当前位置:网站首页>Hudi integrated spark data analysis example (including code flow and test results)
Hudi integrated spark data analysis example (including code flow and test results)
2022-07-03 09:21:00 【Did Xiao Hu get stronger today】
List of articles
Data sets
The data is 2017 year 5 month 1 Japan -10 month 31 Japan ( Half a year ) Daily order data of Haikou , Including the longitude and latitude of the start and end of the order and the order type
、 Travel category 、 Order attribute data of passengers .
Baidu network disk connection :
link :https://pan.baidu.com/s/1e1hhf0Aag1ukWiRdMLnU3w
Extraction code :i3x4
Data processing objectives
According to Haikou didi travel data , According to the following demand statistical analysis :
Overall project structure
data ETL And preservation
Code writing
resources The three configuration files under the package are Hadoop Configuration file for , Just copy it directly .
- pom File dependency
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.0.0</spark.version>
<hadoop.version>2.7.3</hadoop.version>
<hudi.version>0.9.0</hudi.version>
</properties>
<dependencies>
<!-- rely on Scala Language -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Structured Streaming + Kafka rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client rely on -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- hudi-spark3 -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3-bundle_2.12</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL And Hive Integrate rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.13</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.12</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven Compiled plug-ins -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
- Tool class SparkUtils
import org.apache.spark.sql.SparkSession
/** * SparkSQL Operational data ( Load read and save write ) Time tools , Like getting SparkSession Instance object, etc */
object SparkUtils {
def createSpakSession(clazz: Class[_], master: String = "local[4]", partitions: Int = 4): SparkSession = {
SparkSession.builder()
.appName(clazz.getSimpleName.stripSuffix("$"))
.master(master)
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.shuffle.partitions", partitions)
.getOrCreate()
}
def main(args: Array[String]): Unit = {
val spark = createSpakSession(this.getClass)
println(spark)
Thread.sleep(10000000)
spark.stop()
}
}
- DidiStorageSpark.scala
package com.tianyi.hudi.didi
import org.apache.spark.sql.{
DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.functions._
/** * Analysis of travel operation data of didi Haikou , Use SparkSQL Operational data , Read first CSv file , Save to Hudi In the table . * step1. structure SparkSession Instance object ( Integrate Hudi and HDFS) * step2. Load local CSV File format didi travel data * step3. Didi travel data ETL Handle * stpe4. Save the converted data to Hudi surface * step5. The application ends and the resource is closed */
object DidiStorageSpark {
// Didi data path
//file Represents the local file system
def datasPath : String = "file:///D:/BigData/Hudi/heima/ExerciseProject/hudi-learning/datas/didi/dwv_order_make_haikou_1.txt"
//Hudi Attributes in the table
val hudiTableName : String = "tbl_didi_haikou"
val hudiTablePath : String = "/hudi-warehouse/tbl_didi_haikou"
/** * Read csv Formatted text file data , Package to DataFrame in */
def readCsvFile(spark: SparkSession, path: String): DataFrame = {
spark.read
// Set the separator to tab
.option("sep", "\\t")
// File header line name
.option("header", true)
// Automatically infer types based on numerical values
.option("inferSchema", "true")
// specify the path to a file
.csv(path)
}
/** * Analyze the data of didi travel in Haikou ETL Conversion operation : Appoint ts and partitionpath Column */
def procevss(dataFrame: DataFrame): DataFrame = {
dataFrame
// add to hudi Partition field of the table , Third level division -> yyyy-MM-dd
.withColumn(
"partitionpath",
concat_ws("-", col("year"), col("month"), col("day"))
)
.drop("year", "month", "day")
// add to timestamp Column , As Hudi When merging table record data, fields , Use the departure time
//departure_time yes String type , It needs to be converted into Long type
.withColumn(
"ts",
unix_timestamp(col("departure_time"), "yyyy-MM-dd HH:mm:ss")
)
}
/** * Put the dataset DataFrame Save to Hudi In the table , The type of the table is COW, It belongs to batch saving data , Write less and read more */
def saveToHudi(dataframe: DataFrame, table: String, path: String): Unit = {
// Import package
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
// Save the data
// Save the data
dataframe.write
.mode(SaveMode.Overwrite)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi Set the attribute value of the table
.option(RECORDKEY_FIELD.key(), "order_id")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","hty")
//step1. structure SparkSession Instance object ( Integrate Hudi and HDFS)
val spark: SparkSession = SparkUtils.createSpakSession(this.getClass)
//step2. Load local CSV File format didi travel data
val didiDF = readCsvFile(spark, datasPath)
// didiDF.printSchema()
// didiDF.show(10, truncate = false)
//step3. Didi travel data ETL Handle
val etlDF: DataFrame = procevss(didiDF)
etlDF.printSchema()
etlDF.show(10,truncate = false)
//stpe4. Save the converted data to Hudi surface
saveToHudi(etlDF, hudiTableName, hudiTablePath)
}
}
Be careful :
def datasPath : String = “file:///D:/BigData/Hudi/heima/ExerciseProject/hudi-learning/datas/didi/dwv_order_make_haikou_1.txt”
Change to the location where the dataset is stored
test result
root
|-- order_id: long (nullable = true)
|-- product_id: integer (nullable = true)
|-- city_id: integer (nullable = true)
|-- district: integer (nullable = true)
|-- county: integer (nullable = true)
|-- type: integer (nullable = true)
|-- combo_type: integer (nullable = true)
|-- traffic_type: integer (nullable = true)
|-- passenger_count: integer (nullable = true)
|-- driver_product_id: integer (nullable = true)
|-- start_dest_distance: integer (nullable = true)
|-- arrive_time: string (nullable = true)
|-- departure_time: string (nullable = true)
|-- pre_total_fee: double (nullable = true)
|-- normal_time: string (nullable = true)
|-- bubble_trace_id: string (nullable = true)
|-- product_1level: integer (nullable = true)
|-- dest_lng: double (nullable = true)
|-- dest_lat: double (nullable = true)
|-- starting_lng: double (nullable = true)
|-- starting_lat: double (nullable = true)
|-- year: integer (nullable = true)
|-- month: integer (nullable = true)
|-- day: integer (nullable = true)
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+----+-----+---+
|order_id |product_id|city_id|district|county|type|combo_type|traffic_type|passenger_count|driver_product_id|start_dest_distance|arrive_time |departure_time |pre_total_fee|normal_time|bubble_trace_id |product_1level|dest_lng|dest_lat|starting_lng|starting_lat|year|month|day|
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+----+-----+---+
|17592880231474|3 |83 |898 |460106|0 |0 |0 |0 |3 |3806 |2017-05-26 00:04:47|2017-05-26 00:02:43|11.0 |14 |d88a957f7f1ff9fae80a9791103f0303|3 |110.3463|20.0226 |110.3249 |20.0212 |2017|5 |26 |
|17592880435172|3 |83 |898 |460106|0 |0 |0 |0 |3 |3557 |2017-05-26 00:16:07|2017-05-26 00:13:12|11.0 |8 |a692221c507544783a0519b810390303|3 |110.3285|20.0212 |110.3133 |20.0041 |2017|5 |26 |
|17592880622846|3 |83 |898 |460108|0 |0 |0 |0 |3 |3950 |2017-05-26 01:05:53|2017-05-26 01:03:25|12.0 |8 |c0a80166cf3529b8a11ef1af10440303|3 |110.3635|20.0061 |110.3561 |20.0219 |2017|5 |26 |
|17592880665344|3 |83 |898 |460106|0 |0 |0 |0 |3 |2265 |2017-05-26 00:51:31|2017-05-26 00:48:24|9.0 |6 |6446aa1459270ad8255c9d6e26e5ff02|3 |110.3172|19.9907 |110.3064 |20.0005 |2017|5 |26 |
|17592880763217|3 |83 |898 |460106|0 |0 |0 |0 |3 |7171 |0000-00-00 00:00:00|2017-05-26 00:55:16|20.0 |NULL |64469e3e59270c7308f066ae2187a102|3 |110.3384|20.0622 |110.3347 |20.0269 |2017|5 |26 |
|17592880885186|3 |83 |898 |460107|0 |0 |0 |0 |3 |8368 |2017-05-26 02:00:15|2017-05-26 01:54:26|24.0 |15 |6446a13459271a517a8435b41aa8a002|3 |110.3397|20.0395 |110.3541 |19.9947 |2017|5 |26 |
|17592881134529|3 |83 |898 |460106|0 |0 |0 |0 |3 |4304 |2017-05-26 03:38:13|2017-05-26 03:33:24|13.0 |NULL |64469e3b59273182744d550020dd6f02|3 |110.3608|20.027 |110.3435 |20.0444 |2017|5 |26 |
|17592881199105|3 |83 |898 |460108|0 |0 |0 |0 |3 |6247 |2017-05-26 03:18:04|2017-05-26 03:15:36|17.0 |12 |64469c3159272d57041f9b782352e802|3 |110.3336|20.001 |110.3461 |20.0321 |2017|5 |26 |
|17592881962918|3 |83 |898 |460106|0 |0 |0 |0 |3 |5151 |2017-05-26 07:13:13|2017-05-26 07:03:29|14.0 |13 |c0a800655927626800006caf8c764d23|3 |110.3433|19.9841 |110.3326 |20.0136 |2017|5 |26 |
|17592882308885|3 |83 |898 |460108|0 |0 |0 |0 |3 |7667 |2017-05-26 07:29:18|2017-05-26 07:23:13|19.0 |20 |c0a8030376f0685e4927c11310330303|3 |110.3121|20.0252 |110.3577 |20.0316 |2017|5 |26 |
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+----+-----+---+
only showing top 10 rows
root
|-- order_id: long (nullable = true)
|-- product_id: integer (nullable = true)
|-- city_id: integer (nullable = true)
|-- district: integer (nullable = true)
|-- county: integer (nullable = true)
|-- type: integer (nullable = true)
|-- combo_type: integer (nullable = true)
|-- traffic_type: integer (nullable = true)
|-- passenger_count: integer (nullable = true)
|-- driver_product_id: integer (nullable = true)
|-- start_dest_distance: integer (nullable = true)
|-- arrive_time: string (nullable = true)
|-- departure_time: string (nullable = true)
|-- pre_total_fee: double (nullable = true)
|-- normal_time: string (nullable = true)
|-- bubble_trace_id: string (nullable = true)
|-- product_1level: integer (nullable = true)
|-- dest_lng: double (nullable = true)
|-- dest_lat: double (nullable = true)
|-- starting_lng: double (nullable = true)
|-- starting_lat: double (nullable = true)
|-- partitionpath: string (nullable = false)
|-- ts: long (nullable = true)
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+-------------+----------+
|order_id |product_id|city_id|district|county|type|combo_type|traffic_type|passenger_count|driver_product_id|start_dest_distance|arrive_time |departure_time |pre_total_fee|normal_time|bubble_trace_id |product_1level|dest_lng|dest_lat|starting_lng|starting_lat|partitionpath|ts |
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+-------------+----------+
|17592880231474|3 |83 |898 |460106|0 |0 |0 |0 |3 |3806 |2017-05-26 00:04:47|2017-05-26 00:02:43|11.0 |14 |d88a957f7f1ff9fae80a9791103f0303|3 |110.3463|20.0226 |110.3249 |20.0212 |2017-5-26 |1495728163|
|17592880435172|3 |83 |898 |460106|0 |0 |0 |0 |3 |3557 |2017-05-26 00:16:07|2017-05-26 00:13:12|11.0 |8 |a692221c507544783a0519b810390303|3 |110.3285|20.0212 |110.3133 |20.0041 |2017-5-26 |1495728792|
|17592880622846|3 |83 |898 |460108|0 |0 |0 |0 |3 |3950 |2017-05-26 01:05:53|2017-05-26 01:03:25|12.0 |8 |c0a80166cf3529b8a11ef1af10440303|3 |110.3635|20.0061 |110.3561 |20.0219 |2017-5-26 |1495731805|
|17592880665344|3 |83 |898 |460106|0 |0 |0 |0 |3 |2265 |2017-05-26 00:51:31|2017-05-26 00:48:24|9.0 |6 |6446aa1459270ad8255c9d6e26e5ff02|3 |110.3172|19.9907 |110.3064 |20.0005 |2017-5-26 |1495730904|
|17592880763217|3 |83 |898 |460106|0 |0 |0 |0 |3 |7171 |0000-00-00 00:00:00|2017-05-26 00:55:16|20.0 |NULL |64469e3e59270c7308f066ae2187a102|3 |110.3384|20.0622 |110.3347 |20.0269 |2017-5-26 |1495731316|
|17592880885186|3 |83 |898 |460107|0 |0 |0 |0 |3 |8368 |2017-05-26 02:00:15|2017-05-26 01:54:26|24.0 |15 |6446a13459271a517a8435b41aa8a002|3 |110.3397|20.0395 |110.3541 |19.9947 |2017-5-26 |1495734866|
|17592881134529|3 |83 |898 |460106|0 |0 |0 |0 |3 |4304 |2017-05-26 03:38:13|2017-05-26 03:33:24|13.0 |NULL |64469e3b59273182744d550020dd6f02|3 |110.3608|20.027 |110.3435 |20.0444 |2017-5-26 |1495740804|
|17592881199105|3 |83 |898 |460108|0 |0 |0 |0 |3 |6247 |2017-05-26 03:18:04|2017-05-26 03:15:36|17.0 |12 |64469c3159272d57041f9b782352e802|3 |110.3336|20.001 |110.3461 |20.0321 |2017-5-26 |1495739736|
|17592881962918|3 |83 |898 |460106|0 |0 |0 |0 |3 |5151 |2017-05-26 07:13:13|2017-05-26 07:03:29|14.0 |13 |c0a800655927626800006caf8c764d23|3 |110.3433|19.9841 |110.3326 |20.0136 |2017-5-26 |1495753409|
|17592882308885|3 |83 |898 |460108|0 |0 |0 |0 |3 |7667 |2017-05-26 07:29:18|2017-05-26 07:23:13|19.0 |20 |c0a8030376f0685e4927c11310330303|3 |110.3121|20.0252 |110.3577 |20.0316 |2017-5-26 |1495754593|
+--------------+----------+-------+--------+------+----+----------+------------+---------------+-----------------+-------------------+-------------------+-------------------+-------------+-----------+--------------------------------+--------------+--------+--------+------------+------------+-------------+----------+
only showing top 10 rows
You can see that the data is transformed and stored in the desired way .
Until then HDFS Check whether the storage is successful :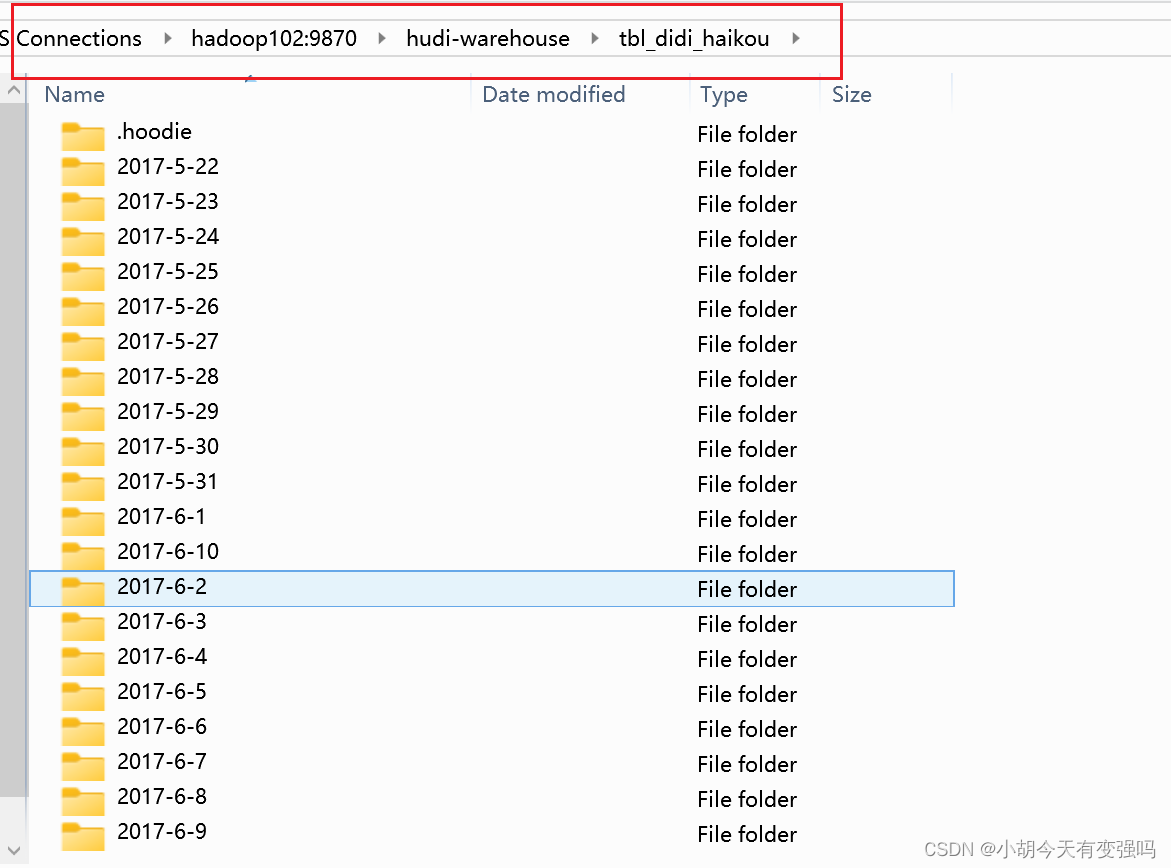
HDFS The data was successfully converted to Hudi In the form of table .
Index query analysis
Code writing
- DidiAnalysisSpark.scala
import java.util.{
Calendar, Date}
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{
DataFrame, SparkSession}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.sql.functions._
/** * Analysis of travel operation data of didi Haikou , Use SparkSQL Operational data , load Hudi Table data , Statistics according to business needs . */
object DidiAnalysisSpark {
//Hudi Table properties , Storage HDFS route
val hudiTablePath = "/hudi-warehouse/tbl_didi_haikou"
/** * load Hudi Table data , Package to DataFrame in */
def readFromHudi(spark: SparkSession, path: String): DataFrame = {
val didDF: DataFrame = spark.read.format("hudi").load(path)
// Selection field
didDF.select(
"product_id", "type", "traffic_type", "pre_total_fee", "start_dest_distance", "departure_time"
)
}
/** * Order type statistics , Field :product_id */
def reportProduct(dataframe: DataFrame): Unit = {
//a. According to the product line id Grouping statistics is enough
val reportDF: DataFrame = dataframe.groupBy("product_id").count()
//b. Customize UDF function , Conversion name
val to_name = udf(
// Anonymous functions
(productId: Int) => {
productId match {
case 1 => " Didi special car "
case 2 => " Didi enterprise bus "
case 3 => " Didi express "
case 4 => " Didi enterprise bus "
}
}
)
//c. Conversion name
val resultDF: DataFrame = reportDF.select(
to_name(col("product_id")).as("order_type"),
col("count").as("total")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
/** * Order timeliness statistics , Field :type */
def reportType(dataframe: DataFrame): Unit = {
// a. According to timeliness id Grouping statistics is enough
val reportDF: DataFrame = dataframe.groupBy("type").count()
// b. Customize UDF function , Conversion name
val to_name = udf(
(realtimeType: Int) => {
realtimeType match {
case 0 => " real time "
case 1 => " make an appointment "
}
}
)
// c. Conversion name
val resultDF: DataFrame = reportDF.select(
to_name(col("type")).as("order_realtime"),
col("count").as("total")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
def reportTraffic(dataframe: DataFrame): Unit = {
// a. According to the traffic type id Grouping statistics is enough
val reportDF: DataFrame = dataframe.groupBy("traffic_type").count()
// b. Customize UDF function , Conversion name
val to_name = udf(
(trafficType: Int) => {
trafficType match {
case 0 => " Ordinary individual tourists "
case 1 => " Enterprise time rent "
case 2 => " Business pick-up package "
case 3 => " Enterprise free package "
case 4 => " Carpooling "
case 5 => " Pick someone up at the airport "
case 6 => " Delivery "
case 302 => " Intercity carpooling "
case _ => " Unknown "
}
}
)
// c. Conversion name
val resultDF: DataFrame = reportDF.select(
to_name(col("traffic_type")).as("traffic_type"),
col("count").as("total")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
/** * Order price statistics , First, divide the order price into stages , Then count the number of each stage , Use fields :pre_total_fee */
def reportPrice(dataframe: DataFrame): Unit = {
val resultDF: DataFrame = dataframe
.agg(
// Price 0 ~ 15
sum(
when(col("pre_total_fee").between(0, 15), 1).otherwise(0)
).as("0~15"),
// Price 16 ~ 30
sum(
when(col("pre_total_fee").between(16, 30), 1).otherwise(0)
).as("16~30"),
// Price 31 ~ 50
sum(
when(col("pre_total_fee").between(31, 50), 1).otherwise(0)
).as("31~50"),
// Price 51 ~ 100
sum(
when(col("pre_total_fee").between(51, 100), 1).otherwise(0)
).as("51~100"),
// Price 100+
sum(
when(col("pre_total_fee").gt(100), 1).otherwise(0)
).as("100+")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
/** * Order distance statistics , First, divide the order distance into different intervals , Then count the number of each interval , Use fields :start_dest_distance */
def reportDistance(dataframe: DataFrame): Unit = {
val resultDF: DataFrame = dataframe
.agg(
// distance : 0 ~ 10km
sum(
when(col("start_dest_distance").between(0, 10000), 1).otherwise(0)
).as("0~10km"),
// distance : 10 ~ 20km
sum(
when(col("start_dest_distance").between(10001, 20000), 1).otherwise(0)
).as("10~20km"),
// distance : 20 ~ 20km
sum(
when(col("start_dest_distance").between(20001, 30000), 1).otherwise(0)
).as("20~30"),
// distance : 30 ~ 50km
sum(
when(col("start_dest_distance").between(30001, 50000), 1).otherwise(0)
).as("30~50km"),
// distance : 50km+
sum(
when(col("start_dest_distance").gt(50001), 1).otherwise(0)
).as("50+km")
)
resultDF.printSchema()
resultDF.show(10, truncate = false)
}
/** * Order week grouping statistics , First convert the date to the week , Then group the weeks , Use fields :departure_time */
def reportWeek(dataframe: DataFrame): Unit = {
// a. Customize UDF function , The conversion date is week
val to_week: UserDefinedFunction = udf(
(dateStr: String) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
val calendar: Calendar = Calendar.getInstance();
val date: Date = format.parse(dateStr)
calendar.setTime(date)
val dayWeek = calendar.get(Calendar.DAY_OF_WEEK) match {
case 1 => " Sunday "
case 2 => " Monday "
case 3 => " Tuesday "
case 4 => " Wednesday "
case 5 => " Thursday "
case 6 => " Friday "
case 7 => " Saturday "
}
// Just return to the week
dayWeek
}
)
//b. Process the data
val reportDF: DataFrame = dataframe
.select(
to_week(col("departure_time")).as("week")
)
.groupBy("week").count()
.select(
col("week"), col("count").as("total")
)
reportDF.printSchema()
reportDF.show(10, truncate = false)
}
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "hty")
//step1、 structure SparkSession Instance object ( Integrate Hudi and HDFS)
val spark: SparkSession = SparkUtils.createSpakSession(this.getClass, partitions = 8)
//step2、 load Hudi The data table , Specified field
val hudiDF: DataFrame = readFromHudi(spark, hudiTablePath)
//hudiDF.printSchema()
//hudiDF.show(10, truncate = false)
// Because data is used many times , So it is recommended to cache
hudiDF.persist(StorageLevel.MEMORY_AND_DISK)
// step3、 Conduct statistical analysis according to business indicators
// indicators 1: Order type statistics
reportProduct(hudiDF)
// indicators 2: Order timeliness statistics
reportType(hudiDF)
// indicators 3: Traffic type statistics
reportTraffic(hudiDF)
// indicators 4: Order price statistics
reportPrice(hudiDF)
// indicators 5: Order distance statistics
reportDistance(hudiDF)
// indicators 6: The date type -> week , Make statistics
reportWeek(hudiDF)
// When the data doesn't exist , Release resources
hudiDF.unpersist()
// step4、 End of application , close resource
spark.stop()
}
}
test result
root
|-- order_type: string (nullable = true)
|-- total: long (nullable = false)
+----------+-------+
|order_type|total |
+----------+-------+
| Didi express |1298383|
| Didi special car |15615 |
+----------+-------+
root
|-- order_realtime: string (nullable = true)
|-- total: long (nullable = false)
+--------------+-------+
|order_realtime|total |
+--------------+-------+
| make an appointment |28488 |
| real time |1285510|
+--------------+-------+
root
|-- traffic_type: string (nullable = true)
|-- total: long (nullable = false)
+------------+-------+
|traffic_type|total |
+------------+-------+
| Delivery |37469 |
| Pick someone up at the airport |19694 |
| Ordinary individual tourists |1256835|
+------------+-------+
root
|-- 0~15: long (nullable = true)
|-- 16~30: long (nullable = true)
|-- 31~50: long (nullable = true)
|-- 51~100: long (nullable = true)
|-- 100+: long (nullable = true)
+------+------+-----+------+----+
|0~15 |16~30 |31~50|51~100|100+|
+------+------+-----+------+----+
|605354|532553|96559|58172 |4746|
+------+------+-----+------+----+
root
|-- 0~10km: long (nullable = true)
|-- 10~20km: long (nullable = true)
|-- 20~30: long (nullable = true)
|-- 30~50km: long (nullable = true)
|-- 50+km: long (nullable = true)
+-------+-------+-----+-------+-----+
|0~10km |10~20km|20~30|30~50km|50+km|
+-------+-------+-----+-------+-----+
|1102204|167873 |39372|3913 |636 |
+-------+-------+-----+-------+-----+
root
|-- week: string (nullable = true)
|-- total: long (nullable = false)
+------+------+
|week |total |
+------+------+
| Sunday |137174|
| Thursday |197344|
| Monday |185065|
| Wednesday |175714|
| Tuesday |185391|
| Saturday |228930|
| Friday |204380|
+------+------+
The data was successfully statistically analyzed as required .
Integrate Hive Inquire about
establish Hive Connect
Click on Database establish hive The connection of , Fill in the relevant parameters 
Click on Test Connection To test , The following screenshot shows that the connection is successful 
Use hql The query
hudi-hive-didi.sql
-- 1. Create database database
CREATE DATABASE IF NOT EXISTS db_hudi ;
-- 2. Using a database
USE db_hudi ;
-- 3. Create table
CREATE EXTERNAL TABLE IF NOT EXISTS tbl_hudi_didi(
order_id bigint ,
product_id int ,
city_id int ,
district int ,
county int ,
type int ,
combo_type int ,
traffic_type int ,
passenger_count int ,
driver_product_id int ,
start_dest_distance int ,
arrive_time string ,
departure_time string ,
pre_total_fee double ,
normal_time string ,
bubble_trace_id string ,
product_1level int ,
dest_lng double ,
dest_lat double ,
starting_lng double ,
starting_lat double ,
partitionpath string ,
ts bigint
)
PARTITIONED BY (date_str string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION '/hudi-warehouse/tbl_didi_haikou' ;
-- View partition table partition
SHOW PARTITIONS db_hudi.tbl_hudi_didi ;
-- 5. Add partition information manually
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-22') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-22' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-23') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-23' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-24') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-24' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-25') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-25' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-26') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-26' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-27') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-27' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-28') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-28' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-29') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-29' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-30') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-30' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-5-31') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-5-31' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-1') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-1' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-2') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-2' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-3') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-3' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-4') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-4' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-5') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-5' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-6') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-6' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-7') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-7' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-8') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-8' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-9') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-9' ;
ALTER TABLE db_hudi.tbl_hudi_didi ADD IF NOT EXISTS PARTITION (date_str = '2017-6-10') LOCATION '/hudi-warehouse/tbl_didi_haikou/2017-6-10' ;
-- test , Query data
SET hive.mapred.mode = nonstrict ;
SELECT order_id, product_id, type, pre_total_fee, traffic_type, start_dest_distance FROM db_hudi.tbl_hudi_didi LIMIT 20;
-- Development testing , Set the operation mode to local mode
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.tasks.max=10;
set hive.exec.mode.local.auto.inputbytes.max=50000000;
set hive.support.concurrency=false;
set hive.auto.convert.join= false;
-- Indicator 1 : Order type statistics
WITH tmp AS (
SELECT product_id, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY product_id
)
SELECT
CASE product_id
WHEN 1 THEN " Didi special car "
WHEN 2 THEN " Didi enterprise bus "
WHEN 3 THEN " Didi express "
WHEN 4 THEN " Didi enterprise express "
END AS order_type,
total
FROM tmp ;
-- Indicator 2 : Order timeliness statistics
WITH tmp AS (
SELECT type, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY type
)
SELECT
CASE type
WHEN 0 THEN " real time "
WHEN 1 THEN " make an appointment "
END AS order_type,
total
FROM tmp ;
-- Indicator 3 : Order traffic type statistics
SELECT traffic_type, COUNT(1) AS total FROM db_hudi.tbl_hudi_didi GROUP BY traffic_type ;
-- Indicator 5 : Order price statistics , First divide the price into ranges , Re statistics , Use here WHEN Functions and SUM function
SELECT
SUM(
CASE WHEN pre_total_fee BETWEEN 0 AND 15 THEN 1 ELSE 0 END
) AS 0_15,
SUM(
CASE WHEN pre_total_fee BETWEEN 16 AND 30 THEN 1 ELSE 0 END
) AS 16_30,
SUM(
CASE WHEN pre_total_fee BETWEEN 31 AND 50 THEN 1 ELSE 0 END
) AS 31_50,
SUM(
CASE WHEN pre_total_fee BETWEEN 50 AND 100 THEN 1 ELSE 0 END
) AS 51_100,
SUM(
CASE WHEN pre_total_fee > 100 THEN 1 ELSE 0 END
) AS 100_
FROM
db_hudi.tbl_hudi_didi ;
Execute the sample :
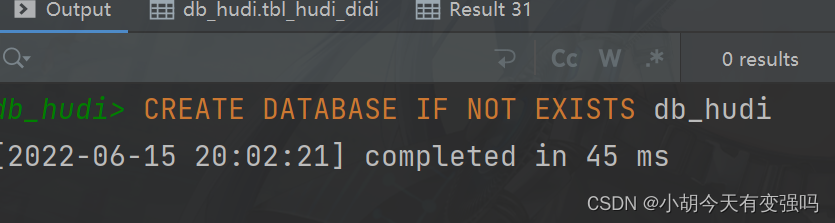
according to hql Just execute the statements in order , The results are consistent with the test results in the index query analysis .
But when I conduct five index query and analysis , newspaper Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask Error of . There is a reference room on the Internet that says Hadoop Less memory resource allocation , It still can't be configured according to the solution . I don't know why , Put it on hold , Find out the reason later .
Reference material
https://www.bilibili.com/video/BV1sb4y1n7hK?p=51&vd_source=e21134e00867aeadc3c6b37bb38b9eee
边栏推荐
- Win10 quick screenshot
- Move anaconda, pycharm and jupyter notebook to mobile hard disk
- LeetCode 715. Range 模块
- Build a solo blog from scratch
- Common formulas of probability theory
- Principles of computer composition - cache, connection mapping, learning experience
- Jenkins learning (III) -- setting scheduled tasks
- The method of replacing the newline character '\n' of a file with a space in the shell
- AcWing 786. 第k个数
- 【点云处理之论文狂读前沿版10】—— MVTN: Multi-View Transformation Network for 3D Shape Recognition
猜你喜欢
Build a solo blog from scratch
Move anaconda, pycharm and jupyter notebook to mobile hard disk
![[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition](/img/94/2ab1feb252dc84c2b4fcad50a0803f.png)
[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition
【点云处理之论文狂读经典版13】—— Adaptive Graph Convolutional Neural Networks

Instant messaging IM is the countercurrent of the progress of the times? See what jnpf says

【点云处理之论文狂读经典版10】—— PointCNN: Convolution On X-Transformed Points

低代码前景可期,JNPF灵活易用,用智能定义新型办公模式

精彩回顾|I/O Extended 2022 活动干货分享

【Kotlin学习】类、对象和接口——带非默认构造方法或属性的类、数据类和类委托、object关键字

Education informatization has stepped into 2.0. How can jnpf help teachers reduce their burden and improve efficiency?
随机推荐
常见渗透测试靶场
Simple use of MATLAB
[point cloud processing paper crazy reading cutting-edge version 12] - adaptive graph revolution for point cloud analysis
【点云处理之论文狂读前沿版13】—— GAPNet: Graph Attention based Point Neural Network for Exploiting Local Feature
一个优秀速开发框架是什么样的?
Crawler career from scratch (V): detailed explanation of re regular expression
Save the drama shortage, programmers' favorite high-score American drama TOP10
State compression DP acwing 91 Shortest Hamilton path
LeetCode 438. 找到字符串中所有字母异位词
AcWing 785. Quick sort (template)
On a un nom en commun, maître XX.
推荐一个 yyds 的低代码开源项目
Solve POM in idea Comment top line problem in XML file
Jenkins learning (III) -- setting scheduled tasks
[point cloud processing paper crazy reading classic version 7] - dynamic edge conditioned filters in revolutionary neural networks on Graphs
【点云处理之论文狂读前沿版8】—— Pointview-GCN: 3D Shape Classification With Multi-View Point Clouds
[point cloud processing paper crazy reading classic version 11] - mining point cloud local structures by kernel correlation and graph pooling
数字化管理中台+低代码,JNPF开启企业数字化转型的新引擎
教育信息化步入2.0,看看JNPF如何帮助教师减负,提高效率?
C language programming specification