当前位置:网站首页>一文了解數據异常值檢測方法
一文了解數據异常值檢測方法
2022-07-04 07:55:00 【數據分析-中志】
异常值檢測方法作為數據分析過程中的重要一步,也是數據分析師的必備技能之一。下面簡單介紹一下數據分析相關的檢測方法,如有不足還請批評指正。
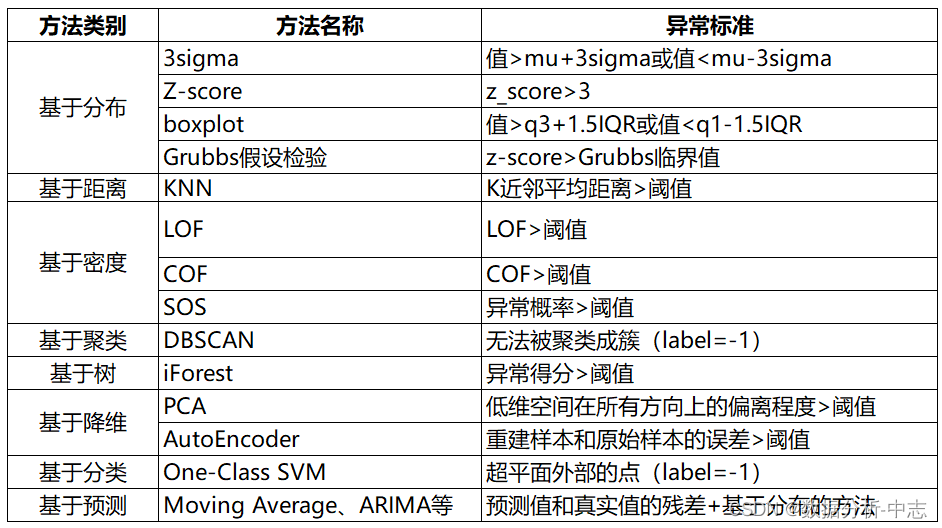
一、基於分布的异常值檢測方法
1. 3sigma
基於正態分布,3sigma准則認為超過3sigma的數據為异常點。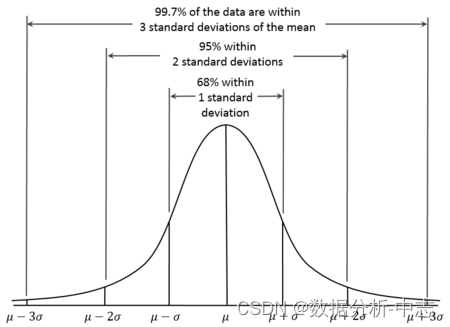
python程序實現:
def three_sigma(s):
mu, std = np.mean(s), np.std(s)
lower, upper = mu-3*std, mu+3*std
return lower, upper
2.Z-score
Z-score為標准分數,測量數據點和平均值的距離,若A與平均值相差2個標准差,Z-score為2。當把Z-score=3作為閾值去剔除异常點時,便相當於3sigma。
def z_score(s):
z_score = (s - np.mean(s)) / np.std(s)
return z_score
3. boxplot
箱線圖時基於四分比特距(IQR)找异常點的。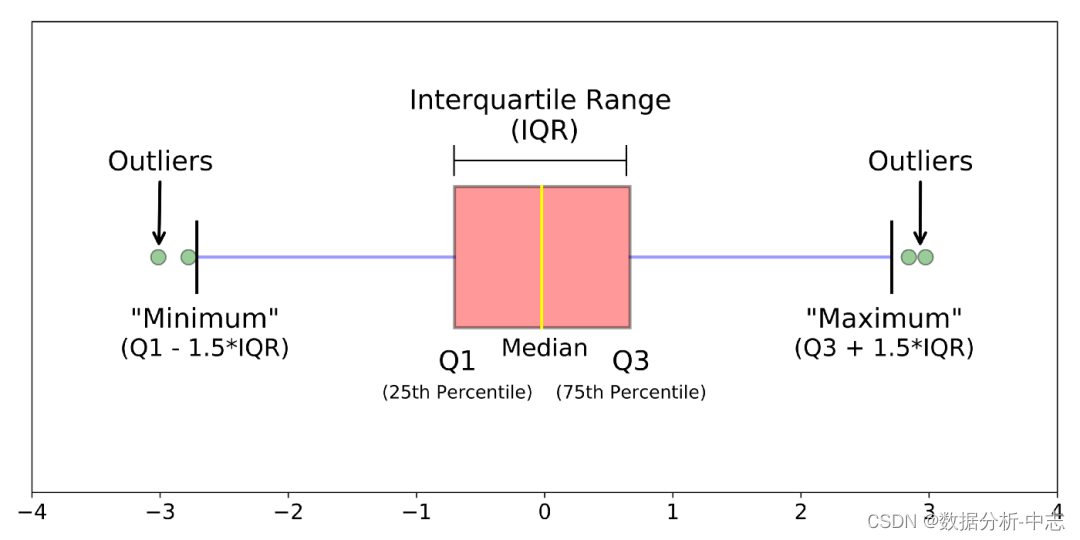
def boxplot(s):
q1, q3 = s.quantile(.25), s.quantile(.75)
iqr = q3 - q1
lower, upper = q1 - 1.5*iqr, q3 + 1.5*iqr
return lower, upper
4.Grubbs假設檢驗
Grubbs’Test為一種假設檢驗的方法,常被用來檢驗服從正態分布的單變量數據集(univariate data set)Y中的單個异常值。若有异常值,則其必為數據集中的最大值或最小值。原假設與備擇假設如下:
● H0: 數據集中沒有异常值
● H1: 數據集中有一個异常值
使用Grubbs測試需要總體是正態分布的。算法流程:
1,樣本從小到大排序
2,求樣本的mean和dev
3, 計算min/max與mean的差距,更大的那個為可疑值
4,求可疑值的z-score (standard score),如果大於Grubbs臨界值,那麼就是outlier
Grubbs臨界值可以查錶得到,它由兩個值决定:檢出水平α(越嚴格越小),樣本數量n,排除outlier,對剩餘序列循環做 1-4 步驟 [1]。詳細計算樣例可以參考。
from outliers import smirnov_grubbs as grubbs
print(grubbs.test([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.min_test_outliers([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.max_test_outliers([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.max_test_indices([8, 9, 10, 50, 9], alpha=0.05))
局限:
1、只能檢測單維度數據
2、無法精確的輸出正常區間
3、它的判斷機制是“逐一剔除”,所以每個异常值都要單獨計算整個步驟,數據量大吃不消。
4、需假定數據服從正態分布或近正態分布
二、基於距離的异常值檢測方法
1、KNN
依次計算每個樣本點與它最近的K個樣本的平均距離,再利用計算的距離與閾值進行比較,如果大於閾值,則認為是异常點。優點是不需要假設數據的分布,缺點是僅可以找出全局异常點,無法找到局部异常點。
from pyod.models.knn import KNN
# 初始化檢測器clf
clf = KNN( method='mean', n_neighbors=3, )
clf.fit(X_train)
# 返回訓練數據上的分類標簽 (0: 正常值, 1: 异常值)
y_train_pred = clf.labels_
# 返回訓練數據上的异常值 (分值越大越异常)
y_train_scores = clf.decision_scores_
三、基於密度的方法
1、 Local Outlier Factor (LOF)
LOF是基於密度的經典算法(Breuning et. al. 2000),通過給每個數據點都分配一個依賴於鄰域密度的離群因子 LOF,進而判斷該數據點是否為離群點。它的好處在於可以量化每個數據點的异常程度(outlierness)。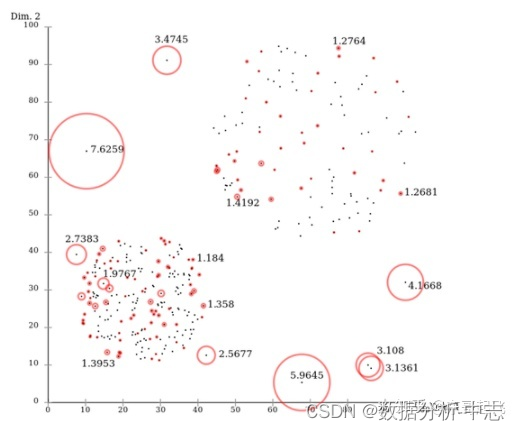
數據點P的局部相對密度(局部异常因子)=點P鄰域內點的平均局部可達密度 跟 數據點P的局部可達密度 的比值: 數據點P的局部可達密度=P最近鄰的平均可達距離的倒數。距離越大,密度越小。
點P到點O的第k可達距離=max(點O的k近鄰距離,點P到點O的距離)。
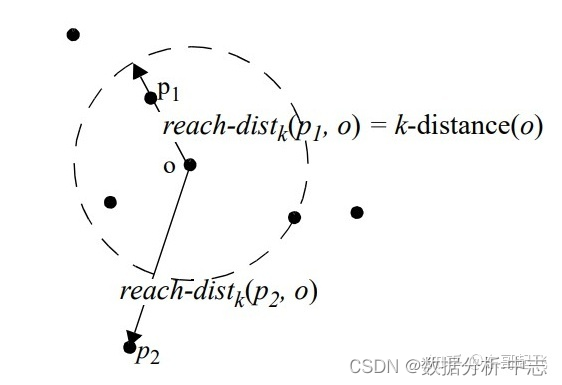
點O的k近鄰距離=第 k個最近的點跟點O之間的距離。
整體來說,LOF算法流程如下:
● 對於每個數據點,計算它與其他所有點的距離,並按從近到遠排序;
● 對於每個數據點,找到它的K-Nearest-Neighbor,計算LOF得分。
from sklearn.neighbors import LocalOutlierFactor as LOF
X = [[-1.1], [0.2], [100.1], [0.3]]
clf = LOF(n_neighbors=2)
res = clf.fit_predict(X)
print(res)
print(clf.negative_outlier_factor_)
2.Connectivity-Based Outlier Factor (COF)
COF是LOF的變種,相比於LOF,COF可以處理低密度下的异常值,COF的局部密度是基於平均鏈式距離計算得到。在一開始的時候我們一樣會先計算出每個點的k-nearest neighbor。而接下來我們會計算每個點的Set based nearest Path,如下圖: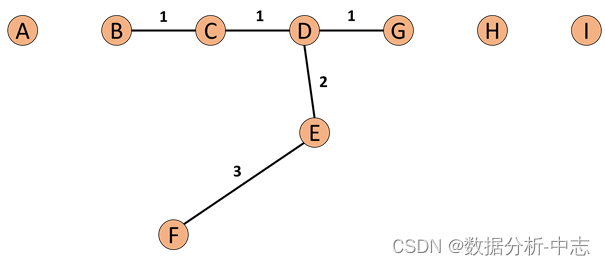
假使我們今天我們的k=5,所以F的neighbor為B、C、D、E、G。而對於F離他最近的點為E,所以SBN Path的第一個元素是F、第二個是E。離E最近的點為D所以第三個元素為D,接下來離D最近的點為C和G,所以第四和五個元素為C和G,最後離C最近的點為B,第六個元素為B。所以整個流程下來,F的SBN Path為{F, E, D, C, G, C, B}。而對於SBN Path所對應的距離e={e1, e2, e3,…,ek},依照上面的例子e={3,2,1,1,1}。
所以我們可以說假使我們想計算p點的SBN Path,我們只要直接計算p點和其neighbor所有點所構成的graph的minimum spanning tree,之後我們再以p點為起點執行shortest path算法,就可以得到我們的SBN Path。
而接下來我們有了SBN Path我們就會接著計算,p點的鏈式距離: 有了ac_distance後,我們就可以計算COF:
from pyod.models.cof import COF
cof = COF(contamination = 0.06, ## 异常值所占的比例
n_neighbors = 20, ## 近鄰數量
)
cof_label = cof.fit_predict(iris.values) # 鳶尾花數據
print("檢測出的异常值數量為:",np.sum(cof_label == 1))
3.Stochastic Outlier Selection (SOS)
將特征矩陣(feature martrix)或者相异度矩陣(dissimilarity matrix)輸入給SOS算法,會返回一個异常概率值向量(每個點對應一個)。SOS的思想是:當一個點和其它所有點的關聯度(affinity)都很小的時候,它就是一個异常點。
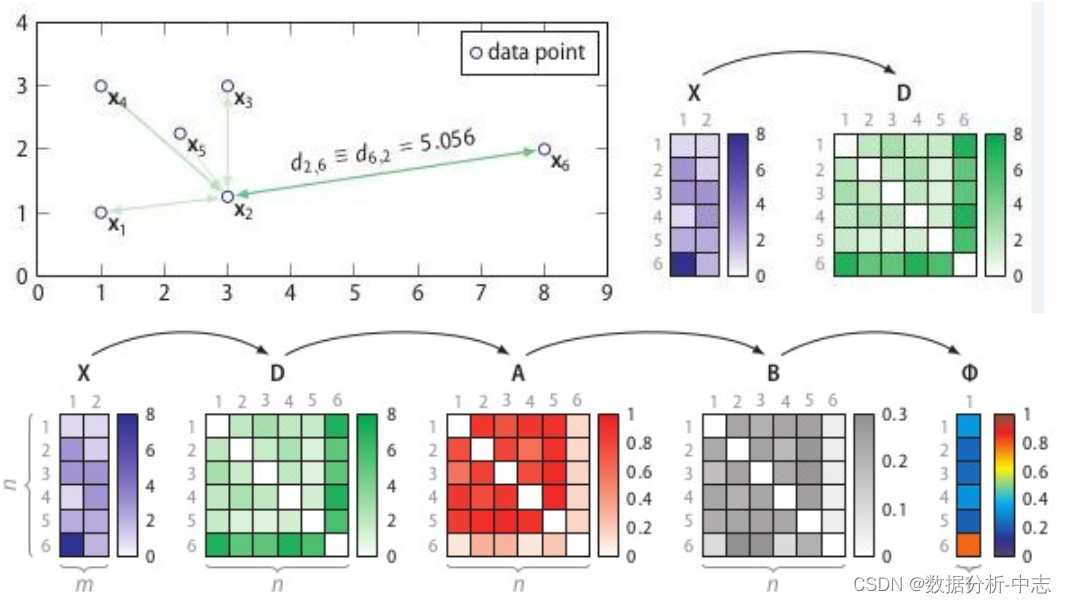
SOS的流程:
計算相异度矩陣D;
計算關聯度矩陣A;
計算關聯概率矩陣B;
算出异常概率向量。
相异度矩陣D是各樣本兩兩之間的度量距離,比如歐式距離或漢明距離等。關聯度矩陣反映的是度量距離方差,如圖7,點 的密度最大,方差最小; 的密度最小,方差最大。而關聯概率矩陣B(binding probability matrix)就是把關聯矩陣(affinity matrix)按行歸一化得到的,如圖8所示。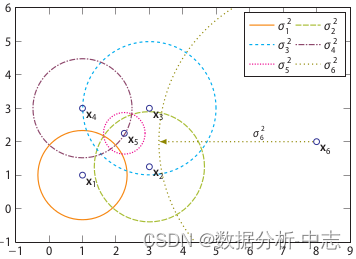
上圖為關聯度矩陣中密度可視化,下圖為關聯概率矩陣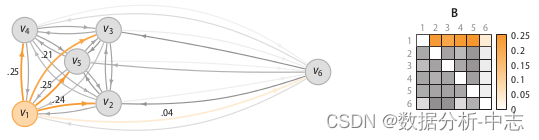
得到了binding probability matrix,每個點的异常概率值就用如下的公式計算,當一個點和其它所有點的關聯度(affinity)都很小的時候,它就是一個异常點。
import pandas as pd
from sksos import SOS
iris = pd.read_csv("http://bit.ly/iris-csv")
X = iris.drop("Name", axis=1).values
detector = SOS()
iris["score"] = detector.predict(X)
iris.sort_values("score", ascending=False).head(10)
四:基於聚類的方法
DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)的輸入和輸出如下,對於無法形成聚類簇的孤立點,即為异常點(噪聲點)。
● 輸入:數據集,鄰域半徑Eps,鄰域中數據對象數目閾值MinPts;
● 輸出:密度聯通簇。
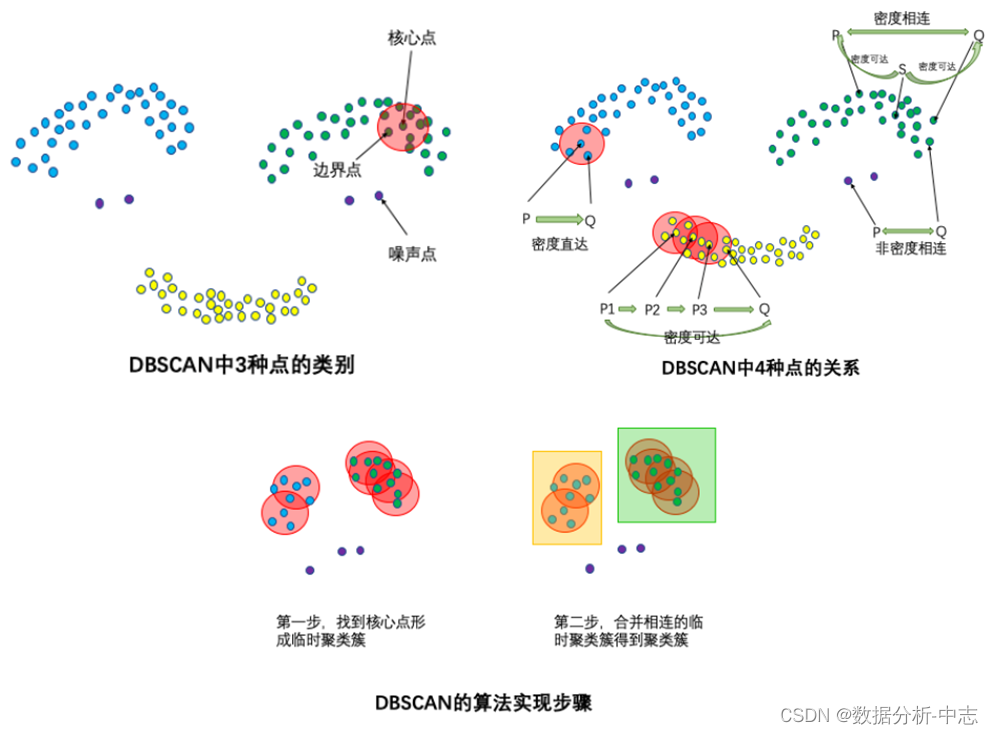
處理流程如下。
從數據集中任意選取一個數據對象點p;
如果對於參數Eps和MinPts,所選取的數據對象點p為核心點,則找出所有從p密度可達的數據對象點,形成一個簇;
如果選取的數據對象點 p 是邊緣點,選取另一個數據對象點;
重複以上2、3步,直到所有點被處理。
from sklearn.cluster import DBSCAN
import numpy as np
X = np.array([[1, 2], [2, 2], [2, 3],
[8, 7], [8, 8], [25, 80]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
array([ 0, 0, 0, 1, 1, -1])
# 0,,0,,0:錶示前三個樣本被分為了一個群
# 1, 1:中間兩個被分為一個群
# -1:最後一個為异常點,不屬於任何一個群
五、基於樹的方法
孤立森林中的 “孤立” (isolation) 指的是 “把异常點從所有樣本中孤立出來”,論文中的原文是 “separating an instance from the rest of the instances”。
我們用一個隨機超平面對一個數據空間進行切割,切一次可以生成兩個子空間。接下來,我們再繼續隨機選取超平面,來切割第一步得到的兩個子空間,以此循環下去,直到每子空間裏面只包含一個數據點為止。我們可以發現,那些密度很高的簇要被切很多次才會停止切割,即每個點都單獨存在於一個子空間內,但那些分布稀疏的點,大都很早就停到一個子空間內了。所以,整個孤立森林的算法思想:异常樣本更容易快速落入葉子結點或者說,异常樣本在决策樹上,距離根節點更近。
隨機選擇m個特征,通過在所選特征的最大值和最小值之間隨機選擇一個值來分割數據點。觀察值的劃分遞歸地重複,直到所有的觀察值被孤立。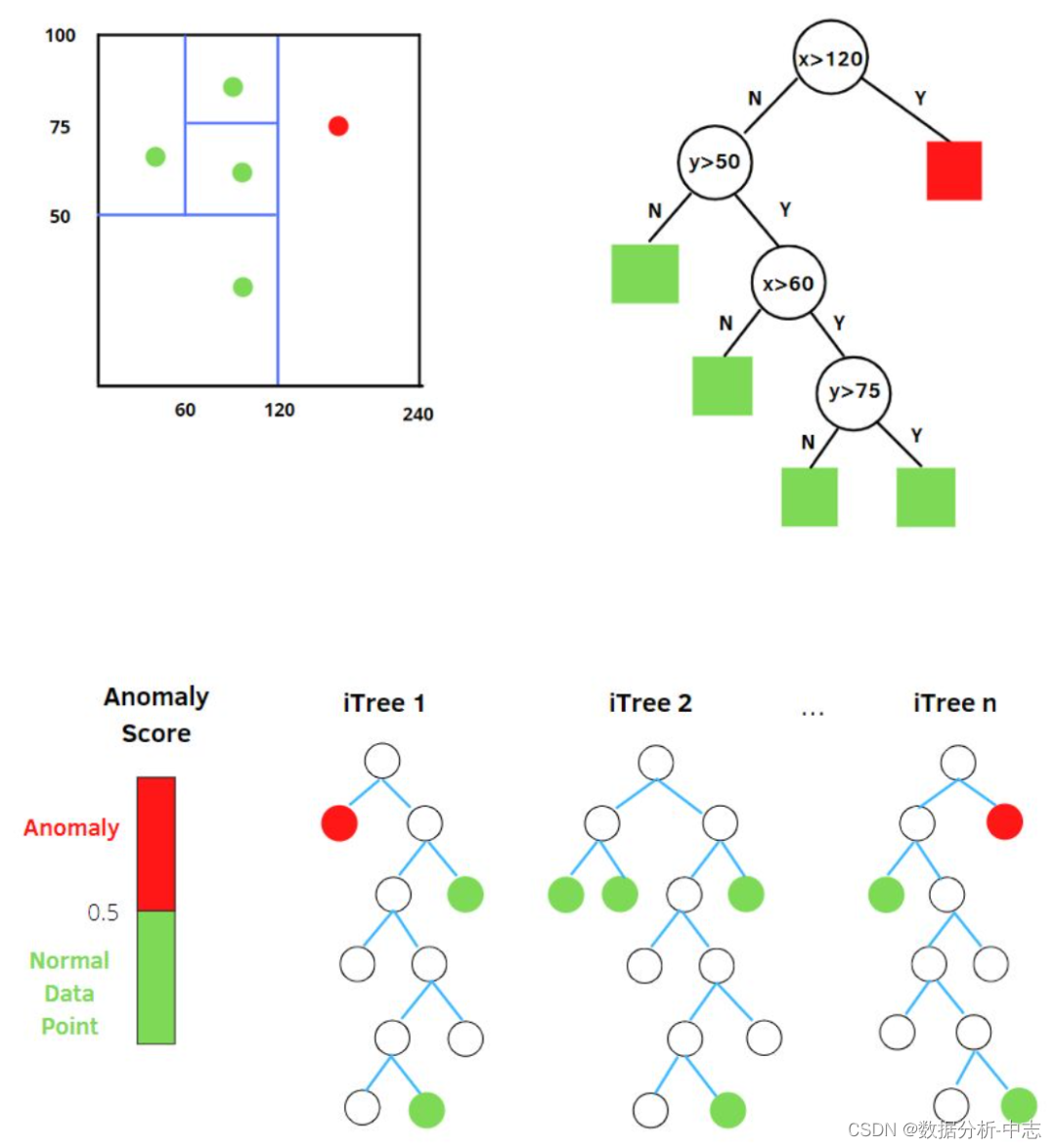
獲得 t 個孤立樹後,單棵樹的訓練就結束了。接下來就可以用生成的孤立樹來評估測試數據了,即計算异常分數 s。對於每個樣本 x,需要對其綜合計算每棵樹的結果,通過下面的公式計算异常得分: ● h(x):為樣本在iTree上的PathLength;
● E(h(x)):為樣本在t棵iTree的PathLength的均值;
● c(n):為n個樣本構建一個二叉搜索樹BST中的未成功搜索平均路徑長度(均值h(x)對外部節點終端的估計等同於BST中的未成功搜索)。 是對樣本x的路徑長度h(x)進行標准化處理。H(n-1)是調和數,可使用ln(n-1)+0.5772156649(歐拉常數)估算。 指數部分值域為(−∞,0),因此s值域為(0,1)。當PathLength越小,s越接近1,此時樣本為异常值的概率越大。
from sklearn.datasets import load_iris
from sklearn.ensemble import IsolationForest
data = load_iris(as_frame=True)
X,y = data.data,data.target
df = data.frame
# 模型訓練
iforest = IsolationForest(n_estimators=100, max_samples='auto',
contamination=0.05, max_features=4,
bootstrap=False, n_jobs=-1, random_state=1)
# fit_predict 函數 訓練和預測一起 可以得到模型是否异常的判斷,-1為异常,1為正常
df['label'] = iforest.fit_predict(X)
# 預測 decision_function 可以得出 异常評分
df['scores'] = iforest.decision_function(X)
六、基於降維的方法
1、Principal Component Analysis (PCA)
PCA在异常檢測方面的做法,大體有兩種思路:
(1) 將數據映射到低維特征空間,然後在特征空間不同維度上查看每個數據點跟其它數據的偏差;
(2) 將數據映射到低維特征空間,然後由低維特征空間重新映射回原空間,嘗試用低維特征重構原始數據,看重構誤差的大小。
PCA在做特征值分解,會得到:
● 特征向量:反應了原始數據方差變化程度的不同方向;
● 特征值:數據在對應方向上的方差大小。
所以,最大特征值對應的特征向量為數據方差最大的方向,最小特征值對應的特征向量為數據方差最小的方向。原始數據在不同方向上的方差變化反應了其內在特點。如果單個數據樣本跟整體數據樣本錶現出的特點不太一致,比如在某些方向上跟其它數據樣本偏離較大,可能就錶示該數據樣本是一個异常點。
在前面提到第一種做法中,樣本 x i x_i xi的异常分數為該樣本在所有方向上的偏離程度: 其中, 為樣本在重構空間裏離特征向量的距離。若存在樣本點偏離各主成分越遠, 會越大,意味偏移程度大,异常分數高。 是特征值,用於歸一化,使不同方向上的偏離程度具有可比性。
在計算异常分數時,關於特征向量(即度量异常用的標杆)選擇又有兩種方式:
● 考慮在前k個特征向量方向上的偏差:前k個特征向量往往直接對應原始數據裏的某幾個特征,在前幾個特征向量方向上偏差比較大的數據樣本,往往就是在原始數據中那幾個特征上的極值點。
● 考慮後r個特征向量方向上的偏差:後r個特征向量通常錶示某幾個原始特征的線性組合,線性組合之後的方差比較小反應了這幾個特征之間的某種關系。在後幾個特征方向上偏差比較大的數據樣本,錶示它在原始數據裏對應的那幾個特征上出現了與預計不太一致的情况。 得分大於閾值C則判斷為异常。
第二種做法,PCA提取了數據的主要特征,如果一個數據樣本不容易被重構出來,錶示這個數據樣本的特征跟整體數據樣本的特征不一致,那麼它顯然就是一個异常的樣本:
其中, 是基於k維特征向量重構的樣本。
基於低維特征進行數據樣本的重構時,舍弃了較小的特征值對應的特征向量方向上的信息。換一句話說,重構誤差其實主要來自較小的特征值對應的特征向量方向上的信息。基於這個直觀的理解,PCA在异常檢測上的兩種不同思路都會特別關注較小的特征值對應的特征向量。所以,我們說PCA在做异常檢測時候的兩種思路本質上是相似的,當然第一種方法還可以關注較大特征值對應的特征向量。
rom sklearn.decomposition import PCA
pca = PCA()
pca.fit(centered_training_data)
transformed_data = pca.transform(training_data)
y = transformed_data
# 計算异常分數
lambdas = pca.singular_values_
M = ((y*y)/lambdas)
# 前k個特征向量和後r個特征向量
q = 5
print "Explained variance by first q terms: ", sum(pca.explained_variance_ratio_[:q])
q_values = list(pca.singular_values_ < .2)
r = q_values.index(True)
# 對每個樣本點進行距離求和的計算
major_components = M[:,range(q)]
minor_components = M[:,range(r, len(features))]
major_components = np.sum(major_components, axis=1)
minor_components = np.sum(minor_components, axis=1)
# 人為設定c1、c2閾值
components = pd.DataFrame({
'major_components': major_components,
'minor_components': minor_components})
c1 = components.quantile(0.99)['major_components']
c2 = components.quantile(0.99)['minor_components']
# 制作分類器
def classifier(major_components, minor_components):
major = major_components > c1
minor = minor_components > c2
return np.logical_or(major,minor)
results = classifier(major_components=major_components, minor_components=minor_components)
2、AutoEncoder
PCA是線性降維,AutoEncoder是非線性降維。根據正常數據訓練出來的AutoEncoder,能够將正常樣本重建還原,但是卻無法將异於正常分布的數據點較好地還原,導致還原誤差較大。因此如果一個新樣本被編碼,解碼之後,它的誤差超出正常數據編碼和解碼後的誤差範圍,則視作為异常數據。需要注意的是,AutoEncoder訓練使用的數據是正常數據(即無异常值),這樣才能得到重構後誤差分布範圍是多少以內是合理正常的。所以AutoEncoder在這裏做异常檢測時,算是一種有監督學習的方法。
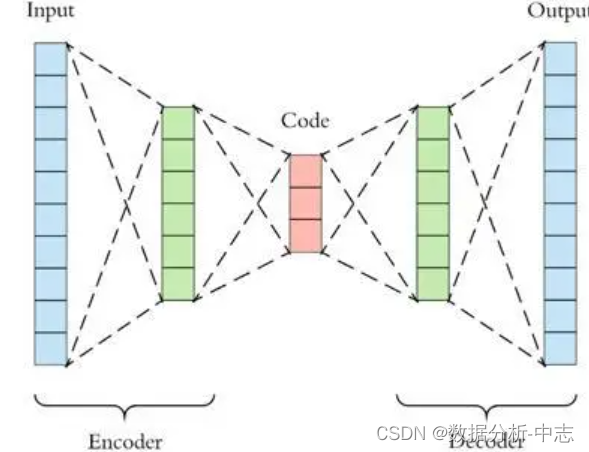
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
# 標准化數據
scaler = preprocessing.MinMaxScaler()
X_train = pd.DataFrame(scaler.fit_transform(dataset_train),
columns=dataset_train.columns,
index=dataset_train.index)
# Random shuffle training data
X_train.sample(frac=1)
X_test = pd.DataFrame(scaler.transform(dataset_test),
columns=dataset_test.columns,
index=dataset_test.index)
tf.random.set_seed(10)
act_func = 'relu'
# Input layer:
model=Sequential()
# First hidden layer, connected to input vector X.
model.add(Dense(10,activation=act_func,
kernel_initializer='glorot_uniform',
kernel_regularizer=regularizers.l2(0.0),
input_shape=(X_train.shape[1],)
)
)
model.add(Dense(2,activation=act_func,
kernel_initializer='glorot_uniform'))
model.add(Dense(10,activation=act_func,
kernel_initializer='glorot_uniform'))
model.add(Dense(X_train.shape[1],
kernel_initializer='glorot_uniform'))
model.compile(loss='mse',optimizer='adam')
print(model.summary())
# Train model for 100 epochs, batch size of 10:
NUM_EPOCHS=100
BATCH_SIZE=10
history=model.fit(np.array(X_train),np.array(X_train),
batch_size=BATCH_SIZE,
epochs=NUM_EPOCHS,
validation_split=0.05,
verbose = 1)
plt.plot(history.history['loss'],
'b',
label='Training loss')
plt.plot(history.history['val_loss'],
'r',
label='Validation loss')
plt.legend(loc='upper right')
plt.xlabel('Epochs')
plt.ylabel('Loss, [mse]')
plt.ylim([0,.1])
plt.show()
# 查看訓練集還原的誤差分布如何,以便制定正常的誤差分布範圍
X_pred = model.predict(np.array(X_train))
X_pred = pd.DataFrame(X_pred,
columns=X_train.columns)
X_pred.index = X_train.index
scored = pd.DataFrame(index=X_train.index)
scored['Loss_mae'] = np.mean(np.abs(X_pred-X_train), axis = 1)
plt.figure()
sns.distplot(scored['Loss_mae'],
bins = 10,
kde= True,
color = 'blue')
plt.xlim([0.0,.5])
# 誤差閾值比對,找出异常值
X_pred = model.predict(np.array(X_test))
X_pred = pd.DataFrame(X_pred,
columns=X_test.columns)
X_pred.index = X_test.index
threshod = 0.3
scored = pd.DataFrame(index=X_test.index)
scored['Loss_mae'] = np.mean(np.abs(X_pred-X_test), axis = 1)
scored['Threshold'] = threshod
scored['Anomaly'] = scored['Loss_mae'] > scored['Threshold']
scored.head()
七、基於分類的方法
1、One-Class SVM
One-Class SVM,這個算法的思路非常簡單,就是尋找一個超平面將樣本中的正例圈出來,預測就是用這個超平面做决策,在圈內的樣本就認為是正樣本,在圈外的樣本是負樣本,用在异常檢測中,負樣本可看作异常樣本。它屬於無監督學習,所以不需要標簽。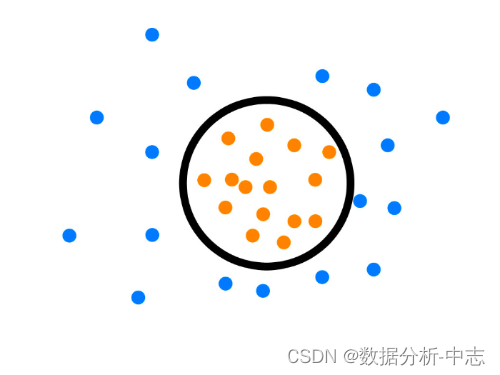
One-Class SVM又一種推導方式是SVDD(Support Vector Domain Description,支持向量域描述),對於SVDD來說,我們期望所有不是异常的樣本都是正類別,同時它采用一個超球體,而不是一個超平面來做劃分,該算法在特征空間中獲得數據周圍的球形邊界,期望最小化這個超球體的體積,從而最小化异常點數據的影響。
假設產生的超球體參數為中心 o 和對應的超球體半徑r>0,超球體體積V被最小化,中心o是支持行了的線性組合;跟傳統SVM方法相似,可以要求所有訓練數據點xi到中心的距離嚴格小於r。但是同時構造一個懲罰系數為C的松弛變量 ζi,優化問題入下所示:
C是調節松弛變量的影響大小,說的通俗一點就是,給那些需要松弛的數據點多少松弛空間,如果C比較小,會給離群點較大的彈性,使得它們可以不被包含進超球體。
from sklearn import svm
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel='rbf', gamma=0.1)
clf.fit(X)
y_pred = clf.predict(X)
n_error_outlier = y_pred[y_pred == -1].size
八、基於預測的方法
對於單條時序數據,根據其預測出來的時序曲線和真實的數據相比,求出每個點的殘差,並對殘差序列建模,利用KSigma或者分比特數等方法便可以進行异常檢測。具體的流程如下: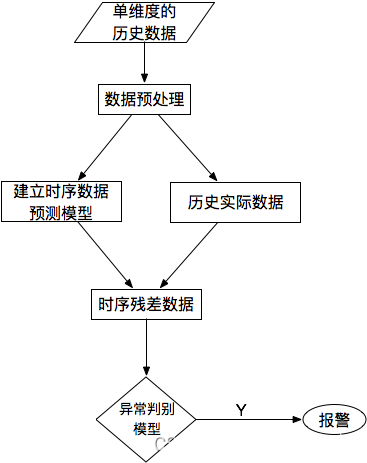
九、總結
异常檢測方法總結如下:
边栏推荐
- 如何用MOS管来实现电源防反接电路
- [network security] what is emergency response? What indicators should you pay attention to in emergency response?
- The right way to capture assertion failures in NUnit - C #
- How to reset IntelliSense in vs Code- How to reset intellisense in VS Code?
- Unity-写入Word
- Activiti常見操作數據錶關系
- Tri des fonctions de traitement de texte dans MySQL, recherche rapide préférée
- How to set multiple selecteditems on a list box- c#
- C#实现一个万物皆可排序的队列
- zabbix监控系统部署
猜你喜欢
![[network security] what is emergency response? What indicators should you pay attention to in emergency response?](/img/2e/96da79d82ae2c49a3a0ab9909467ac.jpg)
[network security] what is emergency response? What indicators should you pay attention to in emergency response?

Handwritten easy version flexible JS and source code analysis
【性能测试】一文读懂Jmeter

Used on windows Bat file startup project
1. Getting started with QT

谷歌官方回应:我们没有放弃TensorFlow,未来与JAX并肩发展
This monitoring system can monitor the turnover intention and fishing all, and the product page has 404 after the dispute appears
Moher College webmin unauthenticated remote code execution

Amd RX 7000 Series graphics card product line exposure: two generations of core and process mix and match

University stage summary
随机推荐
Cannot click button when method is running - C #
The idea of implementing charts chart view in all swiftui versions (1.0-4.0) was born
Leetcode 23. 合并K个升序链表
Is l1-029 too fat (5 points)
[gurobi] establishment of simple model
Used on windows Bat file startup project
I was pressed for the draft, so let's talk about how long links can be as efficient as short links in the development of mobile terminals
[go basics] 2 - go basic sentences
L1-027 rental (20 points)
Difference between static method and non static method (advantages / disadvantages)
墨者学院-Webmin未经身份验证的远程代码执行
zabbix 5.0监控客户端
Unity write word
【性能测试】一文读懂Jmeter
Tri des fonctions de traitement de texte dans MySQL, recherche rapide préférée
OKR vs. KPI figure out these two concepts at once!
Set and modify the page address bar icon favicon ico
Life planning (flag)
大学阶段总结
NPM run build error