当前位置:网站首页>Entropy information entropy cross entropy
Entropy information entropy cross entropy
2022-07-06 23:28:00 【TranSad】
In information theory , We often use entropy to express the degree of chaos and uncertainty of information . The greater the entropy , The more uncertain the information is .
The formula for entropy is as follows :
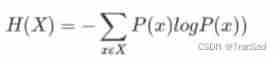
( notes :log Default to 2 Bottom )
Taking this formula apart is actually very simple : A minus sign , One p(x) as well as log(p(x)). We know that the probability of an event is 0-1 Between , Such a probability value is sent into log function ( Here's the picture ), It must be less than 0 Of , So add a symbol outside , We can get the common positive entropy .
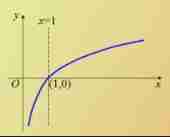
When the probability value tends to 0 perhaps 1 when ( That is, the certainty is very strong ), be p(x) perhaps log(p(x)) Will tend 0, Entropy will be small ; When the probability value tends to 1/2 when ( That is, the uncertainty is very strong ), be p(x) perhaps log(p(x)) Do not tend to 0, Entropy will be large .
for instance , Let's say there are 4 A ball .
1. Suppose it's all black balls ( Minimum uncertainty ), Its entropy is :-1*log1=0
2. hypothesis 2 black ball 2 White ball ( Start with uncertainty ), The entropy is :-0.5log0.5-0.5log0.5=0.301
3. hypothesis 1 black ball 1 White ball 1 yellow ball 1 Basketball ( High uncertainty ), The entropy is :-0.25log0.25--0.25log0.25-0.25log0.25-0.25log0.25 = 0.602
Evaluate the classification results
We know that entropy can be used to see the uncertainty of information , Then we can use entropy to evaluate the effect of classification tasks , For example, we have four pictures , Two pictures of cats : cat 1, cat 2, Two week dog chart : Dog 1, Dog 2. We feed it into the classifier , Obviously, this is a dichotomy problem , Now our two models get the following results respectively :
Model one :( cat 1, cat 2)/( Dog 1, Dog 2).
Model two :( cat 1, Dog 2)/( cat 2, Dog 1).
obviously , Put the model 1 The calculation formula of input entropy of classification results , We can get 0 The entropy of , That is, the uncertainty is 0, Explain that each category is classified correctly . And model 2 The classification results of , You will find that entropy is very large , It shows that the classification effect of the model is not good .
Of course , The above is just a simple example of using entropy to evaluate classification tasks , Only applicable to unsupervised tasks .
Cross entropy
In more cases , Our classification task is labeled , For supervised learning , We use cross entropy to evaluate . The idea of cross entropy is different from the above , It starts from every sample , Calculate the distance between the predicted value and the expected value of each sample ( We call it cross entropy ), Formula for :
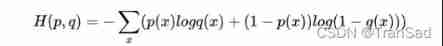
among p For the expected output , A probability distribution q For actual output ,H(p,q) For cross entropy .
For example, the cat and dog classification task , We assume that the cat is 10, Dog for 01, Then if the model classifies cats into dogs , Now p=10,q=01,H(p,q)=-(1*log(0)+0*log(1))=∞. It's not surprising to calculate infinity here , Because it's the opposite , So the calculated “ distance ” A very large . In more cases , We will have something similar q=(0.1,0.9) So the value of the , At this time, the calculated entropy is a non infinite but equally large value .
Information entropy solves the problem of weighing times
Information entropy is very useful , For example, we often encounter such a classic problem : Yes n A little ball , Only one ball weighs differently from the others ( Heavier than other balls ), Ask us how we weigh by balance , You can find this ball at least a few times ?
If we didn't study information theory , The first method I came up with was dichotomy :“ Divide the balls into two parts , Keep the heavy part , Another dichotomy ……” And so on. . But by calculating information entropy , We can deviate from the actual weighing method , Directly from “ God's perspective ” To get the final answer —— This is the wonder of applying information entropy .
How to solve it ? We know there are n A ball , The probability of each ball being heavier is 1/n, Then the total amount of information is :
H(x) = n* (-1/n)*log(1/n) = logn
It uses “ The amount of information ” To describe the result , Information quantity is another variable closely related to entropy in information theory —— Looking at the formula, it seems that the method of calculating the amount of information is also very easy to understand and closely related to the entropy formula .( The more direct calculation formula of information is I=log2(1/p))
And weigh once every time , We can get three results : Left , Right side and the same weight . So the amount of information that can be eliminated is :
H(y)=3*(-1/3)*log(1/3)=log3
therefore , The minimum number of weighing times required is H(x)/H(y)=logn/log3 Time .
The above is just a very simple example , Sometimes we don't know whether the unusual ball is heavy or light , At this time, our uncertainty about the whole will increase , That is, the total amount of information H(x) It will change —— The specific idea of adding is : Finding a different ball requires logn The amount of information , It is necessary to judge whether the ball is heavy or light log2 The amount of information , So the total amount of information H(x) by log2+logn=log2n.
At this time, the minimum number of weighing times required is H(x)/H(y)=log2n/log3 Time .
This article mainly combs the information entropy 、 Concepts and usages such as cross entropy , Finally, it is simply extended to the use of information in information theory to solve the problem of balance weighing . Originally, I wanted to write another three door question ( It can also be seen from the idea of information entropy ), But I feel that I'm getting off the subject and pulling away …… That's it .
边栏推荐
- Two week selection of tdengine community issues | phase II
- Nftscan Developer Platform launches Pro API commercial services
- What can be done for traffic safety?
- Knowledge * review
- What does front-end processor mean? What is the main function? What is the difference with fortress machine?
- Leetcode problem solving - 889 Construct binary tree according to preorder and postorder traversal
- spark调优(二):UDF减少JOIN和判断
- MySQL实现字段分割一行转多行的示例代码
- The same job has two sources, and the same link has different database accounts. Why is the database list found in the second link the first account
- Ajout, suppression et modification d'un tableau json par JS
猜你喜欢
Koa2 addition, deletion, modification and query of JSON array

Hard core observation 545 50 years ago, Apollo 15 made a feather landing experiment on the moon
With the help of this treasure artifact, I became the whole stack
None of the strongest kings in the monitoring industry!
B站大佬用我的世界搞出卷積神經網絡,LeCun轉發!爆肝6個月,播放破百萬

企業不想換掉用了十年的老系統
Let's see through the network i/o model from beginning to end
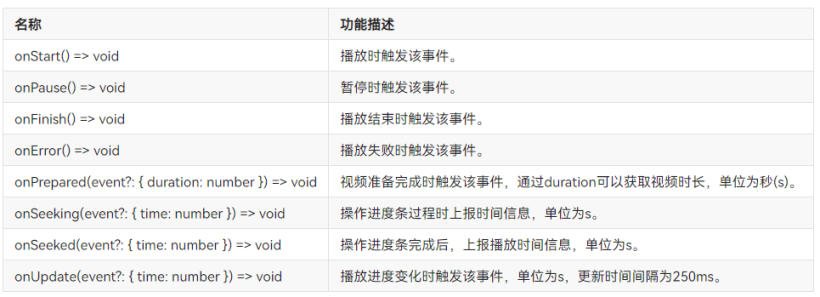
Dayu200 experience officer homepage AITO video & Canvas drawing dashboard (ETS)

(1)长安链学习笔记-启动长安链

Case recommendation: An Qing works with partners to ensure that the "smart court" is more efficient
随机推荐
DevSecOps软件研发安全实践——发布篇
Wu Enda 2022 machine learning course evaluation is coming!
同构+跨端,懂得小程序+kbone+finclip就够了!
Implementation steps of mysql start log in docker
每日刷题记录 (十五)
[launched in the whole network] redis series 3: high availability of master-slave architecture
js對JSON數組的增删改查
How to choose the server system
Example code of MySQL split string as query condition
电脑重装系统u盘文件被隐藏要怎么找出来
AcWing 4300. Two operations (minimum number of BFS searches)
MySQL数据库之JDBC编程
(DART) usage supplement
请问oracle-cdc用JsonDebeziumDeserializationSchema反序列化
Cover fake big empty talk in robot material sorting
Enterprises do not want to replace the old system that has been used for ten years
Per capita Swiss number series, Swiss number 4 generation JS reverse analysis
What does front-end processor mean? What is the main function? What is the difference with fortress machine?
mysql连接vscode成功了,但是报这个错
Word2vec (skip gram and cbow) - pytorch