当前位置:网站首页>How to customize sorting for pandas dataframe
How to customize sorting for pandas dataframe
2020-11-06 01:28:00 【Artificial intelligence meets pioneer】
author |B. Chen compile |VK source |Towards Data Science

Pandas DataFrame There's a built-in method sort_values(), You can sort values according to a given variable . The method itself is quite simple to use , But it doesn't work with custom sort , for example ,
-
t T-shirt size :XS、S、M、L and XL
-
month : January 、 February 、 March 、 April, etc
-
What day : Monday 、 Tuesday 、 Wednesday 、 Thursday 、 Friday 、 Saturday and Sunday .
In this paper , We will learn how to deal with Pandas DataFrame Custom sort .
Please check my Github repo To get the source code :https://github.com/BindiChen/machine-learning/blob/master/data-analysis/017-pandas-custom-sort/pandas-custom-sort.ipynb
problem
Suppose we have a data set about clothing stores :
df = pd.DataFrame({
'cloth_id': [1001, 1002, 1003, 1004, 1005, 1006],
'size': ['S', 'XL', 'M', 'XS', 'L', 'S'],
})
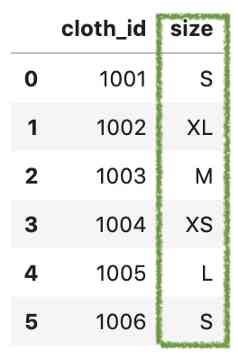
We can see , Each piece of cloth has a size value , The data should be sorted in the following order :
-
XS For extra large
-
S For Trumpet
-
M For medium
-
L For big
-
XL For extra large
however , When calling sort_values('size') when , You will get the following output .

The output is not what we want , But it's technically correct . actually ,sort_values() It is to sort numerical data in numerical order , Sort the object data in alphabetical order .
Here are two common solutions :
-
Create a new column for a custom sort
-
Use CategoricalDtype Cast data to an ordered category type
Create a new column for a custom sort
In this solution , A mapping data frame is needed to represent a custom sort , Then create a new column from the map , Finally, we can sort the data by new columns . Let's take an example to see how this works .
First , Let's create a mapping data frame to represent a custom sort .
df_mapping = pd.DataFrame({
'size': ['XS', 'S', 'M', 'L', 'XL'],
})
sort_mapping = df_mapping.reset_index().set_index('size')

after , Use sort_mapping Create a new column with the mapping values in size_num.
df['size_num'] = df['size'].map(sort_mapping['index'])
Last , Sort values by new column size .
df.sort_values('size_num')
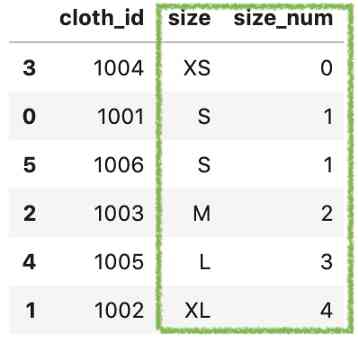
This, of course, is our job . But it creates an alternate column , Efficiency may be reduced when dealing with large data sets .
We can use CategoricalDtype To solve this problem more effectively .
Use CategoricalDtype Cast data to an ordered category type
CategoricalDtype Is a type of categorical data with a category and order [1]. It's very useful for creating custom sorts [2]. Let's take an example to see how this works .
First , Let's import CategoricalDtype.
from pandas.api.types import CategoricalDtype
then , Create a custom category type cat_size_order
-
The first parameter is set to ['XS'、'S'、'M'、'L'、'XL'] As a unique value of size .
-
The second parameter ordered=True, Think of this variable as ordered .
cat_size_order = CategoricalDtype(
['XS', 'S', 'M', 'L', 'XL'],
ordered=True
)
then , call astype(cat_size_order) Cast size data to a custom category type . By running df['size'], We can see size Column has been converted to a category type , The order is [XS<S<M<L<XL].
>>> df['size'] = df['size'].astype(cat_size_order)
>>> df['size']
0 S
1 XL
2 M
3 XS
4 L
5 S
Name: size, dtype: category
Categories (5, object): [XS < S < M < L < XL]
Last , We can call the same method to sort the values .
df.sort_values('size')
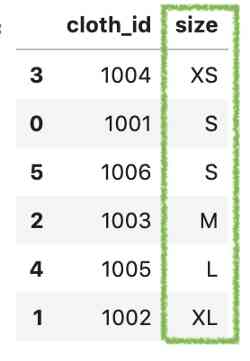
It works better . Let's see what the principle is .
Use cat Of codes Attribute access
Now? size Column has been converted to category type , We can use .cat Accessor to view the classification properties . Behind the scenes , It USES codes Property to represent the size of an ordered variable .
Let's create a new column code , So we can compare size and code values side by side .
df['codes'] = df['size'].cat.codes
df
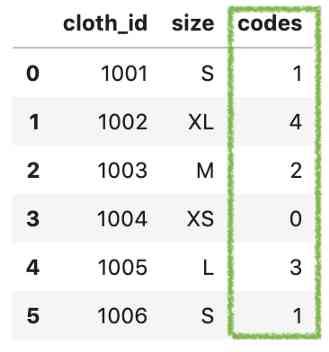
We can see XS、S、M、L and XL The codes for are 0、1、2、3、4 and 5.codes Is the actual value of the category . By running df.info(), We can see that it's actually int8.
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cloth_id 6 non-null int64
1 size 6 non-null category
2 codes 6 non-null int8
dtypes: category(1), int64(1), int8(1)
memory usage: 388.0 bytes
Sort by multiple variables
Next , Let's make things a little more complicated . here , We will sort the data frames by multiple variables .
df = pd.DataFrame({
'order_id': [1001, 1002, 1003, 1004, 1005, 1006, 1007],
'customer_id': [10, 12, 12, 12, 10, 10, 10],
'month': ['Feb', 'Jan', 'Jan', 'Feb', 'Feb', 'Jan', 'Feb'],
'day_of_week': ['Mon', 'Wed', 'Sun', 'Tue', 'Sat', 'Mon', 'Thu'],
})
Similarly , Let's create two custom category types cat_day_of_week and cat_month, And pass them on to astype().
cat_day_of_week = CategoricalDtype(
['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'],
ordered=True
)
cat_month = CategoricalDtype(
['Jan', 'Feb', 'Mar', 'Apr'],
ordered=True,
)
df['day_of_week'] = df['day_of_week'].astype(cat_day_of_week)
df['month'] = df['month'].astype(cat_month)
To sort by multiple variables , We just need to pass a list instead of sort_values(). for example , Press month and day_of_week Sort .
df.sort_values(['month', 'day_of_week'])
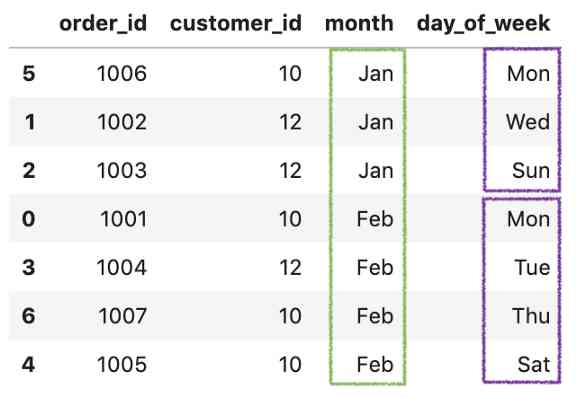
Press ustomer_id,month and day_of_week Sort .
df.sort_values(['customer_id', 'month', 'day_of_week'])
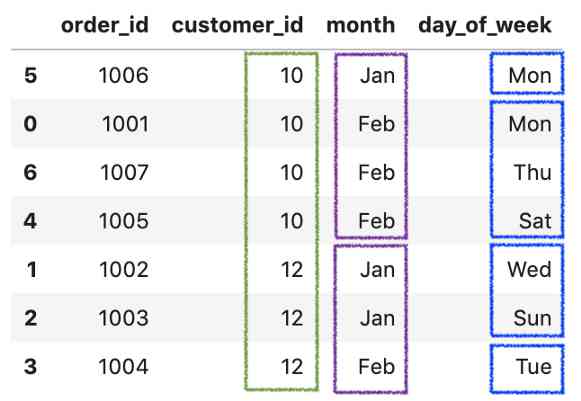
That's it , Thanks for reading .
In my, please Github Export the notebook to get the source code :https://github.com/BindiChen/machine-learning/blob/master/data-analysis/017-pandas-custom-sort/pandas-custom-sort.ipynb
Reference
- [1] Pandas.CategoricalDtype API(https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.CategoricalDtype.html)
- [2] Pandas Categorical CategoricalDtype tutorial (https://pandas.pydata.org/pandas-docs/stable/user_guide/categorical.html#categorical-categoricaldtype)
Link to the original text :https://towardsdatascience.com/how-to-do-a-custom-sort-on-pandas-dataframe-ac18e7ea5320
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
- keras model.compile Loss function and optimizer
- 2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
- 助力金融科技创新发展,ATFX走在行业最前列
- 6.6.1 localeresolver internationalization parser (1) (in-depth analysis of SSM and project practice)
- 6.5 request to view name translator (in-depth analysis of SSM and project practice)
- What problems can clean architecture solve? - jbogard
- EOS创始人BM: UE,UBI,URI有什么区别?
- Python crawler actual combat details: crawling home of pictures
- 用一个例子理解JS函数的底层处理机制
- 小程序入门到精通(二):了解小程序开发4个重要文件
猜你喜欢
Subordination judgment in structured data

Mac installation hanlp, and win installation and use
Windows 10 tensorflow (2) regression analysis of principles, deep learning framework (gradient descent method to solve regression parameters)

Arrangement of basic knowledge points

100元扫货阿里云是怎样的体验?
一篇文章带你了解CSS3图片边框
采购供应商系统是什么?采购供应商管理平台解决方案
![[JMeter] two ways to realize interface Association: regular representation extractor and JSON extractor](/img/cc/17b647d403c7a1c8deb581dcbbfc2f.jpg)
[JMeter] two ways to realize interface Association: regular representation extractor and JSON extractor
比特币一度突破14000美元,即将面临美国大选考验
2019年的一个小目标,成为csdn的博客专家,纪念一下
随机推荐
React design pattern: in depth understanding of react & Redux principle
What is the side effect free method? How to name it? - Mario
一篇文章带你了解CSS3圆角知识
EOS创始人BM: UE,UBI,URI有什么区别?
Solve the problem of database insert data garbled in PL / SQL developer
5.4 static resource mapping
每个前端工程师都应该懂的前端性能优化总结:
一篇文章带你了解CSS对齐方式
Windows 10 tensorflow (2) regression analysis of principles, deep learning framework (gradient descent method to solve regression parameters)
Word segmentation, naming subject recognition, part of speech and grammatical analysis in natural language processing
Do not understand UML class diagram? Take a look at this edition of rural love class diagram, a learn!
Filecoin主网上线以来Filecoin矿机扇区密封到底是什么意思
嘗試從零開始構建我的商城 (二) :使用JWT保護我們的資訊保安,完善Swagger配置
Vuejs development specification
Classical dynamic programming: complete knapsack problem
零基础打造一款属于自己的网页搜索引擎
Analysis of etcd core mechanism
教你轻松搞懂vue-codemirror的基本用法:主要实现代码编辑、验证提示、代码格式化
Python3 e-learning case 4: writing web proxy
Face to face Manual Chapter 16: explanation and implementation of fair lock of code peasant association lock and reentrantlock