当前位置:网站首页>Tensorrt command line program
Tensorrt command line program
2022-07-02 06:27:00 【Little Heshang sweeping the floor】
TensorRT The command line program for
Click here to join NVIDIA Developer Program
trtexec
The sample directory contains a file named trtexec Command line wrapper for . trtexec It is a kind of quick use without developing your own application TensorRT Tools for .
trtexec Tools have three main uses :
- It is useful for benchmarking the network on random or user supplied input data .
- It is useful for generating serialization engines from models .
- It is useful for generating serialization timing caches from builders .
Benchmarking Network
If you save the model as ONNX file 、UFF file , Or if you have Caffe prototxt Format network description , You can use trtexec Tool test use TensorRT The performance of reasoning running on the network . trtexec The tool has many options for specifying input and output 、 Iterations of performance timing 、 Allowed precision and other options .
In order to maximize GPU utilization , trtexec Will advance a batch Put in queue . let me put it another way , It does the following :
enqueue batch 0
-> enqueue batch 1
-> wait until batch 0 is done
-> enqueue batch 2
-> wait until batch 1 is done
-> enqueue batch 3
-> wait until batch 2 is done
-> enqueue batch 4
-> ...
If you use multiple streams ( --streams=N sign ), be trtexec Follow this pattern separately on each stream .
trtexec The tool prints the following performance indicators . The image below shows trtexec Example of running Nsight System profile , The mark shows the meaning of each performance index .
Throughput
The observed throughput is achieved by dividing the number of executions by Total Host Walltime Calculated . If this is significantly lower than GPU Count the reciprocal of time , be GPU It may not be fully utilized due to host side overhead or data transmission . Use CUDA chart ( Use --useCudaGraph ) Or disable H2D/D2H transmission ( Use --noDataTransfer ) Can improve GPU utilization . When trtexec detected GPU When underutilized , The output log provides guidance on which flag to use .
Host Latency
H2D Delay 、GPU Calculate time and D2H Sum of delays . This is the delay of inferring a single execution .
Enqueue Time
The host that queues execution is delayed , Including calling H2D/D2H CUDA API、 Run the host side method and start CUDA kernel . If this is better than GPU Long calculation time , be GPU May not be fully utilized , And the throughput may be dominated by the host side overhead . Use CUDA chart ( with --useCudaGraph ) It can reduce the queuing time .
H2D Latency
The delay of host to device data transmission of single execution input tensor . add to --noDataTransfer To disable H2D/D2H The data transfer .
D2H Latency
The delay of the device to host data transmission of the output tensor of a single execution . add to --noDataTransfer To disable H2D/D2H The data transfer .
GPU Compute Time
To carry out CUDA Kernel GPU Delay .
Total Host Walltime
Execute from the first ( After preheating ) The host time from joining the team to the last execution completion .
Total GPU Compute Time
All executed GPU Calculate the sum of time . If this is significantly shorter than Total Host Walltime, be GPU It may not be fully utilized due to host side overhead or data transmission .
chart 1. stay Nsight The system operates normally trtexec Performance index of (ShuffleNet,BS=16,best,[email protected])
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-gNi3YCop-1656121427859)(trtexec.png)]
take --dumpProfile Logo added to trtexec To display the performance profile of each layer , This enables users to know which layers in the network are GPU It takes the most time to execute . The performance analysis of each layer is also applicable as CUDA Figure starts reasoning ( need CUDA 11.1 And higher ). Besides , Use --profilingVerbosity=detailed Flag build engine and add --dumpLayerInfo Flag to display detailed engine information , Including details and binding information of each layer . This allows you to understand the corresponding operations and parameters of each layer in the engine .
Serialized Engine Generation
If you generate a saved serialization engine file , You can pull it into another application that runs reasoning . for example , You can use TensorRT laboratory Run an engine with multiple execution contexts from multiple threads in a fully pipelined asynchronous manner , To test the performance of parallel reasoning . There are some warnings ; for example , If you use Caffe prototxt File and no model provided , Then random weights will be generated . Besides , stay INT8 In mode , Use random weights , It means trtexec Calibration function is not provided .
trtexec
If you ask --timingCacheFile Option provides timing cache files , Then the builder can load existing analysis data from it and add new analysis data entries during layer analysis . Timing cache files can be reused in other builder instances , To improve the execution time of the builder . It is recommended to only use the same hardware / software configuration ( for example ,CUDA/cuDNN/TensorRT edition 、 Equipment model and clock frequency ) Reuse this cache in ; otherwise , There may be functional or performance problems .
Common command line flags
This section lists commonly used trtexec Command line flags .
Signs of the construction phase
--onnx=<model>: Specify the input ONNX Model .--deploy=<caffe_prototxt>: Specify the CaffeprototxtModel .--uff=<model>: Specify the input UFF Model .--output=<tensor>: Specify the output tensor name . Only if the input model is UFF or Caffe Format is required .--maxBatch=<BS>: Specify the maximum batch size of the build engine . Only if the input model is UFF or Caffe Format is required . If the input model is ONNX Format , Please use--minShapes、--optShapes、--maxShapesFlag to control the range of input shapes , Including batch size .--minShapes=<shapes>,--optShapes=<shapes>,--maxShapes=<shapes>: Specify the range of input shapes used to build the engine . Only if the input model is ONNX Format is required .--workspace=<size in MB>: Specify the maximum workspace size allowed by the policy . This sign has been deprecated . You can use--memPoolSize=<pool_spec>sign .--memPoolSize=<pool_spec>: Specify the maximum size of the workspace allowed by the policy , as well as DLA The size of each loadable memory pool that will be allocated .--saveEngine=<file>: Specify the path to save the engine .--fp16、--int8、--noTF32、--best: Specify network level precision .--sparsity=[disable|enable|force]: Specify whether to use policies that support structured sparsity .disable: Disable all policies using structured sparsity . This is the default setting .enable: Use structured sparse enable policy . Only when ONNX When the weight in the file meets the requirements of structural sparsity , Will use strategies .force: Use structured sparse enable policy , And allowtrtexecCoverONNXThe weight in the document , To force them to have a structured sparse pattern . Please note that , Accuracy will not be preserved , So this is just to get reasoning performance .
--timingCacheFile=<file>: Specify the timing cache to load and save from .--verbose: Open detailed logging .--buildOnly: Build and save the engine without running reasoning .--profilingVerbosity=[layer_names_only|detailed|none]: Specify the level of analysis detail used to build the engine .--dumpLayerInfo , --exportLayerInfo=<file>: Print / Save the layer information of the engine .--precisionConstraints=spec: Control precision constraint settings .none: There is no limit to .prefer: If possible , Satisfy--layerPrecisions / --layerOutputTypesSet precision constraints .obey: Satisfied by--layerPrecisions / --layerOutputTypesSet precision constraints , Otherwise failure .
--layerPrecisions=spec: Control precision constraints of each layer . Only when the PrecisionConstraints It is only effective when it is set to obey or prefer . Norms are read from left to right , The back one will cover the front one . “ * ” Can be used as layerName To specify the default precision for all unspecified layers .- for example :
--layerPrecisions=*:fp16,layer_1:fp32Set the accuracy of all layers toFP16, exceptlayer_1Set toFP32.
- for example :
--layerOutputTypes=spec: Control the output type constraints of each layer . Only when thePrecisionConstraintsIt is only effective when it is set to obey or prefer . Norms are read from left to right , The back one will cover the front one . “ * ” Can be used aslayerNameTo specify the default precision for all unspecified layers . If a layer has multiple outputs , Can be used for this layer “ + ” Multiple types of separation .- for example :
--layerOutputTypes=*:fp16,layer_1:fp32+fp16Set the accuracy of all layer outputs toFP16, butlayer_1With the exception of , Its first output will be set toFP32, Its second output will be set toFP16.
- for example :
The sign of reasoning stage
--loadEngine=<file>: Load the engine from the serialization plan file , Not from the input ONNX、UFF or Caffe Model building engine .--batch=<N>: Specify the batch size to run inference . Only if the input model is UFF or Caffe Format is required . If the input model is ONNX Format , Or the engine is built using explicit batch dimensions , Please switch to--shapes.--shapes=<shapes>: Specify the input shape to run the inference .--warmUp=<duration in ms>,--duration=<duration in seconds>,--iterations=<N>: Specify the minimum duration of warm-up operation 、 The shortest duration of the inference run and the iteration of the inference run . for example , Set up--warmUp=0 --duration=0 --iterationsIt allows users to accurately control the number of iterations of running reasoning .--useCudaGraph: Capture reasoning to CUDA Graph and run reasoning by starting graph . When building TensorRT The engine contains CUDA When the operation is not allowed in the picture capture mode , This parameter can be ignored .--noDataTransfers: Turn off host to device and device to host data transmission .--streams=<N>: Reasoning that runs multiple streams in parallel .--verbose: Open detailed logging .--dumpProfile, --exportProfile=<file>: Print / Save the performance profile of each layer .
For all supported flags and detailed instructions , see also trtexec --help .
Details on how to build this tool and its use examples , see also GitHub:trtexec/README.md file .
边栏推荐
猜你喜欢

Sublime Text 配置php编译环境
Eco express micro engine system has supported one click deployment to cloud hosting

New version of dedecms collection and release plug-in tutorial tool

Web components series (VIII) -- custom component style settings
![Data science [9]: SVD (2)](/img/2c/f1a8c3ff34ff3f3cc6e26157a32bfd.png)
Data science [9]: SVD (2)

Redis - big key problem

数据科学【八】:SVD(一)

找到页面当前元素z-index最高的数值

Contest3147 - game 38 of 2021 Freshmen's personal training match_ A: chicken
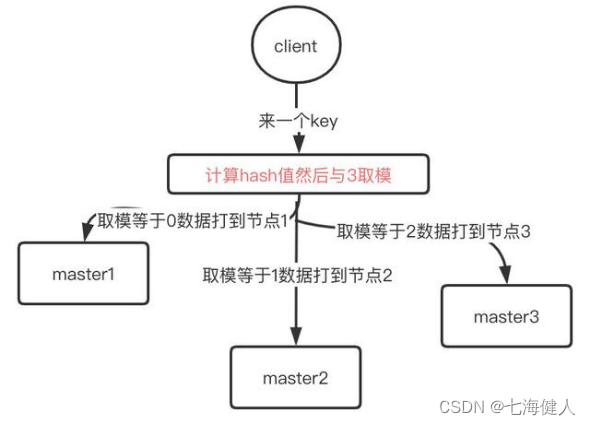
Redis——Cluster数据分布算法&哈希槽
随机推荐
构建学习tensorflow
js中正则表达式的使用
深入学习JVM底层(三):垃圾回收器与内存分配策略
LeetCode 39. 组合总和
BGP routing optimization rules and notification principles
Don't use the new WP collection. Don't use WordPress collection without update
数据科学【九】:SVD(二)
Is there a really free applet?
Data science [viii]: SVD (I)
最新CUDA环境配置(Win10 + CUDA 11.6 + VS2019)
Eco express micro engine system has supported one click deployment to cloud hosting
【张三学C语言之】—深入理解数据存储
BGP 路由優選規則和通告原則
MySQL的10大經典錯誤
加密压缩文件解密技巧
Introduce two automatic code generators to help improve work efficiency
Use of Arduino wire Library
ctf三计
AWD学习
It is said that Kwai will pay for the Tiktok super fast version of the video? How can you miss this opportunity to collect wool?