当前位置:网站首页>Construction of encoder decoder model with keras LSTM
Construction of encoder decoder model with keras LSTM
2020-11-06 01:28:00 【Artificial intelligence meets pioneer】
author |Nechu BM compile |VK source |Towards Data Science

Basic knowledge of : It's better to have some knowledge about cyclic neural networks before you know this article (RNN) And knowledge of codecs .
This article is about how to use Python and Keras A practical tutorial for developing a codec model , More precisely, it's a sequence to sequence (Seq2Seq). In the last tutorial , We developed a many to many translation model , As shown in the figure below :
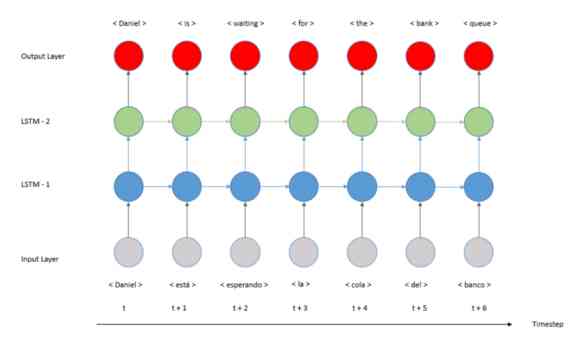
This structure has an important limitation , The length of the sequence . As we can see in the image , The length of input sequence and output sequence must be the same . What if we need different lengths ?
for example , We want to implement a model that accepts different sequence lengths , It takes a sequence of words and outputs a number , Or image subtitle model , Where the input is an image , The output is a sequence of words .
If we want to develop a model with different input and output lengths , We need to develop a codec model . Through this tutorial , We'll learn how to develop models , And apply it to translation practice . The representation of the model is as follows .
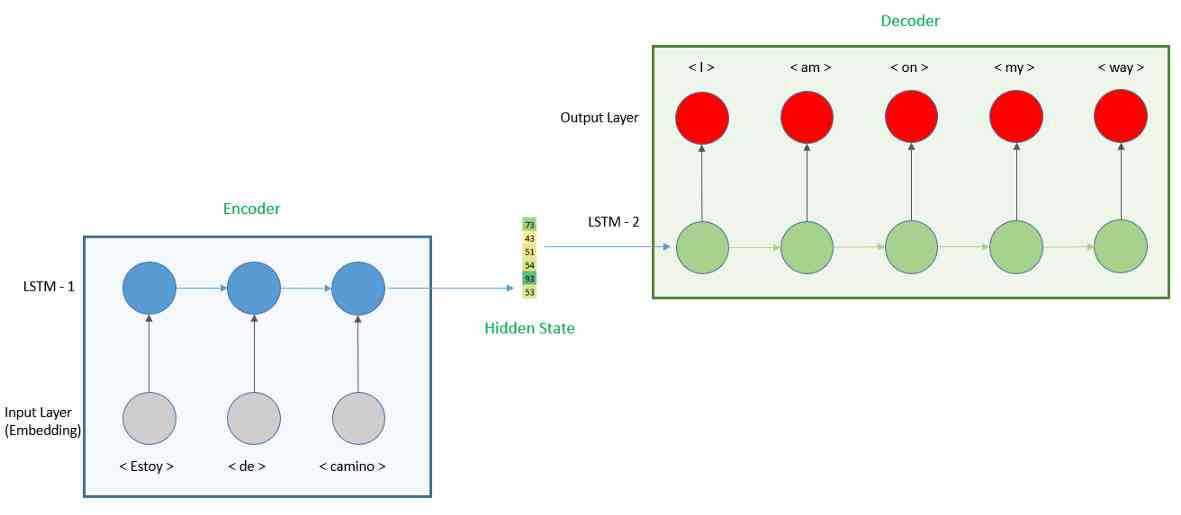
We divide the model into two parts , First , We have an encoder , Input the Spanish sentence and generate a hidden vector . The encoder uses an embedded layer to convert words into a vector and then uses a cyclic neural network (RNN) To calculate the hidden state , Here we're going to use long-term and long-term memory (LSTM) layer .
Then the output of the encoder will be used as the input to the decoder . For the decoder , We will use it again LSTM layer , And the full connectivity layer for predicting English words .
Realization
The sample data comes from manythings.org. It is made up of sentence pairs of language . In our case , We're going to use Spanish - English to .
To build a model, we need to preprocess the data first , Get the maximum length of Spanish and English sentences .
1- Preprocessing
precondition : understand Keras Class in “tokenizer” and “pad_sequences”. If you want to go back in detail , We discussed this topic in the last tutorial .
First , We're going to import it into the library , And then read the downloaded data .
import string
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model
from keras.layers import LSTM, Input, TimeDistributed, Dense, Activation, RepeatVector, Embedding
from keras.optimizers import Adam
from keras.losses import sparse_categorical_crossentropy
# The path of the translation file
path_to_data = 'data/spa.txt'
# Reading documents
translation_file = open(path_to_data,"r", encoding='utf-8')
raw_data = translation_file.read()
translation_file.close()
# Parsing data
raw_data = raw_data.split('\n')
pairs = [sentence.split('\t') for sentence in raw_data]
pairs = pairs[1000:20000]
Once we read the data , We'll keep the first example , In order to train faster . If we want to develop higher performance models , We need to use a complete dataset . Then we have to clean up the data by removing the capital letters and punctuation marks .
def clean_sentence(sentence):
# Put this sentence in lowercase
lower_case_sent = sentence.lower()
# Remove punctuation
string_punctuation = string.punctuation + "¡" + '¿'
clean_sentence = lower_case_sent.translate(str.maketrans('', '', string_punctuation))
return clean_sentence
Next , We identify sentences and analyze data .
def tokenize(sentences):
# establish tokenizer
text_tokenizer = Tokenizer()
# Apply to text
text_tokenizer.fit_on_texts(sentences)
return text_tokenizer.texts_to_sequences(sentences), text_tokenizer
After creating the function , We can preprocess :
# Clean up sentences
english_sentences = [clean_sentence(pair[0]) for pair in pairs]
spanish_sentences = [clean_sentence(pair[1]) for pair in pairs]
# Identifying words
spa_text_tokenized, spa_text_tokenizer = tokenize(spanish_sentences)
eng_text_tokenized, eng_text_tokenizer = tokenize(english_sentences)
print('Maximum length spanish sentence: {}'.format(len(max(spa_text_tokenized,key=len))))
print('Maximum length english sentence: {}'.format(len(max(eng_text_tokenized,key=len))))
# Check the length
spanish_vocab = len(spa_text_tokenizer.word_index) + 1
english_vocab = len(eng_text_tokenizer.word_index) + 1
print("Spanish vocabulary is of {} unique words".format(spanish_vocab))
print("English vocabulary is of {} unique words".format(english_vocab))
The code above prints the following results

According to the previous code , The maximum length of a Spanish sentence is 12 Word , The maximum length of an English sentence is 6 Word . Here we can see the advantages of using the codec model . In the past, we had limitations in dealing with equal length sentences , So we need to fill in English sentences with 12, Now it's only half of it . therefore , what's more , It also reduces LSTM Time steps , Reduced computing requirements and complexity .
We use padding to make the maximum length of sentences in each language equal .
max_spanish_len = int(len(max(spa_text_tokenized,key=len)))
max_english_len = int(len(max(eng_text_tokenized,key=len)))
spa_pad_sentence = pad_sequences(spa_text_tokenized, max_spanish_len, padding = "post")
eng_pad_sentence = pad_sequences(eng_text_tokenized, max_english_len, padding = "post")
# restore
spa_pad_sentence = spa_pad_sentence.reshape(*spa_pad_sentence.shape, 1)
eng_pad_sentence = eng_pad_sentence.reshape(*eng_pad_sentence.shape, 1)
Now we have the data , Let's build a model .
2. Model development
In the next section , We're going to create models , And in python Each layer added is explained in the code .
2.1- Encoder
The first layer we define is the image embedding layer . So , We must first add an input layer , The only parameter to consider here is “shape”, This is the maximum length of a Spanish sentence , In our case, it's 12.
Then we connect it to the embedded layer , The parameters to be considered here are “input_dim”( The length of the Spanish vocabulary ) and “output_dim”( The shape of the embedded vector ). This layer converts Spanish words into vectors that output dimension shapes .
The concept behind this is to extract the meaning of words in the form of spatial representation , Each of these dimensions is a feature that defines a word . for example ,“sol” Convert to shape to 128 Vector . The higher the output dimension , The more semantic meaning is extracted from each word , But the more computing and processing time it takes . We also need to find a balance between speed and performance .
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
Next , We're going to add a size of 64 Of LSTM layer . Even if LSTM Each time step of the output of a hidden vector , We'll focus on the last one , So the parameter return_sequences yes 'False'. We will see LSTM How the layer in the decoder return_sequences=True Working in the case of .
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
encoder = LSTM(64, return_sequences=False)(embedding)
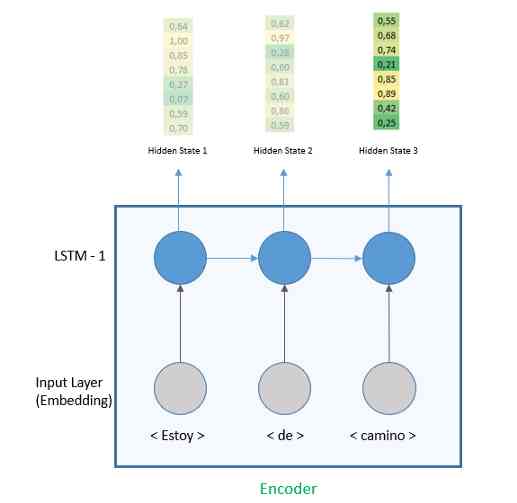
When the return sequence is 'False' when , The output is the last hidden state .
2.2- decoder
The output of the encoder layer will be the hidden state of the last time step . And then we need to put this vector into the decoder . Let's take a closer look at the decoder part , And understand how it works .
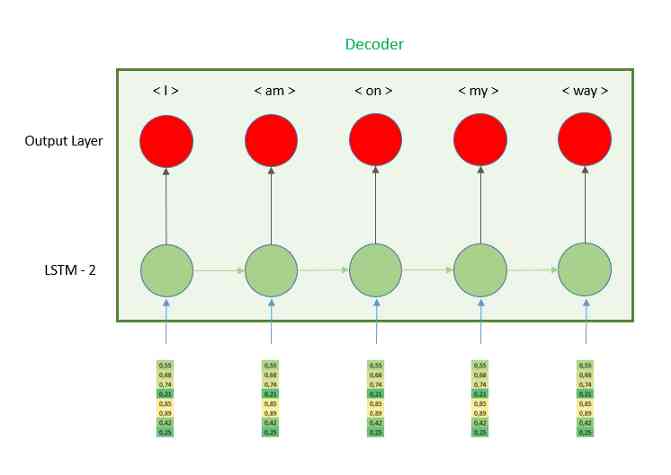
As we can see in the image , The hidden vector is repeated n Time , therefore LSTM Each time step of the receives the same vector . To make every time step have the same vector , We need to use layers RepeatVector, Because its name means its role is to repeat the vector it receives , The only parameter we need to define is n, Repeat the number . This number is equal to the number of time steps in the decoder part , In other words, the maximum length of an English sentence 6.
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
encoder = LSTM(64, return_sequences=False)(embedding)
r_vec = RepeatVector(max_english_len)(encoder)
Once we're ready to enter , We will continue to decode . It also works LSTM Layer built , The difference is in the parameters return_sequences, In this case 'True'. What is this parameter used for ? In the encoder section , We only expect one vector in the last time step , And ignore all the other vectors , Here we expect each time step to have an output vector , In this way, the full connection layer can predict .
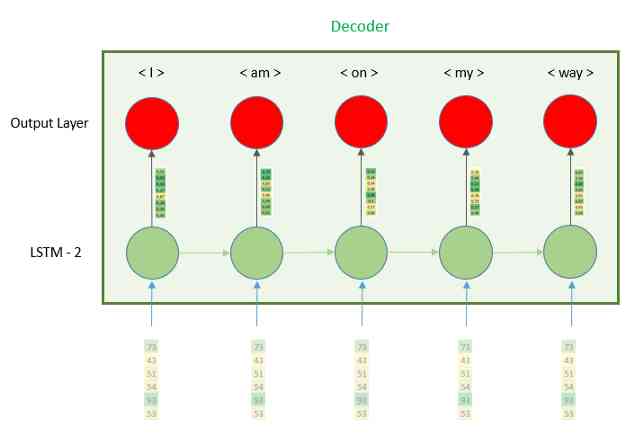
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
encoder = LSTM(64, return_sequences=False)(embedding)
r_vec = RepeatVector(max_english_len)(encoder)
decoder = LSTM(64, return_sequences=True, dropout=0.2)(r_vec)
We have the last step , Predict the translated words . So , We need to use the full connectivity layer . The parameter we need to define is the number of elements , This unit number is the shape of the output vector , It needs to be the same length as the English word . Why? ? The values of this vector are all close to zero , Except that one of the units is close to 1. Then we need to output 1 The index of the unit is mapped to the dictionary , In the dictionary, we map each unit to a word .
for example , If the input is a word ‘sun’, And the output is a vector , All of them are zero , And then the unit 472 yes 1, So we map the index to a dictionary that contains English words , And get the value ‘sun’.
We just saw how to apply the full connectivity layer to predict a word , But how do we predict the whole sentence ? Because we use return_sequence=True, therefore LSTM The layer outputs a vector at each time step , So we need to apply the full connectivity layer explained earlier in each time step , Let them predict one word at a time .
So ,Keras We developed a program called TimeDistributed Specific layers of , It applies the same full connectivity layer to each time step .
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
encoder = LSTM(64, return_sequences=False)(embedding)
r_vec = RepeatVector(max_english_len)(encoder)
decoder = LSTM(64, return_sequences=True, dropout=0.2)(r_vec)
logits = TimeDistributed(Dense(english_vocab))(decoder)
Last , We create the model and add a loss function .
enc_dec_model = Model(input_sequence, Activation('softmax')(logits))
enc_dec_model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(1e-3),
metrics=['accuracy'])
enc_dec_model.summary()
Once we define the model , We can train it .
model_results = enc_dec_model.fit(spa_pad_sentence, eng_pad_sentence, batch_size=30, epochs=100)
When the model is trained , We can translate for the first time . You can also find functions “logits_to_sentence”, It maps the output of the full connectivity layer to English vocabulary .
def logits_to_sentence(logits, tokenizer):
index_to_words = {idx: word for word, idx in tokenizer.word_index.items()}
index_to_words[0] = '<empty>'
return ' '.join([index_to_words[prediction] for prediction in np.argmax(logits, 1)])
index = 14
print("The english sentence is: {}".format(english_sentences[index]))
print("The spanish sentence is: {}".format(spanish_sentences[index]))
print('The predicted sentence is :')
print(logits_to_sentence(enc_dec_model.predict(spa_pad_sentence[index:index+1])[0], eng_text_tokenizer))
Conclusion
The codec architecture allows different input and output sequence lengths . First , We use an embedded layer to create a spatial representation of words , And input it into LSTM layer , Because we only focus on the output of the last time step , We use return_sequences=False.
This output vector needs to be repeated the same number of times as the decoder part , We use RepeatVector layer . The decoder will use LSTM, Parameters return_sequences=True, So the output of each time step is passed to the full connectivity layer .
Although this model is a good improvement from the previous tutorial , We can still improve accuracy . We can add a layer of encoder and decoder to one layer . We can also use the pre trained embedding layer , such as word2vec or Glove. Last , We can use the attention mechanism , This is a major improvement in the field of natural language processing . We'll introduce this concept in the next tutorial .
appendix : Codec without repetition vector
In this tutorial , We learned how to use RepeatVector Layer building encoder - decoder . There's a second option , We use the output of the model as input to the next time step , Instead of repeating hidden vectors , As shown in the figure .
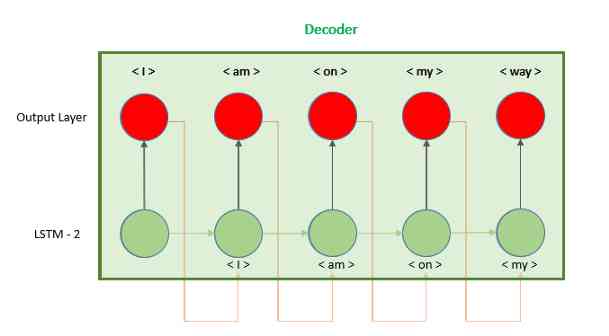
The code to implement this model can be found in Keras Found in document , It needs to be right Keras The library has a deeper understanding , And development is much more complicated :https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
Link to the original text :https://towardsdatascience.com/how-to-build-an-encoder-decoder-translation-model-using-lstm-with-python-and-keras-a31e9d864b9b
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
- React design pattern: in depth understanding of react & Redux principle
- Existence judgment in structured data
- PN8162 20W PD快充芯片,PD快充充电器方案
- Thoughts on interview of Ali CCO project team
- IPFS/Filecoin合法性:保护个人隐私不被泄露
- How to select the evaluation index of classification model
- Python Jieba segmentation (stuttering segmentation), extracting words, loading words, modifying word frequency, defining thesaurus
- Face to face Manual Chapter 16: explanation and implementation of fair lock of code peasant association lock and reentrantlock
- [JMeter] two ways to realize interface Association: regular representation extractor and JSON extractor
- Skywalking series blog 1 - install stand-alone skywalking
猜你喜欢

PHP应用对接Justswap专用开发包【JustSwap.PHP】

Python saves the list data
CCR炒币机器人:“比特币”数字货币的大佬,你不得不了解的知识
多机器人行情共享解决方案
NLP model Bert: from introduction to mastery (2)
It's so embarrassing, fans broke ten thousand, used for a year!
keras model.compile Loss function and optimizer
With the advent of tensorflow 2.0, can pytoch still shake the status of big brother?
至联云分享:IPFS/Filecoin值不值得投资?
关于Kubernetes 与 OAM 构建统一、标准化的应用管理平台知识!(附网盘链接)
随机推荐
vue任意关系组件通信与跨组件监听状态 vue-communication
Working principle of gradient descent algorithm in machine learning
6.5 request to view name translator (in-depth analysis of SSM and project practice)
It's so embarrassing, fans broke ten thousand, used for a year!
前端都应懂的入门基础-github基础
每个前端工程师都应该懂的前端性能优化总结:
6.1.2 handlermapping mapping processor (2) (in-depth analysis of SSM and project practice)
git rebase的時候捅婁子了,怎麼辦?線上等……
Analysis of react high order components
Vue.js Mobile end left slide delete component
Using consult to realize service discovery: instance ID customization
Nodejs crawler captures ancient books and records, a total of 16000 pages, experience summary and project sharing
Five vuex plug-ins for your next vuejs project
Brief introduction of TF flags
What problems can clean architecture solve? - jbogard
ES6学习笔记(五):轻松了解ES6的内置扩展对象
I've been rejected by the product manager. Why don't you know
Network security engineer Demo: the original * * is to get your computer administrator rights! 【***】
This article will introduce you to jest unit test
在大规模 Kubernetes 集群上实现高 SLO 的方法