当前位置:网站首页>BasicVSR++: Improving Video Super-Resolutionwith Enhanced Propagation and Alignment
BasicVSR++: Improving Video Super-Resolutionwith Enhanced Propagation and Alignment
2022-07-04 07:00:00 【mytzs123】
Abstract
Recursive structure is a common framework choice for video super-resolution tasks . The most advanced method BasicVSR Adopt two-way propagation and feature alignment , Effectively use the information in the whole input video . In this study , We redesign it by proposing the alignment of second-order mesh propagation and flow guided deformation BasicVSR. We show that , By enhancing the recursive framework of propagation and alignment , The spatiotemporal information in the misplaced video frames can be used more effectively . Under similar computational constraints , New components can improve performance . especially , Our model BasicVSR++ When the number of parameters is similar ,PSNR Than BasicVSR Higher than 0.82 dB. In addition to video super resolution ,BasicVSR++ It can also be well extended to other video recovery tasks , Such as compressed video enhancement . stay 2021 Of NTIRE in ,BasicVSR++ Won three champions and one runner up in the video super-resolution and compressed video enhancement challenges .
1. Introduction
Video super resolution (VSR) Challenging , Because people need to collect supplementary information of misplaced video frames for recovery . A popular method is sliding window frames [9、32、35、38], Each frame in the video is recovered by using the frames in a short time window . Different from sliding window frame , Recursive frameworks try to exploit long-term dependencies by propagating underlying features . Generally speaking , Compared with the method in sliding window frame , These methods [8、10、11、12、14、27] Allow more compact models . However , The problem of transmitting long-term information and cross frame alignment features in the cyclic model is still difficult .
Chan A recent study by et al. Examined these issues carefully . It will be common VSR The pipeline is divided into four parts , namely spread 、 alignment 、 Aggregation and upsampling , And put forward the basic VSR. stay BasicVSR in , Two way propagation technology is used to extract information from the whole input video for reconstruction . For alignment , Use optical flow to distort features .BasicVSR It is a simple and powerful trunk , Here you can easily add components to improve performance . However , Its rudimentary design in communication and alignment limits the power of information aggregation . therefore , The network is often difficult to recover fine details , Especially when dealing with occluded complex areas . These shortcomings require us to carry out perfect design in terms of communication and arrangement .
In this work , We design second order grid The deformable arrangement guided by propagation and flow is redesigned BasicVSR, So that information can be spread and gathered more effectively .
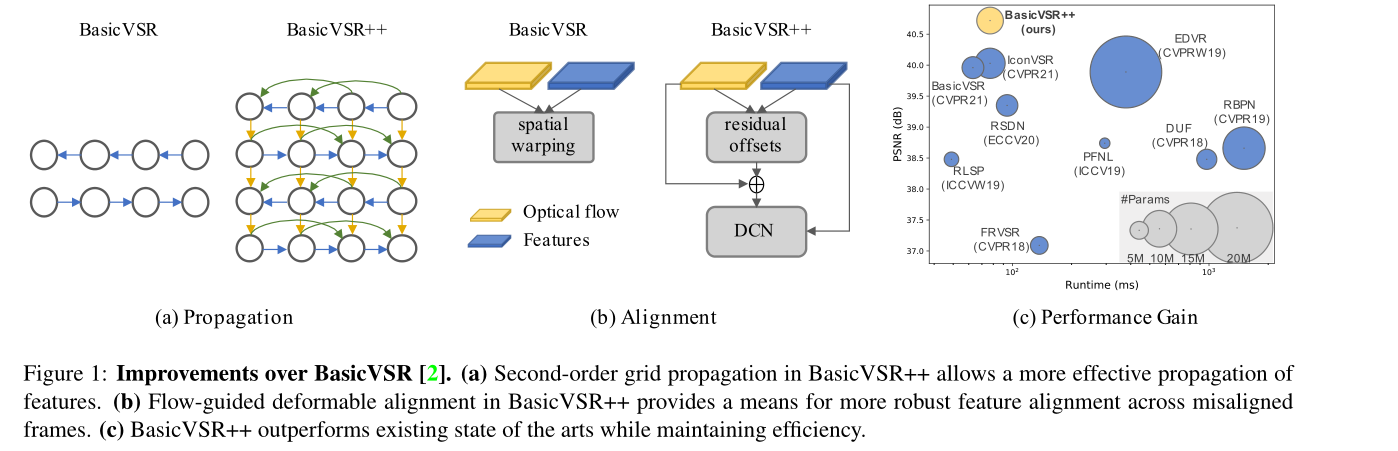
1、 Proposed second-order grid propagation , Pictured 1(a) Shown , It's solved BasicVSR Two limitations of :i) We allow more active two-way communication , Arrange in a grid , and ii) Let's relax BasicVSR Assumption of first-order Markov attributes in , And connect the second order [28] Integrate into the network , So that information can be aggregated from different space-time positions . These two modifications have improved the information flow in the network , It improves the robustness of the network to occlusion and small areas .
2、BasicVSR It shows the advantages of using optical flow for time alignment . However , Optical flow is unstable to occlusion . Inaccurate traffic estimation may jeopardize recovery performance . Deformation alignment [32、33、35] stay VSR Shows its advantages , But it is difficult to train in practice [3]. In order to overcome the instability of training while using deformable alignment , We propose flow guided deformable alignment , Pictured 1(b) Shown . In the proposed module , We didn't learn directly DCN Offset [6,42], Instead, the optical flow field is used as the basic offset refined by the residual flow field to reduce the burden of offset learning . The latter is better than the original DCN Shift to learn more stably .
The above two components are novel , More discussion can be found in the relevant work section . Thanks to more effective design ,BasicVSR++ You can use a lighter trunk than similar products . therefore ,BasicVSR++ While maintaining efficiency , It greatly exceeds the existing technical level , Include BasicVSR and IconVSR( More detailed BasicVSR variant )( chart 1(c)). especially , And previous BasicVSR comparison , When the number of parameters is similar ,REDS4 Peak signal-to-noise ratio on (PSNR) The gain is 0.82 dB【35】. Besides ,BasicVSR++ stay 2021 NTIRE Video super resolution [29] And compressed video enhancement [39] Win three champions and one runner up in the challenge .
2. Related Work
Recurrent Networks: Recursive framework is a popular structure used in various video processing tasks , Like super resolution [8, 10, 11, 12, 14, 27]、 Defuzzifying ring [24, 41] And frame interpolation [36]. for example ,RSDN[12] Adopt one-way propagation , With recursive detail structure block and hidden state adaptation module , To enhance the robustness to appearance changes and error accumulation .Chan wait forsomeone [2] Put forward BasicVSR. This work proves that two-way communication is more important than one-way communication , To make better use of the characteristics of time . Besides , The study also shows the advantages of feature alignment in aligning highly correlated but misaligned features . We ask readers to refer to [2], Learn about the detailed comparison of these components with more traditional propagation and alignment . In our experiment , We focus on... And BasicVSR Compare , Because it is the most advanced VSR Method .
Grid Connections: Grid like designs can be seen in various visual tasks , Such as target detection [5、30、34]、 Semantic segmentation [7、30、34、43] And frame interpolation [25]. Usually , These designs will be given images / The feature is decomposed into multiple resolutions , And use grid to capture fine and rough information across resolutions . Different from the above method ,BasicVSR++ Do not use multi-scale design . contrary , The grid structure is designed to propagate across time in a bidirectional manner . We connect different frameworks to the grid , To repeatedly optimize features , Improve the ability to express .
Higher-Order Propagation: Higher order propagation is studied to improve gradient flow 【16、20、28】. These methods show the improvement of different tasks , Including classification [16] And language modeling [28]. However , These methods do not consider time alignment , This is in VSR Is crucial in our mission . In order to achieve time alignment in second-order propagation , We extend the flow guided deformable alignment to the second-order setting , Incorporate alignment into our communication plan .
Deformable Alignment: Some projects 【32、33、35、37】 Use deformable alignment .TDAN[32] Use deformable convolution to perform alignment at the feature level .EDVR[35] Furthermore, a pyramid cascade deformable with multi-scale design is proposed (PCD) aim . lately ,Chan wait forsomeone [3] Deformable alignment is analyzed , And show that relative to flow based alignment , Performance gain comes from offset diversity . suffer [3] Inspired by the , We use deformable alignment , But a new format is adopted to overcome the instability of training [3]. Our flow guided deformable alignment is different from the offset fidelity loss [3]. The latter uses optical flow as a loss function during training . by comparison , We directly incorporate optical flow into our module as a basic offset , So as to provide clearer guidance in the process of training and reasoning .
3. Methodology
BasicVSR++ Contains two valid modifications , For improved propagation and alignment . Pictured 2 Shown , Given an input video , First, the remaining blocks are applied to extract features from each frame . Then, under our second-order grid propagation scheme, the propagation characteristics , Where alignment is performed by our flow guided deformable alignment . After communication , The aggregated features generate the output image through convolution and pixel shuffling .
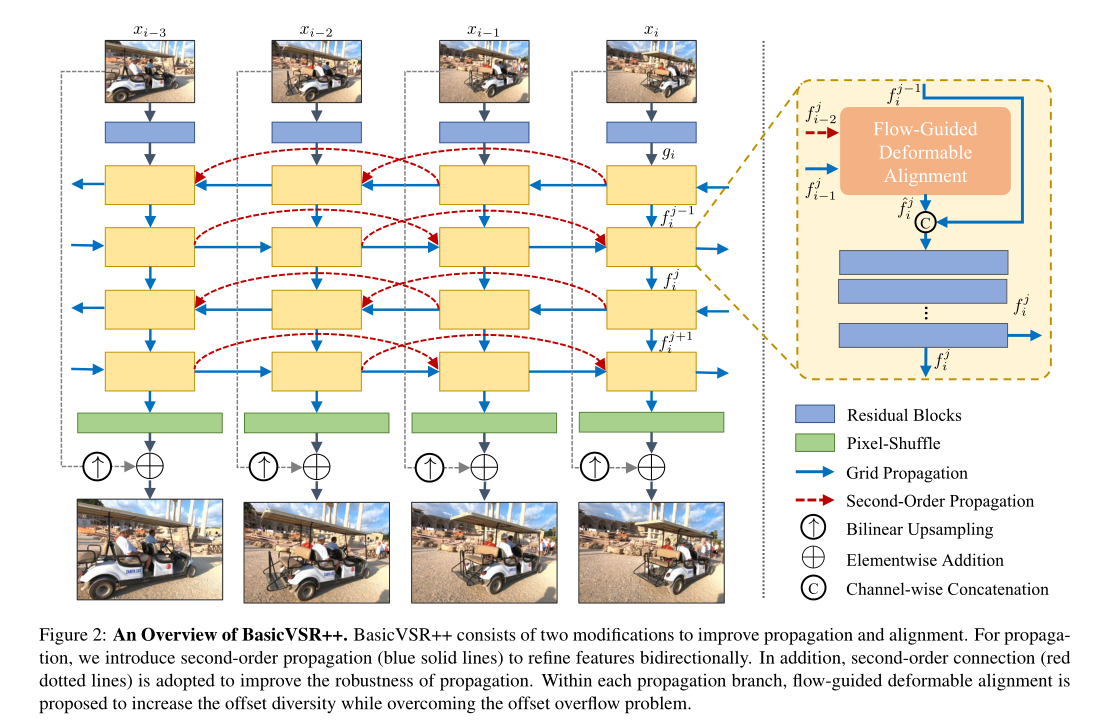 3.1. Second-Order Grid Propagation
3.1. Second-Order Grid Propagation
Most existing methods use one-way propagation [12、14、27]. Some works [2、10、11] Two way propagation is used to utilize the information available in the video sequence . especially ,IconVSR[2] It consists of a coupled propagation scheme with sequential connected branches , To promote information exchange .
Based on the effectiveness of two-way communication , We designed a grid propagation scheme , To achieve repeated refinement through propagation . More specifically , The intermediate features propagate back and forth in time in an alternating manner . By spreading , Sure “ revisit ” Information from different frames , And use it for feature refinement . Compared with existing work that only propagates features once , Grid propagation can repeatedly extract information from the entire sequence , So as to improve the expression ability of features .
In order to further improve the robustness of communication , We relaxed BasicVSR The assumption of the first-order Markov property , Adopt second-order connection , Realize the second-order Markov chain . Through this relaxation , Information can be gathered from different space-time locations , Improved robustness and effectiveness in occluded and fine areas .
Combine the above two parts , We designed the following second-order mesh propagation . set up xi Input image for ,gi To pass through multiple residual blocks from xi The features extracted from the ,f j i For in the j The second branch of propagation i Characteristics of time step calculation . In this section , We describe the procedure of forward propagation , The program definition of backward propagation is similar . In order to calculate the characteristics f j i, We first use our proposed flow guided deformable alignment pair f j i-1 and f j i-2 Align ( Follow the second-order Markov chain ), This will be discussed in the next section .

3.2. Flow-Guided Deformable Alignment
Deformable alignment [33, 35] Than flow based alignment [9, 38] There are obvious improvements , This is due to deformable convolution (DCN)[6, 42] Inherent offset diversity in [3]. However , Deformable registration modules can be difficult to train [3]. The instability of training often leads to offset overflow , Deteriorated the final performance . In order to take advantage of the diversity of offsets , At the same time, overcome instability , We suggest using optical flow to guide deformable registration , This is motivated by the close relationship between deformable registration and optical flow based registration [3]. chart 3 Graphic descriptions are shown in . In the rest of this section , We will introduce the alignment procedure of forward propagation in detail . The program definition of backward propagation is similar . In order to simplify the notation , Superscript j Was omitted .
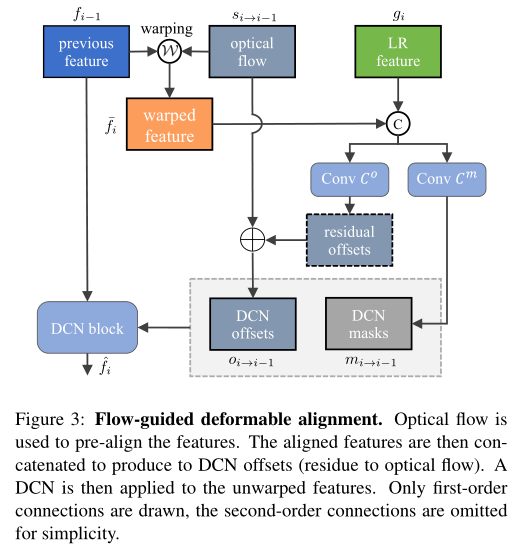
Discussion: With the existing direct calculation DCN Method of offset [32, 33, 35, 37] Different , The flow guided deformable alignment we proposed uses optical flow as the guide . The benefits are twofold . First , because CNN Local receptive fields are known , Pre align features by using optical flow , It can help learn relational sets . secondly , By learning residuals only , Network work only needs to learn a small deviation from optical flow , It reduces the burden of typical deformable alignment modules . Besides ,DCN The modulation mask in is not a direct connection distortion feature , But as an attention map to weigh the contribution of different pixels , Provide additional flexibility .
4. Experiments

The training uses two widely used data sets :REDS[23] and Vimeo-90K[38]. about RED, follow BasicVSR[2], We use REDS43 As test set , Use REDSval44 As validation set . The rest is for training . We use Vid4【21】、UDM10【40】 and Vimeo90K-T【38】 as well as Vimeo-90K As test set . All models use 4× Down sampling for testing , Use two kinds of degradation - Double triple (BI) And fuzzy down sampling (BD)
We use Adam Optimizer [17] and Cosine Annealing programme [22]. The initial learning rate of the main network and traffic network is set to 1×10−4 and 2.5×10−5. The total number of iterations is 600K, before 5000 In the next iteration , The weight of the flow network is fixed . Batch size is 8, Input LR The patch size of the frame is 64×64. We use Charbonnier Loss [4], Because it is better than traditional “2- Loss [18] Better handle outliers and improve performance . We use pre trained SPyNet[26] As our streaming network . Its parameters and running time are comprehensively considered in our method . The number of remaining blocks per branch is set to 7. The number of functional channels is 64 individual . Detailed experimental setup and model structure are provided in the supplementary materials .
4.1. Comparisons with State-of-the-Art Methods
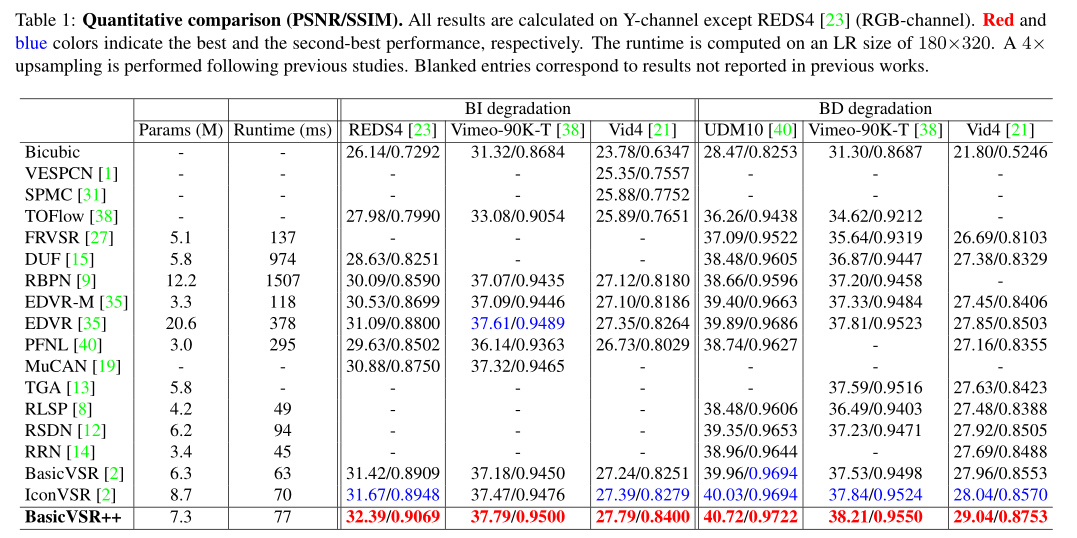 We're going to talk to 16 Compare the two models , A comprehensive experiment was carried out , As shown in the table 1 Shown . surface 1 The quantitative results are summarized , chart 1(c) Provides speed and performance comparisons . Be careful , The above parameters include the parameters in the optical flow network ( if there be ). So this comparison is fair
We're going to talk to 16 Compare the two models , A comprehensive experiment was carried out , As shown in the table 1 Shown . surface 1 The quantitative results are summarized , chart 1(c) Provides speed and performance comparisons . Be careful , The above parameters include the parameters in the optical flow network ( if there be ). So this comparison is fair
As shown in the table 1 Shown ,BasicVSR++ State of the art performance has been achieved on all data sets of both degradation . especially ,BasicVSR++ be better than EDVR[35],EDVR It is a large capacity sliding window method , The peak signal-to-noise ratio is as high as 1.3 dB, At the same time, the parameters are reduced 65%. With the most advanced IconVSR[2] comparison ,BasicVSR++ With fewer parameters , But it improves 1 dB. As shown in the table 2 Shown , Even if we train a lighter version BasicVSR++( Expressed as BasicVSR++(S)), Its network parameters and running time are similar to BasicVSR and IconVSR Quite a , Our model still shows better than BasicVSR Improved 0.82 dB, Than IconVSR Improved 0.57 dB. This gain is in VSR Is considered significant .
Some qualitative comparisons are shown in the figure 11 To 14 Shown .BasicVSR++ Successfully restored fine details . especially ,BasicVSR++ Is the recovery diagram 11 Middle wheel spokes 、 chart 13 Middle stairs and figure 14 The only way of building structure . More examples are provided in the supplementary materials .
5. Ablation Studies
To understand the contribution of the proposed component , We start from the baseline , Insert components step by step . From the table 3 It can be seen that , Each component brings a significant improvement , The peak signal-to-noise ratio ranges from 0.14 dB To 0.46 dB Unequal .
Theoretically , Our proposed propagation scheme can be extended to higher order and more propagation iterations . However , When increasing from first order to second order , The performance gain is quite large ( namely (B)→(C) ) And one or two iterations ( namely (C)→BasicVSR++), We observed in the preliminary experiment , Further increasing the number and number of iterations will not lead to significant improvement ( The peak signal-to-noise ratio is 0.05 dB), So we keep the number of iterations as 2.
Second-Order Grid Propagation:
We further provide some qualitative comparisons , To understand the contribution of the proposed communication programme . Pictured 7 Two examples of , In areas with fine details and complex textures , The contribution of second-order propagation and grid propagation is more significant . In these regions , The information available for reconstruction in the current frame is limited . In order to improve the output quality of these areas , Effective information aggregation from other video frames is needed . Through our second-order propagation scheme , Information can be transmitted through robust and effective communication . This kind of supplementary information basically helps to recover the details . As shown in the example , The network successfully restored the details using our components , Without the corresponding part of our component, fuzzy output will be generated .
Flow-Guided Deformable Alignment: In the figure 8(a-d) in , We compare the offset with BasicVSR++ Compare the optical flow calculated by the flow estimation module . By learning only the residuals of optical flow , The offset generated by this network is highly similar to optical flow , But there are obvious differences . And only from sports ( Optical flow ) Indicates the baseline of a spatial location aggregation information , Our proposed module allows information to be retrieved from multiple locations around , Provides additional flexibility .
This flexibility enables features to have better quality , Pictured 8(g-h) Shown . When using optical flow to perform warping , Due to the interpolation operation in space warps , Aligned features contain blurred edges . contrary , By collecting more information from neighbors , The feature of module alignment proposed by us is clearer , Keep more details .
To prove the superiority of our design , We compared our alignment module with two variants :(1) Optical flow is not used .(2) Optical flow is used to offset fidelity loss [3], That is, optical flow is only used as supervision in the loss function ( Instead of being used as a basic offset in our method ). As shown in the table 4 Shown , If you do not use optical flow as a guide , Instability can lead to training collapse , Lead to PSNR Very low value . When using offset fidelity loss , Training is stable . However , A decrease is observed in our complete model 2.17 dB. our flowguided Deformable alignment combines optical flow directly into the network , To provide clearer guidance , To get better results
Temporal Consistency: ad locum , We studied time consistency , This is a VSR Another important direction in . Compared with sliding window frame , Recursive frameworks essentially maintain better time consistency . In the sliding window frame ( for example EDVR[35]) in , Each frame is reconstructed independently . In this design , Consistency between outputs cannot be guaranteed . contrary , In a recursive framework ( for example BasicVSR[2]), The output is related through the propagation of intermediate features . Time transmission essentially helps to maintain better time consistency .
In the figure 9 in , We compared BasicVSR++ And two most advanced methods ——EDVR and BasicVSR Time profile between . For the sliding window method ,EDVR The time profile of contains significant noise , Indicates flicker artifacts in the output video . contrary , For recursive networks , Without explicit time consistency modeling , come from BasicVSR and BasicVSR++ The configuration file of shows better consistency . However ,BasicVSR The section of still contains discontinuities . Thanks to our enhanced propagation and alignment ,BasicVSR++ It can gather richer information from video frames , Show a smoother time transition . The video results are given in the supplementary materials .
6. NTIRE 2021 Challenge Results
stay NTIRE 2021,BasicVSR++ Win the video super-resolution track with a compact and efficient structure [29]. except VSR outside ,BasicVSR++ It can also be well extended to other recovery tasks .BasicVSR++ Won two champions and one runner up in the compressed video enhancement challenge [39]. chart 10 It shows the recovery results of three different patches of compressed video .BasicVSR++ Successfully reduced artifacts , And produce better quality output . The good performance in the competition proves BasicVSR++ Versatility and versatility .
7. Conclusion
In this work , We redesigned it with two new components BasicVSR, To improve its propagation and alignment performance in video super-resolution tasks . Our model BasicVSR++ While maintaining efficiency , It is much better than the existing advanced level . These designs are well extended to other video recovery tasks , Including compressed video enhancement . These components are universal , We speculate that they will be used for other video based enhancement or recovery tasks , For example, deblurring and denoising .
A. Network Architecture
We use pre trained SPyNet[26] As our streaming network . The number of remaining blocks for initial feature extraction is set to 5, The number of remaining blocks per propagation branch is set to 7. The function channel is set to 64. Our second-order deformable alignment architecture is very similar to the first-order corresponding structure ( Figures in the main paper 3). The only difference is , The pre alignment features and optical flow from different time steps are connected in series , And pass it to the offset estimation module Co And mask estimation module Cm. Their structure is shown in table 5. We will DCN The kernel size is set to 3, The number of deformable groups is set to 16. The code will be released .
B. Experimental Settings
Data sets . The training uses two widely used data sets :REDS[23] and Vimeo-90K[38]. about RED, follow BasicVSR[2], We use REDS45 As test set , Use REDSval46 As validation set . The rest is for training . We use Vid4[21]、UDM10[40] and Vimeo-90K-T[38] as well as Vimeo-90K As test set .
边栏推荐
- [network data transmission] FPGA based development of 100M / Gigabit UDP packet sending and receiving system, PC to FPGA
- Why does the producer / consumer mode wait () use while instead of if (clear and understandable)
- Mysql 45讲学习笔记(十四)count(*)
- [backpack DP] backpack problem
- [FPGA tutorial case 8] design and implementation of frequency divider based on Verilog
- the input device is not a TTY. If you are using mintty, try prefixing the command with ‘winpty‘
- Can the out of sequence message complete TCP three handshakes
- A new understanding of how to encrypt industrial computers: host reinforcement application
- How to input single quotation marks and double quotation marks in latex?
- 响应式移动Web测试题
猜你喜欢

Knowledge payment applet dream vending machine V2
Vulhub vulnerability recurrence 76_ XXL-JOB
Uniapp applet subcontracting

Responsive - media query

The cloud native programming challenge ended, and Alibaba cloud launched the first white paper on application liveliness technology in the field of cloud native

The final week, I split
the input device is not a TTY. If you are using mintty, try prefixing the command with ‘winpty‘
BasicVSR++: Improving Video Super-Resolutionwith Enhanced Propagation and Alignment

Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and
GoogleChromePortable 谷歌chrome浏览器便携版官网下载方式
随机推荐
Set JTAG fuc invalid to normal IO port
Chapter 1 programming problems
notepad++如何统计单词数量
Node connection MySQL access denied for user 'root' @ 'localhost' (using password: yes
Redis面试题集
校园网络问题
tars源码分析之1
uniapp小程序分包
The final week, I split
What is the use of cloud redis? How to use cloud redis?
A new understanding of how to encrypt industrial computers: host reinforcement application
Check and display one column in the known table column
Mysql 45讲学习笔记(十)force index
List of top ten professional skills required for data science work
Responsive - media query
Google Chrome Portable Google Chrome browser portable version official website download method
Fundamentals of SQL database operation
颈椎、脚气
[FPGA tutorial case 7] design and implementation of counter based on Verilog
What is Gibson's law?