当前位置:网站首页>Music generation through deep neural network
Music generation through deep neural network
2020-11-06 01:28:00 【Artificial intelligence meets panchuang】
author |Ramya Vidiyala compile |VK source |Towards Data Science
Deep learning has improved many aspects of our life , Whether it's obvious or subtle . Deep learning in the movie recommendation system 、 Spam detection and computer vision play a key role in the process .
Although the discussion about deep learning as a black box and the difficulty of training is still going on , But in medicine 、 There is a huge potential in many areas such as virtual assistants and e-commerce .
At the intersection of art and Technology , Deep learning can work . To further explore the idea , In this paper , We're going to look at the process of generating machine learning music through a deep learning process , Many people think that this field is beyond the scope of machines ( It's also another interesting area of intense debate !).
Catalog
-
The musical representation of machine learning model
-
Music dataset
-
Data processing
-
Model selection
-
RNN
-
Time distribution, full connection layer
-
state
-
Dropout layer
-
Softmax layer
-
Optimizer
-
Music generation
-
Abstract
The musical representation of machine learning model
We will use ABC music notation .ABC Notation is a shorthand notation , It uses letters a To G To show notes , And use other elements to place the added value . These added values include note length 、 Keys and decorations .
This form of symbol begins as a kind of ASCII Character set code , To facilitate online music sharing , Add a new and simple language for software developers , Easy to use . Here are ABC music notation .
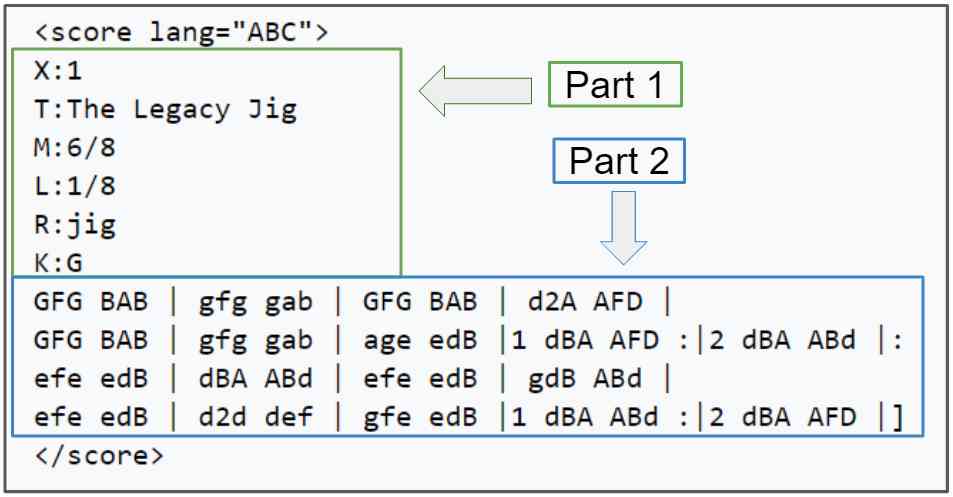
The notation of music is No 1 The lines in the section show a letter followed by a colon . These represent all aspects of the tune , For example, the index when there are multiple tunes in the file (X:)、 title (T:)、 Time signature (M:)、 Default note length (L:)、 The type of melody (R:) Sum key (K:). The key name is followed by the melody .
Music dataset
In this paper , We're going to use the Nottingham music database ABC Open source data provided on the . It contains 1000 Many folk tunes , Most of them have been converted into ABC Symbol :http://abc.sourceforge.net/NMD/
Data processing
Data is currently in a character based classification format . In the data processing phase , We need to convert the data to an integer based numeric format , Prepare for the work of neural networks .
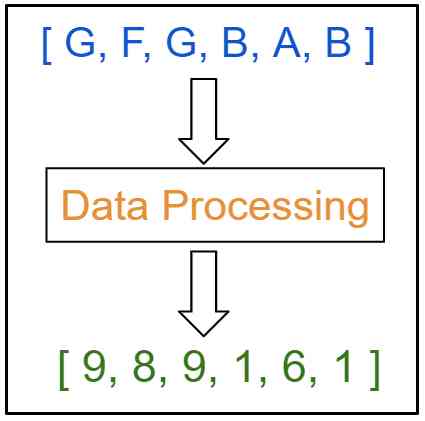
Here each character is mapped to a unique integer . This can be done by using a single line of code .“text” Variables are input data .
char_to_idx = { ch: i for (i, ch) in enumerate(sorted(list(set(text)))) }
To train the model , We use vocab Convert the entire text data into digital format .
T = np.asarray([char_to_idx[c] for c in text], dtype=np.int32)
Machine learning music generation model selection
In the traditional machine learning model , We can't store the previous phase of the model . However , We can use cyclic neural networks ( Often referred to as RNN) To store the previous stages .
RNN There's a repeating module , It takes input from the previous level , And take its output as the input of the next level . However ,RNN Only the most recent information can be retained , So our network needs more memory to learn about long-term dependencies . This is the long-term and short-term memory network (LSTMs).
LSTMs yes RNNs A special case of , Have and RNNs The same chain structure , But there are different repeat module structures .
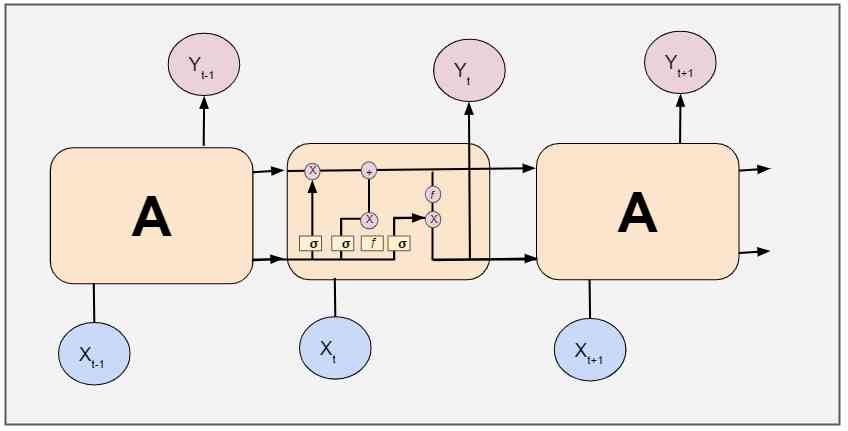
Use here RNN Because :
-
The length of the data doesn't need to be fixed . For each input , The data length may vary .
-
You can store sequences .
-
Various combinations of input and output sequence lengths can be used .
Except for the general RNN, We will also customize it to fit our use cases by adding some adjustments . We will use “ Character level RNN”. In the character RNNs in , Input 、 Both the output character and the output are in the form of conversion .

RNN
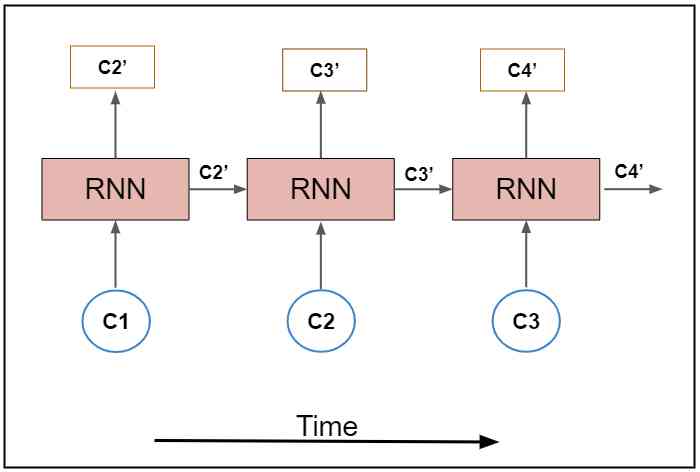
Because we need to generate output on each timestamp , So we're going to use a lot of RNN. In order to achieve multiple RNN, We need to put the parameters “return_sequences” Set to true, To generate each character on each timestamp . By looking at the figure below 5, You can understand it better .
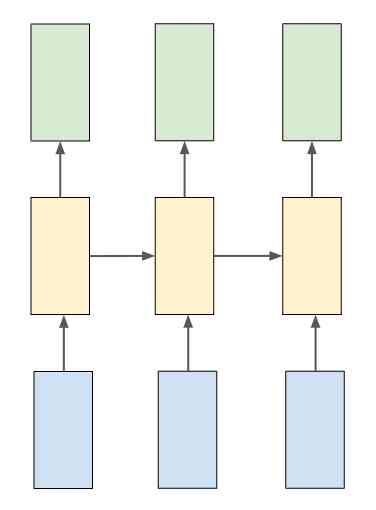
In the diagram above , Blue units are input units , Yellow units are hidden units , Green units are output units . This is a lot of RNN A brief overview of . In order to know more about RNN Sequence , Here's a useful resource :http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Time distribution, full connection layer
To handle the output of each timestamp , We created a full connectivity layer of time distribution . To achieve this , We create a time distributed full connectivity layer on top of the output generated by each timestamp .
state
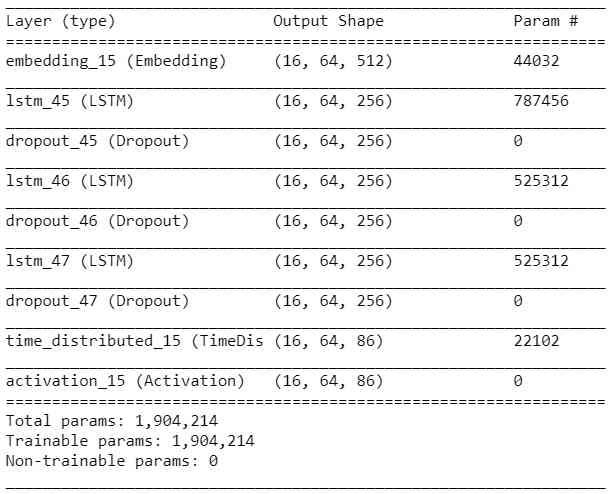
By changing the parameters stateful Set to true, The output of the batch is passed as input to the next batch . After combining all the features , Our model will look like the following figure 6 The overview shown .
The code snippet for the model architecture is as follows :
model = Sequential()
model.add(Embedding(vocab_size, 512, batch_input_shape=(BATCH_SIZE, SEQ_LENGTH)))
for i in range(3):
model.add(LSTM(256, return_sequences=True, stateful=True))
model.add(Dropout(0.2))
model.add(TimeDistributed(Dense(vocab_size)))
model.add(Activation('softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
I strongly recommend that you use layers to improve performance .
Dropout layer
Dropout Layer is a regularization technique , In the process of training , Zero a small part of the input unit at each update , To prevent over fitting .
Softmax layer
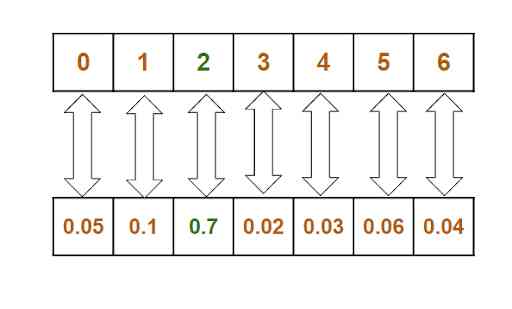
The generation of music is a multi class classification problem , Each class is the only character in the input data . therefore , We used a softmax layer , The classification cross entropy is taken as a loss function .
This layer gives the probability of each class . From the probability list , We choose the one with the highest probability .
Optimizer
To optimize our model , We use adaptive moment estimation , Also known as Adam, Because it is RNN A good choice for .
Making music
up to now , We created one RNN Model , And train them according to their data . The model learns the pattern of input data in the training stage . We call this model “ Training models ”.
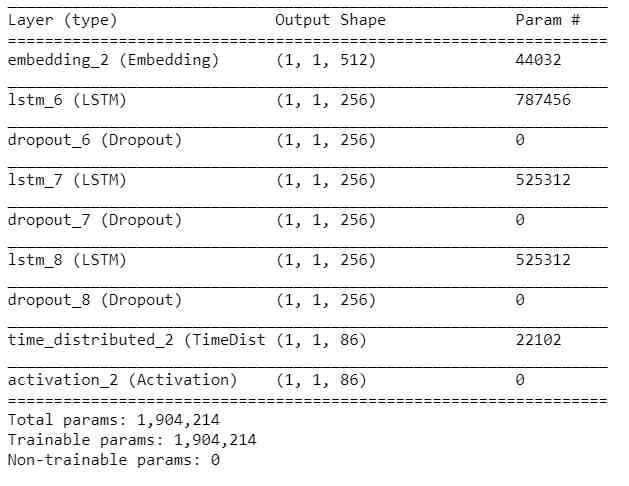
The input size used in the training model is the batch size . For music produced by machine learning , The input size is a single character . So we created a new model , It and "" Training models "" be similar , But the size of the input character is (1,1). In this new model , We load weights from the training model to copy the features of the training model .
model2 = Sequential()
model2.add(Embedding(vocab_size, 512, batch_input_shape=(1,1)))
for i in range(3):
model2.add(LSTM(256, return_sequences=True, stateful=True))
model2.add(Dropout(0.2))
model2.add(TimeDistributed(Dense(vocab_size)))
model2.add(Activation(‘softmax’))
We load the weight of the trained model into the new model . This can be done by using a single line of code .
model2.load_weights(os.path.join(MODEL_DIR,‘weights.100.h5’.format(epoch)))
model2.summary()
In the production of music , Randomly select the first character from the unique character set , Use the previously generated character to generate the next character , And so on . With this structure , We have music .

Here's a snippet of code to help us do this .
sampled = []
for i in range(1024):
batch = np.zeros((1, 1))
if sampled:
batch[0, 0] = sampled[-1]
else:
batch[0, 0] = np.random.randint(vocab_size)
result = model2.predict_on_batch(batch).ravel()
sample = np.random.choice(range(vocab_size), p=result)
sampled.append(sample)
print("sampled")
print(sampled)
print(''.join(idx_to_char[c] for c in sampled))
Here are some of the generated music clips :
We use what is called LSTMs The machine learning neural network for generating these pleasant music samples . Every piece is different , But similar to the training data . These melodies can be used for many purposes :
-
Enhance the creativity of artists through inspiration
-
As a productivity tool for developing new ideas
-
As an adjunct to the artist's work
-
Finish the unfinished work
-
As an independent piece of music
however , This model needs to be improved . Our training materials only have one instrument , The piano . One way we can enhance training data is to add music from a variety of instruments . Another way is to increase the genre of music 、 Rhythm and rhythm characteristics .
at present , Our pattern produces some false notes , Music is no exception . We can reduce these errors and improve the quality of music by increasing the training data set .
summary
In this article , We studied how to deal with music used with neural networks , Deep learning models such as RNN and LSTMs How it works , We also discussed how to adjust the model to produce music . We can apply these concepts to any other system , In these systems , We can generate other forms of art , Including the creation of landscapes or portraits .
Thanks for reading ! If you want to experience this custom dataset for yourself , You can download annotated data here , And in Github Check my code on :https://github.com/RamyaVidiyala/Generate-Music-Using-Neural-Networks
Link to the original text :https://towardsdatascience.com/music-generation-through-deep-neural-networks-21d7bd81496e
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets panchuang]所创,转载请带上原文链接,感谢
边栏推荐
- 2019年的一个小目标,成为csdn的博客专家,纪念一下
- [event center azure event hub] interpretation of error information found in event hub logs
- Network security engineer Demo: the original * * is to get your computer administrator rights! 【***】
- 如何玩转sortablejs-vuedraggable实现表单嵌套拖拽功能
- Linked blocking Queue Analysis of blocking queue
- Mongodb (from 0 to 1), 11 days mongodb primary to intermediate advanced secret
- Installing the consult cluster
- 带你学习ES5中新增的方法
- 全球疫情加速互联网企业转型,区块链会是解药吗?
- Vue.js Mobile end left slide delete component
猜你喜欢
Do not understand UML class diagram? Take a look at this edition of rural love class diagram, a learn!
How to use Python 2.7 after installing anaconda3?
Tool class under JUC package, its name is locksupport! Did you make it?

从海外进军中国,Rancher要执容器云市场牛耳 | 爱分析调研
一篇文章带你了解HTML表格及其主要属性介绍
NLP model Bert: from introduction to mastery (1)

I've been rejected by the product manager. Why don't you know
Filecoin最新动态 完成重大升级 已实现四大项目进展!
零基础打造一款属于自己的网页搜索引擎
Grouping operation aligned with specified datum
随机推荐
I'm afraid that the spread sequence calculation of arbitrage strategy is not as simple as you think
In order to save money, I learned PHP in one day!
Windows 10 tensorflow (2) regression analysis of principles, deep learning framework (gradient descent method to solve regression parameters)
Skywalking series blog 1 - install stand-alone skywalking
Do not understand UML class diagram? Take a look at this edition of rural love class diagram, a learn!
Subordination judgment in structured data
Linked blocking Queue Analysis of blocking queue
6.4 viewresolver view parser (in-depth analysis of SSM and project practice)
Natural language processing - wrong word recognition (based on Python) kenlm, pycorrector
How long does it take you to work out an object-oriented programming interview question from Ali school?
2019年的一个小目标,成为csdn的博客专家,纪念一下
教你轻松搞懂vue-codemirror的基本用法:主要实现代码编辑、验证提示、代码格式化
H5 makes its own video player (JS Part 2)
Advanced Vue component pattern (3)
一篇文章带你了解CSS 分页实例
A course on word embedding
阿里云Q2营收破纪录背后,云的打开方式正在重塑
Relationship between business policies, business rules, business processes and business master data - modern analysis
Summary of common algorithms of binary tree
中小微企业选择共享办公室怎么样?