当前位置:网站首页>服务器SMP、NUMA、MPP体系学习笔记。
服务器SMP、NUMA、MPP体系学习笔记。
2022-07-06 15:57:00 【狂奔的乌龟】
目录
一、背景
商业化处理器都致力于单核处理器的发展,其性能已经发挥到极致,仅仅提高单核芯片的速度会产生过多热量且无法带来相应性能改善,但CPU性能需求大于CPU发展速度。
尽管通过增加流水线可以提高CPU的频率,但是由于缓存的增加与漏电流控制不力的因素,导致功率大幅增加,性能反而不如之前低频率的CPU。由于CPU的功率增加,导致CPU的散热问题也就更加严重,风冷已经不能解决问题了。
那么,此使新的技术就出现了:多核处理器。早在1996年就有第一款多核CPU原型Hydra。2001年IBM推出第一个商用多核处理器POWER4,2005年Intal和AMD多核处理器大规模应用。
多核处理器越来越流行,在服务器、桌面、上网本、平板、手机还是医疗设备、国防、航天等方面都得到了广泛的应用。
二、多核处理器的发展
2.1 从架构上区分
- 同构多核架构:系统中的处理器在架构上是相同的。
- 异构多核架构:系统中的处理器在架构上是不同的。
同构多核架构在硬件与软件设计上比较简单,通用性高。
异构多核处理器有:TI的达芬奇平台DM6000系列(ARM9+DSP)、Xilinx的Zynq7000系列(双核Cortex-A9+FPGA)、Cell处理器(1个64位POWERPC+8个32位协处理器)等等。
同构多核处理器有:Exynos4412,freescale i.mx6 dual和quad系列、TI的OMAP4460等,Intel的Core Duo、Core2 Duo等。
2.2 从运行模式上区分
在软件上区分的话,多核处理器常见有2种运行模式:
AMP(非对称多处理)
SMP(对称多处理)
2.2.1 SMP模式
二是SMP(Symmetric Multi-processing)模式:SMP模式的操作系统构架是多核处理器技术的一种变体,由一个操作系统实例控制所有处理器,所有处理器共享内存。与AMP模式中每个CPU上运行一个操作系统实例不同,SMP模式系统中所有CPU的地位相同,共同运行一个操作系统实例,所有CPU共享系统内存和外设资源。相对于AMP模式,SMP模式的操作系统具有可共享内存、较高的性能和功耗比、以及易实现负载均衡等优点,更能发挥发挥多核处理器的硬件优势。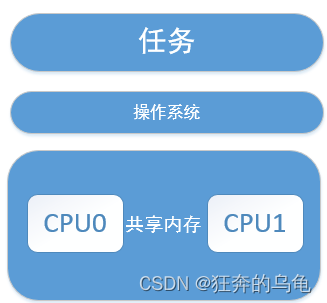
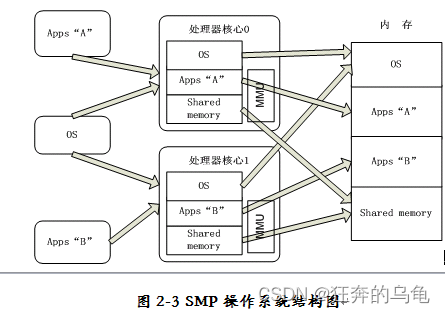
图2-3所示的SMP模式操做系统负责协调两个处理器核之间的工做,两个处理器核共享主存中同一个操做系统实例。虽然在每一个核中应用程序的地址相同,可是经过MMU把它们映射到主存中不一样的位置,从而实现了两个应用程序间代码和数据空间的隔离。
2.2.2 AMP模式
一是AMP(Asymmetric Multi-processing)模式:AMP模式的RTOS在各个CPU上均运行一个操作系统实例(这些操作实例不一定完全相同),各个操作系统拥有自己专用的内存,相互之间通过访问受限的共享内存进行通信。AMP模式的操作系统结构需要用户参与系统资源的分配。这种类型的RTOS应用比较少,商用操作系统中仅有Wind River公司的VxWorks 提供AMP模式的配置。
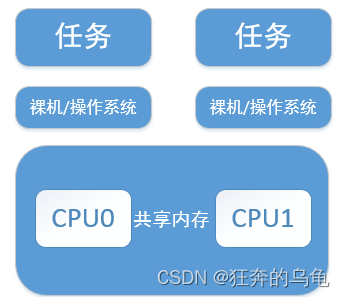
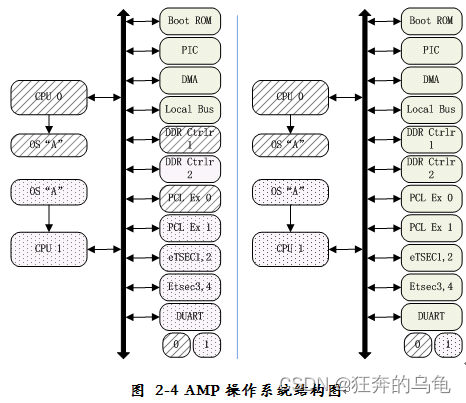
图2-4所示的是典型的AMP系统结构,每一个CPU上运行一个操做系统实例,各个操做系统都有本身独占的资源(最基本的是独占各自专用的CPU),其它资源或者由两个系统共享、或者分配给各个系统专用。资源的分配由用户来决定,于是对用户是可见的。在商用实时操做系统当中只有WindRiver公司的VxWorks提供了AMP模式的支持,目前该模式的应用较少。
2.2.3 SMP和AMP特征总结
SMP的特征是:只有一个操作系统实例,运行在多个CPU上,每个CPU的结构都是一样的,内存、资源共享。这种系统有一个最大的特点就是共享所有资源。
AMP的特征是:多个CPU,各个CPU在架构上不一样,每个CPU内核运行一个独立的操作系统或同一操作系统的独立实例,每个CPU拥有自己的独立资源。这种结构最大的特点在于不共享资源。
三、服务器架构的发展
3.1 从架构上区分
从系统架构来看,目前的商用服务器大体可以分为三类
- 对称多处理器结构
(SMP:Symmetric Multi-Processor) - 非一致存储访问结构
(NUMA:Non-Uniform Memory Access) - 海量并行处理结构
(MPP:Massive Parallel Processing)
共享存储型多处理机有两种模型
- 均匀存储器存取(Uniform-Memory-Access,简称UMA)
- 模型非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型
3.1.1 SMP(Symmetric Multi-Processor)
所谓对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此SMP也被称为一致存储器访问结构(UMA:Uniform Memory Access)对SMP服务器进行扩展的方式包括增加内存、使用更快的CPU、增加CPU、扩充I/O(槽口数与总线数)以及添加更多的外部设备(通常是磁盘存储)。
SMP服务器的主要特征是共享,系统中所有资源(CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,那就是它的扩展能力非常有限。
对于SMP服务器而言,每一个共享的环节都可能造成SMP服务器扩展时的瓶颈,而最受限制的则是内存。由于每个CPU必须通过相同的内存总线访问相同的内存资源,因此随着CPU数量的增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使CPU性能的有效性大大降低。实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU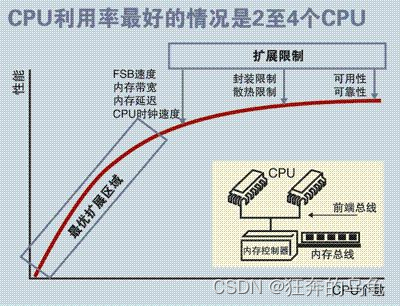
3.1.2 NUMA(Non-Uniform Memory Access)
由于SMP在扩展能力上的限制,人们开始探究如何进行有效地扩展从而构建大型系统的技术,NUMA就是这种努力下的结果之一利用NUMA技术,可以把几十个CPU(甚至上百个CPU)组合在一个服务器内。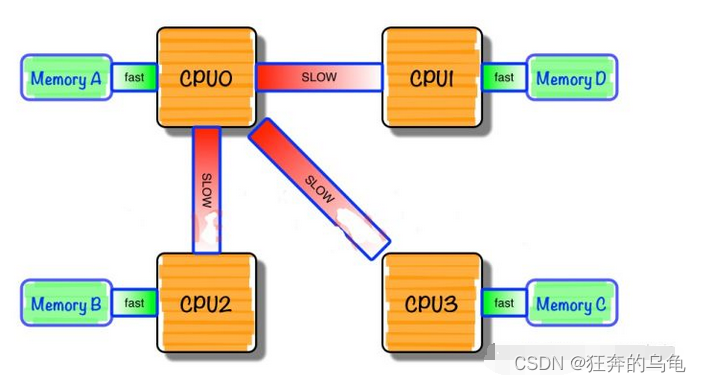
- NUMA多处理机模型如图所示,其访问时间随存储字的位置不同而变化。其共享存储器物理上是分布在所有处理机的本地存储器上。所有本地存储器的集合组成了全局地址空间,可被所有的处理机访问。处理机访问本地存储器是比较快的,但访问属于另一台处理机的远程存储器则比较慢,因为通过互连网络会产生附加时延。
- NUMA服务器的基本特征是具有多个CPU模块,每个CPU模块由多个CPU(如4个)组成,并且具有独立的本地内存、I/O槽口等。
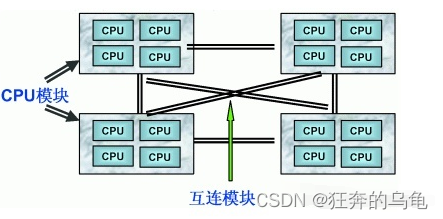
由于其节点之间可以通过互联模块(如称为Crossbar Switch)进行连接和信息交互,因此每个CPU可以访问整个系统的内存(这是NUMA系统与MPP系统的重要差别)。显然,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问NUMA的由来。
由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同CPU模块之间的信息交互。利用NUMA技术,可以较好地解决原来SMP系统的扩展问题,在一个物理服务器内可以支持上百个CPU。比较典型的NUMA服务器的例子包括HP的Superdome、SUN15K、IBMp690等。
但NUMA技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。如HP公司发布Superdome服务器时,曾公布了它与HP其它UNIX服务器的相对性能值,结果发现,64路CPU的Superdome (NUMA结构)的相对性能值是20,而8路N4000(共享的SMP结构)的相对性能值是6.3. 从这个结果可以看到,8倍数量的CPU换来的只是3倍性能的提升。
3.1.3 MPP(Massive Parallel Processing)
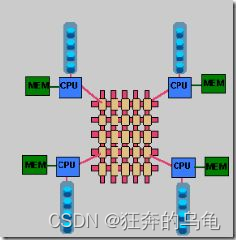
和NUMA不同,MPP提供了另外一种进行系统扩展的方式,它由多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制,目前的技术可实现512个节点互联,数千个CPU。目前业界对节点互联网络暂无标准,如 NCR的Bynet,IBM的SPSwitch,它们都采用了不同的内部实现机制。但节点互联网仅供MPP服务器内部使用,对用户而言是透明的。
在MPP系统中,每个SMP节点也可以运行自己的操作系统、数据库等。但和NUMA不同的是,它不存在异地内存访问的问题。换言之,每个节点内的CPU不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution)。
但是MPP服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。目前一些基于MPP技术的服务器往往通过系统级软件(如数据库)来屏蔽这种复杂性。举例来说,NCR的Teradata就是基于MPP技术的一个关系数据库软件,基于此数据库来开发应用时,不管后台服务器由多少个节点组成,开发人员所面对的都是同一个数据库系统,而不需要考虑如何调度其中某几个节点的负载。
3.2 架构优缺点对比
3.2.1 NUMA、MPP、SMP之间性能的区别
NUMA的节点互联机制是在同一个物理服务器内部实现的,当某个CPU需要进行远地内存访问时,它必须等待,这也是NUMA服务器无法实现CPU增加时性能线性扩展。MPP的节点互联机制是在不同的SMP服务器外部通过I/O实现的,每个节点只访问本地内存和存储,节点之间的信息交互与节点本身的处理是并行进行的。因此MPP在增加节点时性能基本上可以实现线性扩展。SMP所有的CPU资源是共享的,因此完全实现线性扩展。
3.2.2 NUMA、MPP、SMP之间扩展的区别
NUMA理论上可以无限扩展,目前技术比较成熟的能够支持上百个CPU进行扩展。如HP的SUPERDOME。
MPP理论上也可以实现无限扩展,目前技术比较成熟的能够支持512个节点,数千个CPU进行扩展。
SMP扩展能力很差,目前2个到4个CPU的利用率最好,但是IBM的BOOK技术,能够将CPU扩展到8个。
MPP是由多个SMP构成,多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务。
3.2.3 MPP和SMP、NUMA之间应用的区别
MPP的优势
MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。由于MPP系统因为要在不同处理单元之间传送信息,在通讯时间少的时候,那MPP系统可以充分发挥资源的优势,达到高效率。也就是说:操作相互之间没有什么关系,处理单元之间需要进行的通信比较少,那采用MPP系统就要好。因此,MPP系统在决策支持和数据挖掘方面显示了优势。
SMP的优势
MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点。在通讯时间多的时候,那MPP系统可以充分发挥资源的优势。因此当前使用的OTLP程序中,用户访问一个中心数据库,如果采用SMP系统结构,它的效率要比采用MPP结构要快得多。
NUMA架构的优势
NUMA架构来看,它可以在一个物理服务器内集成许多CPU,使系统具有较高的事务处理能力,由于远地内存访问时延远长于本地内存访问,因此需要尽量减少不同CPU模块之间的数据交互。显然,NUMA架构更适用于OLTP事务处理环境,当用于数据仓库环境时,由于大量复杂的数据处理必然导致大量的数据交互,将使CPU的利用率大大降低。
四、总结
传统的多核运算是使用SMP(Symmetric Multi-Processor )模式:将多个处理器与一个集中的存储器和I/O总线相连。所有处理器只能访问同一个物理存储器,因此SMP系统有时也被称为一致存储器访问(UMA)结构体系,一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。很显然,SMP的缺点是可伸缩性有限,因为在存储器和I/O接口达到饱和的时候,增加处理器并不能获得更高的性能,与之相对应的有AMP架构,不同核之间有主从关系,如一个核控制另外一个核的业务,可以理解为多核系统中控制平面和数据平面。
NUMA模式是一种分布式存储器访问方式,处理器可以同时访问不同的存储器地址,大幅度提高并行性。 NUMA模式下,处理器被划分成多个”节点”(node), 每个节点被分配有的本地存储器空间。 所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多。
NUMA 的主要优点是伸缩性。NUMA 体系结构在设计上已超越了 SMP 体系结构在伸缩性上的限制。通过 SMP,所有的内存访问都传递到相同的共享内存总线。这种方式非常适用于 CPU 数量相对较少的情况,但不适用于具有几十个甚至几百个 CPU 的情况,因为这些 CPU 会相互竞争对共享内存总线的访问。NUMA 通过限制任何一条内存总线上的 CPU 数量并依靠高速互连来连接各个节点,从而缓解了这些瓶颈状况。
边栏推荐
- Should the jar package of MySQL CDC be placed in different places in the Flink running mode?
- Dockermysql modifies the root account password and grants permissions
- AcWing 4300. Two operations (minimum number of BFS searches)
- The worse the AI performance, the higher the bonus? Doctor of New York University offered a reward for the task of making the big model perform poorly
- Without CD, I'll teach you a trick to restore the factory settings of win10 system
- Station B boss used my world to create convolutional neural network, Lecun forwarding! Burst the liver for 6 months, playing more than one million
- With the help of this treasure artifact, I became the whole stack
- TDengine 社区问题双周精选 | 第二期
- How to implement Lua entry of API gateway
- The important data in the computer was accidentally deleted by mistake, which can be quickly retrieved by this method
猜你喜欢
B站大佬用我的世界搞出卷積神經網絡,LeCun轉發!爆肝6個月,播放破百萬
Master binary tree in one article
【通信】两层无线 Femtocell 网络上行链路中的最优功率分配附matlab代码

The programmer refused the offer because of low salary, HR became angry and netizens exploded

Gpt-3 is a peer review online when it has been submitted for its own research

Gold three silver four, don't change jobs
The problem that dockermysql cannot be accessed by the host machine is solved
Station B Big utilise mon monde pour faire un réseau neuronal convolutif, Le Cun Forward! Le foie a explosé pendant 6 mois, et un million de fois.
云原生(三十二) | Kubernetes篇之平台存储系统介绍

Stop saying that microservices can solve all problems
随机推荐
基于PaddlePaddle平台(EasyDL)设计的人脸识别课堂考勤系统
Docker mysql5.7 how to set case insensitive
PDF批量拆分、合并、书签提取、书签写入小工具
Computer reinstallation system teaching, one click fool operation, 80% of people have learned
How to implement Lua entry of API gateway
Docker starts MySQL and -emysql_ ROOT_ Password = my secret PW problem solving
The best sister won the big factory offer of 8 test posts at one go, which made me very proud
The programmer said, "I'm 36 years old, and I don't want to be rolled, let alone cut."
The problem that dockermysql cannot be accessed by the host machine is solved
让 Rust 库更优美的几个建议!你学会了吗?
Implementation steps of mysql start log in docker
Let me ask you if there are any documents or cases of flynk SQL generation jobs. I know that flynk cli can create tables and specify items
安全保护能力是什么意思?等保不同级别保护能力分别是怎样?
Nftscan Developer Platform launches Pro API commercial services
【无人机】多无人协同任务分配程序平台含Matlab代码
Is the more additives in food, the less safe it is?
公链与私链在数据隐私和吞吐量上的竞争
前置机是什么意思?主要作用是什么?与堡垒机有什么区别?
TDengine 社区问题双周精选 | 第二期
AI表现越差,获得奖金越高?纽约大学博士拿出百万重金,悬赏让大模型表现差劲的任务...