] (original) step by step teach you to customize the control element - 04, ProgressBar (progress bar)
美团内部讲座|周烜:华东师范大学的数据库系统研究
python100例項
一路踩坑,被迫聊聊 C# 代码调试技巧和远程调试
Filecoin has completed a major upgrade and achieved four major project progress!
Application of restful API based on MVC
FastThreadLocal 是什么鬼?吊打 ThreadLocal 的存在!!
2020年第四届中国 BIM (数字建造)经理高峰论坛即将在杭举办
游戏主题音乐对游戏的作用
Recommendation system based on deep learning
It's easy to operate. ThreadLocal can also be used as a cache