当前位置:网站首页>Named entity recognition in natural language processing: tanford core LP ner (1)
Named entity recognition in natural language processing: tanford core LP ner (1)
2020-11-06 01:28:00 【Elementary school students in IT field】
Reprint please indicate the source :https://blog.csdn.net/HHTNAN
brief introduction
CoreNLP The project is Stanford Developed a set of open source NLP System . Include tokenize, pos , parse And so on , And SpaCy similar .SpaCy Claims to be the fastest NLP System , And provide ready-made python Interface , But the disadvantage is that it does not support Chinese processing at present , CoreNLP The Chinese model is included , It can be directly used to process Chinese , but CoreNLP Use Java Development ,python It's a little bit cumbersome to call .
Stanford CoreNLP It is a powerful natural language processing tool , Many models are trained based on deep learning .
First attach a link to its official website :
https://stanfordnlp.github.io/CoreNLP/index.html
https://nlp.stanford.edu/nlp/javadoc/javanlp/
https://github.com/stanfordnlp/CoreNLP
install Installation
windows 10 Environmental Science
Installation dependency
1. First you need to configure JDK, install JDK 1.8 And above ..
2. Later on https://stanfordnlp.github.io/CoreNLP/history.html Download the corresponding jar package .
Decompress the package to get the directory , Then the language of jar Put the package in this directory .
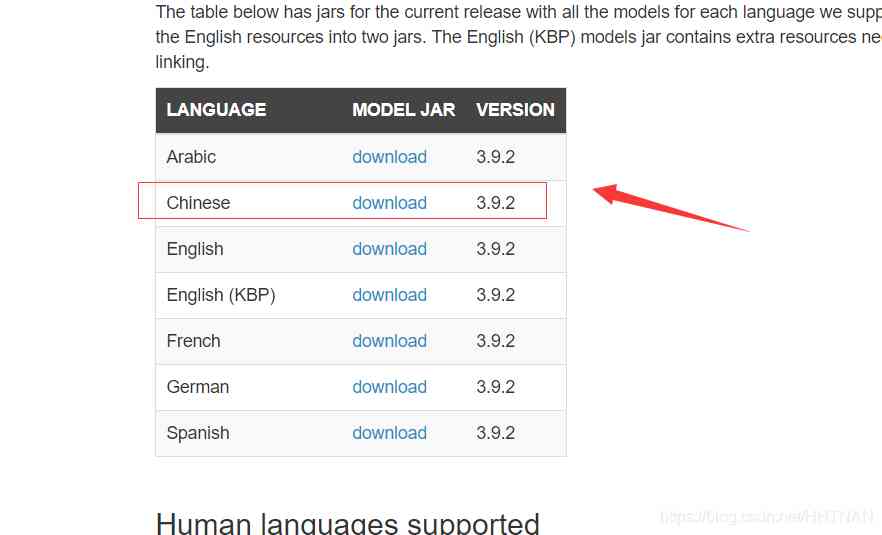
3. download Stanford CoreNLP file :http://stanfordnlp.github.io/CoreNLP/download.html

4. Download the Chinese model jar package ( Be sure to download this file , Otherwise, it is handled in English by default ).
5. Next py install stanfordcorenlp
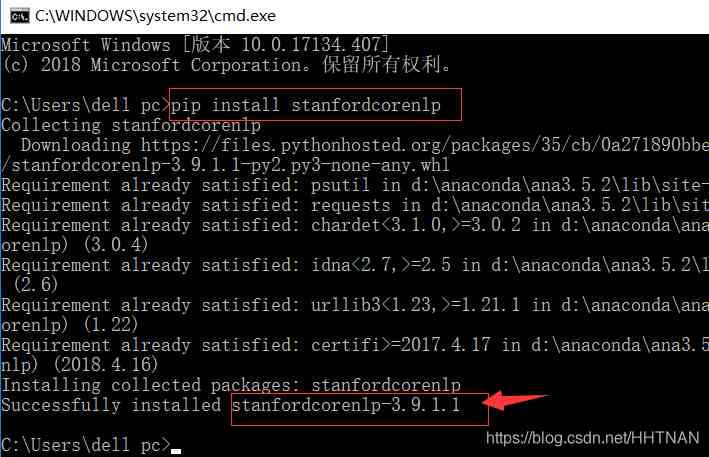
6. Unzip configuration
When the download is complete, the two files add up 1G+ When the download is complete, the two files add up 1G+

Take the decompressed Stanford CoreNLP Folder downloaded Stanford-chinese-corenlp-2018—models.jar Put it in the same directory ( Be careful : Be sure to be in the same directory , Otherwise, the execution will report an error )

7. stay Python Reference model in , Execute the following statement :
from stanfordcorenlp import StanfordCoreNLP
nlp=StanfordCoreNLP(r’D:\D:\stanford_nlp\stanford-corenlp-full-2018-10-05’,lang=‘zh’)
application
#encoding="utf-8"
from stanfordcorenlp import StanfordCoreNLP
import os
if os.path.exists('D:\\stanford_nlp\\stanford-corenlp-full-2018-10-05'):
print("corenlp exists")
else:
print("corenlp not exists")
nlp=StanfordCoreNLP('D:\\stanford_nlp\\stanford-corenlp-full-2018-10-05',lang='zh')
sentence = ' Wang Ming is a graduate student of Tsinghua University '
print(nlp.ner(sentence))
Output :
corenlp exists
[(‘ Wang Ming ’, ‘PERSON’), (‘ yes ’, ‘O’), (‘ tsinghua ’, ‘ORGANIZATION’), (‘ university ’, ‘ORGANIZATION’), (‘ Of ’, ‘O’), (‘ One ’, ‘NUMBER’), (‘ individual ’, ‘O’), (‘ Graduate student ’, ‘O’)]
3、 ... and 、 See part of speech tagging
Access in a browser :http://localhost:9000/


Reprint please indicate the source :https://blog.csdn.net/HHTNAN
版权声明
本文为[Elementary school students in IT field]所创,转载请带上原文链接,感谢
边栏推荐
- What is the difference between data scientists and machine learning engineers? - kdnuggets
- Summary of common algorithms of linked list
- vue任意关系组件通信与跨组件监听状态 vue-communication
- Brief introduction of TF flags
- Filecoin的经济模型与未来价值是如何支撑FIL币价格破千的
- ES6学习笔记(四):教你轻松搞懂ES6的新增语法
- Discussion on the technical scheme of text de duplication (1)
- 零基础打造一款属于自己的网页搜索引擎
- Advanced Vue component pattern (3)
- 比特币一度突破14000美元,即将面临美国大选考验
猜你喜欢

Calculation script for time series data
What to do if you are squeezed by old programmers? I don't want to quit

Arrangement of basic knowledge points

A course on word embedding
前端工程师需要懂的前端面试题(c s s方面)总结(二)

I've been rejected by the product manager. Why don't you know
零基础打造一款属于自己的网页搜索引擎
速看!互联网、电商离线大数据分析最佳实践!(附网盘链接)
vue任意关系组件通信与跨组件监听状态 vue-communication

Summary of common algorithms of linked list
随机推荐
Let the front-end siege division develop independently from the back-end: Mock.js
The difference between Es5 class and ES6 class
How to select the evaluation index of classification model
axios学习笔记(二):轻松弄懂XHR的使用及如何封装简易axios
IPFS/Filecoin合法性:保护个人隐私不被泄露
Python download module to accelerate the implementation of recording
采购供应商系统是什么?采购供应商管理平台解决方案
React design pattern: in depth understanding of react & Redux principle
Interface pressure test: installation, use and instruction of siege pressure test
一篇文章带你了解HTML表格及其主要属性介绍
Word segmentation, naming subject recognition, part of speech and grammatical analysis in natural language processing
Wechat applet: prevent multiple click jump (function throttling)
前端都应懂的入门基础-github基础
ES6学习笔记(二):教你玩转类的继承和类的对象
合约交易系统开发|智能合约交易平台搭建
Using consult to realize service discovery: instance ID customization
Vue.js Mobile end left slide delete component
How to customize sorting for pandas dataframe
百万年薪,国内工作6年的前辈想和你分享这四点
What is the side effect free method? How to name it? - Mario