当前位置:网站首页>20220526 yolov1-v5
20220526 yolov1-v5
2022-06-12 07:35:00 【GAOSHIQI5322688】
you only look once
一、FasterRcnn 先实现感兴趣区域生成,再进行精细的分类和回归,限制了速度。
二、yolov1 无锚框预测
1、网络结构
卷机神经网络
24个卷机层和两个全连接层。
细节:
3*3卷机后接一个通道数低的1*1卷机,降低计算量
都是激活函数 leaky relu ,最后是线性激活函数
训练使用dropout与数据增强来防止过拟合。
2、特征图意义
7*7*30 大小的特征图。
图像划分成7*7的区域,每个区域对应特征图的一个点,该点通道数为30,代表预测的30个特征。
每个区域内预测两个边框。
预测特征由类别概率、边框的置信度、边框位置组成。
1》类别概率:预测边框是哪个类别。
2〉置信度:该区域内是否包含物体的概率。两个框,两个置信度。
3》边框位置:中心坐标和宽高4个量。 两个边框8个值
细节:
1〉yolov1没有先验框,每个区域预测框的大小和位置,是回归问题。
2》两个边框公用一个类别预测。在训练时选取和物体iou大的框。在预测时,选取置信度高的一个框,所以最多检测出49个物体。
3》采用物体类别和置信度分开预测方法。而fasterrcnn背景当作一个类别,在类别预测中包含了置信度的预测。
不足:
1》只能49,有限制,挨着近的不行
2〉没有anchor,对于新的宽高比例的物体检测效果不好。
3》损失函数,大小物体损失占比失衡,定位不准确。
3、损失计算
原则:
1、与真实物体 iou大的为正样本,这个区域类别真值为真实物体类别,该边框置信度真值为 1
2、除了正样本,其余为负样本.负样本没有类别损失和位置损失,只有置信度损失,其真值为0
损失意义: 均使用均方差损失
1、正样本中心点坐标损失
2、正样本宽高损失
3、正样本与负样本的置信度损失。
4、正样本类别损失
三、yolov2依赖锚框
使用darknet网络结构。
darknet优化点:
1、BN层:解决梯度消失和爆炸问题。加速收敛、正则化。在每个卷机之后,激活函数之前。leakey relu
2、用连续的3*3 替代v1的7*7卷机,减少计算量,增加了网络深度。去掉全连接和dropout层。
3、深浅层特征融合,浅层变化13*13*2048,和深层13*13*1024的特征通道拼接。利于小物体检测。
4、每个区域预测5个边框,每个边框有25个预测值,分别20个类别预测、4个(中心xy,宽高wh)偏移量位置、1个置信度。v1是共享类别预测。
先验框设计
1、v2使用聚类
2、优化偏移公式
faster rcnn 预测的边框中心可以出现在图像任何位置,没有限制。
正负样本和损失函数
将预测的位置偏移量作用到先验框上,得到预测框的真实位置。
如果一个预测框和所有真实物体的最大iou小于一定阈值,该预测框为负样本。
真实物体中心点的区域和物体的iou最大预测框为正样本。
保证recall
损失计算:
1、负样本的置信度损失
2、先验框和预测框的损失
3、正样本的位置损失
4、正样本的置信度损失和类别损失。
工程技巧:
1、多尺度训练
接受任意尺寸的输入图片。
2、多阶段训练
darknet分类. 224*224
分类。448*448
检测 darknet passthrouth
优点: 先验框、特征融合
v2不足:
1、虽然采用passrhrouth 采用一层特征图融合,小物体检测有限
2、太工程话,调参数太多
五、yolov3 多尺度与特征融合
1、网络结构darknet-53
DBL:卷机、BN、leaky relu
Res
上采样
concat
残差思想
多层特征图
无池化层
2、多尺度预测
输出三个尺度特征图,深层感受野大,有利于大物体,浅层有利于小物体。 类似FPN
沿用预选框,聚类,9个不同大小宽高的先验框,每个特征图的一个点需要预测3个框。感受野大的使用大的anchor.
优缺点:
优点:速度快、通用强、背景误检率低。
缺点:位置准确性差,召回率不高,对于遮挡和拥挤较难处理,无法高精度。

六、yolov4
yolov4数据输入采用mosaic
1、网络结构

yolov4是CSP darknet53,yolov3是darknet53
yolov3中只有res结构,可以发现yolov4中,res只是CSPx结构的一小部分,CSPx中,一个分支进行过res残差结构,另一个分支,直接和残差结构的结构cat到一起。
base layer后面会分出来两个分支,一个分支是一个大残差边,另外一个分支会接resnet残差结构,最后会将二者经过融合。而yolov3中只有csp中简单的残差,并没有最后的融合操作。
yolov4增加了spp,用来增加感受野
yolov4 ssp之后使用了PANet,进行特征融合。

激活函数:
mish
1.从图中可以看出他在负值的时候并不是完全截断,而是允许比较小的负梯度流入,从而保证信息流动。
2.并且激活函数无边界这个特点,让他避免了饱和这一问题,比如sigmoid,tanh激活函数通常存在梯度饱和问题,在两边极限情况下,梯度趋近于1,而Mish激活函数则巧妙的避开了这一点。
3.另外Mish函数也保证了每一点的平滑,从而使得梯度下降效果比Relu要好。
损失计算:
yolov4中采用CIOU loss
http://www.136.la/jingpin/show-141192.html
YOLOV4与YOLOV3的区别_进我的收藏吃灰吧~~的博客-CSDN博客_yolov4和yolov3的区别
六、yolov5
YOLOv5中的Focus层详解|CSDN创作打卡_tt丫的博客-CSDN博客_focus层
和yolov4的区别:
https://www.csdn.net/tags/OtTaMg2sMTU5NDktYmxvZwO0O0OO0O0O.html
nms:
前向推理:
YOLO中的NMS_WaitFoF的博客-CSDN博客_nms yolo
边栏推荐
- Study on display principle of seven segment digital tube
- LeetCode34. 在排序数组中查找元素的第一个和最后一个位置
- Set up a remote Jupiter notebook
- The first demand in my life - batch uploading of Excel data to the database
- Hongmeng OS first training
- R语言dplyr包mutate_at函数和one_of函数将dataframe数据中指定数据列(通过向量指定)的数据类型转化为因子类型
- AI fanaticism | come to this conference and work together on the new tools of AI!
- linux下怎么停止mysql服务
- Model deployment learning notes (I)
- Leetcode34. find the first and last positions of elements in a sorted array
猜你喜欢

Construction of running water lamp experiment with simulation software proteus

Logistic regression

Generalized semantic recognition based on semantic similarity
![[tutorial] deployment process of yolov5 based on tensorflow Lite](/img/d0/c38f27ad76b62b27cdeb68728e9c8c.jpg)
[tutorial] deployment process of yolov5 based on tensorflow Lite

Use of gt911 capacitive touch screen

Modelarts培训任务1
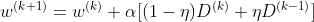
Summary of machine learning + pattern recognition learning (II) -- perceptron and neural network

Summary of semantic segmentation learning (II) -- UNET network
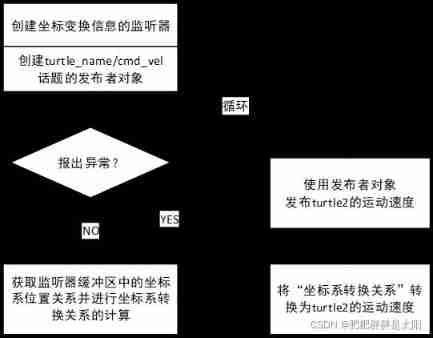
Detailed explanation of coordinate tracking of TF2 operation in ROS (example + code)

2022 electrician (elementary) examination question bank and simulation examination
随机推荐
Day 6 of pyhon
Paddepaddl 28 supports the implementation of GHM loss, a gradient balancing mechanism for arbitrary dimensional data (supports ignore\u index, class\u weight, back propagation training, and multi clas
R语言使用epiDisplay包的summ函数计算dataframe中指定变量在不同分组变量下的描述性统计汇总信息并可视化有序点图、使用dot.col参数设置不同分组数据点的颜色
Study on display principle of seven segment digital tube
Detailed explanation of 14 registers in 8086CPU
Chapter 3 - Fundamentals of cryptography
BI技巧丨当月期初
Interview computer network - transport layer
GD32F4(5):GD32F450时钟配置为200M过程分析
Chapter V - message authentication and digital signature
Voice assistant - Multi round conversation (process implementation)
Modelarts training task 1
2022起重机械指挥考试题模拟考试平台操作
Source code learning - [FreeRTOS] privileged_ Understanding of function meaning
‘CMRESHandler‘ object has no attribute ‘_ timer‘,socket. gaierror: [Errno 8] nodename nor servname pro
Exposure compensation, white increase and black decrease theory
Scoring prediction problem
Non IID data and continuous learning processes in federated learning: a long road ahead
AI fanaticism | come to this conference and work together on the new tools of AI!
Federated meta learning with fast convergence and effective communication