当前位置:网站首页>[point cloud processing paper crazy reading classic version 13] - adaptive graph revolutionary neural networks
[point cloud processing paper crazy reading classic version 13] - adaptive graph revolutionary neural networks
2022-07-03 09:14:00 【LingbinBu】
AGCNN:Adaptive Graph Convolutional Neural Networks
Before reading this article , It should be understood that spectral graph convolution network
Abstract
- background : Graph Convolutional Neural Networks (Graph CNNs) Can be regarded as generalized CNNs, Be able to effectively handle all kinds of graph data
- problem : At present ,Graph CNNs Medium filters It's all based on Fixed or shared graph structure On , For actual data ,graph Structures differ in size and connectivity
- Method : Propose a more generalized and flexible Graph CNNs, The network can transfer any graph Structure as input . In this way , Train for each graph Data learning task driven adaptation graph; In order to learn more efficiently graph, A distance metric learning
- Code :TensorFlow edition
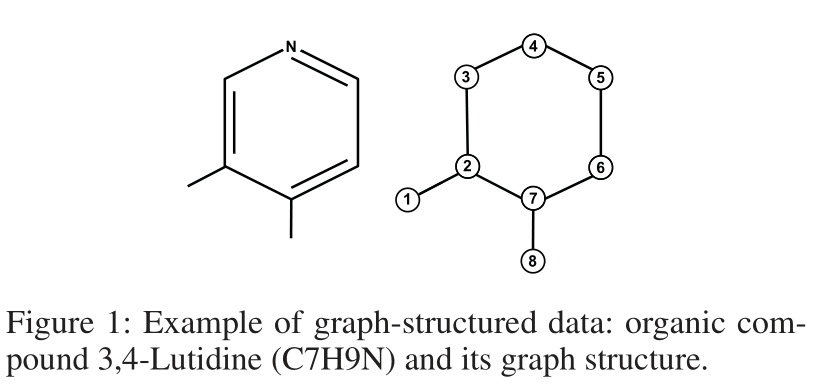
introduction
- In the point cloud classification task ,graph The topology of is more informative than point features
- At present Graph CNNs There are the following bottlenecks :
- graph degree constraint
- It is required to keep the same input graph structure
- fixed graph
- Unable to learn topology information
- In this paper, a new spectral graph convolution network, In different ways graph Structure raw data as input . to batch Each individual sample in is assigned a specific graph Laplacian, Objectively describe its unique topology . specific graph Laplacian Will lead to specific spectral filter, according to graph Laplacian Distinctive graph Laplacian, spectral filter Be able to combine the characteristics of neighborhood .
- residual graph For exploring finer structural information
- a supervised metric learning with Mahalanobis distance Can reduce complexity
- Contributions:
- Construct unique graph Laplacian
- Learn distance metric for graph update
- Feature embedding in convolution
- Accept flexible graph inputs
Related work
The method referred to in this article will one-hop local kernel Extended to K K K-hop Connection . according to graph Fourier transform, If U U U yes L L L Of graph Fourier basis aggregate , that :
x k + 1 = σ ( g θ ( L K ) x k ) = σ ( U g θ ( Λ K ) U T x k ) . x_{k+1}=\sigma\left(g_{\theta}\left(L^{K}\right) x_{k}\right)=\sigma\left(U g_{\theta}\left(\Lambda^{K}\right) U^{T} x_{k}\right) . xk+1=σ(gθ(LK)xk)=σ(Ugθ(ΛK)UTxk).
diag ( Λ ) \operatorname{diag}(\Lambda) diag(Λ) yes L L L Of frequency components.
Method
SGC-LL
Spectral Graph Convolution layer + Graph Laplacian Learning = SGC-LL
Learning Graph Laplacian
Given a graph G = ( V , E ) \mathcal{G}=(V, E) G=(V,E), Its adjacency matrix is A A A, The degree matrix is D D D, Normalized Graph Laplacian matrix L L L Expressed as :
L = I − D − 1 / 2 A D − 1 / 2 L=I-D^{-1 / 2} A D^{-1 / 2} L=I−D−1/2AD−1/2
L L L It represents the connectivity between nodes and the degree of vertices , got it L L L It means you know G \mathcal{G} G Topology of .
because L L L Is a symmetric positive definite matrix , After its feature decomposition, a complete set of feature vectors will be obtained { u s } s = 0 N − 1 \left\{u_{s}\right\}_{s=0}^{N-1} { us}s=0N−1 Composed of U U U, N N N Represents the number of vertices . Use U U U As graph Fourier basis,Graph Laplacian It can be diagonalized into L = U Λ U T L=U \Lambda U^{T} L=UΛUT.
Graph Fourier Transformation is defined as x ^ = U T x \hat{x}=U^{T} x x^=UTx. because graph The spectrum of topological structure is expressed as Λ \Lambda Λ, So spectrum filter g θ ( Λ ) g_{\theta}(\Lambda) gθ(Λ) Will generate a specific convolution in space kernel. By smooth frequency components Composed of spectrum Will form a local space kernel. g θ ( Λ ) g_{\theta}(\Lambda) gθ(Λ) It can be expressed as a polynomial :
g θ ( Λ ) = ∑ k = 0 K − 1 θ k Λ k , g_{\theta}(\Lambda)=\sum_{k=0}^{K-1} \theta_{k} \Lambda^{k}, gθ(Λ)=k=0∑K−1θkΛk,
This leads to a K K K-localized kernel, It allows any pair of shortest path distances d G < K d_{\mathcal{G}}<K dG<K The summit of squeeze in.
Besides , Longer connections mean less similarity , And will be assigned by θ k \theta_{k} θk Less contribution of control . Polynomial filter smoothed spectrum, And by θ k \theta_{k} θk Parameterization also forces the final kernel From the central vertex to the farthest K K K-hop Circular weight distribution of vertices . That's the limit kernel The flexibility of the . what's more , The similarity between two vertices is essentially determined by the selected distance measurement and feature domain . For non Euclidean data , Euclidean distance is no longer guaranteed to be the best measure of similarity . therefore , Because the graph is suboptimal , Therefore, the similarity between connected nodes may be lower than that between disconnected nodes . There are also two possible reasons :
- Graph It is constructed in the original feature domain before feature extraction and transformation
- The topology of a graph is intrinsic , It only represents the physical connection , For example, chemical bonds in molecules
In order to break the above restrictions , We propose a new spectral filter, Yes Laplacian L L L Parameterize .
Given the original Laplacian L L L, features X X X and Parameters Γ \Gamma Γ, function F ( L , X , Γ ) \mathcal{F}(L, X, \Gamma) F(L,X,Γ) The output is updated Laplacian L ~ \tilde{L} L~ Of spectrum, that filter Will become :
g θ ( Λ ) = ∑ k = 0 K − 1 ( F ( L , X , Γ ) ) k g_{\theta}(\Lambda)=\sum_{k=0}^{K-1}(\mathcal{F}(L, X, \Gamma))^{k} gθ(Λ)=k=0∑K−1(F(L,X,Γ))k
Final ,SGC-LL Layers can be represented as :
Y = U g θ ( Λ ) U T X = U ∑ k = 0 K − 1 ( F ( L , X , Γ ) ) k U T X . Y=U g_{\theta}(\Lambda) U^{T} X=U \sum_{k=0}^{K-1}(\mathcal{F}(L, X, \Gamma))^{k} U^{T} X . Y=Ugθ(Λ)UTX=Uk=0∑K−1(F(L,X,Γ))kUTX.
Because it is dense matrix multiplication U T X U^{T} X UTX, So the complexity in the above formula is O ( N 2 ) \mathcal{O}\left(N^{2}\right) O(N2). If g θ ( L ~ ) g_{\theta}(\tilde{L}) gθ(L~) It's through L ~ \tilde{L} L~ Polynomial function of recursive estimation , Then the complexity will be reduced to O ( K ) \mathcal{O}(K) O(K), This is because Laplacian L ~ \tilde{L} L~ It's a sparse matrix . We choose Chebychev Expand the calculation k k k Order polynomial T k ( L ~ ) X T_{k}(\tilde{L}) X Tk(L~)X.
Training Metric for Graph Update
about graph Structural data , Euclidean distance is not the best measure of vertex similarity , So this article uses x i x_{i} xi and x j x_{j} xj Between the Generalized Mahalanobis distance As a measure :
D ( x i , x j ) = ( x i − x j ) T M ( x i − x j ) . \mathbb{D}\left(x_{i}, x_{j}\right)=\sqrt{\left(x_{i}-x_{j}\right)^{T} M\left(x_{i}-x_{j}\right)} . D(xi,xj)=(xi−xj)TM(xi−xj).
If M = I M=I M=I, Then the above formula will degenerate into European distance . In this model , Positive semidefinite matrices M = M= M= W d W d T W_{d} W_{d}^{T} WdWdT, among W d W_{d} Wd yes SGCLL One of the training weights of layer . next , Use this distance to calculate Gauss kernel:
G x i , x j = exp ( − D ( x i , x j ) / ( 2 σ 2 ) ) . \mathbb{G}_{x_{i}, x_{j}}=\exp \left(-\mathbb{D}\left(x_{i}, x_{j}\right) /\left(2 \sigma^{2}\right)\right) . Gxi,xj=exp(−D(xi,xj)/(2σ2)).
In the face of G \mathbb{G} G After normalization , Get dense adjacency matrix A ^ \hat{A} A^.
Re-parameterization on feature transform
In the classic CNNs in , The output characteristics of convolution layer are obtained by adding all characteristic graphs , These characteristic maps are all through different filter Calculated independently . This means that the new feature depends not only on the adjacent vertex , There will be others intra-vertex The influence of characteristics .
however , stay graph convolution On , In the same graph It is impossible to create and train separate topologies for different vertex features . In order to construct intra-vertex and inter-vertex Mapping of features , We are SGC-LL Layer introduces a transformation matrix and an offset vector :
Y = ( U g θ ( Λ ) U T X ) W + b Y=\left(U g_{\theta}(\Lambda) U^{T} X\right) W+b Y=(Ugθ(Λ)UTX)W+b
In the i i i layer , Transformation matrix W i ∈ R d i − 1 × d i W_{i} \in \mathbb{R}^{d_{i-1} \times d_{i}} Wi∈Rdi−1×di And offset b i ∈ R d i × 1 b_{i} \in \mathbb{R}^{d_{i} \times 1} bi∈Rdi×1 And measurement M i M_{i} Mi Training together , among d i d_{i} di It's a feature dimension .
stay SGC-LL Layer , The parameters to be trained are { M i , W i , b i } \left\{M_{i}, W_{i}, b_{i}\right\} { Mi,Wi,bi}, The learning complexity is O ( d i d i − 1 ) \mathcal{O}\left(d_{i} d_{i-1}\right) O(didi−1), No input graph The influence of size and degree , On the next floor SGC-LL in ,spectral filter Will be embedded in other feature fields , The metrics in this feature domain are different from other domains .
Residual Graph Laplacian
In molecular tasks , Because there is no prior knowledge about distance measurement , Measure M M M Is initialized randomly , So it may take a long time to converge . In order to speed up training and improve the stability of learning graph topology , We put forward a reasonable assumption , That is, the optimal graph Laplacian L ^ \hat{L} L^ With primordial Laplacian L L L There are small changes between :
L ^ = L + α L r e s \hat{L}=L+\alpha L_{res} L^=L+αLres
let me put it another way , It's primitive Laplacian L L L Has included a certain number of graph structural information , Some substructure information is not included , Some of them cannot be in intrinsic graph Virtual vertex connection for direct learning on . therefore , We don't study directly L ^ \hat{L} L^, It's learning residual graph Laplacian L r e s ( i ) = L ( M i , X ) L_{res}(i)=\mathcal{L}(M_i,X) Lres(i)=L(Mi,X). L r e s ( i ) L_{res}(i) Lres(i) For the final graph The influence of topology is determined by α \alpha α control ,SGC-LL Specific operations such as Algorithm 1 Shown .

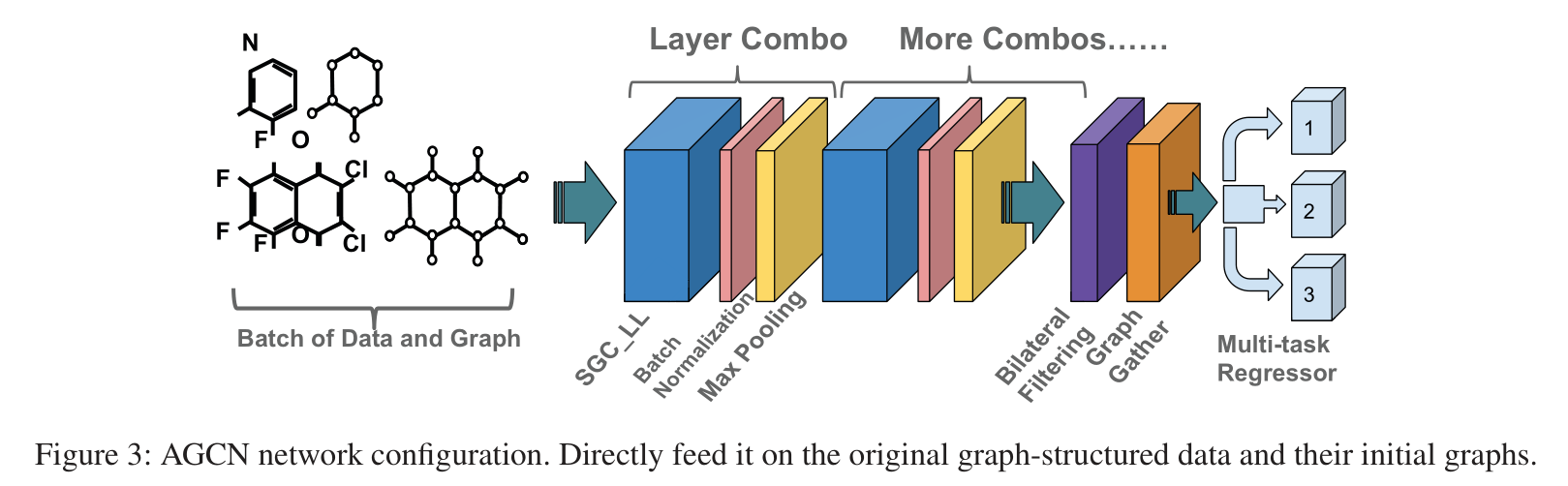
AGCN Network
AGCN Network = SGC-LL layer + graph max pooling layer + graph gather layer
Graph Max Pooling
Graph max pooling Between features . about graph Of the v v v Features of vertices x v x_v xv, pooling The operation will change the j j j Features x v ( j ) x_v(j) xv(j), Replace with j j j The largest of the four features , These features include adjacent vertices and themselves . If N ( v ) N(v) N(v) yes v v v A set of adjacent vertices , So at the top v v v The new feature of is :
x ^ v ( j ) = max ( { x v ( j ) , x i ( j ) , ∀ i ∈ N ( v ) } ) \hat{x}_{v}(j)=\max \left(\left\{x_{v}(j), x_{i}(j), \forall i \in N(v)\right\}\right) x^v(j)=max({ xv(j),xi(j),∀i∈N(v)})
Graph Gather
stay graph gather layer , Add all vertex eigenvectors , As graph Presentation of data .Gather layer The output of is used by vectors to predict . If not used graph gather layer , Then the network can be used for vertex prediction . Predictions in units of vertices include graph Complete and predict on social media .
Bilateral Filter
Bilateral filter layer The function of is to prevent over fitting ,residual graph Laplacian It will certainly adapt to the model to better fit the training task , But there is a risk of over fitting . In order to avoid over fitting , We introduce the modified bilateral filtering layer, By increasing L L L The spatial locality of SGC-LL Regularize the activation result of . In addition to these , It's still used Batch normalization.
Network Configuration
layer combo = one SGC-LL layer + one batch normalization layer + one graph max pooling layer
Passing by a combo layer after ,batch Medium graph The structure has been updated , meanwhile grap The size remains the same .
Batch Training of Diverse Graphs
stay graph The biggest challenge of convolution on structured data is that it is difficult to match different local topologies of training samples .
Article SGC-LL layer Train individual Laplacian, All local topologies of the data structure are preserved . We found that , In the structure graph When the structure ,feature space and distance metrics It's very important ,SGC-LL layer Just need to batch All samples in share the same characteristic transformation matrix and distance metrics. Before training , You need to construct the initial graph Laplacians And according to these initial Laplacians to update kernel, This requires additional memory , But it's acceptable , because graph Laplacians Usually sparse .
边栏推荐
- Too many open files solution
- What is the difference between sudo apt install and sudo apt -get install?
- With low code prospect, jnpf is flexible and easy to use, and uses intelligence to define a new office mode
- 传统办公模式的“助推器”,搭建OA办公系统,原来就这么简单!
- dried food! What problems will the intelligent management of retail industry encounter? It is enough to understand this article
- LeetCode 508. 出现次数最多的子树元素和
- Character pyramid
- Introduction to the basic application and skills of QT
- AcWing 785. Quick sort (template)
- Low code momentum, this information management system development artifact, you deserve it!
猜你喜欢

LeetCode 532. K-diff number pairs in array

Sword finger offer II 029 Sorted circular linked list

AcWing 785. 快速排序(模板)

In the digital transformation, what problems will occur in enterprise equipment management? Jnpf may be the "optimal solution"
2022-2-13 learn the imitation Niuke project - Project debugging skills
Discussion on enterprise informatization construction

LeetCode 75. Color classification

What is an excellent fast development framework like?

dried food! What problems will the intelligent management of retail industry encounter? It is enough to understand this article

低代码前景可期,JNPF灵活易用,用智能定义新型办公模式
随机推荐
LeetCode 535. TinyURL 的加密与解密
AcWing 786. 第k个数
Markdown learning
Complex character + number pyramid
Move anaconda, pycharm and jupyter notebook to mobile hard disk
Binary tree traversal (first order traversal. Output results according to first order, middle order, and last order)
Sword finger offer II 091 Paint the house
Save the drama shortage, programmers' favorite high-score American drama TOP10
Instant messaging IM is the countercurrent of the progress of the times? See what jnpf says
The less successful implementation and lessons of RESNET
Problems in the implementation of lenet
Vscode connect to remote server
记忆化搜索 AcWing 901. 滑雪
STM32F103 can learning record
On February 14, 2022, learn the imitation Niuke project - develop the registration function
【点云处理之论文狂读经典版11】—— Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
干货!零售业智能化管理会遇到哪些问题?看懂这篇文章就够了
LeetCode 30. 串联所有单词的子串
剑指 Offer II 029. 排序的循环链表
2022-1-6 Niuke net brush sword finger offer