当前位置:网站首页>Mysql database underlying foundation column
Mysql database underlying foundation column
2022-07-03 09:47:00 【Vacanda forever】

When you need to rebuild the index ?
When the index is established, it occurs frequently in actual business use update delete operation
How to determine whether the index should be rebuilt ?
1. Index inclination , See if it wastes space , Analyze index
analyze index #index_name validate structrue;
2. stay session Query in index_stats surface
select height,DEL_LF_ROWS/LF_ROWS from index_stats;
When height Result , Index depth , Height from root node to leaf node , perhaps DEL_LF_ROWS/LF_ROWS>0.2 Under the circumstances , Need to consider re indexing .
Index reconstruction
drop index #index_name
create index #index_name on #table_name(index_column);
But it is time-consuming to delete and rebuild the index
Therefore, it is generally recommended to use the refactoring statement of the index
alter index #index_name rebuild;
alter index #index_name rebuild online;
rebuild It is an effective method to rebuild the index , Because the index reconstruction is based on the existing data , If the reconstruction process , There are other users to operate the table data , You can use online, Avoid possible lock problems in index reconstruction .
namely rebuild It will block DML operation , however rebuild online Can't
Hash Index and B Tree index
hash The bottom layer of the index is the hash table , When looking for data , The corresponding key value will be obtained by hashing the data , Then get the final data according to the back table .
B+ A tree is a multi-path balanced lookup tree , Each search starts from the root node , Passing through a node is once IO operation ,B+ Each leaf node of the tree has data connections , Find the leaf node to get the checked key value , Then query to determine whether it is necessary to query data back to the table .
hash It is faster to find the equivalent , however hash Is chaotic , Therefore, range lookup is not supported , and B+ The leaf nodes of the tree follow the rule of "low on the left and high on the right" . Therefore, range search is supported .
Except for the scope ,hash Indexes also cannot support index sorting .
meanwhile ,hash Indexes also do not support fuzzy queries , And the leftmost prefix matching of multi column indexes , The reason is also because hash Functions are hashed .
hash The index cannot avoid returning to the table in any scenario , and B+ The tree is clustered in the index , When overwriting the index, you can complete the query through the index . Avoid returning to your watch .
Business
Four characteristics of transactions : Atomicity , Uniformity , persistence , Isolation, .
Atomic realization principle : Recall all successfully executed statements when the transaction is rolled back .InnoDB Rollback is due to undo.log, When the transaction modifies the database ,InnoDB I'm going to generate the corresponding undo.log. When a transaction fails , call rollback Method , Cause transaction rollback , The use of undo.log Rollback to previous data .
The implementation principle of persistence : If you need to operate the disk every time you read and write data , Will reduce the efficiency of the database . therefore InnoDB Cache is provided in ,(Buffer Pool), It contains the mapping of disk data , As a cache for accessing the database . When the database reads data , from BufferPool Read the data first , If the database does not , Then read from the database , Put... After reading Buffer Pool, When writing scenes , The data about the write operation is written first Buffer Pool,Buffer Pool The data in is periodically flushed into the disk . That is to brush dirty . Among them the Buffer Pool Function and redis In fact, it's quite like , So it also brings many and redis The same downtime as caching . therefore InnoDB There will be redo.log To solve when Buffer Pool outage , The data is not saved to the disk . When the transaction commits , call fsync The interface of redo.log To brush plate , If Mysql Downtime , It can be read on reboot redo.log Data recovery database in .
Why? Buffer Pool It's better than redo.log Writing logs to disk is slow ?
Brushwork (BufferPool) It's random IO, Every time the data is modified, it is random . however redo.log Additional operation of , In sequence IO.
There is a lot of data in the dirty brush , In pages ,redo.log Only the part that needs to be written , Invalid IO Reduce .
Isolation implementation principle : Isolation is achieved through the locking mechanism , Before a transaction modifies data, it must obtain a lock to modify data . According to the lock granularity , It is divided into table lock , Row lock , And on the watch lock , Lock between row locks , Table lock is when operating data , Lock the whole watch , Only one transaction can be committed successfully .
Row lock is to lock the row of data of the operation , Good concurrency , But locking itself is a resource consuming operation , Therefore, locking the table can also save resources .
MyISAM The storage engine only supports table locks ,InnoDB Support row lock .
meanwhile ,InnoDB Also through MVCC Ensure isolation ,MVCC yes Mutli-Version Concurrency Control, Multi version concurrency control protocol , The advantage is that reading is unlocked .
Lock type of database ,InnoDB The storage engine has two types of row level locks , It is divided into shared lock and exclusive lock .
Shared lock : Allow transactions to read a row of data .
Exclusive lock : Allow transactions to delete or modify a row of data .
Shared locks are mainly used to realize lock compatibility , Business A get a Shared lock of row data , Simultaneous transaction B Also available a Shared lock of row data , But when things C Want to get a Exclusive lock of row data , Must wait for business AB All released a Only the shared lock of the row can obtain the exclusive lock .
About deadlocks
Deadlock refers to the scenario in which two or more transaction execution processes compete for unified resources at the same time, resulting in waiting for each other , Without external force, we can't continue to push .
The direct method to solve deadlock is timeout , When two transactions wait for each other , When the waiting time of a transaction is set to exceed a certain threshold , One of the transactions is rolled back , Another waiting transaction continues to run .
The database will also adopt wait-for graph( Waiting chart ) Detection of deadlock , Compared with lock timeout , This is a way to actively discover deadlocks ,wait-for graph Our database will store two kinds of information : A list of lock information , Transaction waiting list
A graph can be constructed through the linked list , If there is a circuit in the diagram , Means there is a deadlock , Resources wait for each other , Judgment will be made before each transaction request , If there is a deadlock InnoDB Will roll back undo The smallest amount of transactions .

边栏推荐
- 307. Range Sum Query - Mutable
- Characteristics of PUCCH formats
- Raspberry pie installation SciPy
- 软件测试工程师是做什么的 通过技术测试软件程序中是否有漏洞
- Solve editor MD uploads pictures and cannot get the picture address
- Jetson Nano 自定义启动图标kernel Logo cboot logo
- STM32 serial communication principle
- 【力扣刷题笔记(二)】特别技巧,模块突破,45道经典题目分类总结,在不断巩固中精进
- Leetcode daily question (1362. closest divisors)
- Equality judgment of long type
猜你喜欢
![[CSDN] C1 training problem analysis_ Part III_ JS Foundation](/img/b2/68d53ad09688f7fc922ac65e104f15.png)
[CSDN] C1 training problem analysis_ Part III_ JS Foundation

UCI and data multiplexing are transmitted on Pusch - determine the bit number of harqack, csi1 and csi2 (Part II)
Leetcode daily question (931. minimum falling path sum)

MySQL data manipulation language DML common commands

UCI and data multiplexing are transmitted on Pusch - Part I
[CSDN]C1訓練題解析_第三部分_JS基礎
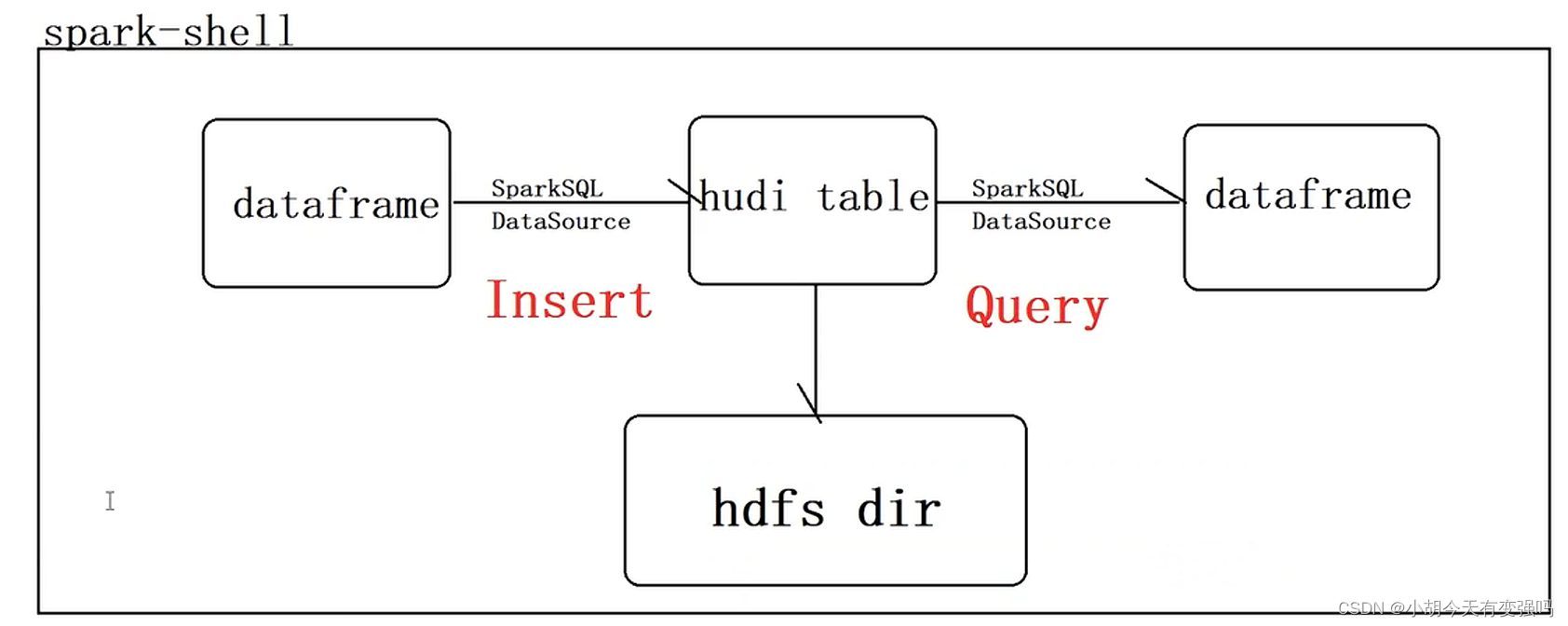
Hudi quick experience (including detailed operation steps and screenshots)
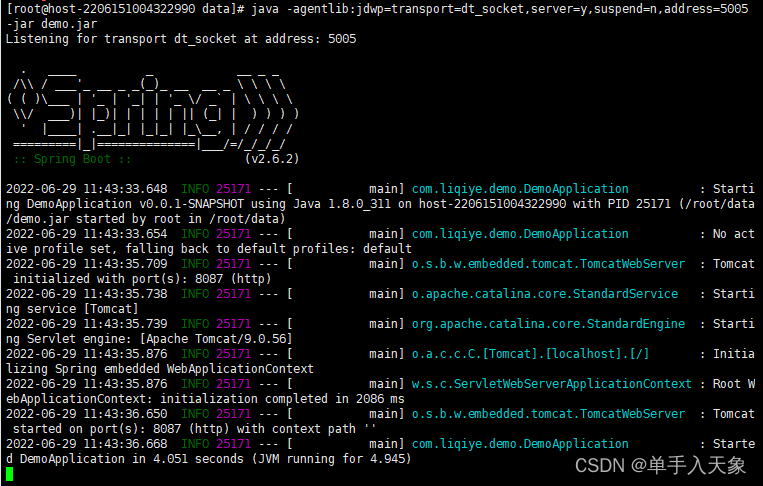
IDEA远程断点调试jar包项目

MySQL environment variable configuration

Difference of EOF
随机推荐
Epoll read / write mode in LT and et modes
Fundamentals of Electronic Technology (III)__ Logic gate symbols in Chapter 5
STM32 interrupt priority management
Successful graduation [3]- blog system update...
numpy. Reshape() and resize() functions
Jestson nano downloads updated kernel and DTB from TFTP server
PIP references domestic sources
Nodemcu-esp8266 development (vscode+platformio+arduino framework): Part 2 --blinker_ Hello_ WiFi (lighting technology - Mobile App control routine)
万字手撕七大排序(代码+动图演示)
PolyWorks script development learning notes (I) - script development environment
Make the most basic root file system of Jetson nano and mount NFS file system on the server
【22毕业季】我是毕业生yo~
Installation and uninstallation of pyenv
CEF下载,编译工程
Shell logic case
顺利毕业[3]-博客系统 更新中。。。
数字身份验证服务商ADVANCE.AI顺利加入深跨协 推进跨境电商行业可持续性发展
Hudi quick experience (including detailed operation steps and screenshots)
PolyWorks script development learning notes (III) -treeview advanced operation
Win10 install elk