当前位置:网站首页>10 张图打开 CPU 缓存一致性的大门
10 张图打开 CPU 缓存一致性的大门
2022-07-07 11:08:00 【Young丶】
前言
直接上,不多 BB 了。
正文
CPU Cache 的数据写入
随着时间的推移,CPU 和内存的访问性能相差越来越大,于是就在 CPU 内部嵌入了 CPU Cache(高速缓存),CPU Cache 离 CPU 核心相当近,因此它的访问速度是很快的,于是它充当了 CPU 与内存之间的缓存角色。
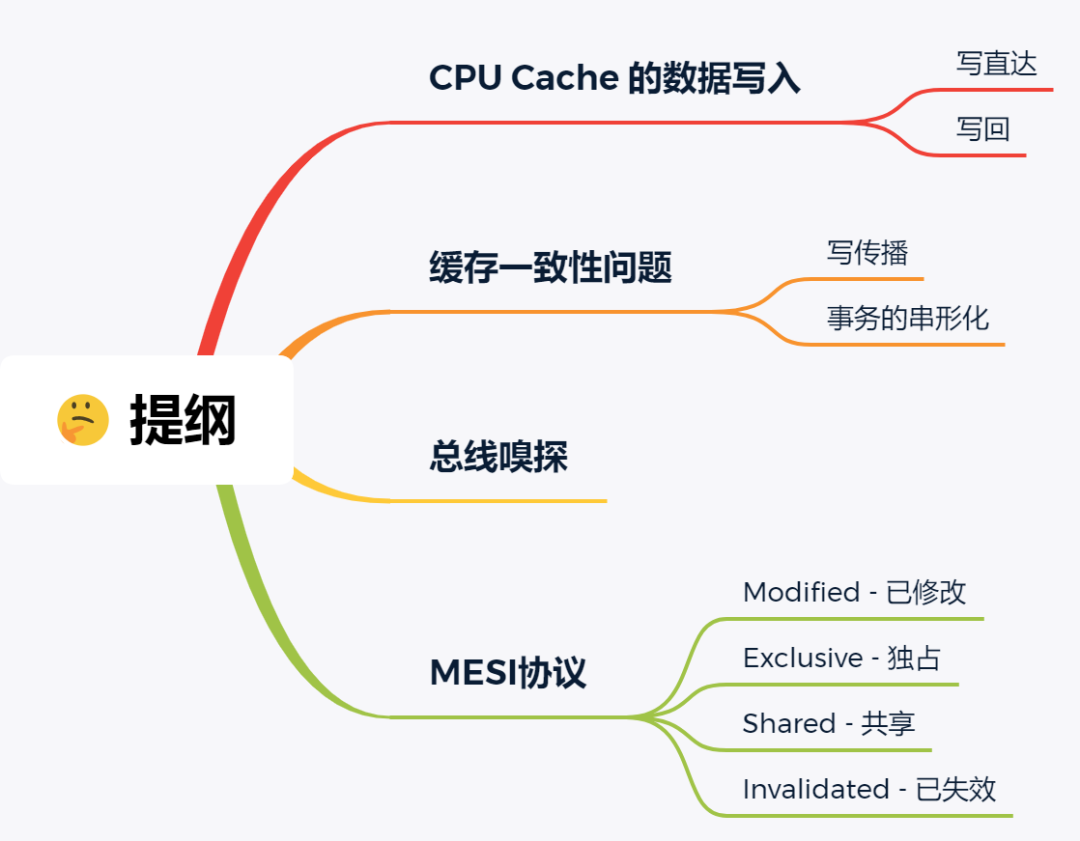
CPU Cache 通常分为三级缓存:L1 Cache、L2 Cache、L3 Cache,级别越低的离 CPU 核心越近,访问速度也快,但是存储容量相对就会越小。其中,在多核心的 CPU 里,每个核心都有各自的 L1/L2 Cache,而 L3 Cache 是所有核心共享使用的。
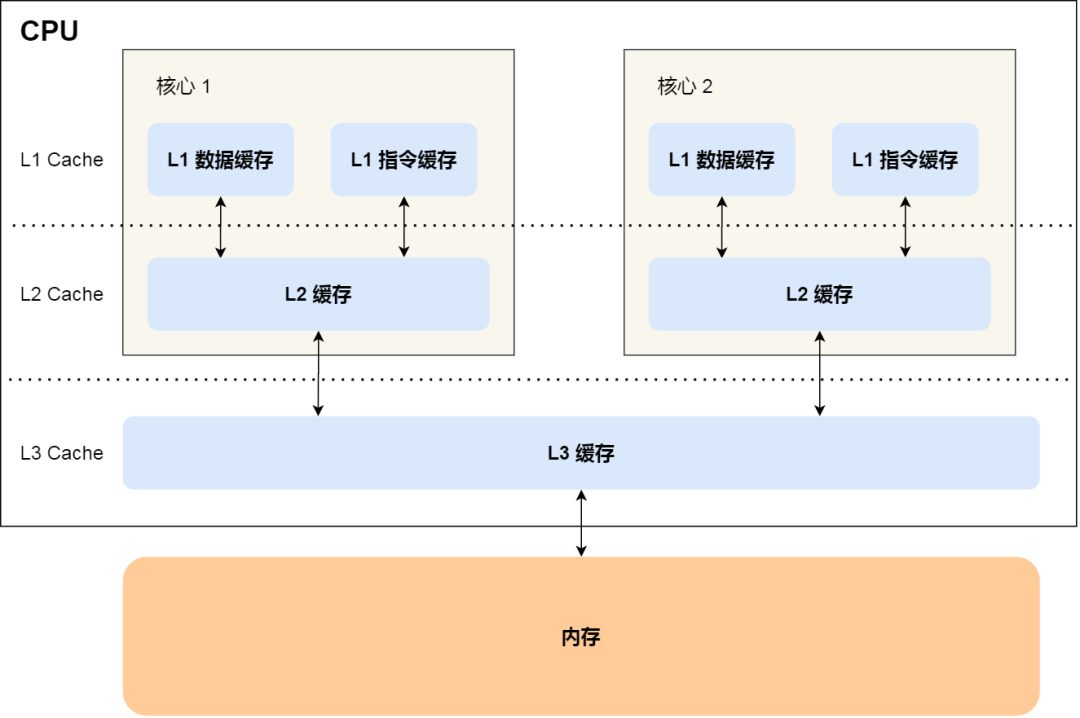
我们先简单了解下 CPU Cache 的结构,CPU Cache 是由很多个 Cache Line 组成的,CPU Line 是 CPU 从内存读取数据的基本单位,而 CPU Line 是由各种标志(Tag)+ 数据块(Data Block)组成,你可以在下图清晰的看到:
我们当然期望 CPU 读取数据的时候,都是尽可能地从 CPU Cache 中读取,而不是每一次都要从内存中获取数据。所以,身为程序员,我们要尽可能写出缓存命中率高的代码,这样就有效提高程序的性能,具体的做法,你可以参考我上一篇文章「如何写出让 CPU 跑得更快的代码?」
事实上,数据不光是只有读操作,还有写操作,那么如果数据写入 Cache 之后,内存与 Cache 相对应的数据将会不同,这种情况下 Cache 和内存数据都不一致了,于是我们肯定是要把 Cache 中的数据同步到内存里的。
问题来了,那在什么时机才把 Cache 中的数据写回到内存呢?为了应对这个问题,下面介绍两种针对写入数据的方法:
- 写直达(Write Through)
- 写回(Write Back)
写直达
保持内存与 Cache 一致性最简单的方式是,把数据同时写入内存和 Cache 中,这种方法称为写直达(*Write Through*)。
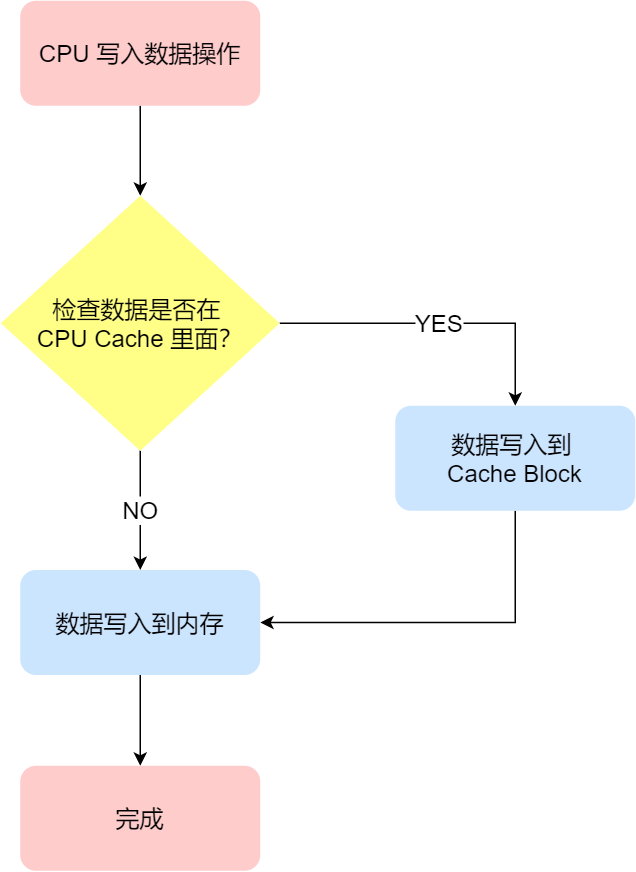
在这个方法里,写入前会先判断数据是否已经在 CPU Cache 里面了:
- 如果数据已经在 Cache 里面,先将数据更新到 Cache 里面,再写入到内存里面;
- 如果数据没有在 Cache 里面,就直接把数据更新到内存里面。
写直达法很直观,也很简单,但是问题明显,无论数据在不在 Cache 里面,每次写操作都会写回到内存,这样写操作将会花费大量的时间,无疑性能会受到很大的影响。
写回
既然写直达由于每次写操作都会把数据写回到内存,而导致影响性能,于是为了要减少数据写回内存的频率,就出现了写回(*Write Back*)的方法。
在写回机制中,当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能。
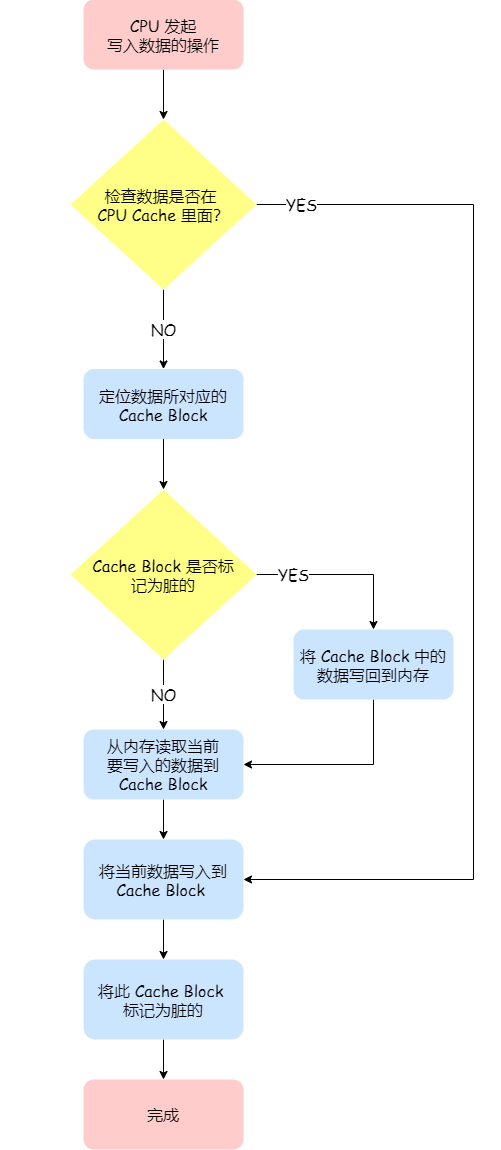
那具体如何做到的呢?下面来详细说一下:
- 如果当发生写操作时,数据已经在 CPU Cache 里的话,则把数据更新到 CPU Cache 里,同时标记 CPU Cache 里的这个 Cache Block 为脏(Dirty)的,这个脏的标记代表这个时候,我们 CPU Cache 里面的这个 Cache Block 的数据和内存是不一致的,这种情况是不用把数据写到内存里的;
- 如果当发生写操作时,数据所对应的 Cache Block 里存放的是「别的内存地址的数据」的话,就要检查这个 Cache Block 里的数据有没有被标记为脏的,如果是脏的话,我们就要把这个 Cache Block 里的数据写回到内存,然后再把当前要写入的数据,写入到这个 Cache Block 里,同时也把它标记为脏的;如果 Cache Block 里面的数据没有被标记为脏,则就直接将数据写入到这个 Cache Block 里,然后再把这个 Cache Block 标记为脏的就好了。
可以发现写回这个方法,在把数据写入到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为脏标记的情况下,才会将数据写到内存中,而在缓存命中的情况下,则在写入后 Cache 后,只需把该数据对应的 Cache Block 标记为脏即可,而不用写到内存里。
这样的好处是,如果我们大量的操作都能够命中缓存,那么大部分时间里 CPU 都不需要读写内存,自然性能相比写直达会高很多。
缓存一致性问题
现在 CPU 都是多核的,由于 L1/L2 Cache 是多个核心各自独有的,那么会带来多核心的缓存一致性(*Cache Coherence*) 的问题,如果不能保证缓存一致性的问题,就可能造成结果错误。
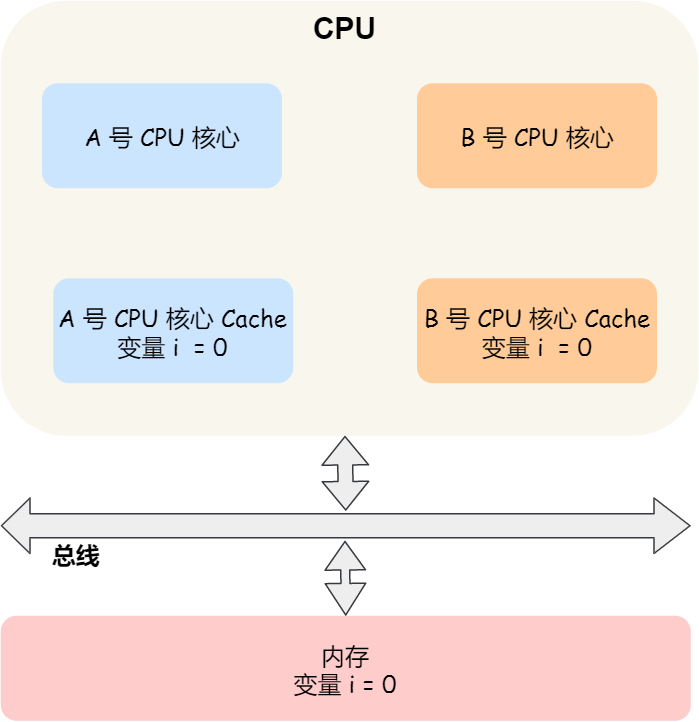
那缓存一致性的问题具体是怎么发生的呢?我们以一个含有两个核心的 CPU 作为例子看一看。
假设 A 号核心和 B 号核心同时运行两个线程,都操作共同的变量 i(初始值为 0 )。
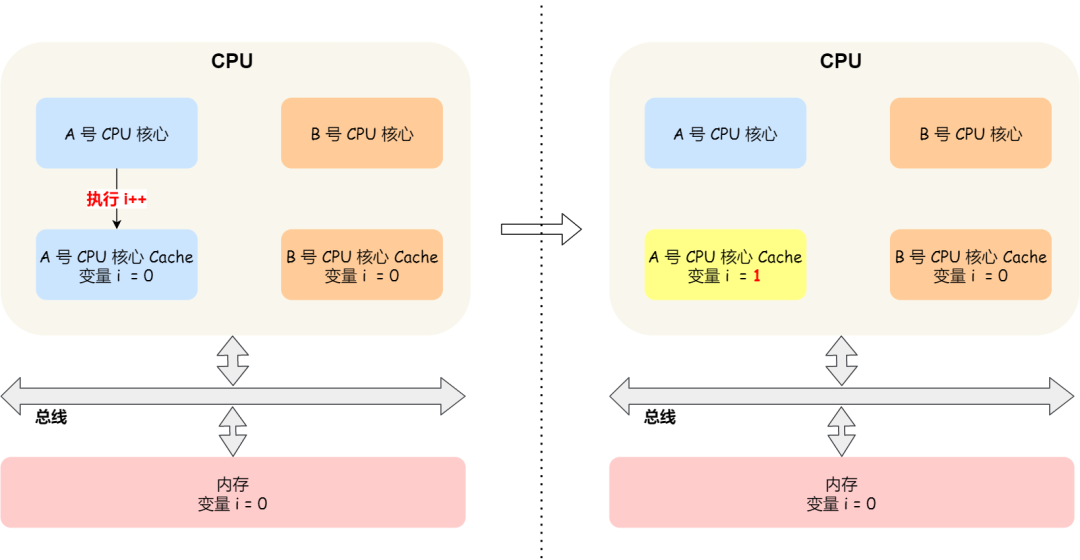
这时如果 A 号核心执行了 i++ 语句的时候,为了考虑性能,使用了我们前面所说的写回策略,先把值为 1 的执行结果写入到 L1/L2 Cache 中,然后把 L1/L2 Cache 中对应的 Block 标记为脏的,这个时候数据其实没有被同步到内存中的,因为写回策略,只有在 A 号核心中的这个 Cache Block 要被替换的时候,数据才会写入到内存里。
如果这时旁边的 B 号核心尝试从内存读取 i 变量的值,则读到的将会是错误的值,因为刚才 A 号核心更新 i 值还没写入到内存中,内存中的值还依然是 0。这个就是所谓的缓存一致性问题,A 号核心和 B 号核心的缓存,在这个时候是不一致,从而会导致执行结果的错误。
那么,要解决这一问题,就需要一种机制,来同步两个不同核心里面的缓存数据。要实现的这个机制的话,要保证做到下面这 2 点:
- 第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(*Wreite Propagation*);
- 第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串形化(*Transaction Serialization*)。
第一点写传播很容易就理解,当某个核心在 Cache 更新了数据,就需要同步到其他核心的 Cache 里。
而对于第二点事务的串形化,我们举个例子来理解它。
假设我们有一个含有 4 个核心的 CPU,这 4 个核心都操作共同的变量 i(初始值为 0 )。A 号核心先把 i 值变为 100,而此时同一时间,B 号核心先把 i 值变为 200,这里两个修改,都会「传播」到 C 和 D 号核心。
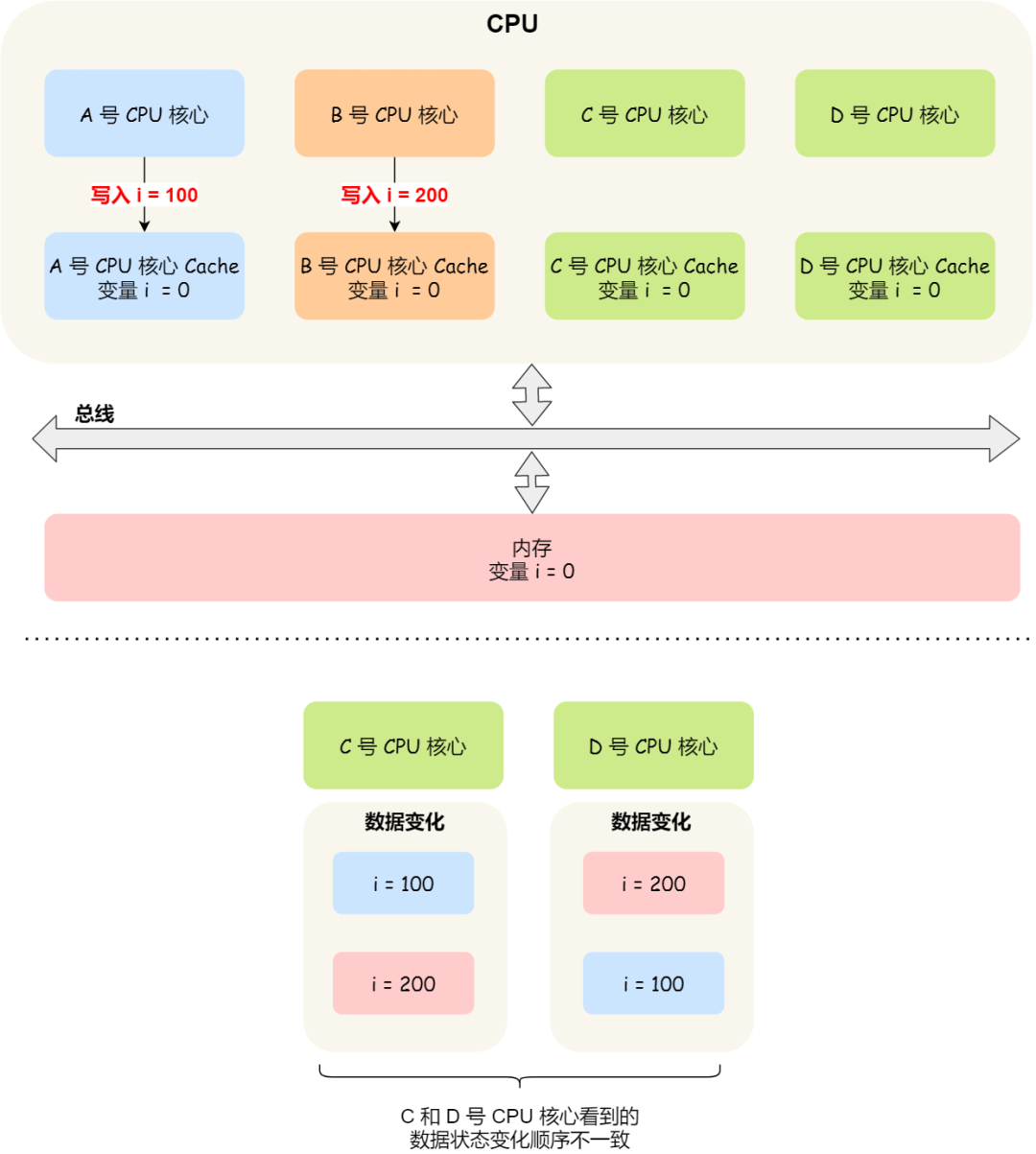
那么问题就来了,C 号核心先收到了 A 号核心更新数据的事件,再收到 B 号核心更新数据的事件,因此 C 号核心看到的变量 i 是先变成 100,后变成 200。
而如果 D 号核心收到的事件是反过来的,则 D 号核心看到的是变量 i 先变成 200,再变成 100,虽然是做到了写传播,但是各个 Cache 里面的数据还是不一致的。
所以,我们要保证 C 号核心和 D 号核心都能看到相同顺序的数据变化,比如变量 i 都是先变成 100,再变成 200,这样的过程就是事务的串形化。
要实现事务串形化,要做到 2 点:
- CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
- 要引入「锁」的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新。
那接下来我们看看,写传播和事务串形化具体是用什么技术实现的。
总线嗅探
写传播的原则就是当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心。最常见实现的方式是总线嗅探(*Bus Snooping*)。
我还是以前面的 i 变量例子来说明总线嗅探的工作机制,当 A 号 CPU 核心修改了 L1 Cache 中 i 变量的值,通过总线把这个事件广播通知给其他所有的核心,然后每个 CPU 核心都会监听总线上的广播事件,并检查是否有相同的数据在自己的 L1 Cache 里面,如果 B 号 CPU 核心的 L1 Cache 中有该数据,那么也需要把该数据更新到自己的 L1 Cache。
可以发现,总线嗅探方法很简单, CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,这无疑会加重总线的负载。
另外,总线嗅探只是保证了某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道,但是并不能保证事务串形化。
于是,有一个协议基于总线嗅探机制实现了事务串形化,也用状态机机制降低了总线带宽压力,这个协议就是 MESI 协议,这个协议就做到了 CPU 缓存一致性。
MESI 协议
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:
- Modified,已修改
- Exclusive,独占
- Shared,共享
- Invalidated,已失效
这四个状态来标记 Cache Line 四个不同的状态。
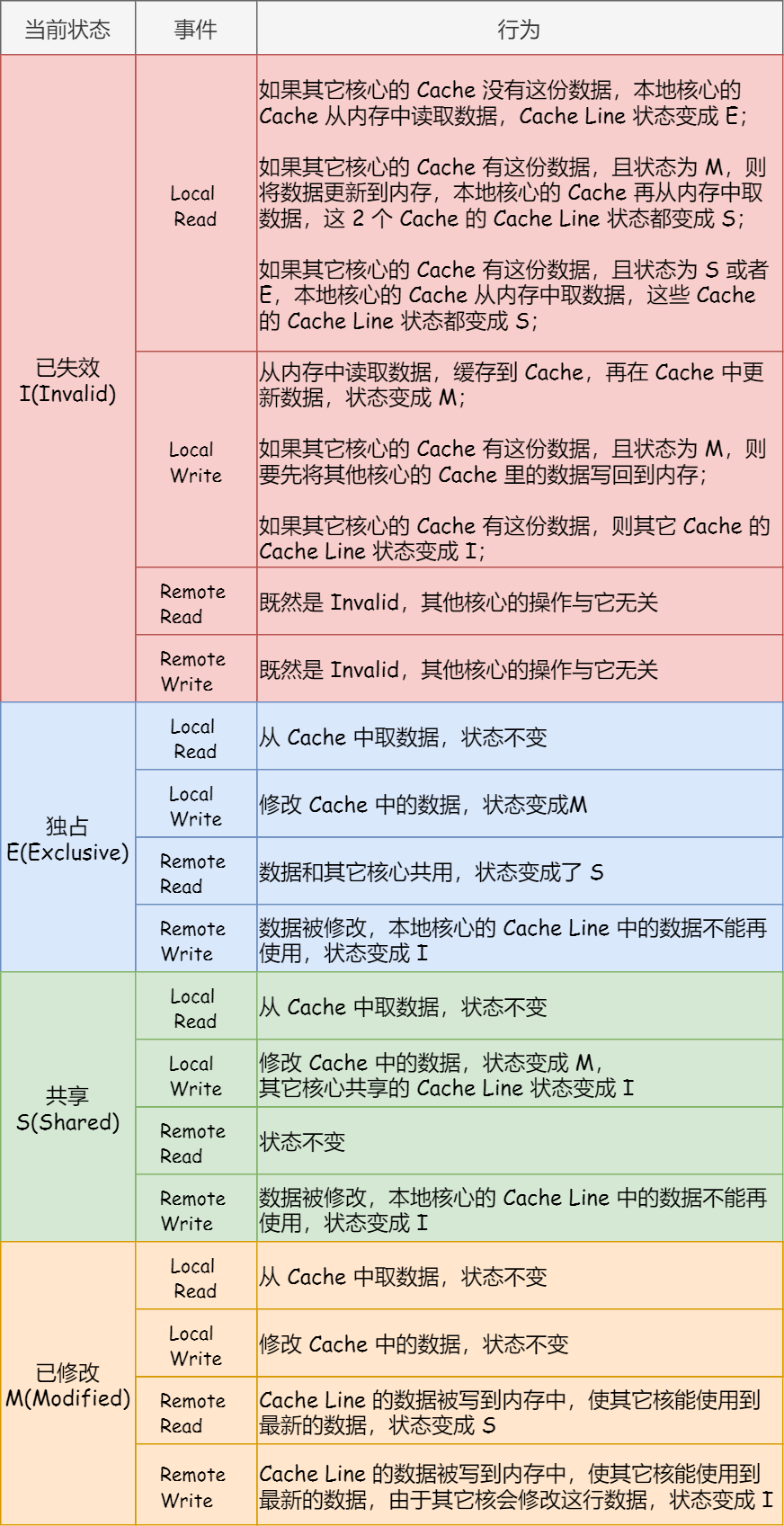
「已修改」状态就是我们前面提到的脏标记,代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存里。而「已失效」状态,表示的是这个 Cache Block 里的数据已经失效了,不可以读取该状态的数据。
「独占」和「共享」状态都代表 Cache Block 里的数据是干净的,也就是说,这个时候 Cache Block 里的数据和内存里面的数据是一致性的。
「独占」和「共享」的差别在于,独占状态的时候,数据只存储在一个 CPU 核心的 Cache 里,而其他 CPU 核心的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就可以直接自由地写入,而不需要通知其他 CPU 核心,因为只有你这有这个数据,就不存在缓存一致性的问题了,于是就可以随便操作该数据。
另外,在「独占」状态下的数据,如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
那么,「共享」状态代表着相同的数据在多个 CPU 核心的 Cache 里都有,所以当我们要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后再更新当前 Cache 里面的数据。
我们举个具体的例子来看看这四个状态的转换:
- 当 A 号 CPU 核心从内存读取变量 i 的值,数据被缓存在 A 号 CPU 核心自己的 Cache 里面,此时其他 CPU 核心的 Cache 没有缓存该数据,于是标记 Cache Line 状态为「独占」,此时其 Cache 中的数据与内存是一致的;
- 然后 B 号 CPU 核心也从内存读取了变量 i 的值,此时会发送消息给其他 CPU 核心,由于 A 号 CPU 核心已经缓存了该数据,所以会把数据返回给 B 号 CPU 核心。在这个时候, A 和 B 核心缓存了相同的数据,Cache Line 的状态就会变成「共享」,并且其 Cache 中的数据与内存也是一致的;
- 当 A 号 CPU 核心要修改 Cache 中 i 变量的值,发现数据对应的 Cache Line 的状态是共享状态,则要向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后 A 号 CPU 核心才更新 Cache 里面的数据,同时标记 Cache Line 为「已修改」状态,此时 Cache 中的数据就与内存不一致了。
- 如果 A 号 CPU 核心「继续」修改 Cache 中 i 变量的值,由于此时的 Cache Line 是「已修改」状态,因此不需要给其他 CPU 核心发送消息,直接更新数据即可。
- 如果 A 号 CPU 核心的 Cache 里的 i 变量对应的 Cache Line 要被「替换」,发现 Cache Line 状态是「已修改」状态,就会在替换前先把数据同步到内存。
所以,可以发现当 Cache Line 状态是「已修改」或者「独占」状态时,修改更新其数据不需要发送广播给其他 CPU 核心,这在一定程度上减少了总线带宽压力。
事实上,整个 MESI 的状态可以用一个有限状态机来表示它的状态流转。还有一点,对于不同状态触发的事件操作,可能是来自本地 CPU 核心发出的广播事件,也可以是来自其他 CPU 核心通过总线发出的广播事件。下图即是 MESI 协议的状态图:
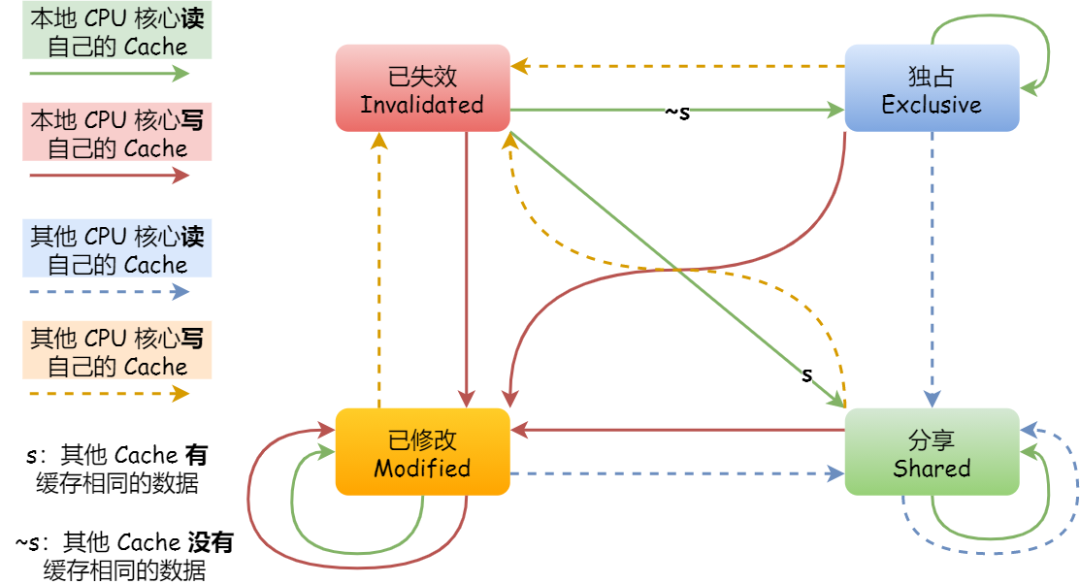
MESI 协议的四种状态之间的流转过程,我汇总成了下面的表格,你可以更详细的看到每个状态转换的原因:
总结
CPU 在读写数据的时候,都是在 CPU Cache 读写数据的,原因是 Cache 离 CPU 很近,读写性能相比内存高出很多。对于 Cache 里没有缓存 CPU 所需要读取的数据的这种情况,CPU 则会从内存读取数据,并将数据缓存到 Cache 里面,最后 CPU 再从 Cache 读取数据。
而对于数据的写入,CPU 都会先写入到 Cache 里面,然后再在找个合适的时机写入到内存,那就有「写直达」和「写回」这两种策略来保证 Cache 与内存的数据一致性:
- 写直达,只要有数据写入,都会直接把数据写入到内存里面,这种方式简单直观,但是性能就会受限于内存的访问速度;
- 写回,对于已经缓存在 Cache 的数据的写入,只需要更新其数据就可以,不用写入到内存,只有在需要把缓存里面的脏数据交换出去的时候,才把数据同步到内存里,这种方式在缓存命中率高的情况,性能会更好;
当今 CPU 都是多核的,每个核心都有各自独立的 L1/L2 Cache,只有 L3 Cache 是多个核心之间共享的。所以,我们要确保多核缓存是一致性的,否则会出现错误的结果。
要想实现缓存一致性,关键是要满足 2 点:
- 第一点是写传播,也就是当某个 CPU 核心发生写入操作时,需要把该事件广播通知给其他核心;
- 第二点是事物的串行化,这个很重要,只有保证了这个,次啊能保障我们的数据是真正一致的,我们的程序在各个不同的核心上运行的结果也是一致的;
基于总线嗅探机制的 MESI 协议,就满足上面了这两点,因此它是保障缓存一致性的协议。
MESI 协议,是已修改、独占、共享、已实现这四个状态的英文缩写的组合。整个 MSI 状态的变更,则是根据来自本地 CPU 核心的请求,或者来自其他 CPU 核心通过总线传输过来的请求,从而构成一个流动的状态机。另外,对于在「已修改」或者「独占」状态的 Cache Line,修改更新其数据不需要发送广播给其他 CPU 核心。
边栏推荐
- SSM框架搭建的步骤
- DHCP 动态主机设置协议 分析
- 人均瑞数系列,瑞数 4 代 JS 逆向分析
- Importance of database security
- 国泰君安证券开户怎么开的?开户安全吗?
- 有什么类方法或是函数可以查看某个项目的Laravel版本的?
- Blog recommendation | Apache pulsar cross regional replication scheme selection practice
- “新红旗杯”桌面应用创意大赛2022
- Image pixel read / write operation
- Per capita Swiss number series, Swiss number 4 generation JS reverse analysis
猜你喜欢

COSCon'22 社区召集令来啦!Open the World,邀请所有社区一起拥抱开源,打开新世界~
Analysis of DHCP dynamic host setting protocol
详细介绍六种开源协议(程序员须知)

TPG x AIDU|AI领军人才招募计划进行中!
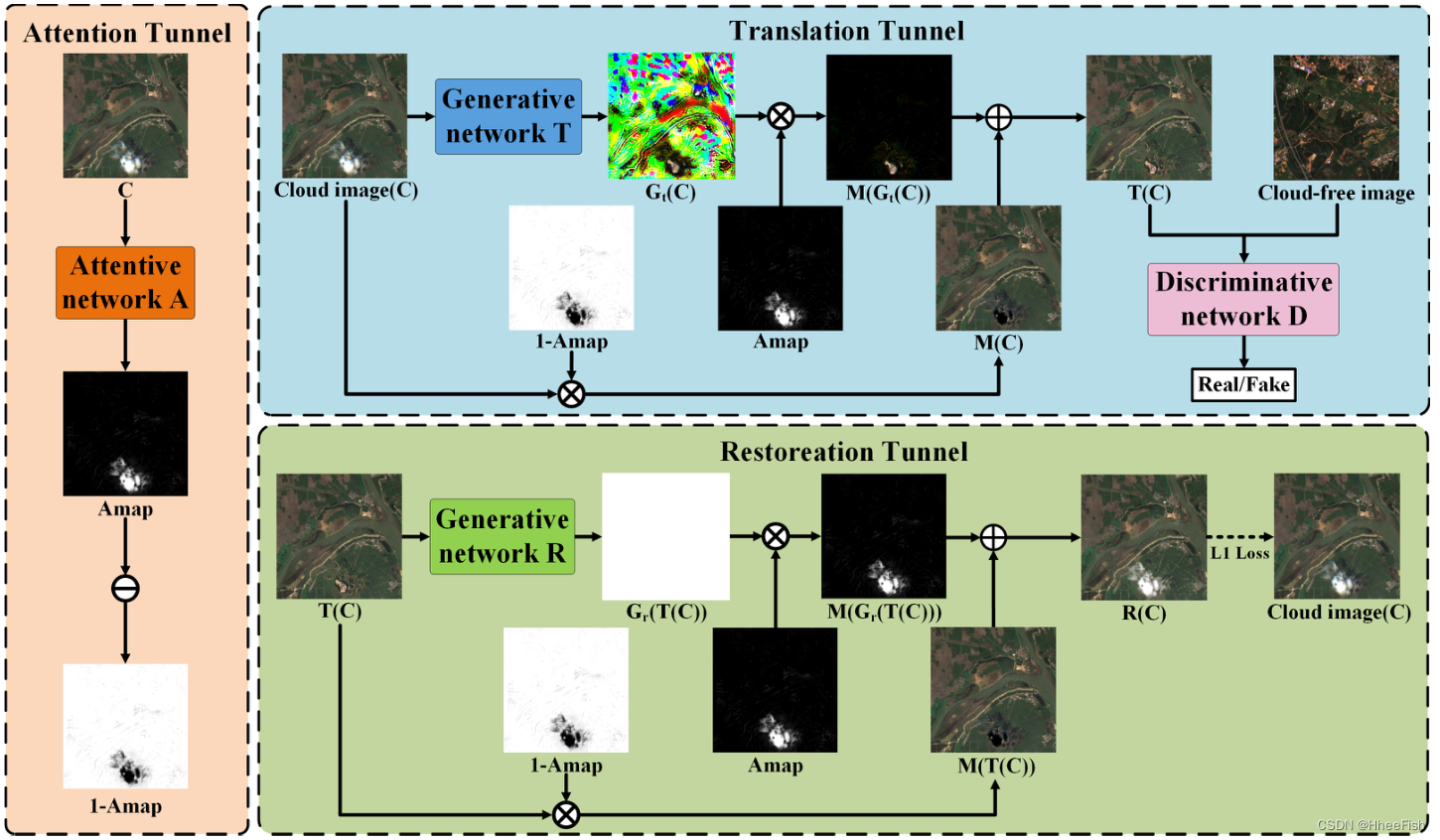
Cloud detection 2020: self attention generation countermeasure network for cloud detection in high-resolution remote sensing images

关于 appium 如何关闭 app (已解决)
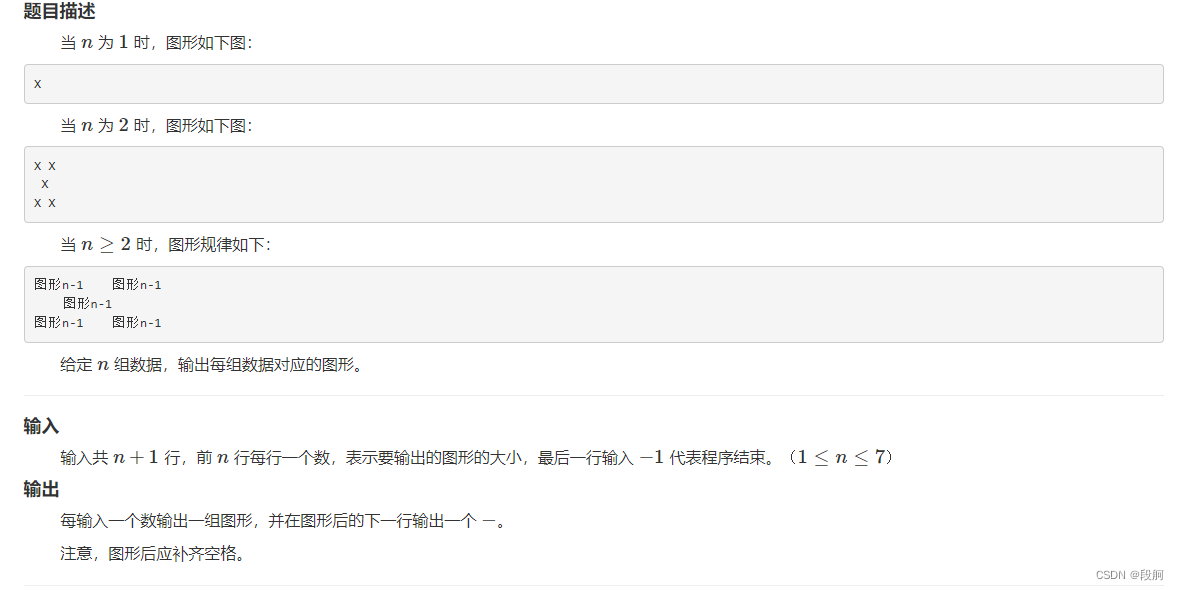
HZOJ #240. 图形打印四
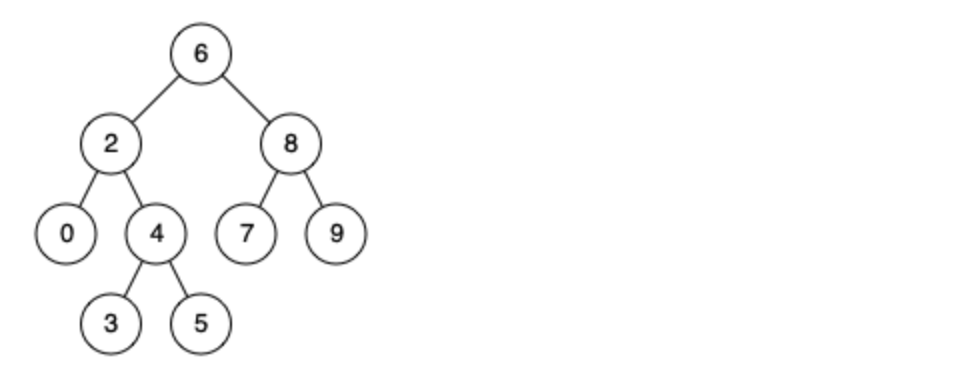
Leetcode skimming: binary tree 25 (the nearest common ancestor of binary search tree)
HZOJ #240. Graphic printing IV
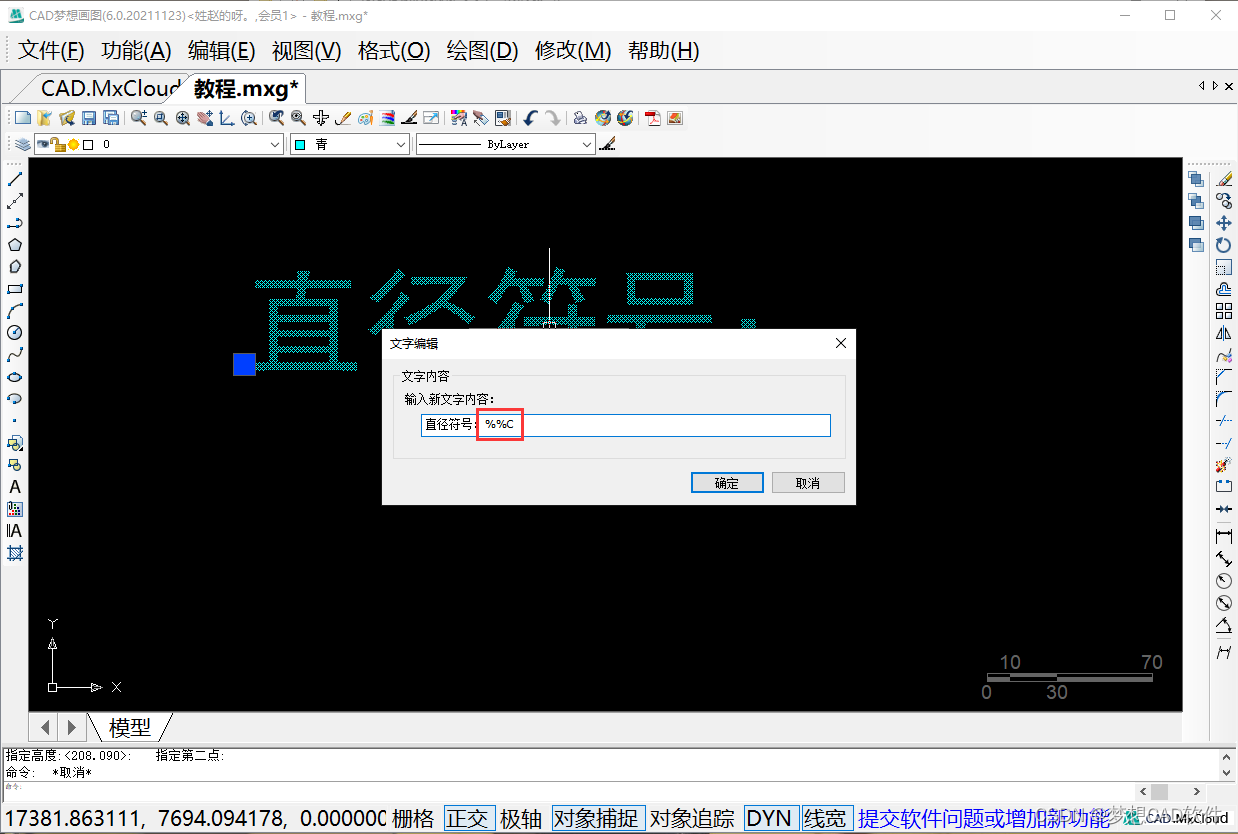
AUTOCAD——大于180度的角度标注、CAD直径符号怎么输入?
随机推荐
谷歌浏览器如何重置?谷歌浏览器恢复默认设置?
【学习笔记】线段树选做
How to reset Firefox browser
Differences between MySQL storage engine MyISAM and InnoDB
leecode3. 无重复字符的最长子串
为租客提供帮助
Query whether a field has an index with MySQL
[learn wechat from 0] [00] Course Overview
Day-24 UDP, regular expression
《ASP.NET Core 6框架揭秘》样章[200页/5章]
Analysis of DHCP dynamic host setting protocol
About the problem of APP flash back after appium starts the app - (solved)
mysql怎么创建,删除,查看索引?
Master formula. (used to calculate the time complexity of recursion.)
红杉中国完成新一期90亿美元基金募集
[learn microservices from 0] [03] explore the microservice architecture
【无标题】
Day26 IP query items
[untitled]
处理链中断后如何继续/子链出错removed from scheduling