当前位置:网站首页>Mobilenet series (5): use pytorch to build mobilenetv3 and learn and train based on migration
Mobilenet series (5): use pytorch to build mobilenetv3 and learn and train based on migration
2022-07-06 00:49:00 【@BangBang】
This blog realizes MobileNetV3 Code for , Reference resources pytorch Officially realized mobilenet Source code
The details of the MobileNetV3 Network explanation , Refer to the post :MobileNet series (4):MobileNetv3 Network details
Code details
open model_v3.py file
- take channel Adjust to the nearest 8 Integer multiple
def _make_divisible(ch,divisor=8,min_ch=None):
if min_ch is None:
min_ch=divisor
new_ch=max(min_ch,int(ch+divisor/2)//divisor*divisor)
if new_ch <0.9*ch:
new_ch += divisor
return new_ch
- V3 Convolution structure of network
stay V3 Convolution used in Networks , It's basically :Convolution Conv +BN+ Activation function, Here we define a convolution classConvBNActivation
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes:int,
out_planes:int,
kernel_size:int =3,
stride:int =1,
groups:int=1,
norm_layer:Optional[Callable[...,nn.Module]]=None,
activation_layer:Optional[Callable[...,nn.Module]]=None
):
padding=(kernel_size-1)//2
if norm_layer is None:
norm_layer =nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation,self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False,
norm_layer(out_planes),
activation_layer))
- SE modular
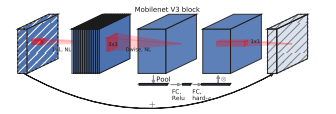
- Before Blog in , We talked about
SEmodular , It is actually two full connection layers . For the first fully connected layer , Its number of nodes is the input characteristic matrix channel Of1/4, The number of nodes in the second full link layer is the same as that of the input characteristic matrix channel Is consistent .
Be careful : The activation function of the first convolution layer isReLU, The activation function of the second convolution layer makesh-sigmoidActivation function .
SE The code of the module is as follows :
class SqueezeExcitaion(nn.Module):
def __init__(self,input_c:int,squeeze_factor:int=4):
super(SqueezeExcitaion,self).__init__()
squeeze_c=_make_divisible(input_c//squeeze_factor,8)
self.fc1 = nn.Conv2d(input_c,squeeze_c,1)
self.fc2 = nn.Conv2d(squeeze_c,input_c,1)
def forward(self,x:Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x,output_size=(1,1))
scale =self.fc1(scale)
scale=F.relu(scale,inplace=True)
scale=self.fc2(scale)
scale=F.hardsigmoid(scale,inplace=True)
return scale * x
The network configuration InvertedResidualConfig
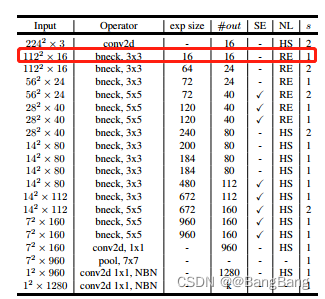
in the light of MobileNetv3 Parameters of each layer , The parameters are shown in the following table :
Network parameter configuration class :InvertedResidualConfig
class InvertedResidualConfig:
def __init__(self,
input_c:int,
kernel:int,
expanded_c:int,
out_c:int,
use_se:bool,
activation:str,
stride:int,
width_multi:float) #width_multi Convolution layer uses channel Magnification factor of
self.input_c=self.adjust_channels(input_c,width_multi)
self.kernel=kernel
self.expanded_c=self.adjust_channels(expanded_c,width_multi)
self.out_c=self.adjust_channels(out_c,width_multi)
self.use_se=use_se
self.use_hs=ativation=="HS" #whether using h-switch activation
self.stride=stride
@staticmethod
def adjust_channels(channels:int,width:float):
return _make_divisivle(channels*width_multi,8)
bneck modular
mobilenectv3 The network consists of a series of bneck Stacked ,bneck Before the module detailed reference Blog .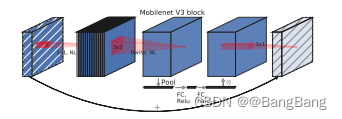
Create a class InvertedResidual Inherit nn.Module
class InvertedResidual(nn.Module):
def __init__(self,
cnf:InvertedResidualConfig,
norm_layer:Callable[...,nn.Module]):
super(InvertedResidual,self).__init__()
if cnf.stride not in [1,2]:
raise ValueError("illegal stride value.")
self.use_res_connect=(cnf.stride ==1 and cnf.input_c=cnf.out_c)
layers:List[nn.Module] = []
# Use nn.Hardswish pytorch Version needs to be 1.7 Or more
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
#expand
# In the network structure , first bneck Of input channel and exp size equal , That is, it didn't pass 1x1 Convolution dimension , So the first one bneck No, 1x1 Convolution
if cnf.expanded_c ! = cnf.input_c: # Equal no 1x1 Convolution dimension , Unequal means 1x1 Convolution dimension
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer
))
# depthwise
layers.append(ConvBNActivation(
cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c, # depthwise Convolution groups= The channel number
norm_layer=norm_layer,
activation_layer=activation_layer
))
if cnf.use_se:
layers.append(SqueezeExcitaion(cnf.expaned_c))
# 1x1 Reduced dimensional convolution layer
layers.append(ConvBNActivation( cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity # Linear activation
))
self.block=nn.Sequential(*layers)
self.out_channel=cnf.out_c
def forward(self,x:Tensor) -> Tensor
result=self.block(x)
if self.use_res_connect:
result +=x
return result
- structure MobileNetV3
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting:List[InvertedResidualConfig],
last_channel:int,
num_classes:int =1000,
block:Optional[Callable[...,nn.Module]]=None,
norm_layer:Optional[Callable[...,nn.Module]]=None
):
super(MobileNetVe,self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty")
elif not (isinstance(inverted_residual_setting,List) and
all([isInstance(s,InvertedResidualConfig) for s in inverted_residual_setting]))
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer=partial(nn.BatchNorm2d,eps=0.001,momentum=0.01)
layers:List[nn.Module] = []
# building first layer
fisrtconv_output_c =inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardwish))
# building inverted residual block
for cnf in inverted_residual_setting:
layers.append(block(cnf,norm_layer))
# building last several layers
lastconv_input_c=inverted_residual_setting[-1].out_c
lastconv_output_c=6*lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer =norm_layer,
activation_layer=nn.Hardswish
))
self.features =nn.Sequential(*layers)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.classifier=nn.Sequential(nn.Linear(lastconv_output_c,last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2,inplace=True),
nn.Linear(last_channel,num_classes))
# initial weights
for m in self.modules():
if isinstance(m.nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m,(nn.BatchNorm2d,nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zers_(m.bias)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.zeros(m.bias)
def _forward_impl(self,x:Tensor) ->Tensor:
x=self.features(x)
x=self.avgpool(x)
x=torch.flatten(x,1)
x=self.classifier(x)
return x
def forward(self,x:Tensor) ->Tensor:
return self._forward_impl(x)
- structure MobileNetV3 Large
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
""" Constructs a large MobileNetV3 architecture from "Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>. weights_link: https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth Args: num_classes (int): number of classes reduced_tail (bool): If True, reduces the channel counts of all feature layers between C4 and C5 by 2. It is used to reduce the channel redundancy in the backbone for Detection and Segmentation. """
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, "RE", 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
- structure MobileNetV3 Small
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
""" Constructs a large MobileNetV3 architecture from "Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>. weights_link: https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth Args: num_classes (int): number of classes reduced_tail (bool): If True, reduces the channel counts of all feature layers between C4 and C5 by 2. It is used to reduce the channel redundancy in the backbone for Detection and Segmentation. """
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, "RE", 2), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
Network training
Training image data set download train.py
import os
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from model_v2 import MobileNetV2 # Can be replaced with MobileNetV3 MobileNetV3-Large MobileNetV3-Smalll
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
batch_size = 16 # Adjust according to the size of the video memory
epochs = 5
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# create model
net = MobileNetV2(num_classes=5) # Can be replaced with MobileNetV3 MobileNetV3-Large MobileNetV3-Smalll
# load pretrain weights
# download url: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
model_weight_path = "./mobilenet_v2.pth" # Can replace MobileNetV3 MobileNetV3-Large MobileNetV3-Smalll Pre training weight of
assert os.path.exists(model_weight_path), "file {} dose not exist.".format(model_weight_path)
pre_weights = torch.load(model_weight_path, map_location=device)
# delete classifier weights
pre_dict = {
k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)
# freeze features weights
for param in net.features.parameters():
param.requires_grad = False
net.to(device)
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)
best_acc = 0.0
save_path = './MobileNetV2.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1,
epochs)
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
Model to predict
predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model_v2 import MobileNetV2
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = MobileNetV2(num_classes=5).to(device)
# load model weights
model_weight_path = "./MobileNetV2.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
- List item
Model prediction effect 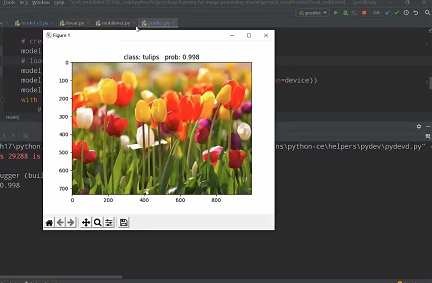
Source download
边栏推荐
- NLP generation model 2017: Why are those in transformer
- Intensive learning weekly, issue 52: depth cuprl, distspectrl & double deep q-network
- anconda下载+添加清华+tensorflow 安装+No module named ‘tensorflow‘+KernelRestarter: restart failed,内核重启失败
- golang mqtt/stomp/nats/amqp
- [groovy] compile time metaprogramming (compile time method interception | find the method to be intercepted in the myasttransformation visit method)
- Classic CTF topic about FTP protocol
- Leetcode:20220213 week race (less bugs, top 10% 555)
- Spark SQL空值Null,NaN判断和处理
- Installation and use of esxi
- 数据分析思维分析方法和业务知识——分析方法(三)
猜你喜欢

Folding and sinking sand -- weekly record of ETF
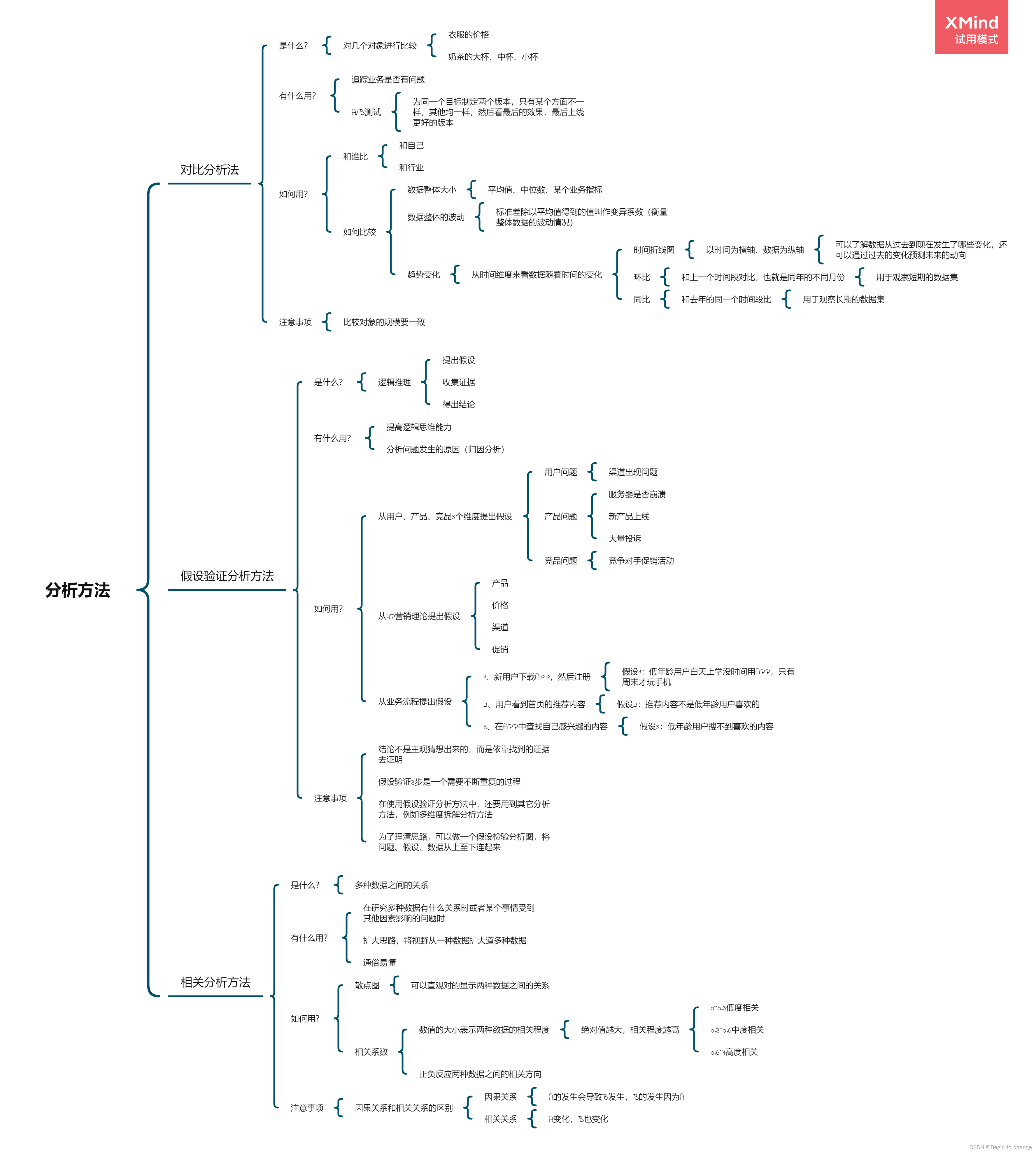
数据分析思维分析方法和业务知识——分析方法(二)

cf:H. Maximal AND【位运算练习 + k次操作 + 最大And】
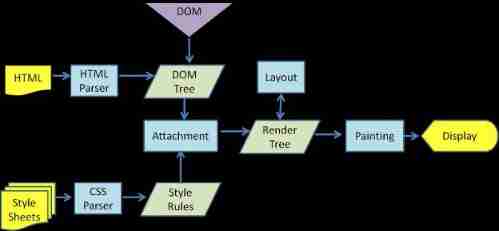
Browser reflow and redraw

MIT doctoral thesis | robust and reliable intelligent system using neural symbol learning
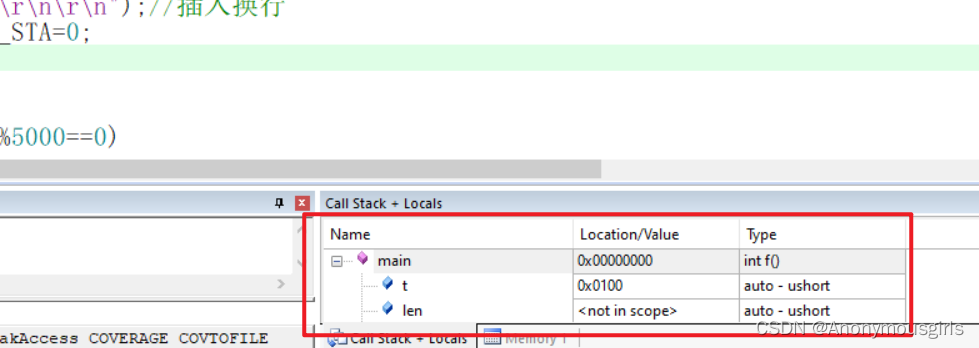
Set data real-time update during MDK debug
Free chat robot API
![[groovy] compile time meta programming (compile time method interception | method interception in myasttransformation visit method)](/img/e4/a41fe26efe389351780b322917d721.jpg)
[groovy] compile time meta programming (compile time method interception | method interception in myasttransformation visit method)
MCU realizes OTA online upgrade process through UART
建立时间和保持时间的模型分析
随机推荐
MIT博士论文 | 使用神经符号学习的鲁棒可靠智能系统
China Taiwan strategy - Chapter 8: digital marketing assisted by China Taiwan
Pointer pointer array, array pointer
MySQL storage engine
Installation and use of esxi
Reading notes of the beauty of programming
关于#数据库#的问题:(5)查询库存表中每本书的条码、位置和借阅的读者编号
MCU realizes OTA online upgrade process through UART
【EI会议分享】2022年第三届智能制造与自动化前沿国际会议(CFIMA 2022)
[groovy] compile time meta programming (compile time method interception | method interception in myasttransformation visit method)
[groovy] JSON serialization (jsonbuilder builder | generates JSON string with root node name | generates JSON string without root node name)
How to use the flutter framework to develop and run small programs
测试/开发程序员的成长路线,全局思考问题的问题......
数据分析思维分析方法和业务知识——分析方法(三)
Hundreds of lines of code to implement a JSON parser
RAID disk redundancy queue
DD's command
Notepad + + regular expression replace String
Cve-2017-11882 reappearance
Problems and solutions of converting date into specified string in date class