当前位置:网站首页>Discussion on the technical scheme of text de duplication (1)
Discussion on the technical scheme of text de duplication (1)
2020-11-06 01:28:00 【Elementary school students in IT field】
Please indicate the source of forwarding :https://blog.csdn.net/HHTNAN
For text de duplication , I personally deal with it from the amount of data 、 Text features 、 Text length ( Short text 、 Long text ) Consider several directions .
Common de duplication tasks , Such as webpage de duplication , Post to duplicate , Comments, redundancies, etc .
A good de duplication task is not only to compare text similarities , And compare the semantic similarity .
Next, let's introduce the scheme of text de duplication .
1. Traditional signature algorithm and text integrity judgment
One 、 Traditional signature algorithm and text integrity judgment
Ask questions :
(1) Operation and maintenance online bin file , Distribute the document to 4 On the machine on the line , How to determine bin The documents are all consistent ?
(2) user A The message is msg Send to user B, user B How to judge the received msg_t Is the user A Sent msg?
Ideas :
A byte by byte comparison is inefficient for two large files or large web pages , We can use a signature value ( for example md5 value ) For a big document , If the signature value is the same, the large file is considered to be the same ( Forget about the conflict rate )
answer :
(1) take bin File access md5, take 4 On the machine on the line bin The documents are also taken from md5, If 5 individual md5 Same value , The explanation is consistent
(2) user A take msg And the news md5 Send to user at the same time B, user B received msg_t After that, I also take md5, Get the value with the user A Sent by md5 If the values are the same , shows msg_t And msg identical
Conclusion : md5 It's a signature algorithm , It is often used to judge the integrity and consistency of data
md5 Design principles : Two texts, even if only 1 individual bit Different , Its md5 Signature values can also vary greatly , So it only applies to “ integrity ”check, Do not apply to “ similarity ”check.
New questions thrown :
Is there a signature algorithm , If the text is very similar , The signature values are very similar ?
This method comes from the Internet , I think it's good , Therefore, it is directly quoted that , As the opening paragraph , If there is any infringement , Feel free to contact me .
simhash

simhash yes google The algorithm used to deal with massive text de duplication . google Produce , You'll see . simhash The best part is to put a document , Finally, it turns into a 64 Bytes of bits , For the time being, it is called characteristic character , And then to judge the repetition, we just need to judge whether the distance between their feature words is <n( According to experience, this n The general value is 3), You can judge whether the two documents are similar .
principle
simhash The generation of values is illustrated as follows
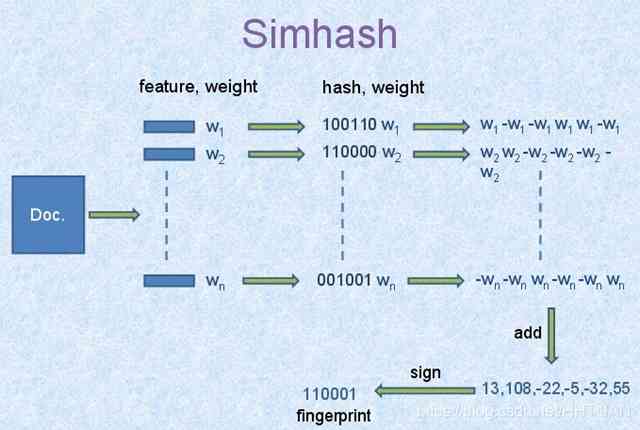
It takes three minutes to understand this diagram, and it's almost how to achieve this simhash The algorithm . It's very simple . Google products , Simple and practical .
-
1、 participle , Form the characteristic word of this article by the word segmentation of the text to be judged . Finally, a word sequence is formed to remove noise words and add weight to each word , We assume that the weights are divided into 5 A level (1~5). such as :“
The United States “51 District ” Employees say there is 9 A flying saucer , I've seen gray aliens ” ==> After the participle “ The United States (4) 51 District (5) Employee (3) call (1) Inside (2)
Yes (1) 9 frame (3) Flying saucer (5) once (1) See (3) gray (4) The aliens (5)”, Brackets are used to represent the importance of the word in the whole sentence , The bigger the number, the more important . -
2、hash, adopt hash Algorithm turns every word into hash value , such as “ The United States ” adopt hash The algorithm is calculated as 100101,“51 District ” adopt hash The algorithm is calculated as
101011. So our string becomes a string of numbers , Remember what I said at the beginning of the article , In order to improve the performance of similarity calculation, we should turn the article into digital calculation , Now it's time for dimensionality reduction . -
3、 weighting , adopt 2 The steps of the hash Generate results , Need to form a weighted number string according to the weight of the word , such as “ The United States ” Of hash The value is “100101”, Weighted as “4
-4 -4 4 -4 4”;“51 District ” Of hash The value is “101011”, Weighted as “ 5 -5 5 -5 5 5”. -
4、 Merge , Add up the sequence values of the above words , Become a sequence string . such as “ The United States ” Of “4 -4 -4 4 -4 4”,“51 District ” Of “ 5
-5 5 -5 5 5”, Add up each bit , “4+5 -4±5 -4+5 4±5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”. As an example, only two words of , Real computation requires adding up the sequence of all the words . -
5、 Dimension reduction , hold 4 Step by step “9 -9 1 -1 1 9” become 0 1 strand , Form our final simhash Signature . If each bit is greater than 0 Write it down as 1, Less than 0 Write it down as 0. The final result is :“1 0 1 0 1 1”.
The diagram of the whole process is :
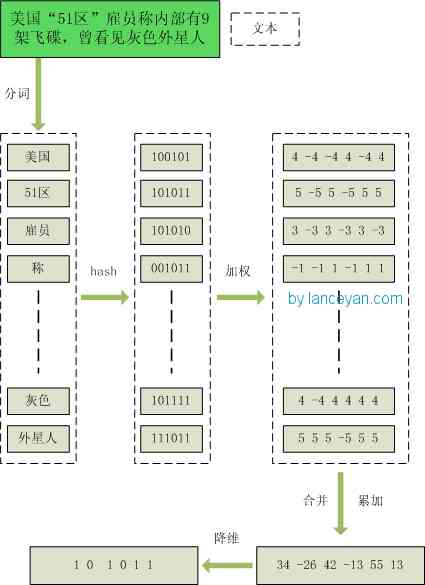
Here we are , How from a doc To a simhash The process of value has been made clear .
You may have questions , After so many steps, so much trouble , No, just to get a 0 1 String ? I type this text directly as a string , use hash Function generation 0 1 It's simpler . It's not like that , Tradition hash Function is to generate unique values , such as md5、hashmap etc. .md5 Is used to generate a unique signature string , Just add one more character md5 It seems that the two figures are quite different ;hashmap It is also used to find key value pairs , Data structure for quick insertion and search . However, we mainly solve the text similarity calculation , To compare the two articles is whether they know each other , Of course, we reduce the dimension to generate hashcode It's also used for this purpose . If you see here, you will understand , What we use simhash Even if the string in the article becomes 01 Strings can also be used to calculate similarity , While traditional hashcode But not . We can do a test , Two text strings that differ by only one character ,“ Your mother told you to go home for dinner , Go home, go home ” and “ Your mother told you to go home for dinner , Go home, go home ”.
adopt simhash The calculation result is :
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
adopt hashcode The calculation for the :
1111111111111111111111111111111110001000001100110100111011011110
1010010001111111110010110011101
You can see , Similar texts are only partially 01 The string has changed , And ordinary. hashcode But you can't do it , This is the charm of local sensitive hashing . at present Broder Proposed shingling Algorithm and Charikar Of simhash The algorithm should be regarded as the industry recognized better algorithm . stay simhash The inventor of Charikar There is no specific simhash Algorithms and proofs , Quantum Turing ” The proof is that simhash It's made up of random hyperplanes hash The algorithm evolved .
Here is about 【 Hamming distance 】
Binary string A and Binary string B Hemingway distance of Namely A xor B After binary 1 The number of .
Examples are as follows :
> A = 100111;
> B = 101010;
> hamming_distance(A, B) = count_1(A xor B) = count_1(001101) = 3;
When we figure out all doc Of simhash The value of , Need to compute doc A and doc B The condition of whether they are similar is :
A and B Is Hamming distance less than or equal to n, This n According to experience, the value is generally taken as 3,
simhash It's locally sensitive in nature hash, and md5 It's not the same thing . Because of its local sensitivity , So we can use Hamming distance to measure simhash Value similarity .
simhash By Charikar stay 2002 It was put forward in 1986 , Reference resources 《Similarity estimation techniques from rounding algorithms》 .
Through this transformation , We convert all the texts in the library into simhash Code , And converted to long Type storage , Reduced space . Now we've solved the space , But how to calculate two simhash The similarity of ? Is it to compare two simhash Of 01 How many different ? Right , In fact, that's how it works , We pass the Hemingway distance (Hamming distance) You can work out two simhash Is it similar or not . Two simhash Corresponding binary (01 strand ) The quantities with different values are called these two simhash Hemingway distance of . Examples are as follows : 10101 and 00110 Starting from the first, there is the first one in turn 、 Fourth 、 Number five is different , Then Hamming's distance is 3. For binary strings a and b, Hamming's distance is equal to at a XOR b In the result of the calculation 1 The number of ( Universal algorithms ).
For efficient comparison , We preload the existing text in the library and convert it to simhash code Stored in memory space . A piece of text is first converted to simhash code, And then with the memory simhash code Compare , test 100w The calculation is in 100ms. The speed has been greatly improved .
Section :
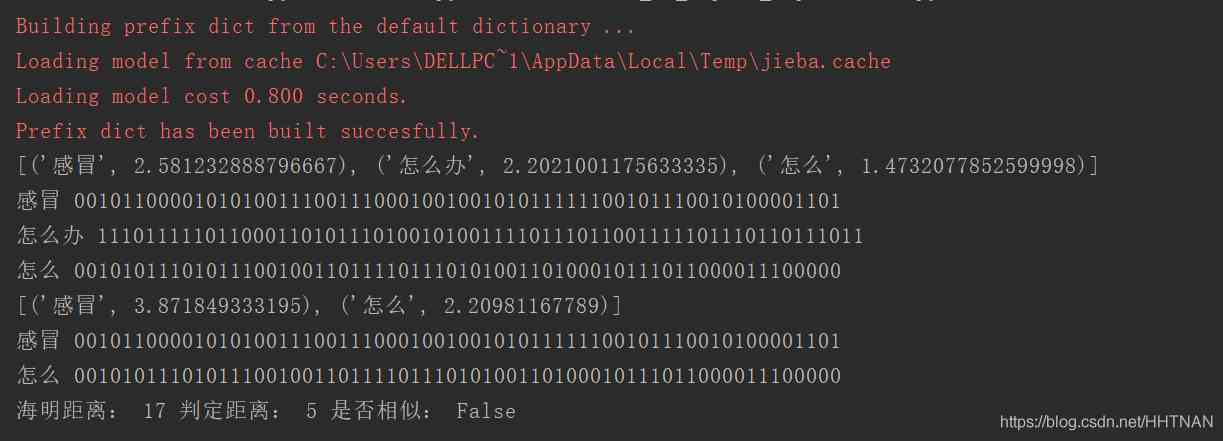
- 1、 At present, the speed has been improved, but the data is increasing , If the data grows to an hour in the future 100w, Press now once 100ms, One thread processes for one second 10 Time , A minute 60 10 Time , An hour 6010 60 Time = 36000 Time , One day 601060*24 = 864000 Time . Our goal is one day 100w Time , It can be done by adding two threads . But if it takes an hour 100w And then ? You need to add 30 Threads and corresponding hardware resources guarantee that the speed can reach , So the cost goes up . Can there be a better way , Improve the efficiency of our comparison ?
- 2、 Through a lot of testing ,simhash Used to compare large text , such as 500 The effect of the above words is very good , Distance less than 3 They are basically similar , The rate of misjudgment is also relatively low . But if we're dealing with microblogging , Most are 140 A word , Use simhash The effect is not so ideal . See the picture below , In the distance for 3 Is a more eclectic point , In the distance for 10 When the effect is already very poor , But we test short text a lot, and the distance that looks similar is 10. If the distance used is 3, A lot of repeated information in short text will not be filtered , If the distance used is 10, The error rate of long text is also very high , How to solve ?
Code implementation
#coding:utf8
import math
import jieba
import jieba.analyse
class SimHash(object):
def __init__(self):
pass
def getBinStr(self, source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2 ** 128 - 1
for c in source:
x = ((x * m) ^ ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
x = bin(x).replace('0b', '').zfill(64)[-64:]
print(source, x)
return str(x)
def getWeight(self, source):
# fake weight with keyword
return ord(source)
def unwrap_weight(self, arr):
ret = ""
for item in arr:
tmp = 0
if int(item) > 0:
tmp = 1
ret += str(tmp)
return ret
def simHash(self, rawstr):
seg = jieba.cut(rawstr, cut_all=True)
keywords = jieba.analyse.extract_tags("|".join(seg), topK=100, withWeight=True)
print(keywords)
ret = []
for keyword, weight in keywords:
binstr = self.getBinStr(keyword)
keylist = []
for c in binstr:
weight = math.ceil(weight)
if c == "1":
keylist.append(int(weight))
else:
keylist.append(-int(weight))
ret.append(keylist)
# Do... On the list " Dimension reduction "
rows = len(ret)
cols = len(ret[0])
result = []
for i in range(cols):
tmp = 0
for j in range(rows):
tmp += int(ret[j][i])
if tmp > 0:
tmp = "1"
elif tmp <= 0:
tmp = "0"
result.append(tmp)
return "".join(result)
def getDistince(self, hashstr1, hashstr2):
length = 0
for index, char in enumerate(hashstr1):
if char == hashstr2[index]:
continue
else:
length += 1
return length
if __name__ == "__main__":
simhash = SimHash()
s1=" What to do with a cold " # The result is bad , semantics
s2=" How to treat a cold "
# s1 = "100 element =38 Ten thousand star coins , Add WeChat " # The result is bad
# s2 = "38 Ten thousand star coins 100 element , Add VX"
# with open("a.txt", "r") as file:
# s1 = "".join(file.readlines())
# file.close()
# with open("b.txt", "r") as file:
# s2 = "".join(file.readlines())
# file.close()
# s1 = "this is just test for simhash, here is the difference"
# s2 = "this is a test for simhash, here is the difference"
# print(simhash.getBinStr(s1))
# print(simhash.getBinStr(s2))
hash1 = simhash.simHash(s1)
hash2 = simhash.simHash(s2)
distince = simhash.getDistince(hash1, hash2)
# value = math.sqrt(len(s1)**2 + len(s2)**2)
value = 5
print(" Hamming distance :", distince, " Determine the distance :", value, " Whether it is similar to :", distince<=value)
Reference material : Through train

版权声明
本文为[Elementary school students in IT field]所创,转载请带上原文链接,感谢
边栏推荐
- Skywalking series blog 5-apm-customize-enhance-plugin
- After reading this article, I understand a lot of webpack scaffolding
- [event center azure event hub] interpretation of error information found in event hub logs
- ES6 essence:
- PHP应用对接Justswap专用开发包【JustSwap.PHP】
- 比特币一度突破14000美元,即将面临美国大选考验
- [JMeter] two ways to realize interface Association: regular representation extractor and JSON extractor
- 一篇文章带你了解CSS3图片边框
- Save the file directly to Google drive and download it back ten times faster
- 全球疫情加速互联网企业转型,区块链会是解药吗?
猜你喜欢
Summary of common algorithms of binary tree

使用 Iceberg on Kubernetes 打造新一代云原生数据湖

Existence judgment in structured data
EOS创始人BM: UE,UBI,URI有什么区别?

Using Es5 to realize the class of ES6
ES6学习笔记(四):教你轻松搞懂ES6的新增语法
ES6学习笔记(五):轻松了解ES6的内置扩展对象
小程序入门到精通(二):了解小程序开发4个重要文件

I think it is necessary to write a general idempotent component
一篇文章教会你使用Python网络爬虫下载酷狗音乐
随机推荐
Face to face Manual Chapter 16: explanation and implementation of fair lock of code peasant association lock and reentrantlock
ES6学习笔记(二):教你玩转类的继承和类的对象
6.6.1 localeresolver internationalization parser (1) (in-depth analysis of SSM and project practice)
Grouping operation aligned with specified datum
CCR炒币机器人:“比特币”数字货币的大佬,你不得不了解的知识
I've been rejected by the product manager. Why don't you know
Wechat applet: prevent multiple click jump (function throttling)
This article will introduce you to jest unit test
The data of pandas was scrambled and the training machine and testing machine set were selected
Working principle of gradient descent algorithm in machine learning
Three Python tips for reading, creating and running multiple files
前端都应懂的入门基础-github基础
用一个例子理解JS函数的底层处理机制
Electron application uses electronic builder and electronic updater to realize automatic update
Analysis of partial source codes of qthread
中小微企业选择共享办公室怎么样?
[JMeter] two ways to realize interface Association: regular representation extractor and JSON extractor
Mac installation hanlp, and win installation and use
The choice of enterprise database is usually decided by the system architect - the newstack
6.3 handlerexceptionresolver exception handling (in-depth analysis of SSM and project practice)