当前位置:网站首页>Understanding weight sharing in convolutional neural networks
Understanding weight sharing in convolutional neural networks
2022-07-26 15:58:00 【Hua Weiyun】
First of all, it introduces the weight sharing implemented by single-layer network. Yuan Li introduces
Simply from share From the perspective of : Weight sharing is filter Value sharing for
Convolution neural network two core ideas :
1. Network local connection (Local Connectivity)
2. Convolution kernel parameter sharing (Parameter Sharing)
A key function of both is to reduce the number of parameters , Make the operation simple 、 Efficient , Can operate on very large data sets .
Let's use the most intuitive diagram , To clarify the role of both .
CNN The right way to open , As shown below 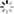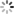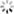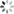
It can be summed up as : One  The convolution kernel of is scanned on the image , Feature extraction . Usually
The convolution kernel of is scanned on the image , Feature extraction . Usually  ,
, ![[ The formula ]](https://img-blog.csdnimg.cn/20200704172851630.png) ,
, ![[ The formula ]](https://img-blog.csdnimg.cn/2020070417290117.png) Convolution kernel of is commonly used , If channels by [ The formula ] Words (32,64 Is the number of commonly used channels ), So the total number of parameters is
Convolution kernel of is commonly used , If channels by [ The formula ] Words (32,64 Is the number of commonly used channels ), So the total number of parameters is 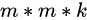 .
.
- Don't make parameter sharing
If not parameter sharing Realize the operation of the above figure , The convolution kernel structure will become as shown in the figure below

This is not difficult to find : The number of parameters of convolution kernel is consistent with the size of image pixel matrix , namely 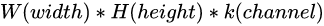
for example :Inception V3 The input image size of is 192192 Of ,** If the first floor 3332 The convolution kernel of removes parameter sharing , Then the number of parameters will become 192192*32, about 120 All the parameters , It's the original 288 Parameters 50 ten thousandfold .**
- Don't make local connectivity
If local connection is not used , That is, of course, a fully connected network (fully connect), That is, each element unit is fully connected with the neurons in the hidden layer , The network structure is as follows .

At this time, the parameter quantity becomes 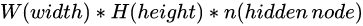 , Because the pixel matrix is very large , Therefore, more hidden layer nodes will be selected , At this time, the number of parameters of a single hidden layer usually exceeds 1 Ten million , It makes it difficult for the network to train .
, Because the pixel matrix is very large , Therefore, more hidden layer nodes will be selected , At this time, the number of parameters of a single hidden layer usually exceeds 1 Ten million , It makes it difficult for the network to train .
Here are pytorch Weight sharing code for multi-layer networks
import torchimport torch.nn as nnimport randomimport matplotlib.pyplot as plt # draw loss curve def plot_curve(data): fig = plt.figure() plt.plot(range(len(data)), data, color='blue') plt.legend(['value'], loc='upper right') plt.xlabel('step') plt.ylabel('value') plt.show() class DynamicNet(nn.Module): def __init__(self, D_in, H, D_out): super(DynamicNet, self).__init__() self.input_linear = nn.Linear(D_in, H) self.middle_linear = nn.Linear(H, H) self.output_linear = nn.Linear(H, D_out) def forward(self, x): h_relu = self.input_linear(x).clamp(min=0) # Repeated use Middle linear modular for _ in range(random.randint(0, 3)): h_relu = self.middle_linear(h_relu).clamp(min=0) y_pred = self.output_linear(h_relu) return y_pred # N It's batch size ;D It's the input dimension # H Is the hidden layer dimension ;D_out It's the output dimension N, D_in, H, D_out = 64, 1000, 100, 10 # Simulated training data x = torch.randn(N, D_in)y = torch.randn(N, D_out) model = DynamicNet(D_in, H, D_out)criterion = nn.MSELoss(reduction='sum')# It is difficult to train this strange model with ordinary random gradient descent , So we used momentum Method .optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9) loss_list = []for t in range(500): # Forward propagation y_pred = model(x) # Calculate the loss loss = criterion(y_pred, y) loss_list.append(loss.item()) # Zero gradient , Back propagation , Update weights optimizer.zero_grad() loss.backward() optimizer.step() plot_curve(loss_list)边栏推荐
- Change an ergonomic chair to relieve the old waist of sitting and writing code~
- VS2019Debug模式太卡进不去断点
- DELTA控制器RMC200
- Research and application of the whole configuration of large humanoid robot
- 白话详解决策树模型之使用信息熵构建决策树
- Digital warehouse: iqiyi digital warehouse platform construction practice
- Parker pump pv140r1k1t1pmmc
- Understand │ XSS attack, SQL injection, CSRF attack, DDoS attack, DNS hijacking
- Glyphs V3 Font Icon query
- 深度学习中图像增强技术的综合综述
猜你喜欢

Summary of QT plug-in development -- add plug-in menu in the main interface

大型仿人机器人整机构型研究与应用

How to use job plug-in type to call a kettle job through ETL scheduling tool taskctl?

Digital warehouse: iqiyi digital warehouse platform construction practice
.NET 手动获取注入对象

关于我写的IDEA插件能一键生成service,mapper....这件事(附源码)

SAP ABAP 守护进程的实现方式

【工具分享】自动生成文件目录结构工具mddir
Pandora IOT development board learning (RT thread) - Experiment 17 esp8266 experiment (learning notes)

TI C6000 TMS320C6678 DSP+ Zynq-7045的PS + PL异构多核案例开发手册(3)

随机推荐
Kalibr calibration realsensed435i -- multi camera calibration
How to use job plug-in type to call a kettle job through ETL scheduling tool taskctl?
bucher齿轮泵QX81-400R301
Pytorch installation CUDA corresponding
04 callable and common auxiliary classes
ROS问题及解决方案——依赖包安装以及无法修正错误
理解卷积神经网络中的权值共享
提问征集丨快来向NLLB作者提问啦!(智源Live第24期)
马斯克被曝绿了谷歌创始人:导致挚友二婚破裂,曾下跪求原谅
We were tossed all night by a Kong performance bug
企业数字化转型需要深入研究,不能为了转型而转型
超简单!只需简单几步即可为TA定制天气小助理!!
御神楽的学习记录之SoC FPGA的第一个工程-Hello World
LeetCode_ Prefix and_ Hash table_ Medium_ 525. Continuous array
.net get injection object manually
OSPF comprehensive experiment
单例模式
Gcc/g++ and dynamic and static libraries and GDB
ES6 advanced - query commodity cases
[leetcode] 33. Search rotation sort array