当前位置:网站首页>Hudi 快速体验使用(含操作详细步骤及截图)
Hudi 快速体验使用(含操作详细步骤及截图)
2022-07-03 09:00:00 【小胡今天有变强吗】
Hudi 快速体验使用
本示例要完成下面的流程: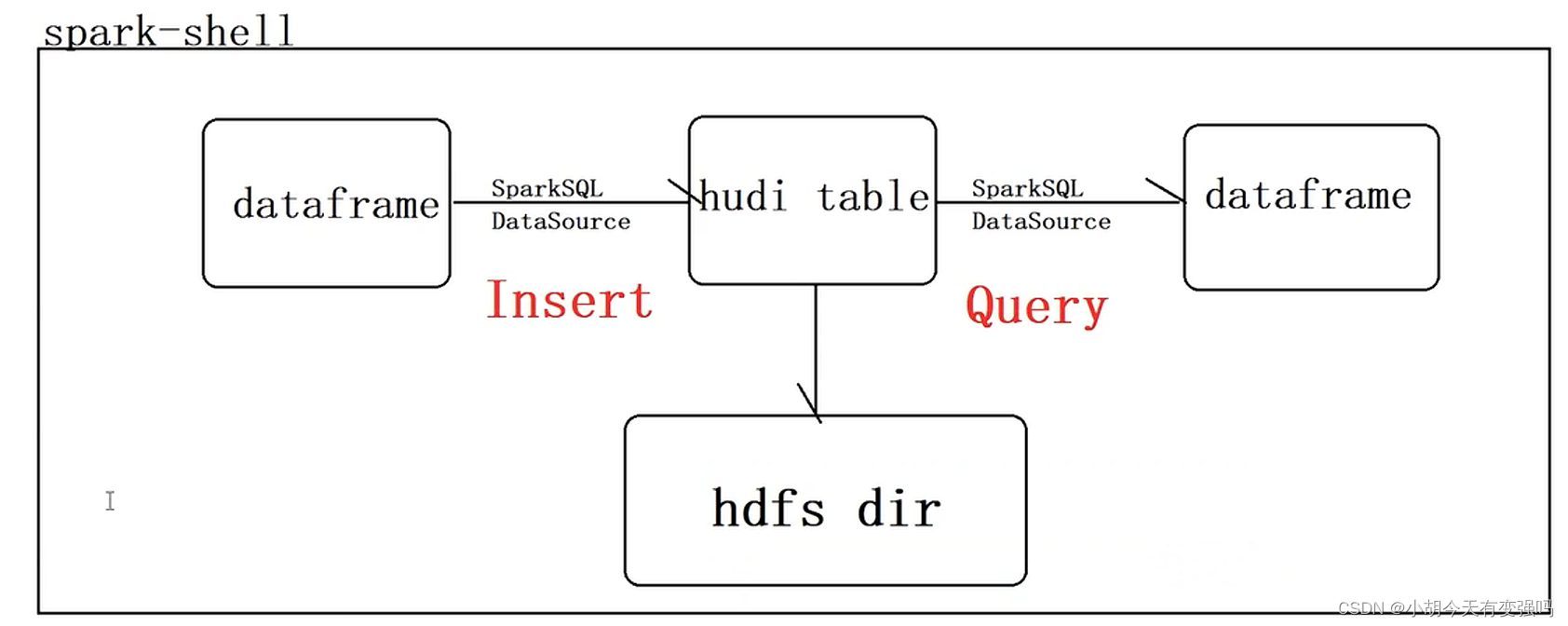
需要提前安装好hadoop、spark以及hudi及组件。
spark 安装教程:
https://blog.csdn.net/hshudoudou/article/details/125204028?spm=1001.2014.3001.5501
hudi 编译与安装教程:
https://blog.csdn.net/hshudoudou/article/details/123881739?spm=1001.2014.3001.5501
注意只Hudi管理数据,不存储数据,不分析数据。
启动 spark-shel l添加 jar 包
./spark-shell \
--master local[2] \
--jars /home/hty/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar,\
/home/hty/hudi-jars/spark-avro_2.12-3.0.1.jar,/home/hty/hudi-jars/spark_unused-1.0.0.jar.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
可以看到三个 jar 包都上传成功:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ljXalTIm-1654780395209)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220609165739566.png)]](/img/4e/23f4b3aca8c7a6873cbec44a13e746.png)
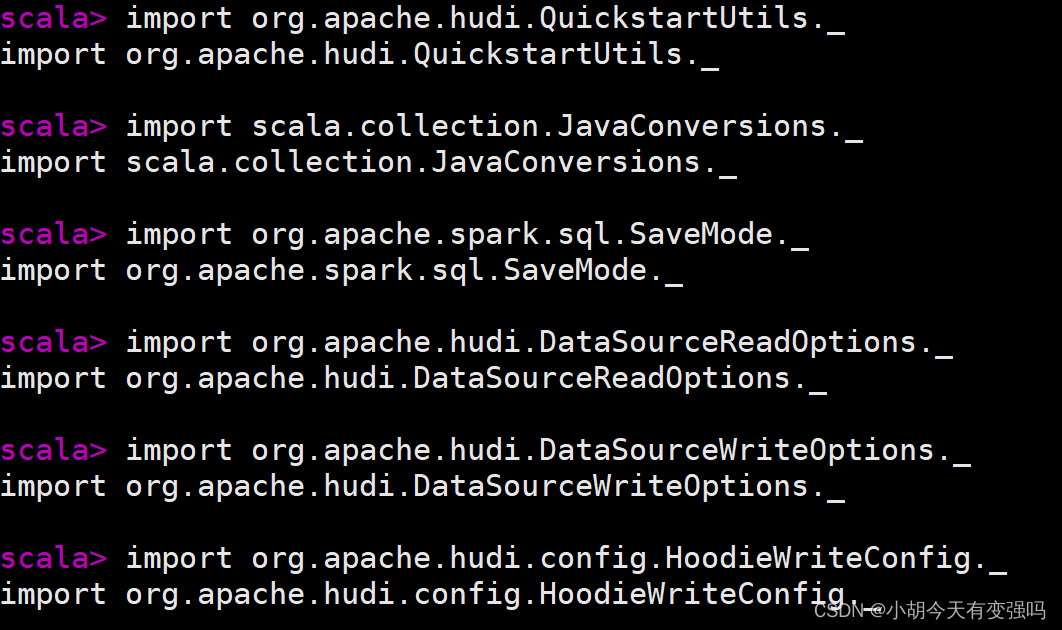
导包并设置存储目录:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hadoop102:8020/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator

模拟产生Trip乘车数据
val inserts = convertToStringList(dataGen.generateInserts(10))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dd2CZtFP-1654780395209)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220609171909589.png)]](/img/55/8bb7afe823c468b768ef2f5518c245.png)

3.将模拟数据List转换为DataFrame数据集
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
4.查看转换后DataFrame数据集的Schema信息

5.选择相关字段,查看模拟样本数据
df.select("rider", "begin_lat", "begin_lon", "driver", "fare", "uuid", "ts").show(10, truncate=false)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q01Acwo7-1654780395209)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220609172907830.png)]](/img/3e/23e59af23e0446eff5ce2e6d120f01.png)
插入数据
将模拟产生Trip数据,保存到Hudi表中,由于Hudi诞生时基于Spark框架,所以SparkSQL支持Hudi数据源,直接通 过format指定数据源Source,设置相关属性保存数据即可。
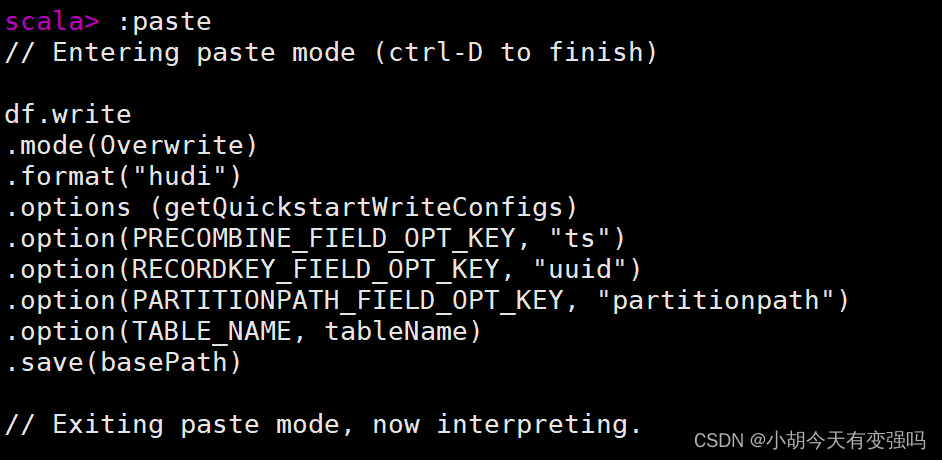
df.write
.mode(Overwrite)
.format("hudi")
.options (getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(RECORDKEY_FIELD_OPT_KEY, "uuid")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
.option(TABLE_NAME, tableName)
.save(basePath)
getQuickstartWriteConfigs,设置写入/更新数据至Hudi时,Shuffle时分区数目
PRECOMBINE_FIELD_OPT_KEY,数据合并时,依据主键字段
RECORDKEY_FIELD_OPT_KEY,每条记录的唯一id,支持多个字段
PARTITIONPATH_FIELD_OPT_KEY,用于存放数据的分区字段
paste模式,粘贴完按ctrl + d 执行。

Hudi表数据存储在HDFS上,以PARQUET列式方式存储的
从Hudi表中读取数据,同样采用SparkSQL外部数据源加载数据方式,指定format数据源和相关参数options:
val tripSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
其中指定Hudi表数据存储路径即可,采用正则Regex匹配方式,由于保存Hudi表属于分区表,并且为三级分区(相 当于Hive中表指定三个分区字段),使用表达式://// 加载所有数据。
查看表结构:
tripSnapshotDF.printSchema()

比原先保存到Hudi表中数据多5个字段,这些字段属于Hudi管理数据时使用的相关字段。
将获取Hudi表数据DataFrame注册为临时视图,采用SQL方式依据业务查询分析数据:
tripSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
利用sqark SQL查询
spark.sql("select fare, begin_lat, begin_lon, ts from hudi_trips_snapshot where fare > 20.0").show()

查看新增添的几个字段:
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, _hoodie_file_name from hudi_trips_snapshot").show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hbKEhmlv-1654780395210)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220609204702530.png)]](/img/95/1074f107be182b59b65c0ee7f35467.png)
这几个新增添的字段就是 hudi 对表进行管理而增添的字段。
参考资料:
边栏推荐
- String splicing method in shell
- Solve POM in idea Comment top line problem in XML file
- Jenkins learning (II) -- setting up Chinese
- What are the stages of traditional enterprise digital transformation?
- 【点云处理之论文狂读经典版13】—— Adaptive Graph Convolutional Neural Networks
- How to check whether the disk is in guid format (GPT) or MBR format? Judge whether UEFI mode starts or legacy mode starts?
- On a un nom en commun, maître XX.
- [graduation season | advanced technology Er] another graduation season, I change my career as soon as I graduate, from animal science to programmer. Programmers have something to say in 10 years
- AcWing 786. Number k
- 【点云处理之论文狂读前沿版10】—— MVTN: Multi-View Transformation Network for 3D Shape Recognition
猜你喜欢

LeetCode 513. 找树左下角的值

In the digital transformation, what problems will occur in enterprise equipment management? Jnpf may be the "optimal solution"

Jenkins learning (I) -- Jenkins installation
![[point cloud processing paper crazy reading frontier edition 13] - gapnet: graph attention based point neural network for exploring local feature](/img/66/2e7668cfed1ef4ddad26deed44a33a.png)
[point cloud processing paper crazy reading frontier edition 13] - gapnet: graph attention based point neural network for exploring local feature
Vscode connect to remote server

Hudi 集成 Spark 数据分析示例(含代码流程与测试结果)
![[set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)](/img/fd/c0f885cdd17f1d13fdbc71b2aea641.jpg)
[set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)

低代码前景可期,JNPF灵活易用,用智能定义新型办公模式

Education informatization has stepped into 2.0. How can jnpf help teachers reduce their burden and improve efficiency?
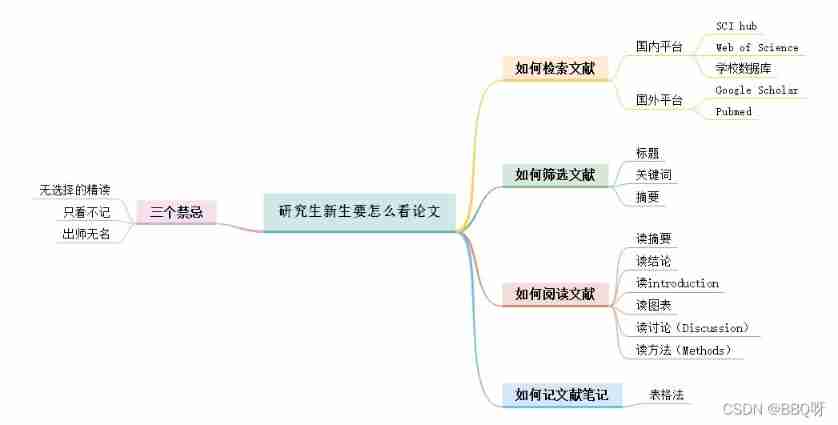
Just graduate student reading thesis
随机推荐
Explanation of the answers to the three questions
Vscode connect to remote server
Internet Protocol learning record
Simple use of MATLAB
教育信息化步入2.0,看看JNPF如何帮助教师减负,提高效率?
[point cloud processing paper crazy reading frontier edition 13] - gapnet: graph attention based point neural network for exploring local feature
dried food! What problems will the intelligent management of retail industry encounter? It is enough to understand this article
【点云处理之论文狂读经典版9】—— Pointwise Convolutional Neural Networks
The method of replacing the newline character '\n' of a file with a space in the shell
Save the drama shortage, programmers' favorite high-score American drama TOP10
LeetCode 241. 为运算表达式设计优先级
【Kotlin学习】运算符重载及其他约定——重载算术运算符、比较运算符、集合与区间的约定
Jenkins learning (III) -- setting scheduled tasks
[point cloud processing paper crazy reading frontier version 11] - unsupervised point cloud pre training via occlusion completion
精彩回顾|I/O Extended 2022 活动干货分享
Crawler career from scratch (I): crawl the photos of my little sister ① (the website has been disabled)
LeetCode 75. 颜色分类
Recommend a low code open source project of yyds
String splicing method in shell
【点云处理之论文狂读前沿版11】—— Unsupervised Point Cloud Pre-training via Occlusion Completion