当前位置:网站首页>Hudi quick experience (including detailed operation steps and screenshots)
Hudi quick experience (including detailed operation steps and screenshots)
2022-07-03 09:25:00 【Did Xiao Hu get stronger today】
List of articles
Hudi Quick experience
This example is to complete the following process :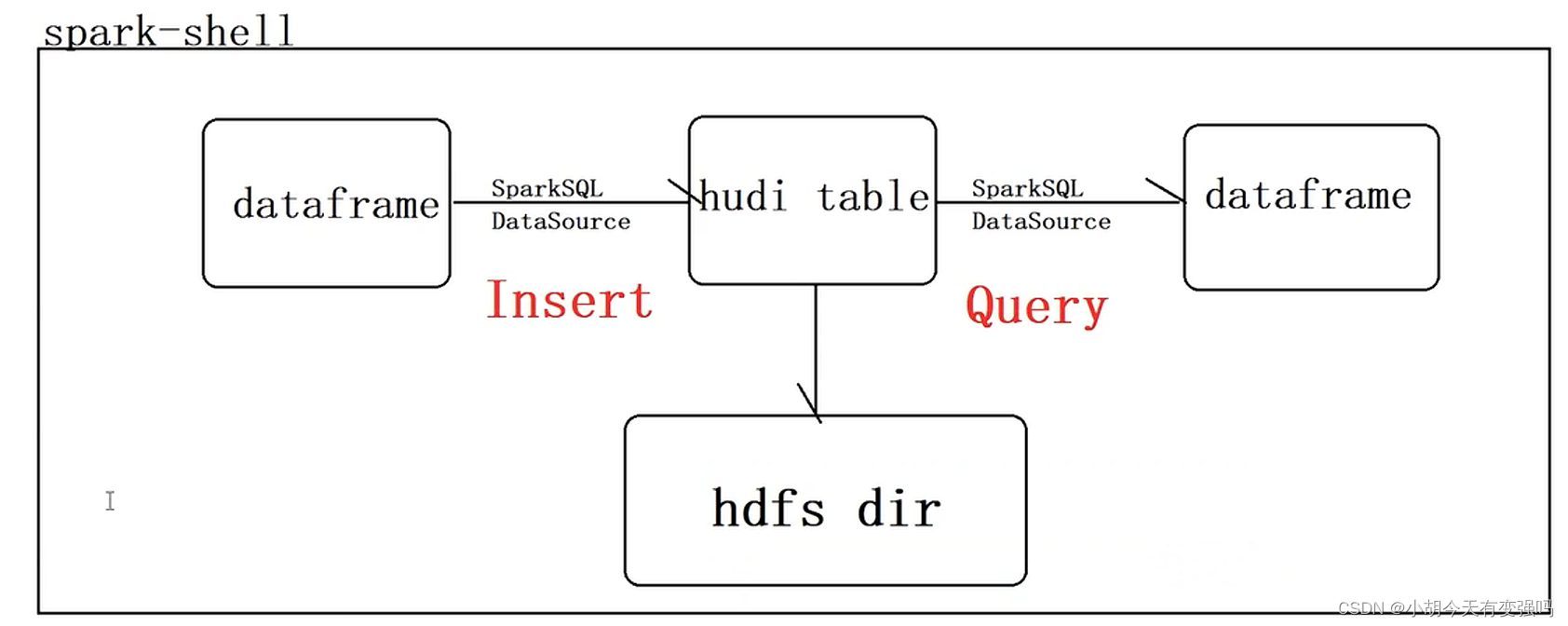
It needs to be installed in advance hadoop、spark as well as hudi And components .
spark Installation tutorial :
https://blog.csdn.net/hshudoudou/article/details/125204028?spm=1001.2014.3001.5501
hudi Compilation and installation tutorial :
https://blog.csdn.net/hshudoudou/article/details/123881739?spm=1001.2014.3001.5501
Attention only Hudi Management data , Don't store data , Do not analyze data .
start-up spark-shel l add to jar package
./spark-shell \
--master local[2] \
--jars /home/hty/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar,\
/home/hty/hudi-jars/spark-avro_2.12-3.0.1.jar,/home/hty/hudi-jars/spark_unused-1.0.0.jar.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
You can see three jar Packages are uploaded successfully :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-ljXalTIm-1654780395209)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609165739566.png)]](/img/4e/23f4b3aca8c7a6873cbec44a13e746.png)
Import the package and set the storage directory :
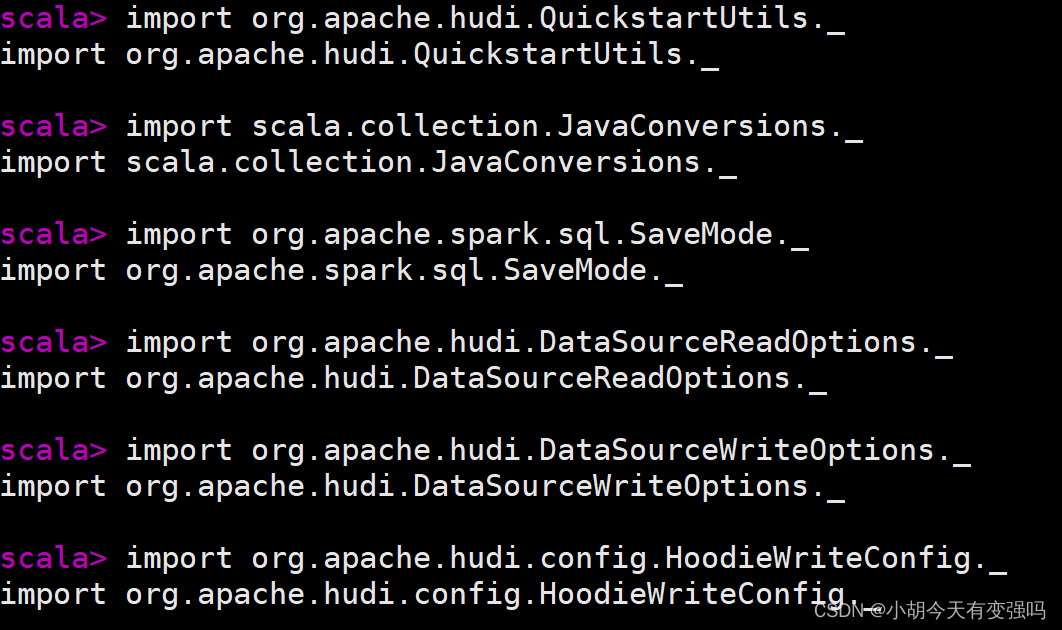
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hadoop102:8020/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator

Simulation produces Trip Ride data
val inserts = convertToStringList(dataGen.generateInserts(10))
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-dd2CZtFP-1654780395209)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609171909589.png)]](/img/55/8bb7afe823c468b768ef2f5518c245.png)

3. The simulated data List Convert to DataFrame Data sets
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
4. View post conversion DataFrame Data sets Schema Information

5. Select the relevant field , View simulated sample data
df.select("rider", "begin_lat", "begin_lon", "driver", "fare", "uuid", "ts").show(10, truncate=false)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-q01Acwo7-1654780395209)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609172907830.png)]](/img/3e/23e59af23e0446eff5ce2e6d120f01.png)
insert data
The simulation will produce Trip data , Save to Hudi In the table , because Hudi Born based on Spark frame , therefore SparkSQL Support Hudi data source , Direct communication too format specify data source Source, Set relevant properties and save data .
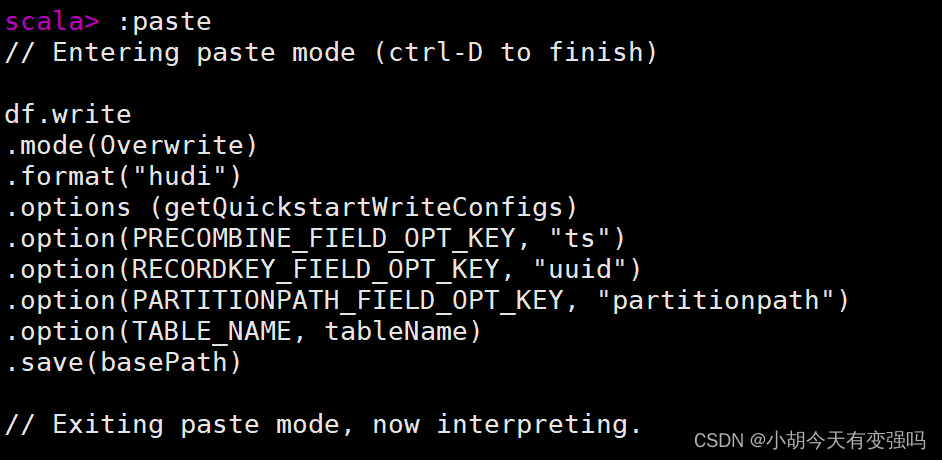
df.write
.mode(Overwrite)
.format("hudi")
.options (getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(RECORDKEY_FIELD_OPT_KEY, "uuid")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
.option(TABLE_NAME, tableName)
.save(basePath)
getQuickstartWriteConfigs, Set write / Update data to Hudi when ,Shuffle Number of time partitions
PRECOMBINE_FIELD_OPT_KEY, When data is merged , According to the primary key field
RECORDKEY_FIELD_OPT_KEY, Unique for each record id, Support multiple fields
PARTITIONPATH_FIELD_OPT_KEY, Partition field used to store data
paste Pattern , Press after pasting ctrl + d perform .

Hudi Table data is stored in HDFS On , With PARQUET Stored in columns
from Hudi Read data in table , Same use SparkSQL How to load data from external data sources , Appoint format Data source and related parameters options:
val tripSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
It specifies Hudi Table data storage path , Using regularization Regex How to match , Because of saving Hudi Table belongs to partition table , And it is a three-level partition ( phase When Hive Specify three partition fields in the table ), Use expressions ://// Load all the data .
View table structure :
tripSnapshotDF.printSchema()

Save to Hudi There are many data in the table 5 A field , These fields belong to Hudi Related fields used when managing data .
Will get Hudi Table data DataFrame Register as a temporary view , use SQL Method: query and analyze data based on business :
tripSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
utilize sqark SQL Inquire about
spark.sql("select fare, begin_lat, begin_lon, ts from hudi_trips_snapshot where fare > 20.0").show()

Check the newly added fields :
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, _hoodie_file_name from hudi_trips_snapshot").show()
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-hbKEhmlv-1654780395210)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609204702530.png)]](/img/95/1074f107be182b59b65c0ee7f35467.png)
These newly added fields are hudi Fields added for table management .
Reference material :
边栏推荐
- Win10 quick screenshot
- Utilisation de hudi dans idea
- Flink学习笔记(十一)Table API 和 SQL
- Install third-party libraries such as Jieba under Anaconda pytorch
- 【毕业季|进击的技术er】又到一年毕业季,一毕业就转行,从动物科学到程序员,10年程序员有话说
- Temper cattle ranking problem
- ERROR: certificate common name “*.” doesn’t match requested ho
- Simple use of MATLAB
- Numerical analysis notes (I): equation root
- Crawler career from scratch (V): detailed explanation of re regular expression
猜你喜欢

npm install安装依赖包报错解决方法
MySQL installation and configuration (command line version)

【点云处理之论文狂读经典版7】—— Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs

2022-2-13 learning xiangniuke project - version control
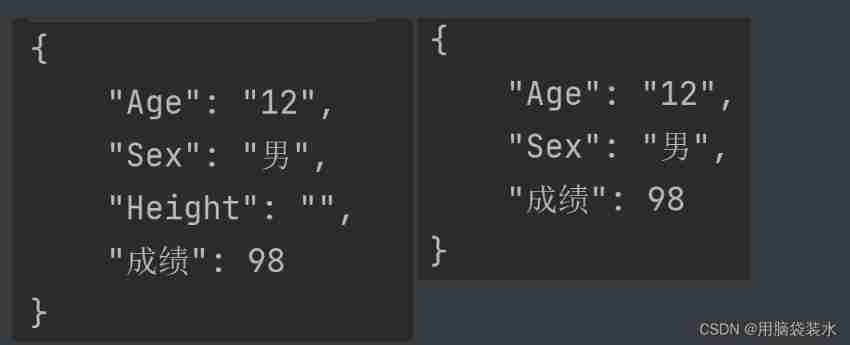
Go language - JSON processing
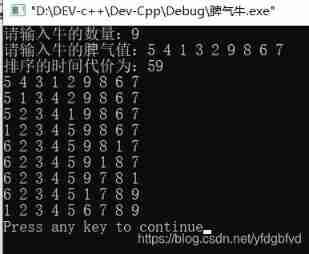
Temper cattle ranking problem

Construction of simple database learning environment

【Kotlin学习】类、对象和接口——带非默认构造方法或属性的类、数据类和类委托、object关键字
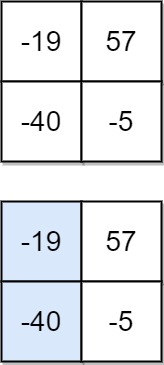
LeetCode每日一题(931. Minimum Falling Path Sum)

【Kotlin疑惑】在Kotlin类中重载一个算术运算符,并把该运算符声明为扩展函数会发生什么?
随机推荐
Trial of the combination of RDS and crawler
Just graduate student reading thesis
【点云处理之论文狂读经典版9】—— Pointwise Convolutional Neural Networks
[point cloud processing paper crazy reading frontier edition 13] - gapnet: graph attention based point neural network for exploring local feature
Severity code description the project file line prohibits the display of status error c2440 "initialization": unable to convert from "const char [31]" to "char *"
LeetCode每日一题(1996. The Number of Weak Characters in the Game)
State compression DP acwing 291 Mondrian's dream
【Kotlin学习】类、对象和接口——带非默认构造方法或属性的类、数据类和类委托、object关键字
Spark overview
2022-2-14 learning xiangniuke project - Session Management
LeetCode每日一题(1856. Maximum Subarray Min-Product)
Construction of simple database learning environment
Vscode编辑器右键没有Open In Default Browser选项
Simple use of MATLAB
【点云处理之论文狂读经典版8】—— O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis
[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition
Problems in the implementation of lenet
[point cloud processing paper crazy reading classic version 8] - o-cnn: octree based revolutionary neural networks for 3D shape analysis
Jenkins learning (III) -- setting scheduled tasks
Crawler career from scratch (IV): climb the bullet curtain of station B through API