当前位置:网站首页>A course on word embedding
A course on word embedding
2020-11-06 01:28:00 【Artificial intelligence meets pioneer】
author |Shraddha Anala compile |VK source |Towards Data Science
No matter who we are , read 、 understand 、 Communicating and ultimately generating new content is something we all need to do in our professional life .
When it comes to extracting useful features from a given text body , The process involved is a vector of continuous integers ( The word bag ) Comparison is fundamentally different . This is because the information in a sentence or text is encoded in a structured order , The semantic position of a word conveys the meaning of the text .
therefore , While maintaining the context of the text , The dual requirement of proper representation of data prompted me to learn and implement two different kinds of NLP Model to implement the task of text classification .
Word embedding is a dense representation of a single word in a text , Consider the context and other words associated with it .
Compared with the simple bag of words model , The real value vector can select dimension more effectively , More effectively capture the semantic relationship between words .
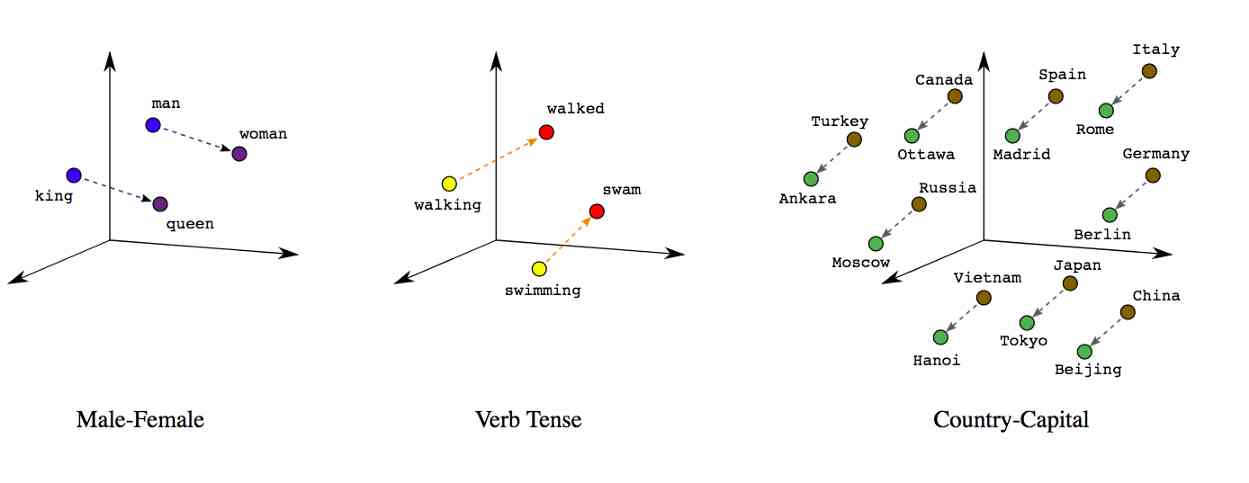
In short , Words with similar meanings or often appearing in similar contexts , Will have similar vector representations , It depends on the meaning of these words “ near ” or “ apart ” How far is it .
In this paper , I'm going to explore the embedding of two words -
- Train our own embeddedness
- In the process of the training GloVe Word embedding
Data sets
For this case study , We will use Kaggle Of Stack Overflow Data sets (https://www.kaggle.com/imoore/60k-stack-overflow-questions-with-quality-rate). This dataset contains 6 Ten thousand users asked questions on the website , The main task is to divide the problem into 3 class .
Now let's look at this multi category NLP The actual model of the project itself .
however , Before we start , Please make sure you have installed these packages / library .
pip install gensim # be used for NLP Preprocessing tasks
pip install keras # Embedded layer
1. Training word embedding
If you want to skip the explanation , Please visit the complete code of the first model :https://github.com/shraddha-an/nlp/blob/main/word_embedding_classification.ipynb
1) Data preprocessing
In the first model , We will train a neural network to learn embedding from our text corpus . To be specific , We will use Keras The library provides word identification and index for the embedded layer of neural network .
Before training our network , Some key parameters have to be determined . These include the size of the word or the number of unique words in the corpus and the dimension of the embedded vector .
The following links are data sets for training and testing . Now we're going to import them , Only problem and quality columns are kept for analysis :https://www.kaggle.com/imoore/60k-stack-overflow-questions-with-quality-rate
I also changed the column name and defined a function text_clean To clean up the problem .
# Import library
# Data manipulation / Handle
import pandas as pd, numpy as np
# visualization
import seaborn as sb, matplotlib.pyplot as plt
# NLP
import re
from nltk.corpus import stopwords
from gensim.utils import simple_preprocess
stop_words = set(stopwords.words('english'))
# Import dataset
dataset = pd.read_csv('train.csv')[['Body', 'Y']].rename(columns = {'Body': 'question', 'Y': 'category'})
ds = pd.read_csv('valid.csv')[['Body', 'Y']].rename(columns = {'Body': 'question', 'Y': 'category'})
# Clean up symbols and HTML label
symbols = re.compile(pattern = '[/<>(){}\[\]\|@,;]')
tags = ['href', 'http', 'https', 'www']
def text_clean(s: str) -> str:
s = symbols.sub(' ', s)
for i in tags:
s = s.replace(i, ' ')
return ' '.join(word for word in simple_preprocess(s) if not word in stop_words)
dataset.iloc[:, 0] = dataset.iloc[:, 0].apply(text_clean)
ds.iloc[:, 0] = ds.iloc[:, 0].apply(text_clean)
# Training and test sets
X_train, y_train = dataset.iloc[:, 0].values, dataset.iloc[:, 1].values.reshape(-1, 1)
X_test, y_test = ds.iloc[:, 0].values, ds.iloc[:, 1].values.reshape(-1, 1)
# one-hot code
from sklearn.preprocessing import OneHotEncoder as ohe
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer(transformers = [('one_hot_encoder', ohe(categories = 'auto'), [0])],
remainder = 'passthrough')
y_train = ct.fit_transform(y_train)
y_test = ct.transform(y_test)
# Set parameters
vocab_size = 2000
sequence_length = 100
If you look at the original dataset , You'll find that HTML The question contained in the tag , for example ,<p>…question</p>. Besides , There are also some words , Such as href,https etc. , Throughout the text , So I want to make sure that these two sets of unnecessary characters are removed from the text .
Gensim Of simple_preprocess Method returns a list of lowercase tags , Remove the accent .
Use it here apply Method will iterate through the preprocessing function to run each line , And return the output before moving on to the next line . Apply text preprocessing to training and test data sets .
Because there's a dependent variable in the vector 3 Categories , We will apply one-hot Encode and initialize some parameters for later use .
2) Tagging
Next , We will use Keras Tokenizer Class converts the problem of word composition into an array , Use their index to represent words .
therefore , We must first use fit_on_texts Method , Building an index vocabulary from the words that appear in the dataset .
After building a vocabulary , We use text_to_sequences Method converts a sentence into a list of numbers representing words .
pad_sequences Function ensures that all observations have the same length , Can be set to any number or the length of the longest question in the dataset .
We initialized it earlier vocab_size Parameters are just the size of our vocabulary ( For learning and indexing ).
# Keras The identifier of
from keras.preprocessing.text import Tokenizer
tk = Tokenizer(num_words = vocab_size)
tk.fit_on_texts(X_train)
X_train = tk.texts_to_sequences(X_train)
X_test = tk.texts_to_sequences(X_test)
# use 0 Fill in everything
from keras.preprocessing.sequence import pad_sequences
X_train_seq = pad_sequences(X_train, maxlen = sequence_length, padding = 'post')
X_test_seq = pad_sequences(X_test, maxlen = sequence_length, padding = 'post')
3) Training embedding layer
Last , In this part , We will build our model and our training , It consists of two main layers , An embedded layer will learn the training documents prepared above , And a dense output layer to implement the classification task .
The embedding layer will learn the representation of words , At the same time, train the neural network , A lot of text data is needed to provide accurate predictions . In our case ,45000 The training observations are sufficient to effectively learn the corpus and classify the quality of the problem . We will see from the indicators that .
# Training embedding layer and neural network
from keras.models import Sequential
from keras.layers import Embedding, Dense, Flatten
model = Sequential()
model.add(Embedding(input_dim = vocab_size, output_dim = 5, input_length = sequence_length))
model.add(Flatten())
model.add(Dense(units = 3, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
model.summary()
history = model.fit(X_train_seq, y_train, epochs = 20, batch_size = 512, verbose = 1)
# Save the model after training
#model.save("model.h5")
4) Assessment and measurement map
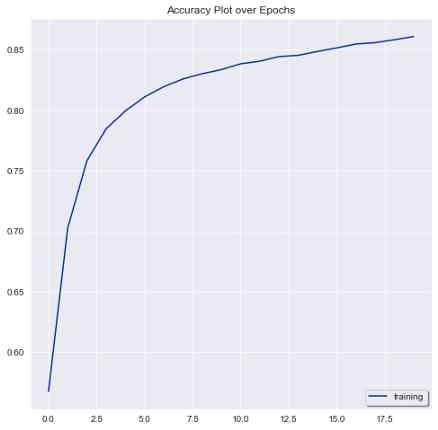
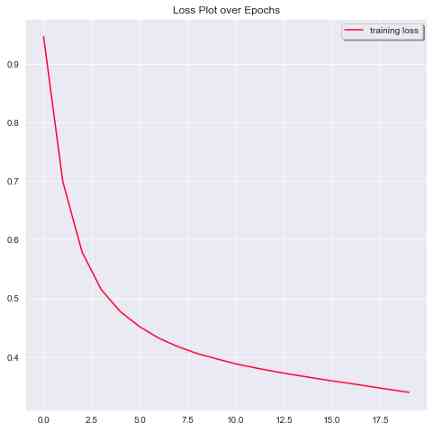
The rest is to evaluate the performance of our model , And draw a graph to see how the accuracy and loss metrics of the model change over time .
The performance metrics for our model are shown in the following screenshot .

The code is the same as the code shown below .
# Evaluate the performance of the model on the test set
loss, accuracy = model.evaluate(X_test_seq, y_test, verbose = 1)
print("\nAccuracy: {}\nLoss: {}".format(accuracy, loss))
# Draw accuracy and loss
sb.set_style('darkgrid')
# 1) Accuracy
plt.plot(history.history['accuracy'], label = 'training', color = '#003399')
plt.legend(shadow = True, loc = 'lower right')
plt.title('Accuracy Plot over Epochs')
plt.show()
# 2) Loss
plt.plot(history.history['loss'], label = 'training loss', color = '#FF0033')
plt.legend(shadow = True, loc = 'upper right')
plt.title('Loss Plot over Epochs')
plt.show()
Here's how to improve accuracy in training
20 individual epoch The loss map of
2. In the process of the training GloVe Word embedding
If you just want to run the model , Here's the complete code :https://github.com/shraddha-an/nlp/blob/main/pretrained_glove_classification.ipynb
Instead of training your own embeddedness , Another option is to use pre trained word embedding , such as GloVe or Word2Vec. In this part , We will use it in Wikipedia+gigaword5 Trained on GloVe Word embedding ; Download... From here :https://nlp.stanford.edu/projects/glove/
i) Select a pre training word to embed , If
Your dataset is made up of more “ Universal ” The language of , Generally speaking, you don't have that big data set .
Because these embeddings have been trained on a large number of words from different sources , If your data is also universal , Then the pre training model may be well done .
Besides , Through pre training embedding , You can save time and computing resources .
ii) Choose to train your own embedding , If
Your data ( And projects ) It's based on a niche industry , Like medicine 、 Finance or any other non generic and highly specific area .
under these circumstances , The general word embedding representation may not be suitable for you , And some words may not be in the vocabulary .
A large amount of domain data is needed to ensure that the learned word embedding can correctly represent different words and their semantic relations
Besides , It requires a lot of computing resources to browse your corpus and build word embedding .
Final , It's training your own embedding based on existing data , Or use the pre trained embedding , It will depend on your project .
obviously , You can still experiment with both models , And choose a more accurate model , But the above tutorial is just a simplified one , Can help you make decisions .
The process
The previous section has taken most of the steps required , Just make some adjustments .
We just need to build an embedding matrix of a word and its vectors , Then use it to set the weight of the embedded layer .
therefore , Keep preprocessing 、 The tagging and filling steps remain unchanged .
Once we import the original dataset and run the previous text cleaning steps , Let's run the code below to build the matrix .
Let's decide how many dimensions to embed (50、100、200), And include its name in the path variable below .
# # Import embedded
path = 'Full path to your glove file (with the dimensions)'
embeddings = dict()
with open(path, 'r', encoding = 'utf-8') as f:
for line in f:
# Every line in the file is a word plus 50 Number ( The vector that represents the word )
values = line.split()
# The first element of each line is a word , The rest 50 One is its vector
embeddings[values[0]] = np.array(values[1:], 'float32')
# Set some parameters
vocab_size = 2100
glove_dim = 50
sequence_length = 200
# Construct embedding matrix from words in corpus
embedding_matrix = np.zeros((vocab_size, glove_dim))
for word, index in word_index.items():
if index < vocab_size:
try:
# If the embedding of a given word exists , Retrieve it and map it to words .
embedding_matrix[index] = embeddings[word]
except:
pass
The code for building and training the embedded layer and neural network should be slightly modified , To allow embedding matrices to be used as weights .
# neural network
from keras.models import Sequential
from keras.layers import Embedding, Dense, Flatten
model = Sequential()
model.add(Embedding(input_dim = vocab_size,
output_dim = glove_dim,
input_length = sequence))
model.add(Flatten())
model.add(Dense(units = 3, activation = 'softmax'))
model.compile(optimizer = 'adam', metrics = ['accuracy'], loss = 'categorical_crossentropy')
# Load our pre trained embedding matrix into the embedding layer
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False # Weights are not updated during training
# Training models
history = model.fit(X_train_seq, y_train, epochs = 20, batch_size = 512, verbose = 1)
Here are the performance indicators of our pre trained model in the test set .

Conclusion
From the performance index of the two models , The training embedding layer seems to be more suitable for this dataset .
Some of the reasons may be
1) Most of the problems with stack overflow are related to IT It's about programming , in other words , This is a domain specific scenario .
2) 45000 A large training data set of samples provides a good learning scenario for our embedded layer .
I hope this tutorial will help you , Thanks for reading , See you for the next article .
Link to the original text :https://towardsdatascience.com/a-guide-to-word-embeddings-8a23817ab60f
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
- [JMeter] two ways to realize interface Association: regular representation extractor and JSON extractor
- 6.5 request to view name translator (in-depth analysis of SSM and project practice)
- Advanced Vue component pattern (3)
- Face to face Manual Chapter 16: explanation and implementation of fair lock of code peasant association lock and reentrantlock
- keras model.compile Loss function and optimizer
- 前端都应懂的入门基础-github基础
- 從小公司進入大廠,我都做對了哪些事?
- PN8162 20W PD快充芯片,PD快充充电器方案
- “颜值经济”的野望:华熙生物净利率六连降,收购案遭上交所问询
- 一篇文章带你了解CSS对齐方式
猜你喜欢

ipfs正舵者Filecoin落地正当时 FIL币价格破千来了
阿里云Q2营收破纪录背后,云的打开方式正在重塑
助力金融科技创新发展,ATFX走在行业最前列

Swagger 3.0 天天刷屏,真的香嗎?
Want to do read-write separation, give you some small experience
快快使用ModelArts,零基礎小白也能玩轉AI!
一篇文章带你了解CSS3 背景知识
Don't go! Here is a note: picture and text to explain AQS, let's have a look at the source code of AQS (long text)
小程序入门到精通(二):了解小程序开发4个重要文件
至联云解析:IPFS/Filecoin挖矿为什么这么难?
随机推荐
做外包真的很难,身为外包的我也无奈叹息。
Python download module to accelerate the implementation of recording
Troubleshooting and summary of JVM Metaspace memory overflow
速看!互联网、电商离线大数据分析最佳实践!(附网盘链接)
Working principle of gradient descent algorithm in machine learning
Swagger 3.0 天天刷屏,真的香嗎?
keras model.compile Loss function and optimizer
在大规模 Kubernetes 集群上实现高 SLO 的方法
华为云“四个可靠”的方法论
How to use parameters in ES6
Character string and memory operation function in C language
至联云解析:IPFS/Filecoin挖矿为什么这么难?
In order to save money, I learned PHP in one day!
Natural language processing - BM25 commonly used in search
axios学习笔记(二):轻松弄懂XHR的使用及如何封装简易axios
Calculation script for time series data
一篇文章带你了解SVG 渐变知识
I'm afraid that the spread sequence calculation of arbitrage strategy is not as simple as you think
Advanced Vue component pattern (3)
OPTIMIZER_ Trace details