当前位置:网站首页>A code example of the PCL method in the domain of DG (Domain Generalization)
A code example of the PCL method in the domain of DG (Domain Generalization)
2022-08-04 06:19:00 【nuomi666】
Share your articlesPCL: Proxy-based Contrastive Learning for Domain Generalization,代码已经在GitHub上已经开源,Its use is inDomainBedRealize the optimization of the frame on the basisSWADOn the framework of this paper mainly put some compact code,For each module only retained an algorithm.
DomainBedIf master toDGThe realization of a variety of methods in the field of,So the framework to write very complicated,封装了很多东西,For the first time to use classmates really unfriendly,Even may look not to understand even the input and output,如果对DG和DA感兴趣的同学,Here recommend a bosses to realizeDA和DG的库,Migration study code base,比较容易看懂!!
话不多说,直接上代码
主文件
main.py
import torch
import algorithm
from torch.autograd import Variable
from torchvision import datasets, transforms
#使用swad调优的话,Asynchronous finally
#import swa_utils
#import swad as swad_module
import torch.nn as nn
train_transforms= transforms.Compose([
transforms.Resize(256),
transforms.RandomRotation((5), expand=True),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.ColorJitter(.3, .3, .3, .3),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
val_dataTrans = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
train_data_dir = '../../data/train'
val_data_dir = '../../data/val'
test_data_dir='../../data/test'
train_dataset = datasets.ImageFolder(train_data_dir, train_transforms)
val_dataset = datasets.ImageFolder(val_data_dir,val_dataTrans)
test_dataset = datasets.ImageFolder(test_data_dir, val_dataTrans)
#According to the need to partition data set
# train_dataset = torch.utils.data.ConcatDataset([train_dataset1, test_dataset])
# val_dataset = datasets.ImageFolder(val_data_dir, _dataTrans)
# val_dataset, val_dataset_ = torch.utils.data.random_split(val_dataset, [5, len(val_dataset) - 5])
# train_dataset = torch.utils.data.ConcatDataset([train_dataset, val_dataset_])
train_dataloder = torch.utils.data.DataLoader(train_dataset,batch_size=4,shuffle=True)
val_dataloder = torch.utils.data.DataLoader(val_dataset,batch_size=4,shuffle=True)
device = "cuda" if torch.cuda.is_available() else"cpu"
# setup hparams
algorithm = algorithm.ERM(input_shape=[3, 244, 244], num_classes=4)
use_swad=False#是否使用swad优化
#The choice of the optimizer inalgorithm文件里
if use_swad:
swad_algorithm = swa_utils.AveragedModel(algorithm)
swad_cls = getattr(swad_module, 'LossValley')
swad_kwargs={
'n_converge': 3, 'n_tolerance': 6, 'tolerance_ratio': 0.3}
swad = swad_cls(**swad_kwargs)
algorithm.to(device)
lossfunc=nn.CrossEntropyLoss()
epochs=10
if __name__ == '__main__':
for epoch in range(epochs):
running_loss = 0
running_corrects = 0
algorithm.train()
for step ,(inputs, labels) in enumerate(train_dataloder):
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
step_vals = algorithm.update(inputs, labels)
if use_swad:
swad_algorithm.update_parameters(algorithm, step=step)
_, outputs = algorithm.predict(inputs)
_, preds = torch.max(outputs.data, 1)
train_loss = lossfunc(outputs, labels)
# statistics
running_loss += loss.data
train_acc=torch.sum(preds == labels.data).cpu().to(torch.float32)
running_corrects += train_acc
tr_epoch_loss = running_loss / len(train_dataloder)
tr_epoch_acc = running_corrects / len(train_dataloder)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(epoch, tr_epoch_loss, tr_epoch_acc))
with torch.no_grad():
algorithm.eval()
running_loss = 0
running_corrects = 0
for step, (inputs, labels) in enumerate(val_dataloder ):
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
_, outputs = algorithm.predict(inputs)
_, preds = torch.max(outputs.data, 1)
loss = lossfunc(outputs, labels)
# statistics
running_loss += loss.data
val_acc = torch.sum(preds == labels.data).cpu().to(torch.float32)
running_corrects += val_acc
te_epoch_loss = running_loss / len(val_dataloder)
te_epoch_acc = running_corrects / len(val_dataloder)
if use_swad:
swad.update_and_evaluate(swad_algorithm, te_epoch_acc)
swad_algorithm = swa_utils.AveragedModel(algorithm) # reset
filename = r'epoch{}_Loss{:.4f}_Acc{:.4f}_Loss{:.4f}_Acc{:.4f}.pth'.format(
epoch, tr_epoch_loss, tr_epoch_acc, te_epoch_loss, te_epoch_acc)
torch.save(algorithm.state_dict(), filename, _use_new_zipfile_serialization=False)
主算法
The main algorithm part,这里使用的是Empirical Risk Minimization (ERM, Vapnik, 1998),原DomainBedFramework provides many algorithm,如IRM、GroupDRO、RSC等,Can according to need to take.
————————————————————
algorithm.py
import math
from model import *
from losses import ProxyLoss, ProxyPLoss
import torch
class ERM(torch.nn.Module):
""" Empirical Risk Minimization (ERM) """
def __init__(self, input_shape, num_classes):
super(ERM, self).__init__()
self.encoder, self.scale, self.pcl_weights = encoder()
self._initialize_weights(self.encoder)
self.fea_proj, self.fc_proj = fea_proj()
nn.init.kaiming_uniform_(self.fc_proj, mode='fan_out', a=math.sqrt(5))
self.featurizer = ResNet()
self.classifier = nn.Parameter(torch.FloatTensor(num_classes,256))
nn.init.kaiming_uniform_(self.classifier, mode='fan_out', a=math.sqrt(5))
self.optimizer = torch.optim.Adam([
{
'params': self.featurizer.parameters()},
{
'params': self.encoder.parameters()},
{
'params': self.fea_proj.parameters()},
{
'params': self.fc_proj},
{
'params': self.classifier},
], lr=0.002, weight_decay=0.0)
self.proxycloss = ProxyPLoss(num_classes=num_classes, scale=self.scale)
def _initialize_weights(self, modules):
for m in modules:
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def update(self, x, y, **kwargs):
all_x = x
all_y = y
rep, pred = self.predict(all_x)
loss_cls = F.nll_loss(F.log_softmax(pred, dim=1), all_y)
fc_proj = F.linear(self.classifier, self.fc_proj)
assert fc_proj.requires_grad == True
loss_pcl = self.proxycloss(rep, all_y, fc_proj)
loss = loss_cls + self.pcl_weights * loss_pcl
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return {
"loss_cls": loss_cls.item(), "loss_pcl": loss_pcl.item()}
def predict(self, x):
x = self.featurizer(x)
x = self.encoder(x)
rep = self.fea_proj(x)
pred = F.linear(x, self.classifier)
return rep, pred
网络结构
Next is the main network structure module,这里是用的ResNet50For the feature extraction of images,Then use the connection layer forencoder
————————————————————
model.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models
class Identity(nn.Module):
"""An identity layer"""
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
class SqueezeLastTwo(nn.Module):
""" A module which squeezes the last two dimensions, ordinary squeeze can be a problem for batch size 1 """
def __init__(self):
super(SqueezeLastTwo, self).__init__()
def forward(self, x):
return x.view(x.shape[0], x.shape[1])
class ResNet(torch.nn.Module):
"""ResNet with the softmax chopped off and the batchnorm frozen"""
def __init__(self):
super(ResNet, self).__init__()
#If you want to use other network for feature extraction,可以在这里改
#But to take the followingencoderModule layer of all connections of the input and output new network last full connection is the same
network = torchvision.models.resnet50(pretrained=False)
# network = resnet50(pretrained=hparams["pretrained"])
self.network = network
# adapt number of channels
# save memory
# del self.network.fc
#The new network output layer replacement is empty,用来提供encoder的接口
#tips;The last layer is mostlymodel.fc或model.head
self.network.fc = Identity()
self.dropout = nn.Dropout(0.1)
self.freeze_bn()
def forward(self, x):
"""Encode x into a feature vector of size n_outputs."""
return self.dropout(self.network(x))
def train(self, mode=True):
""" Override the default train() to freeze the BN parameters """
super().train(mode)
self.freeze_bn()
def freeze_bn(self):
for m in self.network.modules():
if isinstance(m, nn.BatchNorm2d):
m.eval()
def encoder():
scale_weights = 12
pcl_weights = 1
dropout = nn.Dropout(0.25)
hidden_size = 512
out_dim = 256
#In the new network should pay attention to change here
n_outputs = 2048
encoder = nn.Sequential(
nn.Linear(n_outputs, hidden_size),
nn.BatchNorm1d(hidden_size),
nn.ReLU(inplace=True),
dropout,
nn.Linear(hidden_size, out_dim),
)
return encoder, scale_weights, pcl_weights
def fea_proj():
dropout = nn.Dropout(0.25)
hidden_size = 256
out_dim = 256
fea_proj = nn.Sequential(
nn.Linear(out_dim,
out_dim),
)
fc_proj = nn.Parameter(
torch.FloatTensor(out_dim,
out_dim)
)
return fea_proj, fc_proj
损失函数
PCL中提到的损失函数
————————————————————————
losses.py
# coding: utf-8
''' custom loss function '''
import math
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# # ========================= proxy Contrastive loss ==========================
class ProxyLoss(nn.Module):
''' pass '''
def __init__(self, scale=1, thres=0.1):
super(ProxyLoss, self).__init__()
self.scale = scale
self.thres = thres
def forward(self, feature, pred, target):
feature = F.normalize(feature, p=2, dim=1) # normalize
feature = torch.matmul(feature, feature.transpose(1, 0)) # (B, B)
label_matrix = target.unsqueeze(1) == target.unsqueeze(0)
feature = feature * ~label_matrix # get negative matrix
feature = feature.masked_fill(feature < self.thres, -np.inf)
pred = torch.cat([pred, feature], dim=1) # (N, C+N)
loss = F.nll_loss(F.log_softmax(self.scale * pred, dim=1), \
target)
return loss
class ProxyPLoss(nn.Module):
''' pass '''
def __init__(self, num_classes, scale):
super(ProxyPLoss, self).__init__()
self.soft_plus = nn.Softplus()
self.label = torch.LongTensor([i for i in range(num_classes)]).cuda()
self.scale = scale
def forward(self, feature, target, proxy):
feature = F.normalize(feature, p=2, dim=1)
pred = F.linear(feature, F.normalize(proxy, p=2, dim=1)) # (N, C)
label = (self.label.unsqueeze(1) == target.unsqueeze(0))
pred = torch.masked_select(pred.transpose(1, 0), label)
pred = pred.unsqueeze(1)
feature = torch.matmul(feature, feature.transpose(1, 0)) # (N, N)
label_matrix = target.unsqueeze(1) == target.unsqueeze(0)
index_label = torch.LongTensor([i for i in range(feature.shape[0])]) # generate index label
index_matrix = index_label.unsqueeze(1) == index_label.unsqueeze(0) # get index matrix
feature = feature * ~label_matrix # get negative matrix
feature = feature.masked_fill(feature < 1e-6, -np.inf)
logits = torch.cat([pred, feature], dim=1) # (N, C+N)
label = torch.zeros(logits.size(0), dtype=torch.long).cuda()
loss = F.nll_loss(F.log_softmax(self.scale * logits, dim=1), label)
return loss
class PosAlign(nn.Module):
''' pass '''
def __init__(self):
super(PosAlign, self).__init__()
self.soft_plus = nn.Softplus()
def forward(self, feature, target):
feature = F.normalize(feature, p=2, dim=1)
feature = torch.matmul(feature, feature.transpose(1, 0)) # (N, N)
label_matrix = target.unsqueeze(1) == target.unsqueeze(0)
positive_pair = torch.masked_select(feature, label_matrix)
# print("positive_pair.shape", positive_pair.shape)
loss = 1. * self.soft_plus(torch.logsumexp(positive_pair, 0))
return loss
SWAD调参
如果要使用SWAD调参,Can go fromGitHub自取swad和swa_utils.
After the line by line analysis again when you have time…
边栏推荐
猜你喜欢
![[Deep Learning Diary] Day 1: Hello world, Hello CNN MNIST](/img/06/6f49260732e5832edae2ec80aafc99.png)
[Deep Learning Diary] Day 1: Hello world, Hello CNN MNIST
![[Deep Learning 21-Day Learning Challenge] 3. Use a self-made dataset - Convolutional Neural Network (CNN) Weather Recognition](/img/d0/3b8549b9704278e8ec1df03a90f80e.png)
[Deep Learning 21-Day Learning Challenge] 3. Use a self-made dataset - Convolutional Neural Network (CNN) Weather Recognition
YOLOV5 V6.1 详细训练方法

Th in thymeleaf: href use notes
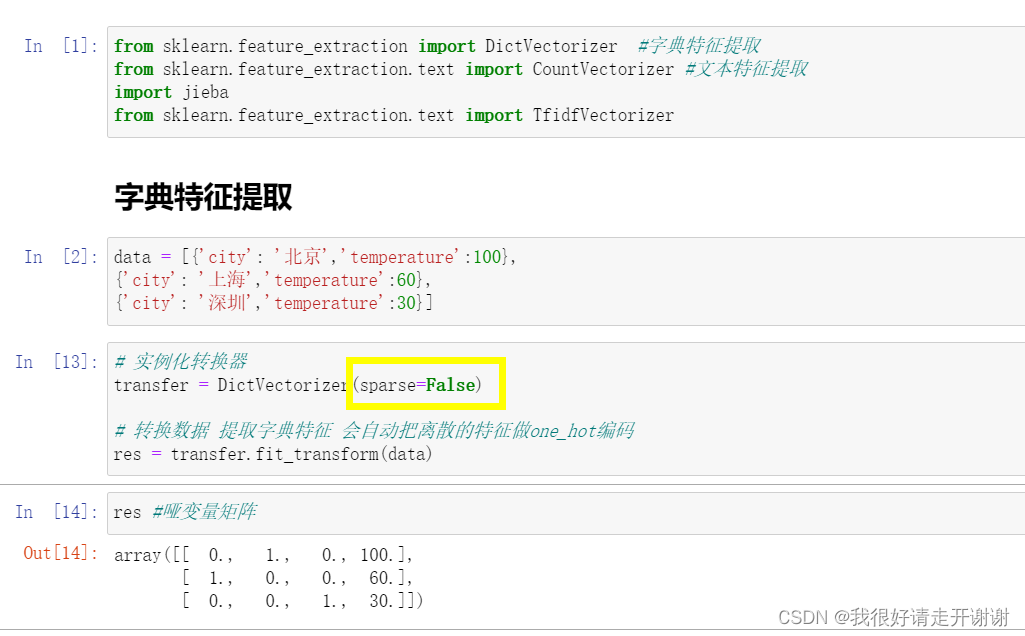
Dictionary feature extraction, text feature extraction.
![[CV-Learning] Linear Classifier (SVM Basics)](/img/94/b48e34b2c215ca47f8ca25ce97547e.png)
[CV-Learning] Linear Classifier (SVM Basics)

【CV-Learning】卷积神经网络预备知识
代码庆端午--粽你心意

Copy攻城狮信手”粘“来 AI 对对联

【CV-Learning】Image Classification
随机推荐
[Go language entry notes] 13. Structure (struct)
动手学深度学习_线性回归
Learning curve learning_curve function in sklearn
如何用Pygame制作简单的贪吃蛇游戏
代码庆端午--粽你心意
YOLOV5 V6.1 详细训练方法
[CV-Learning] Linear Classifier (SVM Basics)
Install dlib step pit record, error: WARNING: pip is configured with locations that require TLS/SSL
打金?工作室?账号被封?游戏灰黑产离我们有多近
【代码学习】
审稿意见回复
Copy攻城狮5分钟在线体验 MindIR 格式模型生成
Halcon缺陷检测
基于PyTorch的FCN-8s语义分割模型搭建
【论文阅读】Multi-View Spectral Clustering with Optimal Neighborhood Laplacian Matrix
TensorFlow2 study notes: 4. The first neural network model, iris classification
【CV-Learning】Convolutional Neural Network
(导航页)OpenStack-M版-双节点手工搭建-附B站视频
Amazon Cloud Technology Build On 2022 - AIot Season 2 IoT Special Experiment Experience
read and study