当前位置:网站首页>Spark 集群安装与部署
Spark 集群安装与部署
2022-07-03 09:00:00 【小胡今天有变强吗】
Spark集群安装部署
集群规划:
三台主机的名称为:hadoop102, hadoop103, hadoop104。集群规划如下:
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| Master+Worker | Worker | Worker |
上传并解压
Spark下载地址:
https://spark.apache.org/downloads.html
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩在指定位置
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark
修改配置文件
进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
mv slaves.template slaves
修改 slaves 文件,添加 work 节点
hadoop102 hadoop103 hadoop104修改 spark-env.sh.template 文件名为 spark-env.sh
mv spark-env.sh.template spark-env.sh修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/opt/module/jdk1.8.0_144 //修改为自己对应的jdk路径 SPARK_MASTER_HOST=hadoop102 SPARK_MASTER_PORT=7077分发 spark 目录
xsync spark注意需要提前安装xsync免密登录,如果未配置可以参考:https://blog.csdn.net/hshudoudou/article/details/123101151?spm=1001.2014.3001.5501
启动集群
执行脚本命令:
sbin/start-all.sh![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8w8JeNL9-1654759026708)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220609143834238.png)]](/img/e8/e1e53eee730483302151edf6945deb.png)
- 查看三台服务器的进程
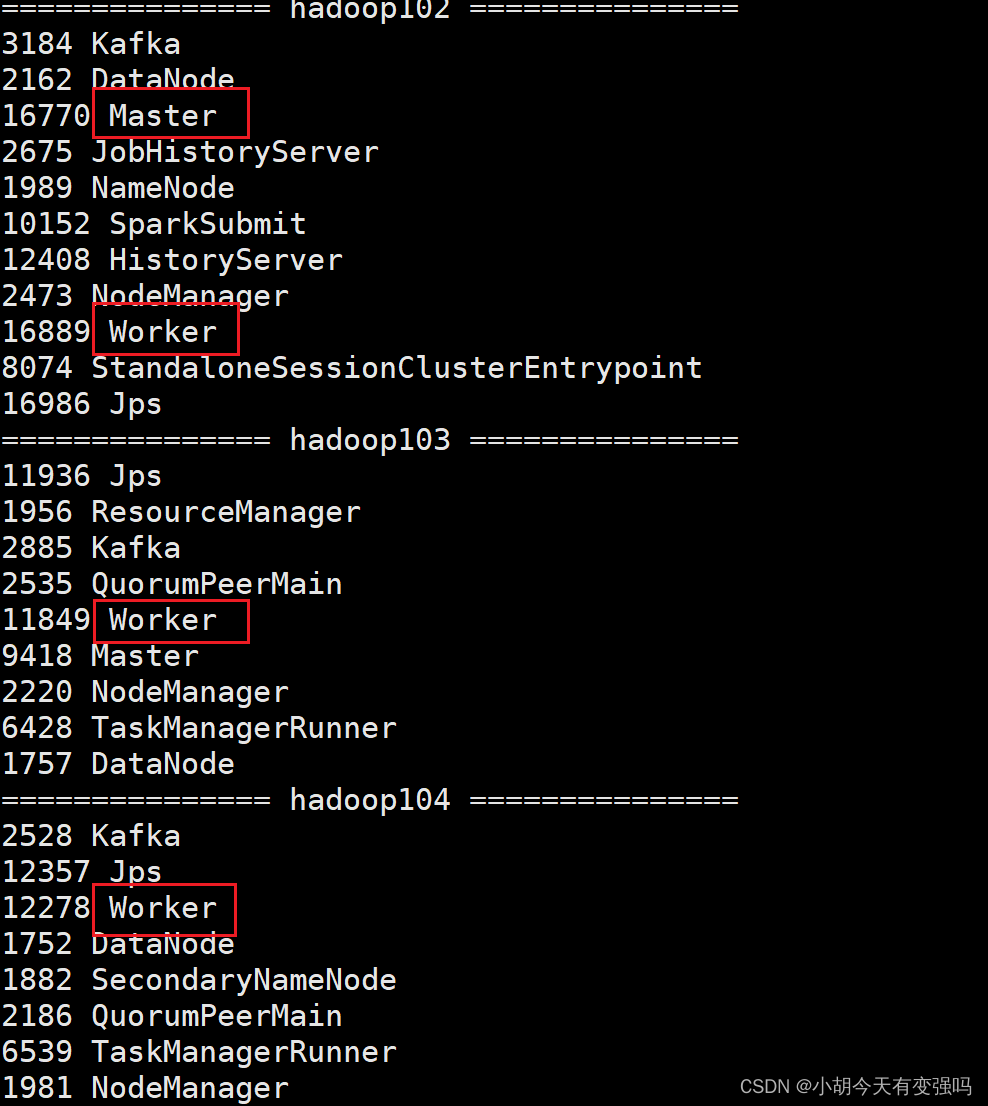
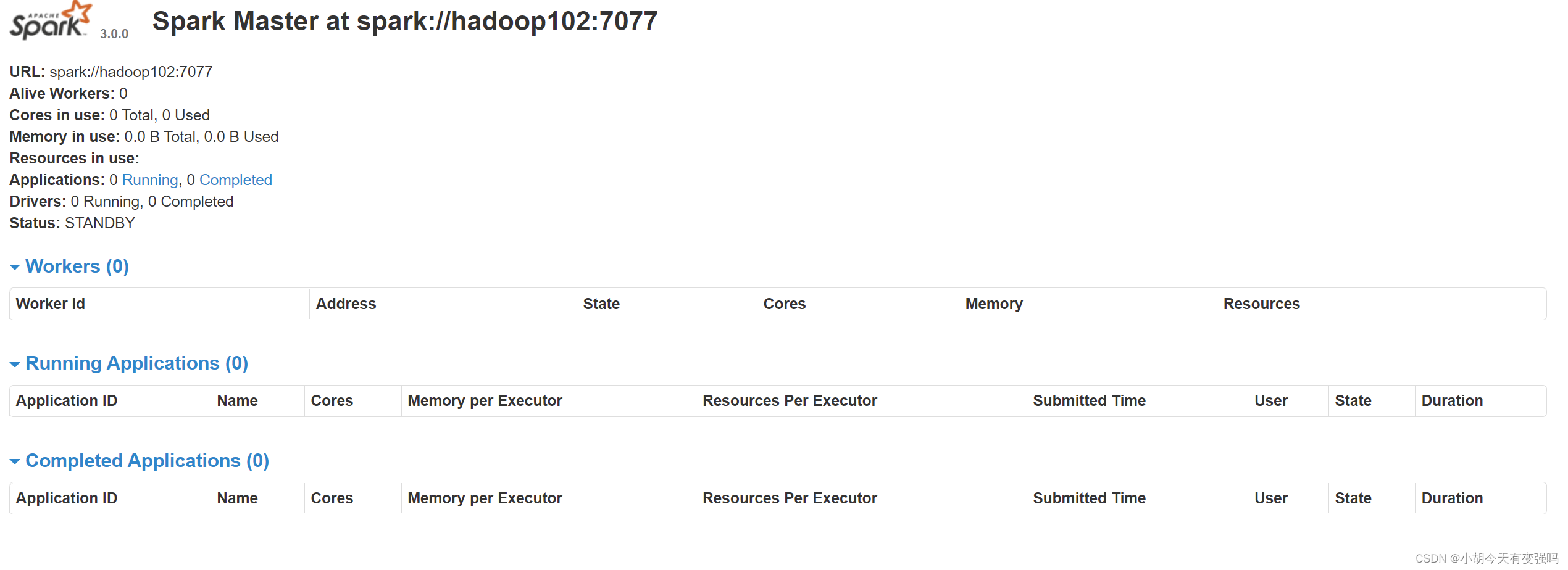
- 查看 Master 资源监控 Web UI 界面: http://hadoop102:8080
提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
–class 表示要执行程序的主类
–master spark://hadoop102:7077 独立部署模式,连接到 Spark 集群
spark-examples_2.12-3.0.0.jar 运行类所在的 jar 包
数字 10 表示程序的入口参数,用于设定当前应用的任务数量
提交参数说明:在提交应用中,一般会同时一些提交参数
| 参数 | 解释 | 可选值举例 |
|---|---|---|
| –class | Spark 程序中包含主函数的类 | |
| –master | spark 程序运行的模式(环境) | 模式:local[*]、spark://linux1:7077、 Yarn |
| –executor-memory 1G | 指定每个 executor 可用内存为 1G | 其余配置根据情况设定即可 |
| –total-executor-cores 2 | 指定所有executor使用的cpu核数为 2 个 | |
| –executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用 jar,包含依赖。 | |
| application-arguments | 传给 main()方法的参数 | |
配置历史服务器
修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop102:8020/directory
需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
如果不存在,需要进行创建:
sbin/start-dfs.sh
hadoop fs -mkdir /director
修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory -Dspark.history.retainedApplications=30"分发配置文件
xsync conf
重新启动集群和历史服务
sbin/start-all.sh sbin/start-history-server.sh重新执行任务
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop102:7077 \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10查看历史服务:http://hadoop102:18080
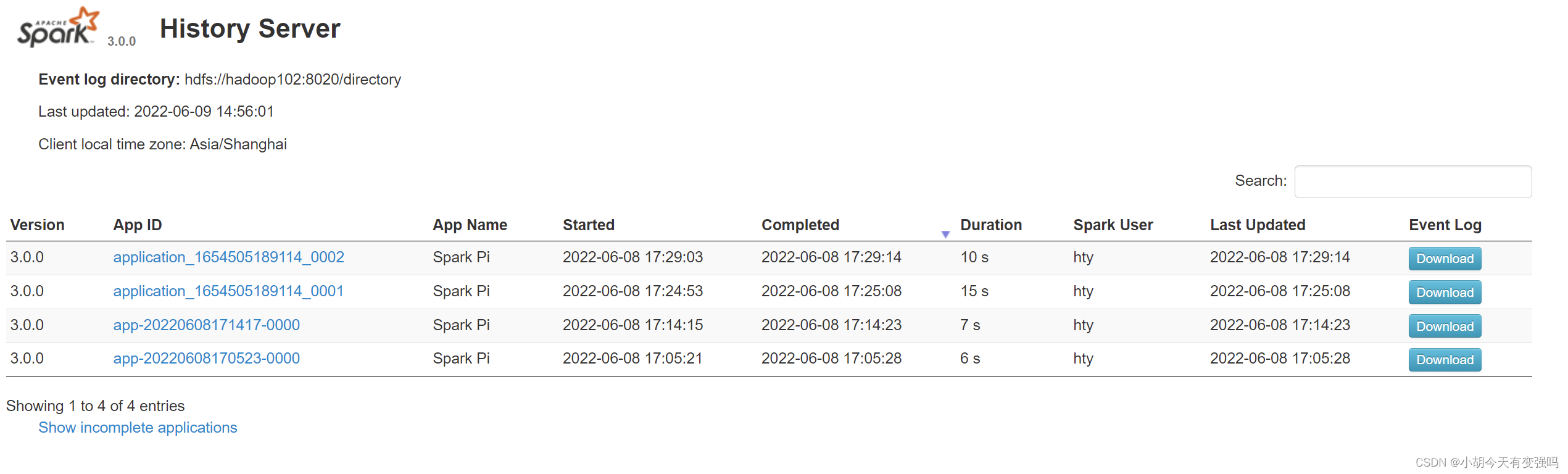
配置高可用(HA)
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以 为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master 发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用 Zookeeper 设置。
集群规划:
| hadoop02 | hadoop103 | hadoop04 |
|---|---|---|
| Master Zookeeper Worker | Master Zookeeper Worker | Zookeeper Worker |
停止集群
sbin/stop-all.sh
启动zookeeper
zk.sh start //这儿是利用脚本命令启动,如果没有写脚本,可以在zookeeper目录下用下面命令 xstart zk修改 spark-env.sh 文件添加如下配置
注释如下内容:
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
添加如下内容:
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自
定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104 -Dspark.deploy.zookeeper.dir=/spark"
分发配置文件
xsync conf/
Yarn 模式
上述的部署模式为独立部署(Standalone)模式,独立部署模式由 Spark 自身提供计算资源,无需其他框架提供资源。这 种方式降低了和其他第三方资源框架的耦合性,独立性非常强。Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,因此更多的还是利用Yarn模式。
- 修改 hadoop 配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml, 并分发
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认 是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认 是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
export JAVA_HOME=/opt/module/jdk1.8.0_144 //替换成自己的jdk目录 YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop //替换成自己打包hadoop目录
- 启动 HDFS 以及 YARN 集群
边栏推荐
- Construction of simple database learning environment
- 数字化管理中台+低代码,JNPF开启企业数字化转型的新引擎
- Utilisation de hudi dans idea
- C language programming specification
- 【点云处理之论文狂读前沿版12】—— Adaptive Graph Convolution for Point Cloud Analysis
- Use the interface colmap interface of openmvs to generate the pose file required by openmvs mvs
- Hudi 集成 Spark 数据分析示例(含代码流程与测试结果)
- IDEA 中使用 Hudi
- 【点云处理之论文狂读前沿版10】—— MVTN: Multi-View Transformation Network for 3D Shape Recognition
- AcWing 787. Merge sort (template)
猜你喜欢
Navicat, MySQL export Er graph, er graph
Move anaconda, pycharm and jupyter notebook to mobile hard disk
Solve POM in idea Comment top line problem in XML file
![[point cloud processing paper crazy reading frontier edition 13] - gapnet: graph attention based point neural network for exploring local feature](/img/66/2e7668cfed1ef4ddad26deed44a33a.png)
[point cloud processing paper crazy reading frontier edition 13] - gapnet: graph attention based point neural network for exploring local feature

LeetCode 508. The most frequent subtree elements and
Just graduate student reading thesis

【Kotlin疑惑】在Kotlin类中重载一个算术运算符,并把该运算符声明为扩展函数会发生什么?
![[advanced feature learning on point clouds using multi resolution features and learning]](/img/f0/abed28e94eb4a95c716ab8cecffe04.png)
[advanced feature learning on point clouds using multi resolution features and learning]

Digital statistics DP acwing 338 Counting problem
2022-2-14 learning xiangniuke project - generate verification code
随机推荐
Tag paste operator (#)
【点云处理之论文狂读前沿版13】—— GAPNet: Graph Attention based Point Neural Network for Exploiting Local Feature
LeetCode 532. 数组中的 k-diff 数对
拯救剧荒,程序员最爱看的高分美剧TOP10
State compression DP acwing 91 Shortest Hamilton path
Jenkins learning (II) -- setting up Chinese
[point cloud processing paper crazy reading classic version 9] - pointwise revolutionary neural networks
Common formulas of probability theory
【点云处理之论文狂读经典版13】—— Adaptive Graph Convolutional Neural Networks
Hudi 快速体验使用(含操作详细步骤及截图)
Overview of database system
LeetCode 715. Range module
Jenkins learning (I) -- Jenkins installation
LeetCode 1089. Duplicate zero
Basic knowledge of network security
On February 14, 2022, learn the imitation Niuke project - develop the registration function
CSDN markdown editor help document
AcWing 786. 第k个数
Hudi 集成 Spark 数据分析示例(含代码流程与测试结果)
Notes on numerical analysis (II): numerical solution of linear equations