当前位置:网站首页>MobileNet系列(5):使用pytorch搭建MobileNetV3并基于迁移学习训练
MobileNet系列(5):使用pytorch搭建MobileNetV3并基于迁移学习训练
2022-07-06 00:44:00 【@BangBang】
本博文实现的MobileNetV3的代码,参考pytorch官方实现的mobilenet源码
详细的MobileNetV3 网络讲解,参考博文:MobileNet系列(4):MobileNetv3网络详解
代码详解
打开model_v3.py文件
- 将channel调整到离它最近的8的整数倍
def _make_divisible(ch,divisor=8,min_ch=None):
if min_ch is None:
min_ch=divisor
new_ch=max(min_ch,int(ch+divisor/2)//divisor*divisor)
if new_ch <0.9*ch:
new_ch += divisor
return new_ch
- V3网络的卷积结构
在V3网络中使用的卷积,基本上都是:卷积Conv +BN+激活函数,这里定义一个卷积类ConvBNActivation
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes:int,
out_planes:int,
kernel_size:int =3,
stride:int =1,
groups:int=1,
norm_layer:Optional[Callable[...,nn.Module]]=None,
activation_layer:Optional[Callable[...,nn.Module]]=None
):
padding=(kernel_size-1)//2
if norm_layer is None:
norm_layer =nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation,self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False,
norm_layer(out_planes),
activation_layer))
- SE模块
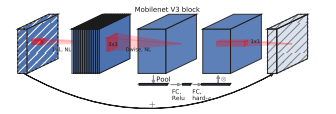
- 在之前博客中,我们有讲到过
SE模块,其实是两个全连接层。对于第一个全连接层,它的节点个数是输入特征矩阵channel的1/4,而第二个全链接层它的节点个数与我们输入特征矩阵的channel是保持一致的。
注意:第一个卷积层它的激活函是ReLU,第二个卷积层它的激活函数使h-sigmoid激活函数。
SE模块的代码如下:
class SqueezeExcitaion(nn.Module):
def __init__(self,input_c:int,squeeze_factor:int=4):
super(SqueezeExcitaion,self).__init__()
squeeze_c=_make_divisible(input_c//squeeze_factor,8)
self.fc1 = nn.Conv2d(input_c,squeeze_c,1)
self.fc2 = nn.Conv2d(squeeze_c,input_c,1)
def forward(self,x:Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x,output_size=(1,1))
scale =self.fc1(scale)
scale=F.relu(scale,inplace=True)
scale=self.fc2(scale)
scale=F.hardsigmoid(scale,inplace=True)
return scale * x
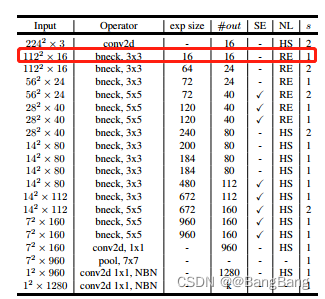
网络配置InvertedResidualConfig
针对MobileNetv3每一层的参数,参数如下表所示:
网络参数配置类:InvertedResidualConfig
class InvertedResidualConfig:
def __init__(self,
input_c:int,
kernel:int,
expanded_c:int,
out_c:int,
use_se:bool,
activation:str,
stride:int,
width_multi:float) #width_multi 卷积层使用channel的倍率因子
self.input_c=self.adjust_channels(input_c,width_multi)
self.kernel=kernel
self.expanded_c=self.adjust_channels(expanded_c,width_multi)
self.out_c=self.adjust_channels(out_c,width_multi)
self.use_se=use_se
self.use_hs=ativation=="HS" #whether using h-switch activation
self.stride=stride
@staticmethod
def adjust_channels(channels:int,width:float):
return _make_divisivle(channels*width_multi,8)
bneck模块
mobilenectv3网络是由一系列的bneck堆叠形成的,bneck模块详解参考之前博客。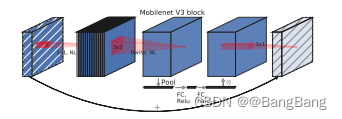
创建类InvertedResidual继承nn.Module
class InvertedResidual(nn.Module):
def __init__(self,
cnf:InvertedResidualConfig,
norm_layer:Callable[...,nn.Module]):
super(InvertedResidual,self).__init__()
if cnf.stride not in [1,2]:
raise ValueError("illegal stride value.")
self.use_res_connect=(cnf.stride ==1 and cnf.input_c=cnf.out_c)
layers:List[nn.Module] = []
# 使用nn.Hardswish pytorch版本需要1.7或以上
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
#expand
#网络结构中,第一个bneck的 input channel和exp size大小相等,即没有通过1x1卷积升维,因此第一个bneck没有1x1卷积
if cnf.expanded_c ! = cnf.input_c: #相等没有1x1卷积升维,不等表示有1x1卷积升维
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer
))
# depthwise
layers.append(ConvBNActivation(
cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c, # depthwise卷积 groups=通道数
norm_layer=norm_layer,
activation_layer=activation_layer
))
if cnf.use_se:
layers.append(SqueezeExcitaion(cnf.expaned_c))
# 1x1降维的卷积层
layers.append(ConvBNActivation( cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity #线性激活
))
self.block=nn.Sequential(*layers)
self.out_channel=cnf.out_c
def forward(self,x:Tensor) -> Tensor
result=self.block(x)
if self.use_res_connect:
result +=x
return result
- 构建MobileNetV3
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting:List[InvertedResidualConfig],
last_channel:int,
num_classes:int =1000,
block:Optional[Callable[...,nn.Module]]=None,
norm_layer:Optional[Callable[...,nn.Module]]=None
):
super(MobileNetVe,self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty")
elif not (isinstance(inverted_residual_setting,List) and
all([isInstance(s,InvertedResidualConfig) for s in inverted_residual_setting]))
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer=partial(nn.BatchNorm2d,eps=0.001,momentum=0.01)
layers:List[nn.Module] = []
# building first layer
fisrtconv_output_c =inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardwish))
# building inverted residual block
for cnf in inverted_residual_setting:
layers.append(block(cnf,norm_layer))
# building last several layers
lastconv_input_c=inverted_residual_setting[-1].out_c
lastconv_output_c=6*lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer =norm_layer,
activation_layer=nn.Hardswish
))
self.features =nn.Sequential(*layers)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.classifier=nn.Sequential(nn.Linear(lastconv_output_c,last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2,inplace=True),
nn.Linear(last_channel,num_classes))
# initial weights
for m in self.modules():
if isinstance(m.nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m,(nn.BatchNorm2d,nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zers_(m.bias)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.zeros(m.bias)
def _forward_impl(self,x:Tensor) ->Tensor:
x=self.features(x)
x=self.avgpool(x)
x=torch.flatten(x,1)
x=self.classifier(x)
return x
def forward(self,x:Tensor) ->Tensor:
return self._forward_impl(x)
- 构建MobileNetV3 Large
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
""" Constructs a large MobileNetV3 architecture from "Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>. weights_link: https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth Args: num_classes (int): number of classes reduced_tail (bool): If True, reduces the channel counts of all feature layers between C4 and C5 by 2. It is used to reduce the channel redundancy in the backbone for Detection and Segmentation. """
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, "RE", 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
- 构建MobileNetV3 Small
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
""" Constructs a large MobileNetV3 architecture from "Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>. weights_link: https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth Args: num_classes (int): number of classes reduced_tail (bool): If True, reduces the channel counts of all feature layers between C4 and C5 by 2. It is used to reduce the channel redundancy in the backbone for Detection and Segmentation. """
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, "RE", 2), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
网络训练
训练的图像数据集下载train.py
import os
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from model_v2 import MobileNetV2 # 可以替换为MobileNetV3 MobileNetV3-Large MobileNetV3-Smalll
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
batch_size = 16 #根据显存大小调整
epochs = 5
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# create model
net = MobileNetV2(num_classes=5) # 可以替换为MobileNetV3 MobileNetV3-Large MobileNetV3-Smalll
# load pretrain weights
# download url: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
model_weight_path = "./mobilenet_v2.pth" # 可以替换MobileNetV3 MobileNetV3-Large MobileNetV3-Smalll 的预训练权重
assert os.path.exists(model_weight_path), "file {} dose not exist.".format(model_weight_path)
pre_weights = torch.load(model_weight_path, map_location=device)
# delete classifier weights
pre_dict = {
k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)
# freeze features weights
for param in net.features.parameters():
param.requires_grad = False
net.to(device)
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)
best_acc = 0.0
save_path = './MobileNetV2.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1,
epochs)
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
模型预测
predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model_v2 import MobileNetV2
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = MobileNetV2(num_classes=5).to(device)
# load model weights
model_weight_path = "./MobileNetV2.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
- List item
模型预测效果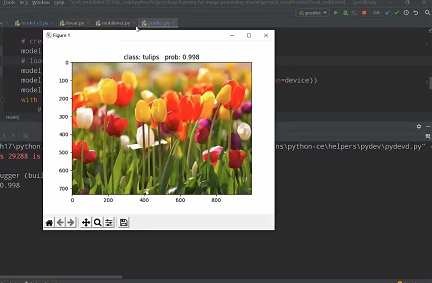
源码下载
边栏推荐
- I'm interested in watching Tiktok live beyond concert
- KDD 2022 | EEG AI helps diagnose epilepsy
- MCU通过UART实现OTA在线升级流程
- notepad++正则表达式替换字符串
- Why can't mathematics give machine consciousness
- Classic CTF topic about FTP protocol
- LeetCode 6005. The minimum operand to make an array an alternating array
- 多线程与高并发(8)—— 从CountDownLatch总结AQS共享锁(三周年打卡)
- 常用API类及异常体系
- 从 1.5 开始搭建一个微服务框架——调用链追踪 traceId
猜你喜欢

anconda下载+添加清华+tensorflow 安装+No module named ‘tensorflow‘+KernelRestarter: restart failed,内核重启失败

cf:H. Maximal AND【位运算练习 + k次操作 + 最大And】
Extension and application of timestamp

MIT博士论文 | 使用神经符号学习的鲁棒可靠智能系统
![[groovy] compile time meta programming (compile time method interception | method interception in myasttransformation visit method)](/img/e4/a41fe26efe389351780b322917d721.jpg)
[groovy] compile time meta programming (compile time method interception | method interception in myasttransformation visit method)
常用API类及异常体系
Free chat robot API
![Atcoder beginer contest 254 [VP record]](/img/13/656468eb76bb8b6ea3b6465a56031d.png)
Atcoder beginer contest 254 [VP record]
Idea remotely submits spark tasks to the yarn cluster

KDD 2022 | EEG AI helps diagnose epilepsy
随机推荐
Calculate sha256 value of data or file based on crypto++
Intranet Security Learning (V) -- domain horizontal: SPN & RDP & Cobalt strike
notepad++正则表达式替换字符串
免费的聊天机器人API
Promise
logstash清除sincedb_path上传记录,重传日志数据
Illustrated network: the principle behind TCP three-time handshake, why can't two-time handshake?
Problems and solutions of converting date into specified string in date class
[groovy] JSON string deserialization (use jsonslurper to deserialize JSON strings | construct related classes according to the map set)
Basic introduction and source code analysis of webrtc threads
STM32按键消抖——入门状态机思维
A preliminary study of geojson
Why can't mathematics give machine consciousness
esxi的安装和使用
Leetcode 44 Wildcard matching (2022.02.13)
小程序技术优势与产业互联网相结合的分析
Promise
Pointer pointer array, array pointer
[groovy] JSON serialization (convert class objects to JSON strings | convert using jsonbuilder | convert using jsonoutput | format JSON strings for output)
Go learning --- structure to map[string]interface{}