当前位置:网站首页>数据科学【九】:SVD(二)
数据科学【九】:SVD(二)
2022-07-02 06:10:00 【swy_swy_swy】
数据科学【九】:SVD(二)
数据准备
我们这次研究文本数据。我们可以从sklearn.datasets获得fetch_20newsgroups,即20个不同范畴的新闻文本集;这里我们选取四个范畴。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.stem.snowball import SnowballStemmer
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
news_data = fetch_20newsgroups(subset='train', categories=categories)
分词
每一篇文章可视为一个字符串。这个字符串由空格、换行符以及词组成。需要注意的是,同一个词可能有多种变形,比如时态、复数、变格等等,视语言而定。从诸多变形中“提取”词语,即为分词。我们可以调用SnowballStemmer()实现:
stemmer = SnowballStemmer('english')
stemmed_articles = []
for article in news_data.data:
stemmed_words = []
for word in article.split():
stemmed_words.append(stemmer.stem(word))
stemmed_articles.append(" ".join(stemmed_words))
词的重要性
给定一个词和一个文本集,如何量化这个词的重要性?一个指标是tf-idf特征。tf-idf特征有两部分构成,分别为:
- TF(t, a):词语t在文章a中出现的比率,即t出现的次数/文章总词数。
- IDF(t, s):文章集合的文章数比出现词语t的文章数的对数,即log10(文章总数/出现该词的文章数)
- tf-idf: TF 与IDF的乘积。
通过以上定义,我们知道在一个文本集中,对每一篇文本都有一个特征向量。
我们可以使用from sklearn.feature_extraction.text import TfidfVectorizer来获得tf-idf特征向量。
import pandas as pd
tfidfvctr = TfidfVectorizer(max_df = 0.25, min_df = 0.05)
tfidf_mat = tfidfvctr.fit_transform(stemmed_articles)
tfidf_df = pd.DataFrame(tfidf_mat.toarray())
tfidf_df.to_csv("tfidf.csv", index=False)
对tf-idf使用SVD降维
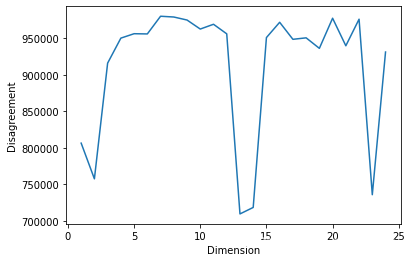
我们对上文得到的SVD矩阵降维,保留不同秩的特征值,并通过disagreemet distance评价聚类效果。
disagreement_distance = []
original_dataset = pd.read_csv("tfidf.csv", low_memory=False).values
for k in range(1,25):
dim_reduced_dataset = PCA(k).fit_transform(original_dataset)
kmeans = KMeans(n_clusters=4, init='k-means++', max_iter=100, n_init=10, random_state=0)
kmeans.fit_predict(dim_reduced_dataset)
labelsk = kmeans.labels_
disagreement_distance.append(disagreement_dist(labelsk, news_data.target))
plt.plot(range(1,25), disagreement_distance)
plt.ylabel('Disagreement')
plt.xlabel('Dimension')
plt.show()
边栏推荐
- Little bear sect manual query and ADC in-depth study
- The difference between session and cookies
- Style modification of Mui bottom navigation
- Web components series (VIII) -- custom component style settings
- Ti millimeter wave radar learning (I)
- Replace Django database with MySQL (attributeerror: 'STR' object has no attribute 'decode')
- LeetCode 83. Delete duplicate elements in the sorting linked list
- 格式校验js
- Use some common functions of hbuilderx
- JWT tool class
猜你喜欢

经典文献阅读之--Deformable DETR

VRRP之监视上行链路

Leverage Google cloud infrastructure and landing area to build enterprise level cloud native excellent operation capability

Spark overview
![[C language] simple implementation of mine sweeping game](/img/f7/15d561b3c329847971cabd4708c851.png)
[C language] simple implementation of mine sweeping game
网络相关知识(硬件工程师)
数据回放伴侣Rviz+plotjuggler

Detailed explanation of BGP message
深入学习JVM底层(五):类加载机制
深入了解JUC并发(一)什么是JUC
随机推荐
Use some common functions of hbuilderx
Shenji Bailian 3.54-dichotomy of dyeing judgment
LeetCode 78. subset
Ti millimeter wave radar learning (I)
Deep learning classification network -- vggnet
Compte à rebours de 3 jours pour l'inscription à l'accélérateur de démarrage Google Sea, Guide de démarrage collecté à l'avance!
VRRP之监视上行链路
Ros2 --- lifecycle node summary
Let every developer use machine learning technology
ES6的详细注解
Zabbix Server trapper 命令注入漏洞 (CVE-2017-2824)
Cglib代理-代码增强测试
The difference between session and cookies
LeetCode 83. 删除排序链表中的重复元素
LeetCode 78. 子集
LeetCode 39. Combined sum
51 single chip microcomputer - ADC explanation (a/d conversion, d/a conversion)
Use of Arduino wire Library
线性dp(拆分篇)
VLAN experiment of switching technology