当前位置:网站首页>Différenciation et introduction des services groupés, distribués et microservices
Différenciation et introduction des services groupés, distribués et microservices
2022-07-07 05:37:00 【Jour férié】
Table des matières
2.、Pourquoi utiliser un Cluster?
1、Caractéristiques des grappes
3、Classification des grappes et caractéristiques des différentes classifications
Trois、Introduction à la classification des grappes
1、Cluster d'équilibrage de charge
3、Cluster informatique haute performance
Quatre、 Cluster vs. Distributed Difference
Cinq、 Différences entre les services distribués et les microservices
1、 Si la distribution appartient à un micro - service ?
2、Architecture des microservices
Un.、Le concept de Cluster
Un Cluster serveur est un système serveur , C'est grâce à un ensemble de logiciels serveurs faiblement intégrés et / Ou le matériel est connecté très étroitement pour compléter le calcul .En un sens,, Ils peuvent être considérés comme un serveur .
Les serveurs individuels d'un système groupé sont souvent appelés noeuds ,Généralement connecté au réseau local,Mais il y a d'autres connexions possibles. Les serveurs groupés sont souvent utilisés pour améliorer la vitesse de calcul et / Ou fiabilité . Regroupement général
Serveur plus qu'un seul serveur , Par exemple, les coûts de performance des postes de travail ou des superserveurs sont beaucoup plus élevés que . Un Cluster est un ensemble de serveurs indépendants ,Combiner les connexions réseau en une seule combinaison pour accomplir une tâche.
Dis - le en blanc, Un Cluster est un ensemble de serveurs indépendants les uns des autres , Former un système de serveurs via un réseau à grande vitesse ,Chaque noeud de Cluster est un serveur autonome qui exécute ses propres processus.Pour les utilisateurs du réseau,L'arrière - plan du site Web est un système unique,Collaborer pour fournir des ressources système aux utilisateurs,Services du système.
2.、Pourquoi utiliser un Cluster?
1、Caractéristiques des grappes
- Haute performanceperformance
Certains ont besoin d'une forte capacité de traitement informatique, comme les prévisions météorologiques , Essais nucléaires, etc. . Ce n'est pas quelque chose que quelques serveurs peuvent gérer . Il faut des milliers d'unités pour finir le travail .
- Efficacité des prix
En général, une architecture de Cluster système , Il ne faut que quelques serveurs ou des dizaines d'hôtes , Plus rentable que des millions de superserveurs dédiés en mouvement .
- Extensibilité
Lorsque la pression de charge du serveur augmente , Le système peut être étendu pour répondre aux besoins , Sans réduire la qualité du Service .
- Disponibilité élevée
Malgré la défaillance de certains matériels et logiciels , Le service pour l'ensemble du système doit être: 7*24Heures de fonctionnement.
2、Avantages de la grappe
- Transparence
Si une partie du serveur tombe en panne et que l'entreprise n'est pas touchée , Le couplage général n'est pas si élevé , La dépendance n'est pas si élevée .Par exemple,NFS Le serveur est en panne et les autres ne peuvent pas être montés , C'est trop dépendant. .
- Haute performance
Augmentation du nombre de visites, Extensibilité facile .
- Maniabilité
L'ensemble du système peut être énorme physiquement , Mais c'est facile à gérer. .
- Programmabilité
Sur un système groupé , Facilité de développement des applications , Le portail demandera ceci .
3、Classification des grappes et caractéristiques des différentes classifications
Les architectures de Clusters informatiques sont généralement classées dans les catégories suivantes par fonction et structure :
- Cluster d'équilibrage de charge(Load balancing clusters)AbréviationsLBC
- Cluster haute disponibilité(High-availability clusters)AbréviationsHAC
- Cluster informatique haute performance(High-perfomance clusters)AbréviationsHPC
- Calcul en grille(Gridcomputing)
En ce qui concerne la classification des grappes , On pense généralement qu'il y a trois , Équilibrage de charge et regroupement à haute disponibilité l'architecture de regroupement couramment utilisée dans notre industrie Internet .
Trois、Introduction à la classification des grappes
1、Cluster d'équilibrage de charge
Le Cluster d'équilibrage de charge est plus pratique pour les entreprises,Solutions d'architecture de systèmes plus rentables. Le Cluster d'équilibrage de charge répartit la pression de charge des demandes d'accès centralisé de nombreux clients aussi uniformément que possible dans le cluster informatique pour le traitement .
La charge de demande du client comprend généralement la charge de traitement du niveau d'application et la charge de trafic réseau .Un tel système est idéal pour servir un grand nombre d'utilisateurs en utilisant le même ensemble d'applications.Chaque noeud peut supporter une certaine pression de charge de demande d'accès,Et les demandes d'accès peuvent être réparties dynamiquement entre les noeuds,Pour équilibrer la charge.
L'équilibrage de la charge fonctionne,En général, les demandes d'accès des clients sont distribuées par un ou plusieurs répartiteurs de charge frontale à un groupe de serveurs à l'arrière - plan,Afin d'atteindre la haute performance et la haute disponibilité de l'ensemble du système. De cette façon, les Clusters sont parfois appelés Clusters de serveurs .
En général, les grappes à haute disponibilité et les grappes à équilibrage de charge utilisent des techniques similaires,.Ou à la fois haute disponibilité et équilibrage de charge.
Le rôle des grappes d'équilibrage de charge:
a)Partage du trafic d'accès(Équilibrage de la charge)
b)Maintenir la continuité des opérations(Haute disponibilité)
2、Cluster haute disponibilité
En général, lorsque l'un des noeuds d'un Cluster échoue,Toutes les tâches du noeud sont automatiquement transférées à d'autres noeuds normaux,Et ce processus n'affecte pas le fonctionnement de l'ensemble du cluster,Sans préjudice de la prestation des services.
.C'est comme si deux noeuds identiques ou plus fonctionnaient dans un Cluster,Quand un noeud primaire tombe en panne, Alors, les autres Le noeud du noeud remplacera le noeud Maître , Poursuivre la tâche ci - dessus .Le noeud esclave peut prendre en charge les ressources du noeud Maître(IPAdresse,Identité du schéma, etc.),À ce stade, l'utilisateur ne découvre pas que l'objet servant est transféré du noeud maître au noeud esclave.
Le rôle des grappes à haute disponibilité: Quand une machine s'arrête et que l'autre prend le relais ..Les logiciels libres de Cluster les plus couramment utilisés sont:keepalive,heardbeat.
3、Cluster informatique haute performance
Le Cluster informatique haute performance utilise différents noeuds informatiques qui assignent des tâches informatiques au cluster pour améliorer la puissance de calcul,Il est donc principalement utilisé dans le domaine de l'informatique scientifique.
Plus populaireHPCAdoptionLinuxLe système d'exploitation et d'autres logiciels libres pour effectuer des opérations parallèles.Cette configuration de Cluster est souvent appeléeBeowulfCluster.Ces grappes exécutent généralement des programmes spécifiques pour jouerHPCclusterCapacité parallèle.Ce type de programme applique généralement une exécution spécifique, Par exemple, conçu pour l'informatique scientifiqueMPIBibliothèque.HPC Les Clusters sont particulièrement adaptés aux tâches de calcul où une grande quantité de communication de données se produit entre les noeuds de calcul , Par exemple, les résultats intermédiaires d'un noeud ou les cas qui affectent les résultats calculés d'autres noeuds .
Quatre、 Cluster vs. Distributed Difference
Le Cluster est une forme physique,La distribution est un mode de fonctionnement
- Distribué: Une entreprise est divisée en plusieurs sous - entreprises , Chaque sous - entreprise est déployée sur un serveur différent
- Cluster:Même entreprise,Déploiement sur plusieurs serveurs
1) La distribution signifie la distribution de différents sous - secteurs à différents endroits .Et un Cluster, c'est rassembler plusieurs serveurs,Réaliser la même entreprise.
2)Chaque noeud de la distribution,Peut être groupé.Et les grappes ne sont pas nécessairement distribuées.
Exemples:Comme Sina.com,Plus de visiteurs,Il pourrait faire un Cluster,Un serveur de réponse devant,Les serveurs suivants font la même chose,S'il y a une visite d'affaires,Serveur de réponse voir quel serveur n'est pas très chargé,Celui qui va finir.
3)Et distribué,Dans un sens étroit,C'est comme un Cluster,Mais son organisation est plus lâche,Pas comme un Cluster.,Il y a une organisation,Un serveur s'est effondré,D'autres serveurs peuvent monter.
4)Chaque noeud distribué, Toutes les sous - entreprises ,Un noeud s'est effondré, Alors cette affaire est inaccessible. .
En termes simples,La distribution améliore l'efficacité en réduisant le temps d'exécution des tâches individuelles,Les grappes, quant à elles, augmentent l'efficacité en augmentant le nombre de tâches exécutées par Unit é de temps.
Une bonne conception devrait être une combinaison de distribution et de regroupement , D'abord distribué puis groupé , La mise en œuvre concrète est que l'entreprise est divisée en plusieurs sous - entreprises , Ensuite, un déploiement groupé est effectué pour chaque sous - entreprise , Si quelque chose ne va pas avec chaque sous - entreprise , L'ensemble du système n'est pas affecté .
1、 Diagramme distribué
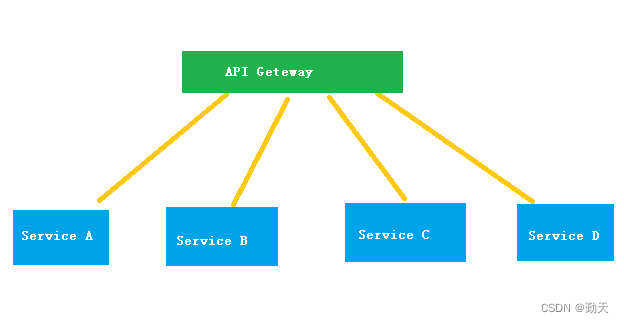
Diviser un grand système en plusieurs modules d'affaires, Les modules d'affaires sont déployés sur différentes machines ,L'interaction des données entre les différents modules d'affaires par l'intermédiaire d'interfaces. La façon de différencier la distribution est de différencier les entreprises en fonction des différentes machines .
Là - haut:service A、B、C、D Composantes opérationnelles ,AdoptionAPI Geteway Effectuer des visites d'affaires .
Note:: La distribution exige une bonne gestion des transactions
2、 Schéma du mode Cluster

Le mode Cluster est un serveur différent qui déploie le même ensemble de services pour l'accès externe , Équilibrer la charge du Service . La façon de différencier un Cluster est basée sur le déploiement de plusieurs services de serveur identiques .
Note:: Le mode Cluster doit être bien fait sessionPartage, Assurez - vous de ne pas passer d'un serveur à l'autre parce que session Et interrompre le Service de sortie .
Configuration généraleNginx* Mise en œuvre du conteneur de charge pour :Cache de ressources statiques、Session Le partage peut être effectué avec ,NginxSoutien5000Concurrence.
Cinq、 Différences entre les services distribués et les microservices
En plus, Il y a aussi un concept similaire à celui de la distribution ,C'est le micro - service..
Le micro - service est un style architectural,Une grande application logicielle complexe consiste en un ou plusieurs microservices.Chaque micro - service du système peut être déployé indépendamment,Les micro - services sont faiblement couplés.Chaque micro - service se concentre uniquement sur l'accomplissement d'une tâche et la bonne exécution de cette tâche.Dans tous les cas,Chaque tâche représente une petite capacité opérationnelle.
1、 Si la distribution appartient à un micro - service ?
La distribution doit être un micro - service. , Les microservices ne sont pas nécessairement distribués
Définition de la distribution : Diviser un service en plusieurs sous - services ,Sur différents serveurs. Les microservices peuvent être placés sur le même serveur , Peut également être placé sur un serveur différent .
2、Architecture des microservices
Les microservices sont conçus pour ne pas être mis à jour à cause d'un module etBUGImpact sur les activités actuelles du système.La nuance entre microservices et distribution est,Les applications de microservices ne sont pas nécessairement dispersées sur plusieurs serveurs,Il peut être le même serveur..

边栏推荐
- K6el-100 leakage relay
- 拼多多商品详情接口、拼多多商品基本信息、拼多多商品属性接口
- 架构设计的五个核心要素
- How digitalization affects workflow automation
- Digital innovation driven guide
- 数字化如何影响工作流程自动化
- Tablayout modification of customized tab title does not take effect
- When deleting a file, the prompt "the length of the source file name is greater than the length supported by the system" cannot be deleted. Solution
- 项目经理如何凭借NPDP证书逆袭?看这里
- 1. AVL tree: left-right rotation -bite
猜你喜欢
Annotation初体验

【js组件】自定义select
Preliminary practice of niuke.com (9)

4. 对象映射 - Mapping.Mapster

JHOK-ZBG2漏电继电器
Mapbox Chinese map address
Leetcode 1189 maximum number of "balloons" [map] the leetcode road of heroding

How digitalization affects workflow automation

论文阅读【Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention】
利用OPNET进行网络仿真时网络层协议(以QoS为例)的使用、配置及注意点
随机推荐
DOM node object + time node comprehensive case
基于 hugging face 预训练模型的实体识别智能标注方案:生成doccano要求json格式
利用OPNET进行网络仿真时网络层协议(以QoS为例)的使用、配置及注意点
JVM (XX) -- performance monitoring and tuning (I) -- Overview
Jhok-zbg2 leakage relay
CentOS 7.9 installing Oracle 21C Adventures
4. 对象映射 - Mapping.Mapster
np. random. Shuffle and np Use swapaxis or transfer with caution
京东商品详情页API接口、京东商品销量API接口、京东商品列表API接口、京东APP详情API接口、京东详情API接口,京东SKU信息接口
[PM products] what is cognitive load? How to adjust cognitive load reasonably?
Mysql database learning (7) -- a brief introduction to pymysql
5阶多项式轨迹
Preliminary practice of niuke.com (9)
张平安:加快云上数字创新,共建产业智慧生态
app clear data源码追踪
C#可空类型
漏电继电器JELR-250FG
Leetcode 1189 maximum number of "balloons" [map] the leetcode road of heroding
When deleting a file, the prompt "the length of the source file name is greater than the length supported by the system" cannot be deleted. Solution
数字化创新驱动指南