当前位置:网站首页>Moco is not suitable for target detection? MsrA proposes object level comparative learning target detection pre training method SOCO! Performance SOTA! (NeurIPS 2021)...
Moco is not suitable for target detection? MsrA proposes object level comparative learning target detection pre training method SOCO! Performance SOTA! (NeurIPS 2021)...
2022-07-05 04:14:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This article shares NeurIPS 2021 The paper 『Aligning Pretraining for Detection via Object-Level Contrastive Learning』MSRA A target detection pre training method based on object level comparative learning is proposed ! performance SOTA!
The details are as follows :

Thesis link :https://arxiv.org/abs/2106.02637
Project links :https://github.com/hologerry/SoCo
introduction :

Image level contrastive representation learning has been proved to be a very effective transfer learning model . However , If there is a need for a specific downstream task , This generalized transfer learning model loses its pertinence . The author believes that this may be suboptimal , The design principle that the pre training task from supervision should be consistent with the downstream task . In this paper , The author follows this principle , A pre training method is designed for target detection task . The author has achieved consistency in the following three aspects :
1) The object level representation is introduced as an object by selectively searching the bounding box proposal;
2) The pre training network structure combines detection pipeline Special modules used in ( for example FPN);
3) Pre training has target level translation invariance 、 Scale invariance and other target detection attributes .
The method proposed in this paper is called selective object contrastive learning (Selective Object COntrastive learning,SoCo) , It's based on Mask R-CNN In the framework of COCO The detection realizes SOTA The migration performance of .
01
Motivation
Pre training and fine tuning have always been the main paradigm of deep neural network training in computer vision . Downstream tasks are usually utilized in large annotation datasets ( for example ImageNet) Initialize the pre training weight learned on . therefore , Supervised ImageNet Pre training is common in the whole field .
In recent years , Self supervised pre training has made considerable progress , Reduce the dependence on label data . These methods aim to learn the general visual representation of various downstream tasks through image level pre training tasks . Some recent work shows that , Image level representation for intensive prediction tasks ( Such as target detection and semantic segmentation ) It's second best . One potential reason is , Image level pre training may be over suitable for overall representation , Unable to understand important attributes other than image classification .
The goal of this paper is to develop self supervised pre training consistent with target detection . In target detection , The detection box is used to represent the object . The translation and scale invariance of target detection are reflected by the position and size of the bounding box . There is an obvious representation gap between image level pre training and object level bounding box for target detection .
Based on this , The author proposes an object level self supervised pre training framework , It is called selective object contrast learning (Selective Object COntrastive learning, SoCo), Downstream tasks dedicated to target detection . In order to introduce object level representation into pre training ,SoCo Use selective search to generate objects proposal.
It is different from the previous image level contrast learning method , Take the whole picture as an example ,SoCo Each object in the image proposal As an independent instance .
therefore , The author designed a new pre training task , For learning object level visual representation compatible with target detection . To be specific ,SoCo Constructed an object level view , The scale and position of the same object instance are enhanced . Then carry out comparative learning , To maximize the similarity of objects in the enhanced view .
The introduction of object level representation also makes it possible to further bridge the gap between pre training and fine-tuning network structure . Target detection usually involves special modules , For example, feature pyramid network (FPN) . It is opposite to the image level contrast learning method which only pre trains the feature backbone network ,SoCo Pre train all network modules used in the detector . therefore , All layers of the detector can be well initialized .
02
Method
2.1 Overview
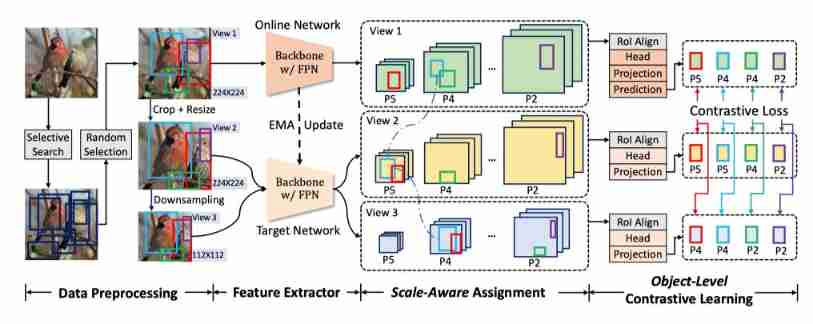
The figure above shows SoCo Of pipeline.SoCo It aims to make pre training consistent with target detection in two aspects :
Network structure alignment between pre training and target detection ;
Introduce the central attribute of target detection .
say concretely , In addition to pre training like the existing self supervised comparative learning methods backbone outside ,SoCo All network modules used in the target detector are also pre trained , Such as FPN and Mask R-CNN In the framework head. therefore , All layers of the detector can be well initialized .
Besides ,SoCo Learned object level representation , These representations are not only more meaningful for target detection , And it has translation and scale invariance . To achieve this ,SoCo By constructing multiple enhanced views and applying scale aware allocation strategy to different layers of feature pyramid , Encourage diversity of target scales and locations . Last , Apply object level contrast learning to maximize the feature similarity of the same object in the enhanced view .
2.2 Data Preprocessing
Object Proposal Generation
suffer R-CNN and Fast R-CNN Inspired by the , The author uses selective search to generate a set of objects for each original image proposal, This is an unsupervised object proposal generating algorithm , It takes into account color similarity 、 Texture similarity and area size . Put each object proposal Expressed as a bounding box , among (,) Represents the coordinates of the center of the bounding box ,w and h Respectively represent the corresponding width and height .
The author retains only those that meet the following requirements proposal:
402 Payment Required
, among W and H Indicates the width and height of the input image . object proposal The generation step does not participate in training , It is executed offline . In each training iteration , The author randomly selects... For each input image K individual proposal.View Construction
SoCo Three views are used in , namely . Size the input image to 224 × 224 In order to obtain . Then use on [0.5,1.0] Random scale for random clipping , obtain . Then resize the to the same size as , And delete objects other than proposal.
Next , Shrink to a fixed size ( for example 112×112) To generate . In all these cases , The bounding box is based on RGB Image clipping and resizing for conversion . Last , Each view is enhanced randomly and independently . The same object proposal The scale and position of are different in the enhanced view , This enables the model to learn translation invariant and scale invariant object level representations .
Box Jitter
To further encourage cross view objects proposal Differences in scale and location , The author is interested in the generated proposal Frame jitter is adopted (Box Jitter) Strategy , As an object level data enhancement . Specific implementation , Given an object proposal , Randomly generate a dithering box:, among .
2.3 Object-Level Contrastive Learning
SoCo The goal of is to make the pre training consistent with target detection . In this paper , Author use Mask R-CNN And feature pyramid network (FPN) To instantiate key design principles . Alignment mainly includes Match the pre training structure with target detection Qi , The important target detection attributes such as object level translation invariance and scale invariance are integrated into the pre training .
Aligning Pretraining Architecture to Object Detection
stay Mask R-CNN after , The author uses FPN The backbone network is used as image level feature extractor , take FPN The output of is expressed as , In steps of . For the bounding box, it means b, application RoIAlign Extract foreground features from the corresponding scale level . For further structural adjustment , In the pre training, the author introduces another R-CNN head. From the image view V Extract bounding box from b Object level feature representation of h by :
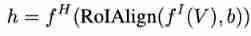
SoCo Two neural networks are used for learning , namely Online network (online network) and Target network (target network). The online network and the target network share the same structure , But with different weights . A group of objects in an image proposal Expressed as , In view proposal Object level representation of , In view It means . They are extracted using online network and target network respectively , As shown below :
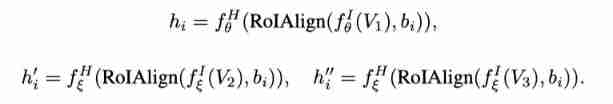
After the online network, a projector and predictor Used to obtain potential embedded ,θ and θ It's all double decked MLP. Add only after the target network projector . Use potential embeddings that represent object level features separately :
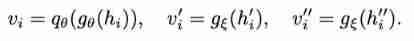
Object proposal The comparative loss of is defined as follows :
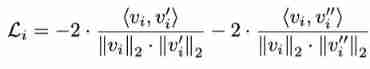
then , The loss function of each image is :
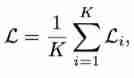
Where is the object proposal The number of .
Besides , Input to the target network , Input to online network , To calculate . Finally, the total loss function is :
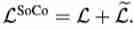
Scale-Aware Assignment
with FPN Of Mask R-CNN Use Anchor and Ground Truth box Between IoU To determine the positive sample . It defines Anchor Pixel regions respectively on . Inspired by this , The author proposes a scale aware allocation strategy , This strategy encourages the pre training model to learn the scale invariant representation of the object level .
To be specific , The author puts the object of area range proposal Assigned to . In this way ,SoCo Be able to learn the scale invariant representation at the object level , This is very important for target detection .
Introducing Properties of Detection to Pretraining
Object detection uses tight bounding boxes to represent objects . To introduce object level representation ,SoCo Generate objects by selective search proposal. Translation invariance and scale invariance at object level are the most important attributes of target detection , That is, the feature representation of objects belonging to the same category is insensitive to scale and position changes . Yes, the result of random clipping .
Random clipping introduces frame shift , therefore and The contrast learning encourages the pre training model to learn the position invariant representation . Is generated by down sampling , This causes the object to proposal Scale enhancement . Scale aware allocation strategy , and The contrast loss guides the pre training of learning scale invariant representation .
03
experiment
3.1 Comparison with State-of-the-Art Methods
Mask R-CNN with R50-FPN on COCO
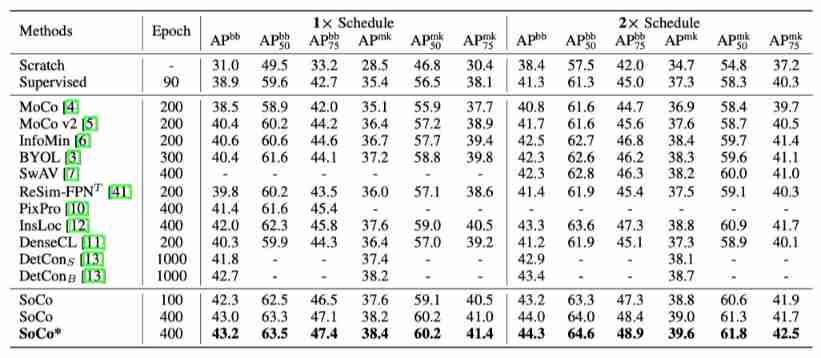
The above table shows the results based on SoCo Band of R50-FPN backbone Of Mask R-CNN result . It can be seen that , Compared with other comparative learning methods , The method in this paper can achieve higher performance .
Mask R-CNN with R50-C4 on COCO
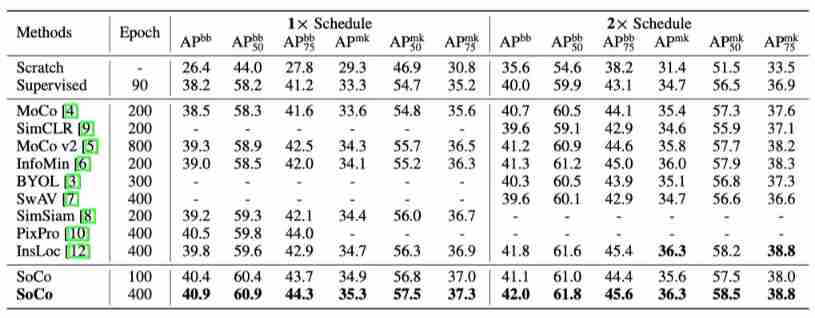
The above table shows the results based on SoCo Band of R50-C4 backbone Of Mask R-CNN result . It can be seen that , Compared with other comparative learning methods , The method in this paper can achieve higher performance .
Faster R-CNN with R50-C4 on Pascal VOC
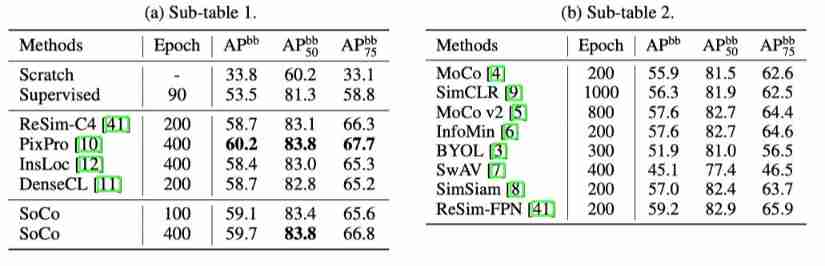
The table above shows Faster R-CNN The result on , It can be seen that , On different frames , The methods in this paper are applicable .
3.2. Ablation Study
Effectiveness of Aligning Pretraining to Object Detection
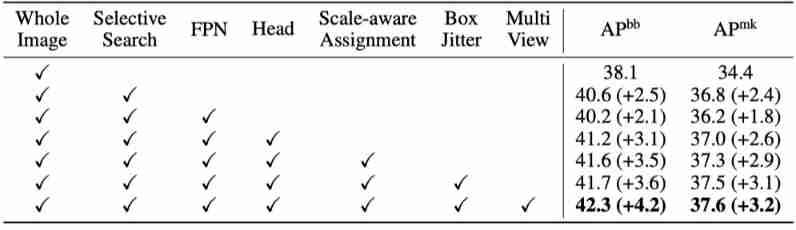
The above table shows the ablation results of different pre training methods and structures , It can be seen that , The methods and modules proposed in this paper , It can promote the improvement of performance .
Ablation Study on Hyper-Parameters
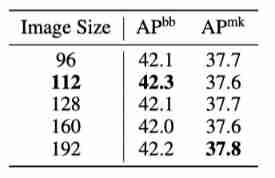
The above table shows the impact of different sizes on the results , It can be seen that , The image size is 112 when , The result is better .
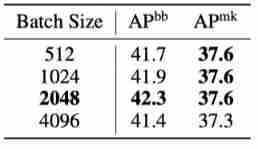
The table above shows the different Batch Size Result .
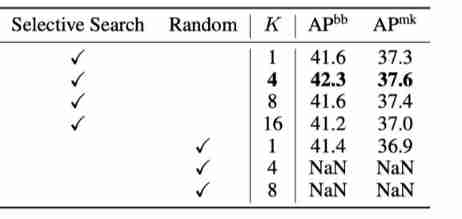
The table above shows the different proposal Results of sampling method and quantity , It can be seen that selective search is better than random sampling , Selective search Proposal The quantity of is 4 The result is the best .
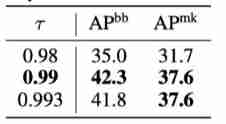
The above table shows the experimental results of different momentum coefficients , The best effect .
3.3. Evaluation on Mini COCO

In order to verify the generalization of the method in this paper , The author is still there Mini COCO Experiments on data sets , The results are shown in the table above .
04
summary
In this paper , An object level self supervised pre training method is proposed —— Selective object contrast learning (Selective Object COntrastive learning,SOCo), It aims to combine pre training with target detection . Different from the previous image level contrast learning methods, the whole image is regarded as an example ,SoCo Each object generated by the selective search algorithm proposal As a separate instance , send SoCo Be able to learn object level visual representation .
then , Further object alignment is obtained in two ways . One is through network alignment between pre training and downstream target detection , Thus, all layers of the detector can be initialized well . The other is by considering the important attributes of target detection , Scale invariance and translation invariance .SoCo Use Mask R-CNN The detector is in COCO On the detection data set SOTA The migration performance of , Also in the R50-FPN and R50-C4 Structural experiments prove that SoCo Versatility and scalability of .
▊ Author's brief introduction
research field :FightingCV Official account operator , The research direction is multimodal content understanding , Focus on solving the task of combining visual modality and language modality , promote Vision-Language Field application of the model .
You know / official account :FightingCV

END
Welcome to join 「 object detection 」 Exchange group notes :OD

边栏推荐
- Kwai, Tiktok, video number, battle content payment
- 技术教程:如何利用EasyDSS将直播流推到七牛云?
- [understand series after reading] 6000 words teach you to realize interface automation from 0 to 1
- Containerd series - detailed explanation of plugins
- 10种寻址方式之间的区别
- How to solve the problem that easycvr changes the recording storage path and does not generate recording files?
- Hexadecimal to octal
- NEW:Devart dotConnect ADO. NET
- 【看完就懂系列】一文6000字教你从0到1实现接口自动化
- Three level linkage demo of uniapp uview u-picker components
猜你喜欢
![[array]566 Reshape the matrix - simple](/img/3c/593156f5bde67bd56828106d7bed3c.png)
[array]566 Reshape the matrix - simple
Laravel8 export excel file
Use threejs to create geometry and add materials, lights, shadows, animations, and axes
How does the applet solve the rendering layer network layer error?

如何优雅的获取每个分组的前几条数据

@The problem of cross database query invalidation caused by transactional annotation

Interview summary: This is a comprehensive & detailed Android interview guide
【虚幻引擎UE】实现UE5像素流部署仅需六步操作少走弯路!(4.26和4.27原理类似)

Threejs realizes sky box, panoramic scene, ground grass

【虚幻引擎UE】实现测绘三脚架展开动画制作
随机推荐
Three level linkage demo of uniapp uview u-picker components
Alibaba cloud ECS uses cloudfs4oss to mount OSS
Laravel8 export excel file
蛇形矩阵
阿里云ECS使用cloudfs4oss挂载OSS
【虚幻引擎UE】实现UE5像素流部署仅需六步操作少走弯路!(4.26和4.27原理类似)
web资源部署后navigator获取不到mediaDevices实例的解决方案(navigator.mediaDevices为undefined)
Rust blockchain development - signature encryption and private key public key
学习MVVM笔记(一)
Judge whether the stack order is reasonable according to the stack order
网络安全-记录web漏洞修复
Get to know MySQL connection query for the first time
[phantom engine UE] only six steps are needed to realize the deployment of ue5 pixel stream and avoid detours! (the principles of 4.26 and 4.27 are similar)
The order of LDS links
A应用唤醒B应该快速方法
How to solve the problem that easycvr changes the recording storage path and does not generate recording files?
为什么百度、阿里这些大厂宁愿花25K招聘应届生,也不愿涨薪5K留住老员工?
lds链接的 顺序问题
小程序中实现文章的关注功能
Online text line fixed length fill tool