当前位置:网站首页>How to encapsulate distributed locks more elegantly
How to encapsulate distributed locks more elegantly
2020-11-06 01:19:00 【Yin Jihuan】
Distributed locks usually have many choices , be based on Redis Of , be based on Zookeeper Of , Based on database and so on .
Redis For caching data , It's used in projects , So use Redis There will be a little more distributed locks .
If you use Redis To make a lock , You can use open source solutions directly , such as redisson.
The most common uses are as follows :
RLock lock = redisson.getLock("anyLock");lock.lock();run();lock.unlock();
Get lock object , call lock() Lock , Execute business logic , call unlock() Release the lock .
Although the framework provides a very simple way to use it , But we still need to do a layer of packaging for the lock . The purpose of packaging is to improve scalability and ease of use .
Abstract interface
If we use it directly redisson The native API Make locks , So many places will appear RLock Related code , And then one day , For some reason , The lock needs to be replaced , At this time, the scope of change is relatively large . Each uses RLock Everything has to be changed .
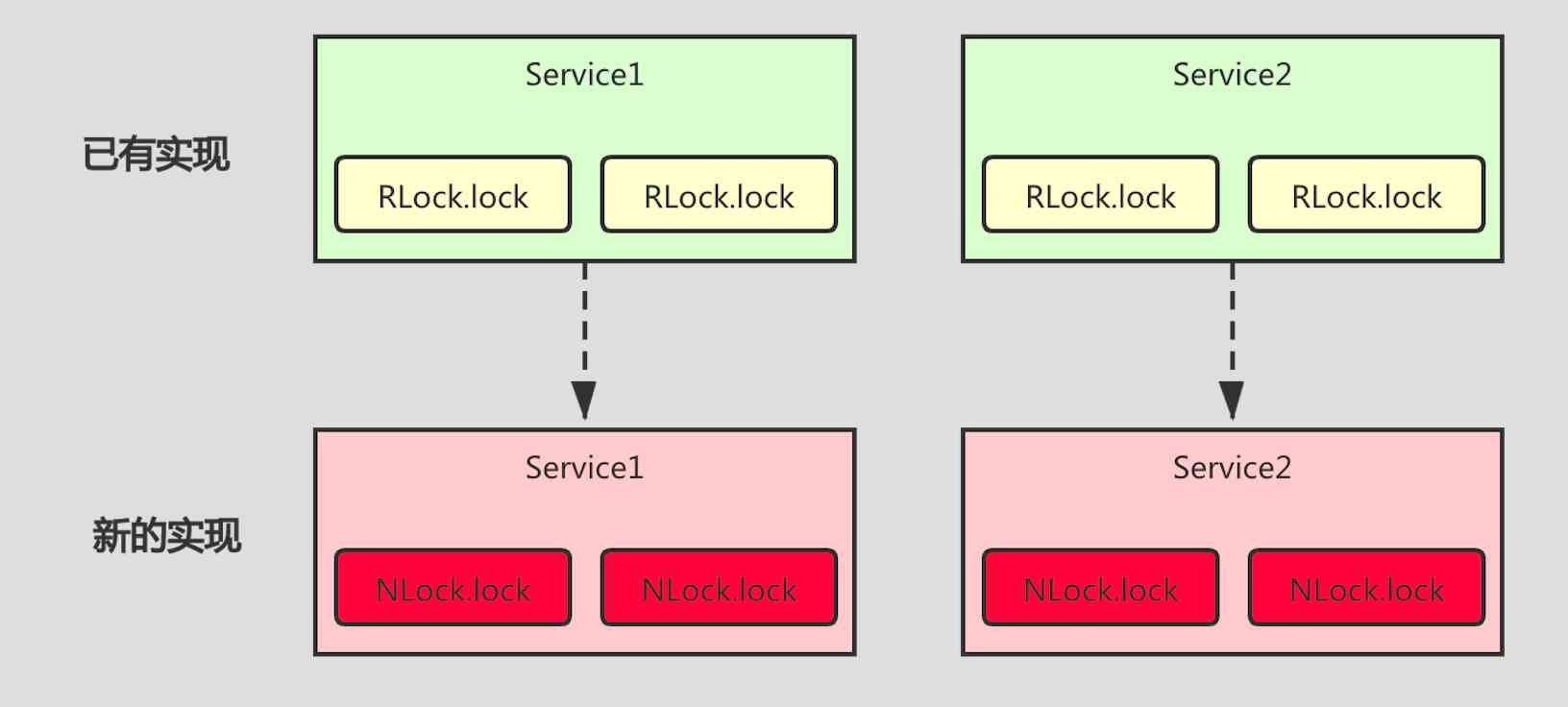
Here's the picture : quite a lot Service Are used to RLock.lock() Method , When we need to replace locks , All the classes and methods involved have to be modified , The change points are shown in the red section .
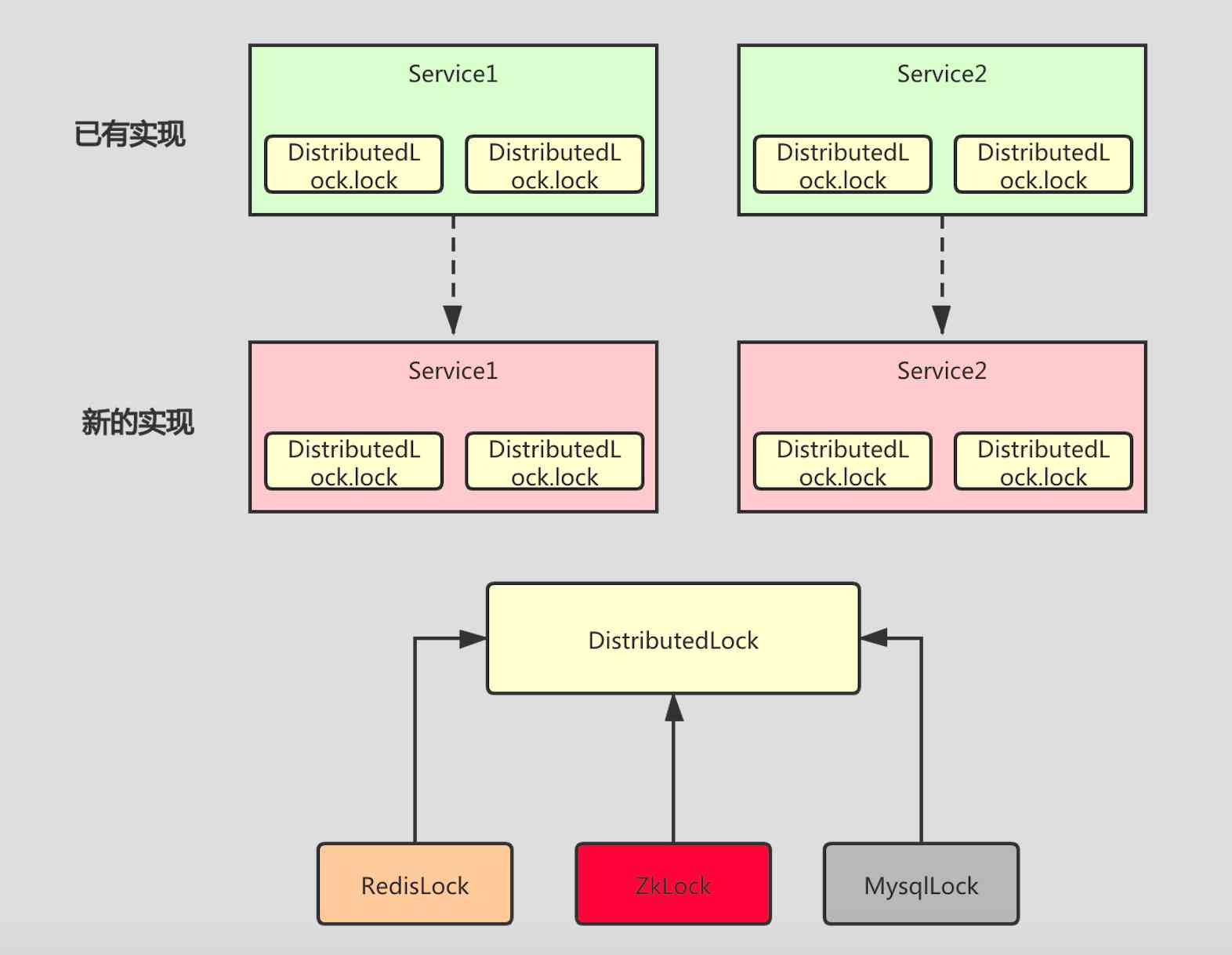
So we need to do a layer of abstraction , You can define a DistributedLock Interface to provide lock related capabilities , Provides multiple implementations , This makes it easy to replace and expand .
Here's the picture : Every Service It's all for DistributedLock Interface to lock , When we need to replace the lock implementation , It doesn't need to be changed , Just replace DistributedLock The realization of .
Automatic release
Automatic release refers to after locking , After the execution of business logic, the lock needs to be closed automatically . In front of Redisson We need to manually call unlock() To release the lock held .
Of course Redisson It also provides the function of timeout release , Under normal circumstances, the lock must be released after the completion of business execution , The next request for the same lock can continue to be processed .
The most common problem with manually releasing resources is forgetting to release , So in JDK7 Introduced in try-with-resources To release resources automatically , I believe everyone is familiar with .
So when we encapsulate , Try not to let the user release it manually , Reduce the probability of error . For those with results, we can use Supplier To deliver your logic , For those that do not return results, you can use Runnable To deliver your logic .
/*** Lock* @param key lock Key* @param waitTime Try to lock , Waiting time (ms)* @param leaseTime Failure time after locking (ms)* @param success The logic of successful lock execution* @param fail Logic of lock failure execution* @return*/<T> T lock(String key, int waitTime, int leaseTime, Supplier<T> success, Supplier<T> fail);
Use :
String result = distributedLock.lock("1001", 1000, () -> {System.out.println(" Came in ....");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}return "success";}, () -> {System.out.println(" Locking failed ....");return "fail";});
Disaster recovery
Another issue to note is the availability of locks , In case the corresponding Redis Something is wrong. , This time to lock is bound to fail , If nothing is done , It will affect normal business operations , Make the business unavailable .
In addition to realizing Redis Outside the lock of , Other locks can be implemented , Like database locks . When Redis When a lock is not available, it is demoted to a database lock , Although performance has an impact , But it doesn't affect the business .
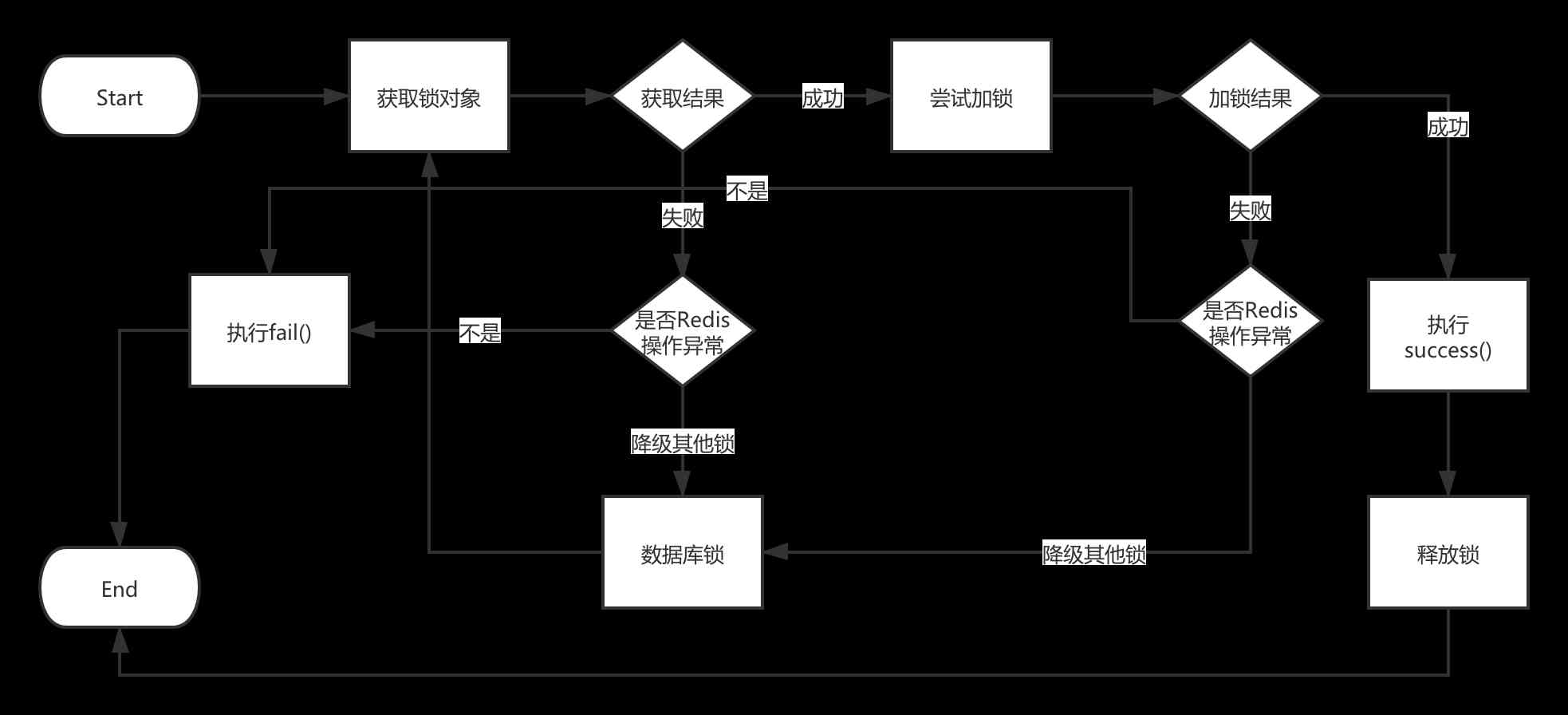
If the database lock is not available ( Digression : It's very unlikely that everything will be available ), It's better to let business operations fail . Because we use the lock scene , It must be to prevent problems caused by concurrent scenarios , If the lock is not available , You're going to spend abnormally , Let business operations continue , There may be business problems without locking .
Of course, monitoring is also very necessary ,Redis, Database monitoring . When something goes wrong , There's a timely intervention .
Monitoring system
Redis, database ,Zookeeper The monitoring of these middleware supporting distributed implementation is definitely necessary . Another monitoring is the fine-grained monitoring of the lock action .
For example, the time to lock , Time to release lock , Time to execute business in a lock , Lock concurrency , Number of executions , The number of lock failures .
These data indicators are very important , It can help you find problems in time . such as 10 Hundreds of lock failures per second , All demoted to database locks , This is when you get an alert , It's easy to see Redis Something is wrong. , Timely solution .
The way of monitoring is just as casual , Every company is different , You can expose data to Prometheus Grab , You can also integrate Cat Do a good job , As long as you can monitor , Just give an alarm .
About author : Yin Jihuan , Simple technology enthusiasts ,《Spring Cloud Microservices - Full stack technology and case analysis 》, 《Spring Cloud Microservices introduction Actual combat and advanced 》 author , official account Ape world Originator .
I have compiled a complete set of learning materials , Those who are interested can search through wechat 「 Ape world 」, Reply key 「 Learning materials 」 Get what I've sorted out Spring Cloud,Spring Cloud Alibaba,Sharding-JDBC Sub database and sub table , Task scheduling framework XXL-JOB,MongoDB, Reptiles and other related information .

版权声明
本文为[Yin Jihuan]所创,转载请带上原文链接,感谢
边栏推荐
- PHP应用对接Justswap专用开发包【JustSwap.PHP】
- 加速「全民直播」洪流,如何攻克延时、卡顿、高并发难题?
- 教你轻松搞懂vue-codemirror的基本用法:主要实现代码编辑、验证提示、代码格式化
- The difference between Es5 class and ES6 class
- After reading this article, I understand a lot of webpack scaffolding
- 钻石标准--Diamond Standard
- ES6学习笔记(五):轻松了解ES6的内置扩展对象
- 连肝三个通宵,JVM77道高频面试题详细分析,就这?
- WeihanLi.Npoi 1.11.0/1.12.0 Release Notes
- 多机器人行情共享解决方案
猜你喜欢

从海外进军中国,Rancher要执容器云市场牛耳 | 爱分析调研
阿里云Q2营收破纪录背后,云的打开方式正在重塑
在大规模 Kubernetes 集群上实现高 SLO 的方法

How to demote a domain controller in Windows Server 2012 and later
Basic principle and application of iptables

Existence judgment in structured data
如何将数据变成资产?吸引数据科学家

Architecture article collection
制造和新的自动化技术是什么?
Character string and memory operation function in C language
随机推荐
The practice of the architecture of Internet public opinion system
PN8162 20W PD快充芯片,PD快充充电器方案
In order to save money, I learned PHP in one day!
C language 100 question set 004 - statistics of the number of people of all ages
条码生成软件如何隐藏部分条码文字
Listening to silent words: hand in hand teaching you sign language recognition with modelarts
After brushing leetcode's linked list topic, I found a secret!
Computer TCP / IP interview 10 even asked, how many can you withstand?
Dapr實現分散式有狀態服務的細節
Character string and memory operation function in C language
加速「全民直播」洪流,如何攻克延时、卡顿、高并发难题?
Working principle of gradient descent algorithm in machine learning
PHP应用对接Justswap专用开发包【JustSwap.PHP】
The difference between Es5 class and ES6 class
Python3 e-learning case 4: writing web proxy
大数据应用的重要性体现在方方面面
Subordination judgment in structured data
带你学习ES5中新增的方法
DTU连接经常遇到的问题有哪些
人工智能学什么课程?它将替代人类工作?